多模态大模型的发展、挑战与应用
多模态大模型的发展、挑战与应用
2023/04/15
研究进展
随着 AlexNet [1] 的出现,过去十年里深度学习得到了快速的发展,而卷积神经网络也从 AlexNet 逐步发展到了 VGG [2]、ResNet [3]、DenseNet [4]、HRNet [5] 等更深的网络结构。研究者们发现,网络越深模型的性能越好。然而,经过多年的发展,研究者们逐渐触碰到了卷积神经网络的极限,而其规模也只发展到了千万到亿的数量级,例如 ResNet-152 的参数量大约为 60 Million (M),HRNet_W64 大约为 128M。2017 年,谷歌首次提出了 Transformer [6] 架构,并在自然语言、视觉等多个领域得到了广泛的应用。
自然语言领域
在自然语言领域,谷歌提出了基于自监督学习的语言模型 BERT [7],利用少量的训练数据进行微调后在多个下游任务上取得了革命性的性能提升。随后,OpenAI 也提出了 GPT-1/2/3 语言模型 [8–10]。值得一提的是,GPT-3 [10] 的参数量已经达到 175 Billion (B),这已经比 HRNet_W64 高出 3 个数量级。特别地,2022 年 11 月,他们公布了 ChatGPT [11] 大模型,通过在 GPT-3 的升级版本 GPT-3.5 上添加人类反馈强化学习 (RLHF) 的微调机制,极大地提升了模型的性能。由于其在聊天、检索等多个领域上的出色表现,ChatGPT 吸引了全球广泛的关注,并开启了大模型研究的新时代。今年 3 月份,他们通过进一步添加图像输入,提出了 GPT-4 [12] 大模型,这也标志这 GPT 家族从单一的语言大模型跨入到多模态大模型。此外,2022 年,Meta 也发布了他们的语言大模型 OPT [13],参数量跟 GPT-3 一致,达到了 175B。值得一提的是,他们将代码和模型进行了开源,并详细公布了整个训练过程中遇到的问题日志,极大地促进了大模型的落地。2022 年 4 月,谷歌提出语言大模型 PaLM [14],参数量达到 540B,训练过程中使用了 6144 个 TPUs。在国内,2021 年,百度提出参数量为 10B 的中文语言大模型 ERNIE 3.0 [15]。并进一步提出更大参数规模的 ERNIE 3.0 Titan [16],参数量达到 260B。此外,华为提出中文语言大模型“PanGu-”[17],其参数量达到 200B。今年 3 月,华为进一步推出中文语言大模型“PanGu-Σ”[18],其参数量已经达到惊人的 1.085 Trillion (T)。
图像领域
2021 年,谷歌提出视觉 Transformer (ViT) [19],他们将图片处理成一系列图像补丁并送入 Transformer 结构,完成图像的分类任务。并在物体检测、语义分割、视频理解等多个图像处理任务上取得 SOTA 性能。随后,MSRA 提出了 Swin Transformer [20],通过采用滑动窗口来实现一种层级 Transformer 结构。在图像预训练方向,Meta 何凯明提出了著名的 MAE [21] 预训练策略。通过先掩盖大面积的图像内容再重建的方式,实现了对图像的表征学习。随后,该工作被大量研究者进行了进一步的研究与拓展。今年 2 月,谷歌进一步将 ViT 的参数量扩增到 22B,提出了 ViT-22B [22]。此外,针对分割任务,Meta 提出了分割一切模型(SAM) [23],利用大模型编码器、大量数据以及多种有效的 prompt,在分割任务上展现出了惊人的性能,且泛化性能比已有的方法都更加优秀。
多模态领域
顾名思义,多模态大模型是指模型中涉及到了两种及其以上的模态信息。目前,大多数的多模态模型只涉及了文本和图像两种模态。根据两种模态在模型上的位置可以将这些多模态模型分为:文生图模型、图生文模型、以及图文模型。
对于文生图大模型,即模型根据用户提供的文本生成对应的图像。在扩散模型 (Diffusion model) 被提出来之前,GAN-based 模型一直是图像生成的主要模型。由于扩散模型在图像生成方面的优秀表现,已经成为了目前主流的图像生成框架。基于扩散模型,OpenAI 提出了参数量为 3.5B 的 GLIDE [24] 模型和 DALL-E2 [25] 模型。此外,德国海德堡大学提出了参数量为 1.45B 的 Stable Diffusion [26] 模型,以及谷歌提出的参数量为 2B 的 Imagen [27] 模型。
对于图生文大模型,与文生图相反,即模型根据用户提供的图像生成对应的文本,其广泛应用在 OCR 领域。除了简单地从图像中提取文字,更具有挑战的是理解输入的图片,并提供相对应的文本解释。2022 年,微软提出了参数量为 0.7B 的 GIT [28] 模型。最近,OpenAI 公布的 GPT-4 [12] 大模型,也可以将图像作为输入,而模型输出对应的文本解释。
对于图文大模型,一般是指将图像和文本一起输入模型中,其广泛应用于视觉-语言预训练任务中。与单一的语言、视觉预训练不同,多模态联合的预训练可以为模型提供更加丰富的信息,从而提升模型的学习能力。视觉-语言预训练任务中代表作是 2021 年 OpenAI 提出的 CLIP [29] 模型。通过一个图像编码器和一个文本编码器分布从图像和文本中提取特征,然后利用对比学习实现两个编码器的训练。类似地,谷歌提出基于噪声文本监督的 ALIGN [30] 模型。2022 年,Salesforce 进一步提出 BLIP [31] 模型。针对带有噪声的文本数据,设计一个 Captioner 来合成文本,和一个 Filter 来过滤掉带有噪声的本文。但这些多模态预训练模型的参数量都偏小,也没有达到 Billion 的量级。2022 年,微软提出了参数量为 1.9B 的视觉-语言预训练大模型 BEiT [32]。进一步地,谷歌提出了参数量高达 17B 的大模型 PaLI [33],模型输入图片和文本,输出为文本。除了在预训练任务中,视觉-语言模型也会应用在分割任务中,例如 SAM [23],将文本当做一种 prompt 作为模型的输入,可以提升图像中的物体分割准确率。进一步地,谷歌通过结合语言大模型 PaLM [14] 和视觉大模型 ViT-22B [22] 提出了多模态大模型 PaLM-E [34],是目前拥有最大参数量的多模态大模型,其参数量达到 562B。它不仅可以理解图像,还能理解、生成语言,执行各种复杂的机器人指令而无需重新训练。此外,多模态大模型也被逐渐应用在机器人控制 (RT-1 [35]、ChatGPT for Robotics [36])、导航 (LM-Nav [37]) 等领域。
虽然 ChatGPT 在设计之初是为了实现具有人工智能的对话机器人,但随着研究的进行,人们发现 ChatGPT 可以干更多的事情,甚至带来商业价值。除了简单的文字修改与润色,微软将 ChatGPT 应用在搜索引擎 (New Bing) 上,实现更加智能和精准的搜索。随后,将 ChatGPT 与办公软件 office 相结合提出 Copilot,将 ChatGPT 变成工作中的一个 AI 助手,极大地提高了人们的工作生产力。正是因为微软成功地对 ChatGPT 的充分挖掘和利用,让更多的研究者和公司意识到了大模型的强大能力,也促进了这次大模型革命。受到 ChatGPT 的启发,国内各大公司也纷纷进入大模型浪潮。并计划将大模型应用在教育、医疗、人机交互、办公、翻译、工业等多个行业领域中去。今年 3 月,百度提出了自己的大模型“文心一言” 。4 月,阿里云推出了他们的大模型“通义千问” ,并计划未来将阿里巴巴所有产品接入该大模型。同期,商汤也推出了他们的“日日新 SenseNova”大模型 ,其主要包括自然语言生成、文生图、感知模型标注、以及模型研发功能。此外,其他公司,例如科大讯飞 (1+N 认知智能大模型)、昆仑万维 (天工)、知乎 (知海图 AI)、毫末智行 (雪湖·海若)、澜舟科技 (孟子) 等;以及研究院,例如北京智源研究院(悟道) 等,都将逐步推出并启用自己的大模型。
如表1所示,总结了前面所提及的不同领域下的大模型。
多模态大模型的挑战
计算资源
算力是每个研究机构和公司进入大模型浪潮的“入场券”。以 Meta 的 OPT-175B 为例,他们在训练过程中使用了 992 张显存为 80G 的 NVIDIA A100 GPUs。而谷歌的 PaLM-540B,甚至使用了 6144 张 TPUs。这都充分证明了训练一个大模型需要足够的算力支持。国内许多公司也在积极构建属于自己的云计算平台,例如阿里云、百度云、华为云、腾讯云等等。特别地,4 月 14 号,腾讯云发布了新一代 HCC 高性能计算集群,搭载了 NVIDIA H800 Tensor Core GPU。因此,构建一个高性能计算集群是进行大模型训练的必经之路。
在计算资源有限的情况下又该如何面对大模型的浪潮呢?主要有两个应对策略:
1)参数高效的大模型微调 (Parameter Efficient Fine Tuning, PEFT)。 即将训练好的大模型的参数固定住,通过添加少量的可学习参数在特定的任务上进行微调。其中著名的是 Adapter [38,39],将其插入到训练好的 Transformer 结构中,可以通过少数参数量的学习而充分利用大模型的性能。
2)预训练模型的下游应用。 即直接应用大模型的预测结果作为一种先验或者指导来提升自己模型的性能。例如在 CLIP [29] 被提出来后,就有很多工作在 CLIP 的基础上进行研究。或者,利用文生图的方式,来合成大量的图像-文本对用于对训练数据的扩充 [40]。以及利用训练好的多模态大模型进行人机交互设计等等。
数据
数据作为大模型训练过程中的关键一部分,其质量很大程度上确定了大模型的最终性能。由于数据版权、隐私性等问题,导致大量的数据获取是困难的。特别是在多模态的条件下,获取配对的多模态数据往往更加困难。这不仅是对多模态数据获取设备的考验,也是对公司经济能力的考验。如何获取大量的数据主要有三种应对策略:
1)搭建虚拟系统。 利用游戏引擎(例如 GTA5),通过对真实世界的模拟,可以构建一套完整的虚拟世界,然后将大模型应用在该系统中可以实现无人车/机的训练。该系统不局限于无人车/机的感知训练,其决策、导航等能力都可以得到训练。
2)从互联网上进行爬取。 已有的图像-文本预训练模型 CLIP [29]、ALIGN [30]、BLIP [31] 等,都采用了从互联网爬取配对的图像-文本数据。通过算法的设计,实现对噪声数据的清洗可以提升模型的性能。
3)利用优秀的生成模型来合成大量的图像、文本等数据。 最近,香港大学和字节跳动利用文本到图像的生成模型(GLIDE [24])来生成大量的合成图像,然后利用这些合成数据来促进图像识别任务和大模型预训练 [40]。
虽然通过生成模型可以一定程度上解决数据量的问题,但仍然面临几个问题:
a)生成数据的质量以及保真度;
b)生成数据的多样性;
c)生成数据与真实应用场景之间的域差异。由于这些问题的存在,完全依赖合成数据将会对模型的泛化性、稳定性、安全性方面产生一定的影响。
因此,目前针对数据的解决办法是合成数据和人工标注数据相结合:
a)先在大量的合成数据上进行大模型的预训练,再利用少量的特定场景和任务下的标注数据进行微调,来促进大模型在特定场景下的性能和稳定性;
b)合成数据和标注数据在训练过程中同时使用,即半监督、域自适应训练策略。
算法
算法的设计也对多模态大模型的性能有着重要的影响。特别是针对多种模态信息作为输入的情况下,算法设计层面存在两方面的挑战:
1)如何高效地提取各个模态的特征?
2)如何高效的融合各个模态的特征?
这些问题都是值得研究的课题。目前针对图像和文本模态,都有较多的算法和网络结构被提出来提取它们的特征。但针对其他模态,例如点云,如何设计 Transformer 结构来进行高效的特征提取,目前的研究还相对较少。此外,如何将多个模态的特征进行高效地融合,也是一个值得被研究的课题。针对自动驾驶中的多模态问题,文献 [41] 进行了充分的讨论。
更多的模态
目前的多模态大模型都主要针对图像和文本模态而设计。然而,在无人车/机的场景下,激光雷达(LiDAR)提供的点云模态中包含丰富的空间和深度信息,如何将该模态整合到多模态大模型中也是一个缺乏探索的课题。该方向面临的挑战主要有两方面:
1)大量配对的图像-点云数据的采集;
2)点云数据的特征提取,以及与其他模态特征的高效融合。
训练技巧
目前多模态大模型的参数量轻易地达到几十甚至几百 Billion,各大公司之间公布的大模型参数量甚至形成了竞争状态,越大的模型就越能体现公司的经济实力与工程能力。首先,如何在几百张显卡上训练如此规模的大模型? 这需要专业的集群调度人员,充分利用计算资源,可以实现资源的充分利用并极大地缩短训练时间。从 Meta 公布的 OPT [13] 训练日志中可以看出,训练一次上百 Billion 的大模型不是一件轻松的事情,中间可能面临着多次 loss 不收敛和训练中断的情况,如何针对训练中断等特殊情况做出针对性的设计? 这对工程师的工程能力有着一定的考验。此外,如何对如此规模的大模型进行超参调整? 如果每次都完整地训练整个大模型,这在时间和经济上的开销都是不可承担的。而在小模型上做的消融实验又不能直接应用在大模型上。从 GPT-4 [12] 的技术报告中可以发现,针对这个问题他们提出了一种可预测的扩展性 (Predictable scaling) 策略。即利用小模型上预测的结果来准确地推测出对应大模型的性能,但他们并没有公布该策略的具体实现。因此,我们如何实现该策略是一个值得被讨论的问题。
部署
当大模型被训练好后,如何将大模型部署在移动终端上呢?直接在终端上部署大模型的方式在算力和存储方面都是无法实现的。目前主流的部署方式有两种:
1)云计算。 将大模型部署在云端,终端只进行极少部分的运算,而大量的计算都在云端进行,然后再计算的结果传回终端。该方案的难点是云计算的构建以及传输的带宽。随着 5G 网络的出现,带宽会得到进一步地解决。但在面对没有联网的情况下,该方式将直接失效。
2)大模型指导小模型。 利用量化、蒸馏等手段将大模型学习的知识与性能迁移到小模型上。然后,将小模型部署在移动终端上。该方式的难点是如何更好地进行知识迁移,即小模型上的性能保证。
推理时间
由于其大规模的参数量,大模型的计算量也是非常高的。在算力一定的情况下,如何缩短大模型的推理时间,甚至实现实时推理是目前的一个研究挑战。针对该问题,将训练好的大模型在推理阶段进行量化和剪枝处理是必要的。特别地,针对特定的任务启用对应的参数运算而关闭无关的参数运算也可以极大地提升多模态大模型的推理速度。
多模态大模型在无人机上的应用
由于多模态大模型其卓越的性能表现,除了目前在图像生成、文档处理、搜索引擎等领域上的应用,多模态大模型也将在人机交互、自动驾驶、物流配送等领域得到进一步的应用。如图1所示,多模态大模型在智能终端上的应用范式将会是:1)用户提供语言或者文本指令;2)利用用户提供的指令以及当前采集的多模态感知数据(图像和点云等)作为输入,多模态大模型为智能终端提供行为规划;3)智能终端根据大模型的输出做出对应的行为动作,并采集下一状态的感知数据; 4)通过将新状态下的感知数据输入到多模态大模型,大模型又对应的做出新的行为规划。如此循环,智能终端可以在多模态大模型的指导下完成整个任务。特别地,对于用户提供的语言或文本指令,可以只在开始阶段介入,也可以在任务执行过程中进行人为的干预。

图1: 多模态大模型在智能终端上的应用范式。
结合点云等更多的模态
正如前文所述,目前的多模态大模型只考虑了图像、文本的输入。如果能将点云模态信息作为输入,将极大地提升多模态大模型在自动驾驶以及无人机等应用领域的稳定性和安全性。
路径规划及导航
2022 年,谷歌提出第一个应用大模型进行机器人导航的工作 LM-Nav [37]。如图2所示,该系统完全由预先训练的导航 (ViNG [42])、图像-语言关联 (CLIP [29]) 和语言建模 (GPT-3 [10]) 模型构建,而不需要任何微调或语言注释的机器人数据。该工作实现了多模态大模型在机器人导航任务上成功应用,这也证明了多模态大模型可以应用在无人驾驶以及无人机的路径规划及导航任务上。
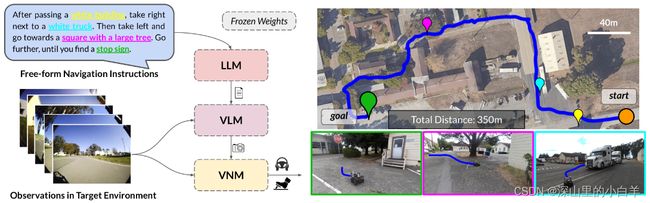
图2: 多模态大模型 LM-Nav 在机器人导航上的应用 [37]。
感知
最近,随着 SAM [23] 模型的提出,证明了大模型在分割任务上优秀的性能表现、以及广泛的通用性。紧接着,北京智源研究院提出了 SegGPT [43],实现利用上下文来分割图像中的所有内容。进一步地,国际数字经济研究院 (IDEA) 将 SAM [23] 和 Grounding DINO [44]、BLIP [31]、Stable Diffusion [26] 集成在一起提出了 Grounded-SAM4,实现大模型分割、检测和生成三种能力的统一。通过这些成功的例子可以看出,将多模态大模型应用在无人机的感知系统上是不可阻挡的趋势。此外,从Grounded-SAM 的提出可以看出,在大模型时代,多个感知任务将会被集成在一起。例如一个多模态大模型可同时完成图像信息上的语义感知,点云信息上的结构感知和深度感知。此外,受到 SAM 上多种 prompt 的启发,多模态大模型中可以将多种模态信息用于指导大模型的感知任务,除了文本信息,还可以将深度信息、点云信息、无人机位置信息等多种信息作为 prompt 用于指导多模态大模型完成精确的感知任务。
表1: 本文所提及的大模型总览。

参考文献
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
[2] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
[4] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in CVPR, 2017.
[5] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in CVPR, 2019.
[6] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPS, 2017.
[7] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[8] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
[9] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” 2019.
[10] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” in NeurIPS, 2020.
[11] OpenAI, “Chatgpt,” https://openai.com/blog/chatgpt, 2022.
[12] ——, “Gpt-4,” https://openai.com/research/gpt-4, 2023.
[13] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al., “Opt: Open pre-trained transformer language models,” arXiv preprint arXiv:2205.01068, 2022.
[14] R. Google, “Palm: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022.
[15] Y. Sun, S. Wang, S. Feng, S. Ding, C. Pang, J. Shang, J. Liu, X. Chen, Y. Zhao, Y. Lu et al., “Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation,” arXiv preprint arXiv:2107.02137, 2021.
[16] S. Wang, Y. Sun, Y. Xiang, Z. Wu, S. Ding, W. Gong, S. Feng, J. Shang, Y. Zhao, C. Pang et al., “Ernie 3.0 titan: Exploring larger-scale knowledge enhanced pre-training for language understanding and generation,” arXiv preprint arXiv:2112.12731, 2021.
[17] W. Zeng, X. Ren, T. Su, H. Wang, Y. Liao, Z. Wang, X. Jiang, Z. Yang, K. Wang, X. Zhang et al., “Pangualpha: Large-scale autoregressive pretrained chinese language models with auto-parallel computation,” arXiv preprint arXiv:2104.12369, 2021.
[18] X. Ren, P. Zhou, X. Meng, X. Huang, Y. Wang, W. Wang, P. Li, X. Zhang, A. Podolskiy, G. Arshinov et al., “Pangu-sigma: Towards trillion parameter language model with sparse heterogeneous computing,” arXiv preprint arXiv:2303.10845, 2023.
[19] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T.Unterthiner, M.Dehghani, M.Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
[20] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in ICCV, 2021.
[21] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in CVPR, 2022.
[22] M.Dehghani,J.Djolonga,B.Mustafa,P.Padlewski,J.Heek,J.Gilmer,A.Steiner,M.Caron,R.Geirhos,I.Alabdulmohsin et al., “Scaling vision transformers to 22 billion parameters,” arXiv preprint arXiv:2302.05442, 2023.
[23] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” arXiv preprint arXiv:2304.02643, 2023.
[24] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image generation and editing with text-guided diffusion models,” in ICML, 2022.
[25] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,” arXiv preprint arXiv:2204.06125, 2022.
[26] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022.
[27] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,” in NeurIPS, 2022.
[28] J. Wang, Z. Yang, X. Hu, L. Li, K. Lin, Z. Gan, Z. Liu, C. Liu, and L. Wang, “Git: A generative image-to-text transformer for vision and language,” arXiv preprint arXiv:2205.14100, 2022.
[29] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021.
[30] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. Le, Y.-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” in ICML, 2021.
[31] J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified visionlanguage understanding and generation,” in ICML, 2022.
[32] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.
[33] X. Chen, X. Wang, S. Changpinyo, A. Piergiovanni, P. Padlewski, D. Salz, S. Goodman, A. Grycner, B. Mustafa, L. Beyer et al., “Pali: A jointly-scaled multilingual language-image model,” arXiv preprint arXiv:2209.06794, 2022.
[34] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,” arXiv preprint arXiv:2303.03378, 2023.
[35] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu et al., “Rt-1: Robotics transformer for real-world control at scale,” arXiv preprint arXiv:2212.06817, 2022.
[36] S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities,” Microsoft, 2023.
[37] D. Shah, B. Osiński, S. Levine et al., “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Conference on Robot Learning, 2023.
[38] N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” in ICML, 2019.
[39] T. Yang, Y. Zhu, Y. Xie, A. Zhang, C. Chen, and M. Li, “Aim: Adapting image models for efficient video action recognition,” ICLR, 2023.
[40] R. He, S. Sun, X. Yu, C. Xue, W. Zhang, P. Torr, S. Bai, and X. Qi, “Is synthetic data from generative models ready for image recognition?” in ICLR, 2023.
[41] D. Feng, C. Haase-Schütz, L. Rosenbaum, H. Hertlein, C. Glaeser, F. Timm, W. Wiesbeck, and K. Dietmayer, “Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 3, pp. 1341–1360, 2020.
[42] D. Shah, B. Eysenbach, G. Kahn, N. Rhinehart, and S. Levine, “Ving: Learning open-world navigation with visual goals,” in ICRA, 2021.
[43] X. Wang, X. Zhang, Y. Cao, W. Wang, C. Shen, and T. Huang, “Seggpt: Segmenting everything in context,” arXiv preprint arXiv:2304.03284, 2023.
[44] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” arXiv preprint arXiv:2303.05499, 2023.