NLP领域最近比较火的Prompt,能否借鉴到多模态领域?一文跟进最新进展

©PaperWeekly 原创 · 作者 | 杨浩
研究方向 | 自然语言处理
#01.
VL-T5

论文标题:
Unifying Vision-and-Language Tasks via Text Generation
收录会议:
ICML 2021
论文链接:
https://arxiv.org/abs/2102.02779
代码链接:
https://github.com/j-min/VL-T5
1.1 Motivation
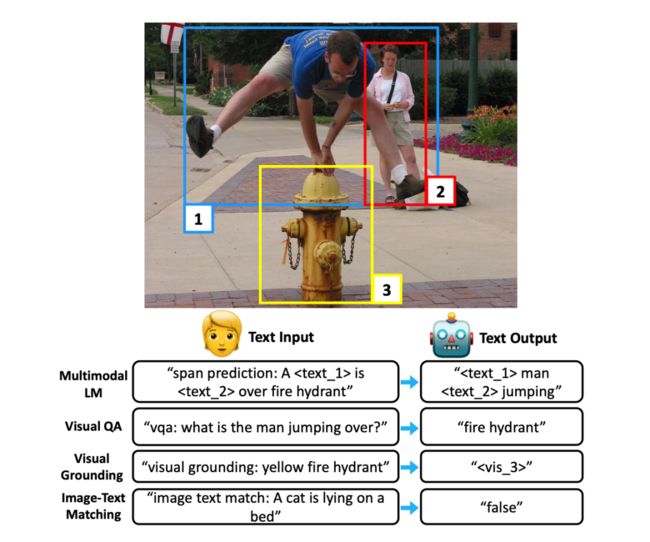
提出了一个统一的框架、统一的训练目标,能够兼容 7 个多模态任务的学习。统一的训练方式是 multimodal conditional text generation,即输入视觉图片+文本,生成文本 label,不同的任务之间的知识可以共享。
1.2 Method
7 个多模态任务的 benchmark,包括 VQA, GQA, COCO Caption, NLVR2, VCR, MMT, REF-COCOg。所有任务的输入加上文本前缀(e.g.”vqa:”, “image text match:”)用于区分不同任务,输出都统一成 text label 的形式。对于 visual grounding 任务,图片特征输入时就加了类似
1.3 Contribution
提出任务统一框架,使用了 encoder-decoder 的 Transformer 结构。
#02.
CLIP

论文标题:
Learning Transferable Visual Models From Natural Language Supervision
收录会议:
ICML 2021
论文链接:
https://arxiv.org/abs/2103.00020
代码链接:
https://github.com/OpenAI/CLIP
2.1 Motivation
NLP 领域BERT/GPT 等可以利用大量的语料的数据进行自监督训练从而进行 pretrain,然而 CV 领域是用标注信息的分类数据集进行 pretrain (ImageNet),是否能利用网上大规模的图片信息进行预训练,使用 natural language 作为 image representation 的监督信号,从而提升下游任务的效果。
2.2 Method
1. 利用从互联网爬取的 400 million 个 image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于 30 个现存的计算机视觉——OCR、动作识别、细粒度分类等。
2. 使用对比学习的方法,做图文匹配的任务,计算相似度。给定 batch=N 的 image-text pairs,CLIP 预测 NxN 的概率(利用线性变换得到 multi-modal embedding space 的向量,点乘计算得到相似度),对角线即为正样本,其它都是负样本。
2.3 Contribution
无需利用 ImageNet 的数据进行训练,就可以达到 ResNet-50 在该数据集上有监督训练的结果。

#03.
Frozen

论文标题:
Multimodal Few-Shot Learning with Frozen Language Models
收录会议:
NeurIPS 2021
论文链接:
https://arxiv.org/abs/2106.13884
3.1 Motivation
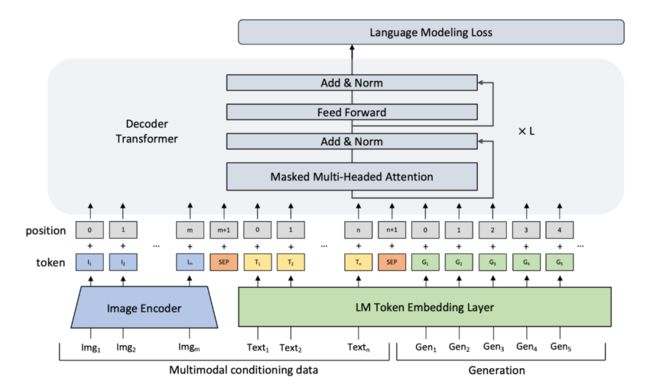
借鉴 NLP 中 prompt 工作,Frozen 可以看成是一种 image conditional 下的 prompt learning,即将连续的 prompt 特征学习变成是来自于图片的特征(由另一个网络训练产生)。探究了固定语言模型参数下如何学习多模态任务。
3.2 Method
Vision Encoder 编码得到图片特征,再映射为 n 个 prompt 向量加到文本表示之前。Language Model 使用了一个 7 billion 参数规模的预训练好的模型;Vision Encoder 使用了 NF-ResNet-50。
3.3 Contribution
通过将 prompt 扩展到有序的图像,将大型语言模型转换为多模态语言模型的方法同时保留语言模型的文本提示能力,在 VQA、OKVQA、miniImageNet 等多个数据集验证了迁移学习的效果。由于 Visiual Encoder 和文本的处理比较简单,模型效果离 SOTA 有一定的距离。

#04.
CoOp

论文标题:
Learning to Prompt for Vision-Language Models
收录会议:
NeurIPS 2021
论文链接:
https://arxiv.org/abs/2109.01134
代码链接:
https://github.com/KaiyangZhou/CoOp
4.1 Motivation
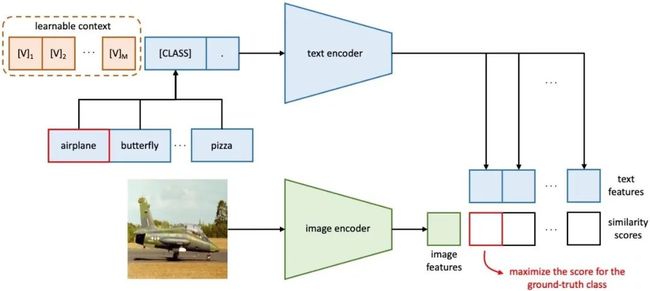
CLIP 中使用的手工 prompt 有两个缺点:1)需要额外的知识和人力来为每个下游任务/数据集设计合适的 prompt,当数据集或者下游任务很多时非常耗时耗力;2)手工 prompt 不太稳定,对某个单词可能很敏感。把 NLP 中离散 token->连续 token 思路引入进来。
4.2 Method
在 class 前面加入一组 prompt 连续向量,续可学的 prompt 具体又可分为 unified context 和 class-specific context (CSC) 两种。实验发现 class-specific context (CSC) 这种类型的 prompt 对细粒度图片分类任务更有用,而在一般的数据集上,unified context 效果更好。
4.3 Contribution
在图片分类任务上的 few-shot learning 设置上,连续 prompts 比 CLIP 中手工定制的 prompt 效果有很大提升。
#05.
MAnTiS

论文标题:
Multimodal Conditionality for Natural Language Generation
论文链接:
https://arxiv.org/abs/2109.01229
5.1 Motivation
将 prompt 方法应用到文案生成。
5.2 Method
image 和 text(即商品 title),分别用 ResNet-152 和 embedding 映射到语言模型的同一个空间中为为 prompt,同时作为条件的文本输入和生成序列一同进行编码,最后再经过 Transformer Decoder 得到输出的描述。
5.3 Contribution
文案生成效果中融入视觉效果,使得生成效果更佳。
#06.
CPT

论文标题:
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
论文链接:
https://arxiv.org/abs/2109.11797
6.1 Motivation
将 prompt 方法应用到 visual grounding 任务上,将任务转化为完形填空问题。
6.2 Method
对图片中的 object 一些被涂上不同颜色的图片,然后把文本当作问题,最后回答什么颜色的图片是问题的答案并填空。
6.3 Contribution
该方法在 visual grounding 任务上 zero/few shot 场景下取得了非常好的表现。

#07.
CLIP-Adapter

论文标题:
CLIP-Adapter: Better Vision-Language Models with Feature Adapters
论文链接:
https://arxiv.org/abs/2110.04544
代码链接:
https://github.com/gaopengcuhk/clip-adapter
7.1 Motivation
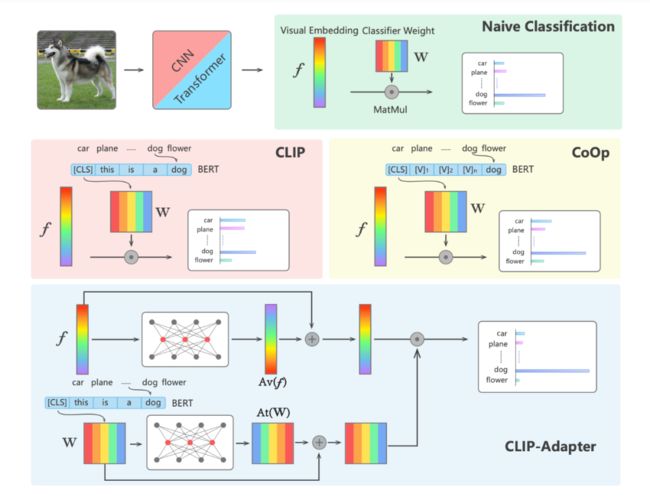
soft prompt 优化的 CoOp,由于 CLIP 的过度参数化和缺乏足够的训练样本,简单的网络调整会导致对特定数据集的过拟合。从而本文只需对轻量级附加特征适配器进行微调,受参数有效迁移学习中适配器模块的启发,作者提出了 CLIP-Adapter,它只调整少量额外权重,而不是优化 CLIP 的所有参数。
7.2 Method
1. CLIP Adapter 仅在视觉或语言主干的最后一层之后添加了两个额外的线性层;相反,原始适配器模块插入到语言主干的所有层中;
2. CLIP Adapter 通过残差连接将原始 Zero-Shot 视觉或语言嵌入与相应的网络调整特征混合。通过这种“残差样式混合”,CLIP Adapter 可以同时利用原始 CLIP 中存储的知识和来自 Few-Shot 训练样本的新学习的知识。
7.3 Contribution
在 11 个数据集上 few-shot 的实验结果,CLIP-Adapter 明显优于 CoOp 和 CLIP。
#08.
DenseCLIP

论文标题:
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
论文链接:
https://arxiv.org/abs/2112.01518
收录会议:
CVPR 2022
代码链接:
https://github.com/raoyongming/denseclip
8.1 Motivation
1. CoOp 中可学的 prompt 是 task-level 或者 class-level 的,不能随着每个输入数据样例的变化而变化,本文设计了 instance-level 的 prompt,即把视觉(图片)特征注入到 prompt 向量中去,所以每个数据对应的 prompt 都是不一样的,引入了数据侧的信息。
2. 从图像-文本对中学习到的知识转移到更复杂的密集预测任务的问题几乎没有被研究(目标检测、语义分割和动作识别等)。在这项工作中,作者通过隐式和显式地利用 CLIP 的预训练的知识,提出了一个新的密集预测框架。
8.2 Method
pre-model prompting:在文本编码器之前将视觉特征和可学习 soft tokens 传递给 Transformer 解码器生成。
prompt post-model prompting:在文本编码器之后将视觉特征和类别向量传递给 Transformer 解码器生成类别向量表示。
8.3 Contribution
提出一个更通用的框架,可以利用从大规模预训练中学到的自然语言先验来改善密集预测。


#09.
PromptFuse

论文标题:
Prompting as Multimodal Fusing
论文链接:
https://openreview.net/pdf?id=wWZCNLkK-FK
9.1 Motivation
对 Frozen 的改进,Frozen 中的 image encoder 同时完成了两个目标:提取视觉特征、对齐图文空间的表示。本文对这两个目标解耦,image encoder 只负责编码图像特征,而对齐图文空间表示的任务交给 prompt 向量来做。这样视觉编码器的参数也变成固定的了,只有 prompt 向量的参数是可训练的。
这样做有两个好处:1)整个架构更加模块化,可以灵活调整视觉编码器,也可以灵活地加入其他模态;2)实现了更高的参数效率,视觉编码器中的大量参数都可以冻结,只需要调整 prompt 向量即可。本文还提出了一种特殊的 attention mask,它迫使 prompt 对所有输入数据都是不可见的,称为 BlindPrompt。
9.2 Method
固定视觉编码器和文本编码器,只更新 prompt 向量。
9.3 Contribution
相比 Fintune 上对于 few-shot 和 full-shot 上有些效果上的提升。

#10.
UniVL

论文标题:
Unified Multimodal Pre-training and Prompt-based Tuning for Vision-Language Understanding and Generation
论文链接:
https://arxiv.org/abs/2112.05587
10.1 Motivation
提出理解与生成统一的多模态预训练,使用 mixing causal mask,下游任务使用 prompt 进行 fintune。
10.2 Method
预训练使用图文对比学习+MLM+图文匹配 loss。
10.3 Contribution
在图文检索 full-shot/zero-shot 相比 UNITER、CLIP 等有所提升,在 Image captioning 和 VQA 上效果也有提升,但是没有达到 SOTA 水平。
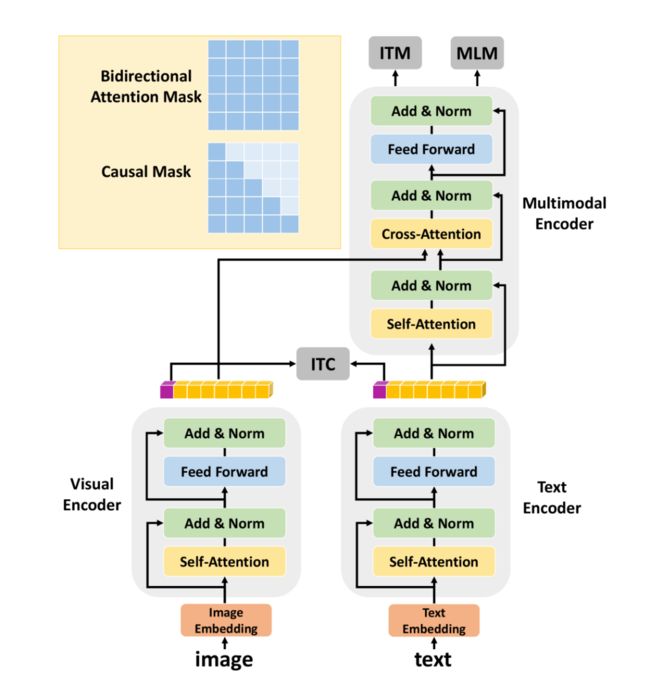
#11.
VL-Adapter

论文标题:
VL-Adapter: Parameter-Efficient Transfer Learning for Vision-and-Language Tasks
论文链接:
https://arxiv.org/abs/2112.06825
11.1 Motivation
在大型文本语料库上预训练的语言模型的微调在视觉和语言(V&L)任务以及纯语言任务上提供了巨大的改进。然而,由于模型规模迅速增长,对预训练模型的整个参数集进行微调变得不切实际。
11.2 Method
将三种流行的基于适配器的方法(Adapter, Hyperformer, Compacter)与标准的完全微调和最近提出的提示微调方法进行比较,应用到多模态任务。
11.3 Contribution
用权重共享技术训练适配器(占总参数的 4.4%)可以与微调整个模型的性能相匹配。

#12.
OFA

论文标题:
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
论文链接:
https://arxiv.org/abs/2202.03052
代码链接:
https://github.com/OFA-Sys/OFA
12.1 Motivation
模态、任务、结构统一的模型 OFA,将多模态及单模态的理解和生成任务统一到 1 个简单的 Seq2Seq 生成式框架中,OFA 执行预训练并使用任务 instruction/prompt 进行微调,并且没有引入额外的任务特定层进行微调。
12.2 Method
统一模态:统一图片、视频、文本的多模态输入形式;统一结构:采取统一采用 Seq2Seq 生成式框架;统一任务:对不同任务人工设计了 8 种任务指令。
12.3 Contribution
OFA 覆盖的下游任务横跨多模态生成、多模态理解、图片分类、自然语言理解、文本生成等多个场景,在图文描述、图像生成、视觉问答、图文推理、物体定位等多个风格各异的任务上取得 SOTA。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
