增强领域的知识图谱
以下是一些近两年基于知识图谱做知识增强的顶会论文:
-
"knowledge-enhanced hierarchical graph convolutional networks for intent detection" (acl 2021)
-
"kg-bert: bert for knowledge graph completion" (emnlp 2019)
-
"k-adapter: infusing knowledge into pre-trained models with adapters" (acl 2020)
-
"coke: contextualized knowledge graph embedding" (emnlp 2020)
-
"knowledge-aware language model pretraining" (acl 2020)
知识图谱推理
是通过将不同的实体和关系建立成一个网络结构,然后利用这个网络结构中的已知信息推导得到未知信息的过程。在知识图谱中,每个实体都以节点的形式存在,而实体之间的关系则以边的形式表示。
知识图谱推理包括三种类型:基于实例的推理、基于分类的推理和基于相似度的推理。其中,基于实例的推理是指根据已知的实例进行推理,比如从一组具有相似特征的实例中推断出新的实例;基于分类的推理是指根据知识图谱中实体所属的分类进行推理,比如根据物种分类推断出某个物种的特征;基于相似度的推理是指根据实体之间的相似性进行推理,比如根据两个实体的相似特征预测它们之间的关系。
知识图谱推理的具体过程是利用已知的实体和关系,通过逻辑推理、机器学习等方法,找到其中的规律和潜在的隐藏信息。在推理过程中,还可以使用一些领域专业知识、语义分析技术等手段对推理结果进行优化和调整。
信息抽取
信息抽取(information extraction)是自然语言处理(nlp)领域的一个重要任务,指从自然语言文本中自动地抽取出具有特定意义的结构化信息,并将其转化为计算机可处理的形式。信息抽取可以帮助人们自动化地处理海量的非结构化数据,从中挖掘出有价值的信息,以支持决策和分析等任务。信息抽取的主要任务包括实体识别(entity recognition)、关系抽取(relation extraction)和事件提取(event extraction)等。实体识别指识别文本中所涉及的具体对象,如人、地点、组织机构等;关系抽取则指识别实体间的语义关系,比如某个人是某个公司的雇员;事件提取则指从文本中抽取出特定类型的事件,比如**会议或自然灾害等。
基于数据增强的领域知识图谱构建方法研究
将对已标注的训练数据进行数据增强来提升信息抽取的效果,传统的数据增强方法包括同义词替换、随机插入、随机交换和随机删除,但领域知识往往包含大量专业词汇,结构固定,传统数据增强方法并不适用,因此,本文引入迁移学习思想进行数据增强的研究。迁移学习是指将从之前训练任务中学到的知识应用到新的训练任务中,主要分为样本迁移、特征迁移、模型迁移和关系迁移。其中,特征迁移可以在文本特征分布相似的情况下,借助历史标记数据以解决目标项目训练实例过少的问题。本文选取的数据为新能源汽车电池技术领域的专利文本,具有领域分支少、文法结构相似等特点,通过特征迁移的方法对人工标注的少量样本数据进行数据增强,提升信息抽取模型訓练效果。
信息抽取模型主要分为文本的多维向量映射和语义特征提取两个方面。文本的多维向量映射即文本的语义表示,传统的语义表示方法,例如Onehot、Word2vec、Glove等,使用一个词向量对应一个词语,包含的语义信息有限;现阶段使用较多的是预训练模型,例如EMLo预训练模型和BERT预训练模型,能够表达出词语在不同语境下的语义信息。预训练模型通过对大量语料进行无监督学习来获取丰富的语义特征,相比于EMLo模型,BERT将模型结构由LSTM更改为Transformer,解决了长依赖的问题,并通过遮蔽语言模型(MaskedLan⁃guageModel,MLM)和下一句预测(NextSentencePrediction,NSP)两种预训练任务,分别从预测遮盖词和预测下一句两个方面学习文本的语法、语义及句间关系。
信息抽取模型抽取出信息主要分为主体词集合、关系词集合以及客体词集合3类,分别映射到知识图谱(S,P,O)三元组的表示形式中,候选三元组由主体词、关系词及客体词的随机组合形成,三元组数据是图谱构建的基础。因此,图谱构建模型的关键在于去除候选三元组的噪声数据,识别语义正确的三元组,也可以看作对三元组和专利文本的语义匹配。本文将候选三元组和对应的专利文本语句组合成一个长句子,利用预训练模型和双向长短记忆神经网络模型进行语义解析,为减少长序列文本在解码过程中上下文信息、位置信息丢失问题的影响,本文加入注意力机制来增强重要字词的权重,优化模型,提升模型的准确率。
K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters
现有方法通常在注入知识时更新预训练模型的原始参数。然而,当多种知识被注入时,历史上注入的知识就会被冲掉。为了解决这个问题,我们提出了KADAPTER,这是一个框架,它保留了预训练模型的原始参数,并支持开发通用的知识注入模型。K-ADAPTER以RoBERTa为骨干模型,每种注入的知识都有一个神经适配器,就像一个连接RoBERTa的插件。不同适配器之间没有信息流,因此可以以分布式的方式有效地训练多个适配器。在这项工作中注入了两种知识,包括(1)从Wikipedia和Wikidata上自动对齐的文本三元组获得的事实知识,以及(2)通过依赖句法分析获得的语言知识。
无监督的方式学习的模型很难捕获丰富的知识。例如,Poerner等人(2019)认为,尽管语言模型在推理实体名称的表面形式方面表现良好,但它们无法捕捉丰富的事实知识。Kassner和Schutze¨(2019)观察到BERT大多没有学习否定的含义(例如“not”)。这些观察激励我们研究将知识注入预先训练的模型,如BERT和RoBERTa。以前的大多数工作(如表1所示)都用知识驱动的目标扩充了标准语言建模目标,并更新了整个模型参数。尽管这些方法在下游任务中获得了更好的性能,但它们在支持注入多种知识的通用模型的开发方面存在困难(Kirkpatrick et al, 2017)。当新类型的知识被注入时,模型参数需要重新训练,以便以前注入的知识会逐渐消失。同时,所得到的模型产生了纠缠的表示,因此很难研究每种知识的效果。
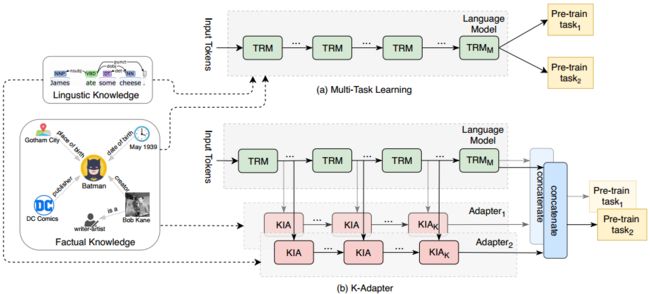
(a)预训练语言模型通过多任务学习注入多种知识。(2)我们的K-ADAPTER通过在不同的预训练任务上独立训练适配器来注入多种知识,支持持续的知识注入。当我们注入新的知识种类时,现有的特定于知识的适配器将不会受到影响。KIA表示适配器层,TRM表示变压器层,两者如图2所示。
第一,我们考虑了事实相关的目标(即谓词/关系预测)和语言相关的目标(即依赖关系预测)。其次,在知识灌输过程中钳制BERT的原有参数。第三,我们的方法支持持续学习,这意味着不同适配器的学习不会纠缠在一起。这种灵活性使我们能够有效地独立注入不同类型的知识,并且在不损失之前注入的知识的情况下注入更多类型的知识 。
如图1 (a)所示,之前的大部分工作都是通过多任务学习,通过注入知识和更新模型参数来增强预训练的语言模型。不管这些不同版本的多任务学习知识注入方法,没有充分研究的常见问题是对先前知识的灾难性遗忘。为了解决这个问题,我们提出了如图1(b)所示的KADAPTER,其中将多种知识分别注入到不同的紧凑神经模型(即本文中的适配器)中,而不是直接将知识注入到预训练的模型中。它保持预训练模型的原始表示固定,并支持持续的知识注入,即将每种知识注入到相应的知识特定适配器中,并产生解纠缠的表示。具体来说,适配器是插入预训练模型之外的特定于知识的模型(具有很少的参数)。适配器的输入是预训练模型中间层的输出隐藏状态。每个适配器被独立地预训练,用于注入不同的鉴别知识,而预训练模型的原始参数被冻结。在本文中,我们利用RoBERTa (Liu et al, 2019)作为预训练模型,主要将事实知识和语言知识注入两种适配器,即事实适配器和语言适配器,分别在关系分类任务和依赖关系预测任务上进行预训练。在本节中,我们首先描述适配器的结构,然后介绍预训练特定于知识的适配器的过程。

特定于知识的适配器
适配器作为外部插件工作。每个适配器模型由K个适配器层组成,其中包含N个变压器(Vaswani等,2017)层和两个投影层。跳过连接应用于两个投影层。
预训练模型的不同变压器层之间的适配器层。我们将预训练模型中变压器层的输出隐藏特征和前适配器层的输出特征连接起来,作为当前适配器层的输入特征。对于每个特定于知识的适配器,我们将预训练模型和适配器的最后一个隐藏特征连接起来,作为该适配器模型的最终输出特征。
在预训练过程中,我们对每个特定于知识的适配器分别进行不同的预训练任务的训练。对于各种下游任务,K-ADAPTER可以采用类似RoBERTa和BERT的微调过程。当只采用一个特定于知识的适配器时,我们可以将该适配器模型的最终输出特征作为下游任务特定于任务的层的输入。当采用多个特定于知识的适配器时,我们将不同适配器模型的输出特征连接起来,作为下游任务特定于任务的层的输入。