深度剖析Spring循环依赖原理,看不懂算我输
最近偶然看到了Spring循环依赖这个知识点,于是就顺便研究了一下,不研究不知道,一研究发现在某些点上竟然存在着各种各样的说法。
于是通过查找各种资料以及看源码,基本上了解了大概原理。
所以从以下几个方面记录下(忍不住吐个槽:现在网上文章真是胡乱抄啊,很多丝毫没有自己的思考)
一. 什么是循环依赖?
在面向对象的编程语言中可以说对象是代码的基本单位。
如果把一个软件比作一台机器,那么就可以把对象看作是一个个零件。
对于一整台机器来说。
零件和零件之间是相互合作相互依赖的,如果依赖过程中出现了环状结构的依赖,就叫做循环依赖。
如下所示:
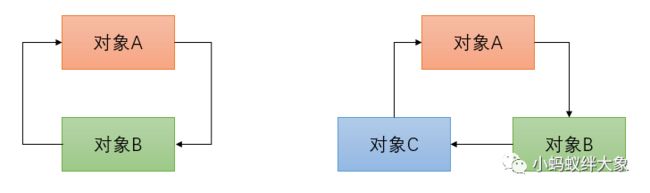
以两个对象循环依赖为例,代码如下所示:
@Service
public class ClassA {
@Resource
private ClassB classB;
private void doXXX(){
//do something
classB.doXXX();
//do something
}
}
@Service
public class ClassB {
@Resource
private ClassA classA;
private void doXXX(){
//do something
classA.doXXX();
//do something
}
}二. 循环依赖会出现什么问题?
1. 单个对象无依赖
首先看下如果一个对象没有依赖其他对象。
那么从Spring第一次获取这个对象的时候。
Spring是怎么创建对象的。

实例化:可以理解为通过反射创建对象的动作
填充属性值:可以理解为通过setter方法为对象的属性赋值
初始化:就是调用对象的初始化方法,如init-method配置的方法,BeanProcessor的前置和后置处理方法对对象做进一步处理
比如如下类:
@Service
public class Single {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}Spring在实例化的时候首先会得到该类的类对象。
然后用反射实例化出对象,接着调用setName方法设置name。
最后调用初始化方法对对象进行初始化。
然后注册到容器中供需要的地方直接调用。
2. 多个对象无循环依赖
看了上面对象的情况后可能心中就会有一个疑问。
如果对象中的属性引用的是一个对象,填充属性的时候发现依赖的对象还没有。
那Spring怎么创建对象呢?
比如如下代码:
@Service
public class A {
@Resource
private B b;
private void doXXX(){
b.doXXX();
}
}
@Service
public class B {
private void doXXX(){
//do something
}
}创建流程如下:
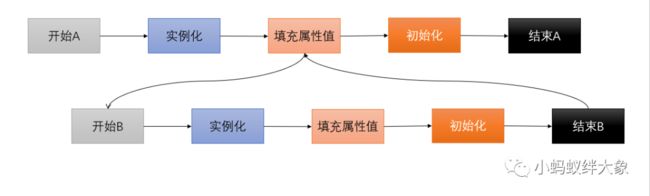
也就是设置属性的时候发现属性所引用的对象没有实例。
那么就会先去创建所引用对象的实例。
创建完之后完成属性设置,然后走下面的流程。
3. 多个对象有循环依赖
看了上面的情况,相信就很容易发现循环依赖所引发的问题了。
那就以以下代码走下流程。
@Service
public class ClassA {
@Resource
private ClassB classB;
private void doXXX(){
//do something
classB.doXXX();
//do something
}
}
@Service
public class ClassB {
@Resource
private ClassA classA;
private void doXXX(){
//do something
classA.doXXX();
//do something
}
}假如此时要获取ClassA对象,那么会有以下步骤:
-
先通过反射实例化ClassA
-
给ClassA对象填充属性值
-
发现ClassA的属性是ClassB对象的引用,而此时Spring容器中并没有ClassB对象
-
所以就会先去实例化ClassB
-
完了接着给ClassB设置属性值
-
但是这时候就发现ClassB的属性是ClassA对象的引用,而ClassA还没有创建好
-
然后就会再次从步骤1开始,无限重复的执行以上过程
这就是所说的循环依赖引发的问题。
但是我们稍微想一下,其实也很容易想出解决方案。
比如给ClassB设置属性的时候,其实ClassA已经执行了实例化操作,只是还没有填充完属性值而已。
所以如果此时把半成品ClassA直接给ClassB的属性。
不就可以打破这个循环,完成两个对象的实例化吗。
Spring的方案的核心思想正是如此。
三. Spring是怎么解决循环依赖问题的呢?
这个相信很多人都熟,准备面试的时候谁还不复习一遍这个知识点呢 哈哈。
还以ClassA和ClassB为例来整一遍流程。
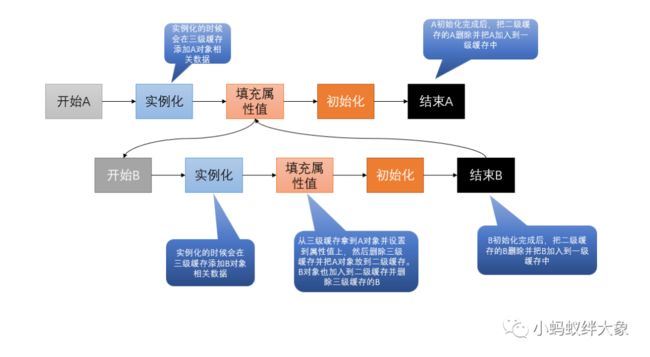
首先明确一点:三级缓存其实就是三个Map
一级缓存:存放的是实例化并初始化完成的对象实例
二级缓存:存放的是实例化完成但是初始化没有完成的实例
三级缓存:存放的是创建对象的工厂类。可以理解为是一段创建对象的逻辑,调用这段逻辑可以创建一个对象
所以如上图所示要获取ClassA对象,会经历以下步骤:
-
实例化ClassA对象,此时还会把创建A对象的工厂放入三级缓存
-
给ClassA对象填充属性
-
发现ClassA的属性是ClassB对象的引用,而此时Spring容器中并没有ClassB对象
-
所以就会先去实例化ClassB,这个时候也会把创建B对象的工厂放入三级缓存
-
给ClassB的属性填充值,此时就会从三级缓存中把ClassA设置进去的工厂拿出来并执行,生成ClassA的对象。把ClassA的三级缓存删除并加入到二级缓存。把ClassB的三级缓存也删除,加入到二级缓存中
-
完成ClassB的初始化,并把ClassB对象加入到一级缓存,二级缓存删除
-
ClassA此时就可以正常的填充属性值了,因为ClassB已经初始化完成
-
ClassA初始化完成并把ClassA添加到一级缓存中,删除二级缓存
这样循环依赖的问题就解决了,两个对象都完成了实例化(标红的是缓存操作)
四. 关于循环依赖原理相关的疑问(这才是文章精华)
说实话以上原理很多人估计都知道。
但是我当时了解到上述原理的时候,内心是充满很多问号的。比如:
1. 上面的第一步说实例化了ClassA。然后第五步又通过工厂实例化了ClassA,这是干啥呢,玩呢?
其实第五步通过工厂实例化的是代理类对象。
在有循环依赖并有AOP逻辑的场景下。
设置属性值的时候因为设置的是半成品对象,还来不及生成代理对象(具体原理下面会提及)。
所以就需要提前生成代理对象,也就是第五步的实例化。
因为第一步不知道该对象存在循环依赖,所以第一步先实例化了一次。
但是最终第五步的实例化对象会赋值给属性。
2. 没看懂三级缓存是干啥的,直接存对象不行吗,有啥意义吗?
其实这就涉及到有AOP逻辑的时候,两个创建对象流程的问题了。
流程一:没有循环依赖的创建对象的流程是。
先实例化,然后设置属性值,然后初始化。
在初始化的后置处理方法中会有逻辑利用动态代理的方式把AOP的增强代码组合到代理类中。
此流程根本用不到三级缓存。
流程二: 当有循环依赖的时候。
我们会发现在设置属性的时候就需要把半成品的对象设置进去。
此时因为没有到初始化阶段,当然半成品的对象就不能像流程一那样走到动态代理逻辑。
就因为这。
所以把动态代理逻辑给前置了。
也就是当设置属性的时候,就从三级缓存拿到创建对象的工厂,调用后就会生成一个代理类。
而第一步创建实例的引用此时就会引用这个代理类。
总结一下:也就是说三级缓存的出现就是为了解决半成品对象提前被使用,但是代理类还没有生成的问题的。
3. 不就是存一下半成品的对象吗,有必要弄三个缓存吗?一个不行?两个足够了吧?
如果是单纯的解决循环依赖的问题(其他啥也不管,就解决依赖的事)!
那其实用一个缓存或者两个缓存都行。
用一个缓存的流程:
-
先实例化ClassA,并把ClassA的代理对象生成出来放入缓存中(如果有代理缓存中存代理对象,没有代理就存原始对象)
-
给ClassA对象填充属性
-
发现ClassA的属性是ClassB对象的引用,而此时Spring容器中并没有ClassB对象
-
所以就会先去实例化ClassB,并把ClassB的代理对象生成出来放入缓存中
-
然后从缓存中拿到ClassA的对象,设置到ClassB属性上
-
ClassB初始化完成
-
给ClassA对象属性赋值
-
ClassA初始化完成
可以看到一个缓存照样可以解决循环依赖的问题,两个对象都能实例化出来。
但是此时我就会又有两个疑问:
3.1 如果在ClassA把半成品对象放入缓存后,另一个地方也要用这个对象,直接从缓存拿出来了怎么办?
其实对于这个问题在大部分对象上可能发生的概率不大。
如果非要解决。
那么可以加锁的方式,在对象创建完成之前不允许获取对象。
3.2 如果是这个流程,那就意味着实例化的时候就要生成代理对象并放入缓存,这可就和原来的非循环依赖流程不一样了。
对于这个问题。
我个人认为就有点偏设计思路方面的问题了。
如果是我的话,不到万不得已,我是绝对不会改变原流程的。
用两个缓存的流程:
其实和上面差不多。
只是可以把半成品对象放入二级缓存,创建完成的对象放入一级缓存。
这样就不会出现用一个缓存时候的问题1。
但是问题2依然存在。
具体可以自己串下流程。
4. 这三个缓存到底有啥用啊,难道就只是为了解决循环依赖问题?
准确的来说二级缓存和三级缓存就是为了解决循环依赖问题而存在的。
但是一级缓存不是!
| 缓存级别 |
缓存内容 | 作用 |
| 一级缓存 | 创建完成的对象 |
|
| 二级缓存 | 半成品对象(执行三级缓存的逻辑生成的对象) | 保证代理对象的唯一性,比如对象A依赖B和C,并且B和C都依赖A,那么如果没有二级缓存的话。B,C两个可能会调用两次三级缓存中的逻辑生成对象,也就生成了两个代理对象。当然最终目的也是为了和三级缓存配合解决循环依赖问题。 |
| 三级缓存 | 创建代理对象的工厂 | 三级缓存的存在其实就是因为Spring的开发者不想要改变原来的生成代理对象的流程(在初始化阶段生成代理对象),而为解决循环依赖问题加的一个补丁,所以如果没有循环依赖的时候用不到三级缓存,自然也就用不到二级缓存。但是一旦有了循环依赖,就利用二级和三级提前生成代理对象。 |
小思考题:
在Spring中有singleton和prototype类型的对象。
注入方式也有setter注入和构造方法注入。
那么Spring可以解决哪些情况下的循环依赖问题呢?为什么?
同名公众号【小蚂蚁绊大象】,更多内容持续输出中