利用Selenium(爬虫)爬取物流信息,并用邮件提醒自己物流更新
受疫情影响,快递无法全面复工,商家在过年期间又压了一堆未发货的订单。现在下单一个快递,商家迟迟无法发货,就算发了货,物流也慢的跟蜗牛一样。每天就是打开淘宝看物流信息,物流信息又没更新,关淘宝,为了节省这些时间,不在焦虑中度过,写了这么一个功能。(*^__^*) 嘻嘻……
准备工作
pip install lxml
pip install selenium
pip install smtplib
pip install email
谷歌浏览器
要爬取的网站 https://kuaidi.chawuliu.cn/
符合自己谷歌浏览器的chromedriver 地址http://npm.taobao.org/mirrors/chromedriver/
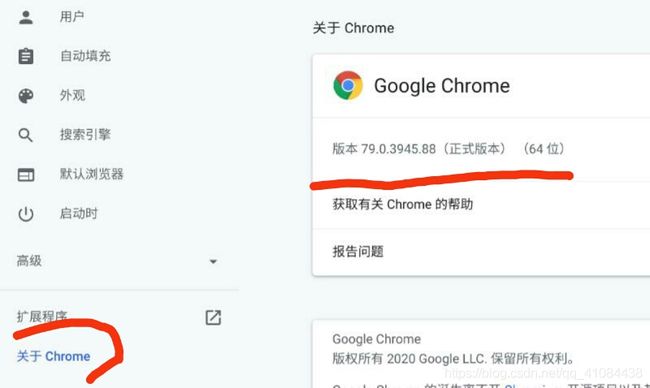
谷歌浏览器的版本在设置->左下角 关于Chrome 查看
因为我的浏览器是79.0.3945.88,所以下载chromdriver的时候选择79.0.3945.36/,要选择与自己浏览器对应的版本,不然会报错。
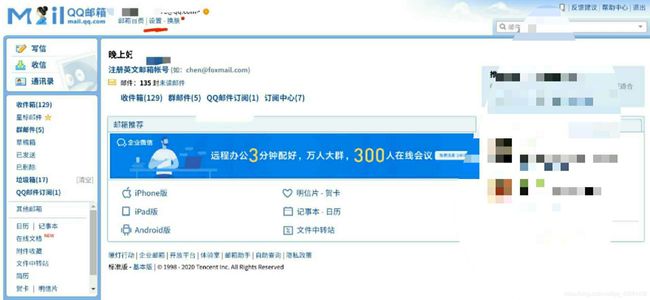
开启邮箱的SMTP服务
这里我使用的是QQ邮箱,只有开启smtp服务,python才能为你代发邮件。开启之后会有一个授权码,保存好这个,Python就是用这个授权码去登录你的邮箱的。


编码阶段
准备了这么久,路已经铺平了,就差这么一段代码了。
简单解释一下我的代码,有三个文件。
Express.py 函数运行的入口
SendEmail.py 处理发送邮件的类
Reptile.py 查询物流的爬虫类
还有之前下载的chromedriver,放在同一文件夹下,linux跟windows下的chromedriver是不一样的。
linux
windows

Express.py
import time
from multiprocessing import Process
from Reptile import Reptile
from SendEmail import SendEmail
k = 0
count = 0
def main():
sendManage = SendEmail(开启STMP服务的邮箱, 目标邮箱, 'smtp.qq.com', 开启STMP服务时的密码)
#sendManage = SendEmail('[email protected]', '[email protected]', 'smtp.qq.com', 'xxx')
# 我是用顺丰物流单号,其他快递公司没有试过
reptileManage = Reptile('快递单号')
global k
global count
count += 1
data = reptileManage.start()
# 上一次的信息条数跟这一次不一样,说明物流更新了
if k != len(data):
k = len(data)
count = 0
# 发送邮件频率不能过高,否则服务器会限制发送,导致代码报错
sendManage.sendEmail(data)
def run():
count = 7199
while count > 0:
print(count, end='')
time.sleep(1)
print('\r', end='')
count -= 1
if __name__ == '__main__':
while True:
p = Process(target=run).start()
main()
# 两个小时运行一次
time.sleep(7200)
# 30天没更新 停止运行
if count > 360:
break
SendEmail.py
# 发送email所需的头文件
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 构建一个发送邮件的类
class SendEmail:
def __init__(self, author, target, server, password):
self.authorEmail = author
self.targetEmail = target
# 发信服务器和授权码
self.smtp_server = server
self.password = password
def writeEmail(self, data):
# 邮箱正文内容,第一个参数为内容,第二个参数为格式(plain 为纯文本),第三个参数为编码
msg = MIMEText('send by python', 'plain', 'utf-8')
# 邮件头信息
msg['From'] = Header(self.authorEmail)
msg['To'] = Header(self.targetEmail)
content = ''
for text in data:
content = content + text + '\n'
msg['Subject'] = Header(content)
return msg
def sendEmail(self, data):
msg = self.writeEmail(data)
# 开启发信服务,这里使用的是加密传输
server = smtplib.SMTP_SSL(host=self.smtp_server)
server.connect(host=self.smtp_server, port=465)
# 登录发信邮箱
server.login(self.authorEmail, self.password)
# 发送邮件
server.sendmail(self.authorEmail, self.targetEmail, msg.as_string())
# 关闭服务器
server.quit()
Reptile.py
# selenium
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import re
import time
import lxml.html
class Reptile:
def __init__(self, Number):
self.Number = Number
# 要爬取的网站
self.url = 'https://kuaidi.chawuliu.cn/'
# linux是一个叫chromedriver的文件, 在windows下是一个exe
# windows的用户要改一下这里
self.driver = webdriver.Chrome('./chromedriver')
def failMessage(self):
list = []
list.append('浏览器在请求的时候发生错误,请查看错误信息!!!')
return list
def succeedMessage(self):
list = []
selector = lxml.html.fromstring(self.driver.page_source)
contentList = selector.xpath('//div/ul/li[@class="feed-item"]')
for item in contentList:
item_time = item.xpath('div/div[@class="feed-item_time"]/text()')[0]
item_date = item.xpath('div/div[@class="feed-item_date"]/text()')[0]
item_content = item.xpath('div[@class="feed-item_content"]/text()')[0]
print(item_time, ' ', item_date, ' ', item_content)
list.append(item_time + ' ' + item_date + ' ' + item_content)
return list
# 切换浏览器的窗口
def turnPage(self):
handles = self.driver.window_handles # 获取当前窗口句柄集合(列表类型)
for handle in handles: # 切换窗口
# current_window指的是driver.page_source
if handle != self.driver.current_window_handle:
self.driver.switch_to.window(handle)
break
def start(self):
self.driver.get(self.url)
# 等待元素('searchbox')的出现,最多等待300s
try:
WebDriverWait(self.driver, 300).until(EC.presence_of_element_located((By.ID, 'searchbox')))
except Exception as _:
print(_)
return self.failMessage()
inputNumber = self.driver.find_element_by_id('searchbox')
inputBtn = self.driver.find_element_by_id('searchBtn')
# 往网页输入物流单号,并回车搜索
inputNumber.clear()
inputNumber.send_keys(self.Number)
inputBtn.send_keys(Keys.RETURN) # 回车
time.sleep(5)
# 回车后会生成新窗口,所以切换窗口
self.turnPage()
try:
WebDriverWait(self.driver, 300).until(EC.presence_of_element_located((By.ID, 'searchbox')))
except Exception as _:
print(_)
return self.failMessage()
selector = lxml.html.fromstring(self.driver.page_source)
link = selector.xpath('/html/body/center/a[2]/@href')[0]
# 这个是最后我们要得到的物流信息
self.driver.get(link)
try:
WebDriverWait(self.driver, 300).until(EC.presence_of_element_located((By.CLASS_NAME, 'feed-container')))
except Exception as _:
print(_)
return self.failMessage()
data = self.succeedMessage()
self.driver.quit() # 关闭浏览器
return data
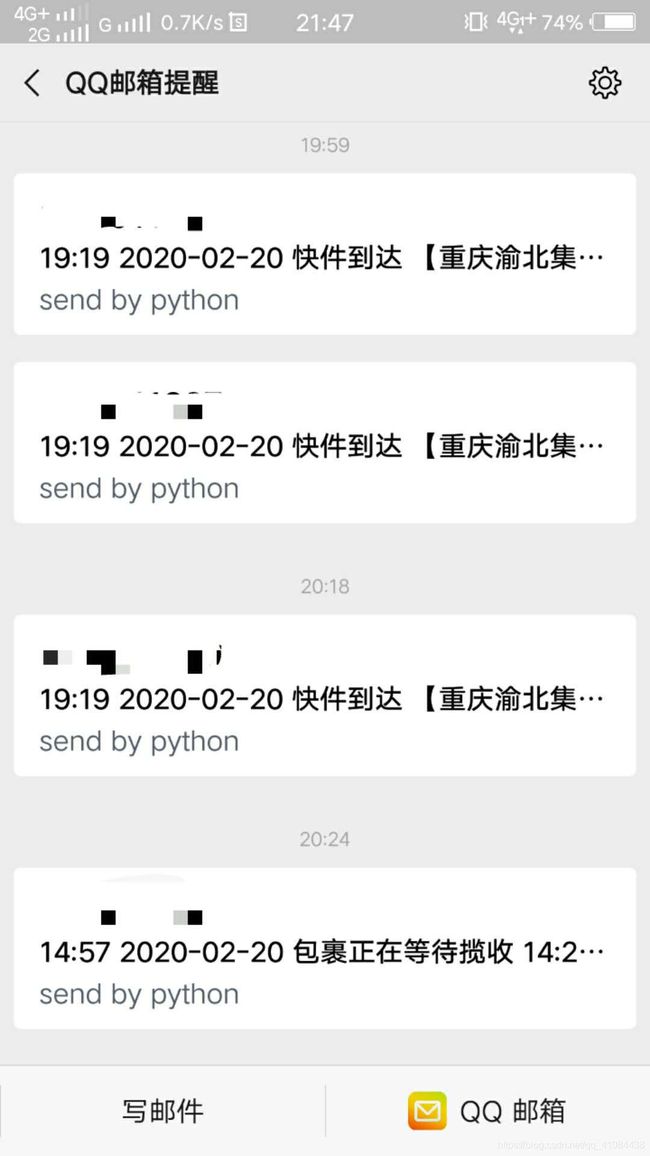
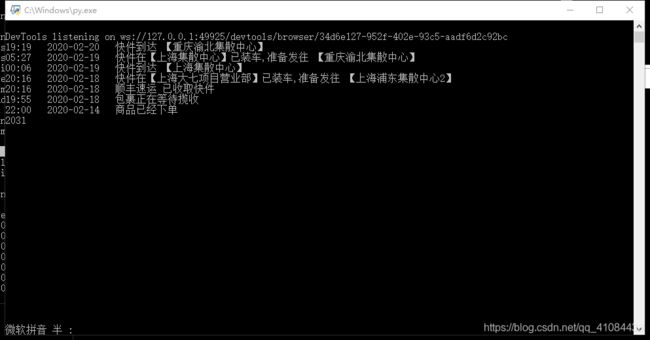
效果
上阿里云腾讯租个虚拟主机,在那里可以24小时不间断运行,感觉更高端了。
下面是云主机给我发回来的邮件,还有在cmd窗口的图片。