Java 对象的序列化和反序列化是一种将对象转换成字节流并存储在硬盘或网络中,以及从字节流中重新加载对象的操作。Java 的序列化和反序列化提供了一种方便的方式,使得可以将对象在不同的应用程序之间进行交互。
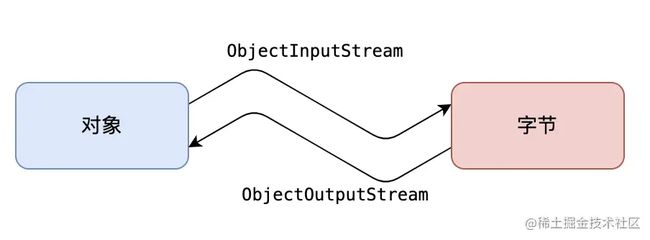
一、什么是 Java 序列化和反序列化?
Java 对象的序列化是将 Java 对象转换成字节流的过程,可用于持久化数据,传输数据等。序列化是将 Java 对象的状态表示为字节序列的过程,可以通过网络传送,存储到文件中或者使用其他的持久化技术,如数据库等。序列化后的字节流可以被传输给远程系统,并在那里重新构造成原始对象。Java 序列化是一个将对象转化为字节流的过程。
Java 对象的反序列化是将字节流重新恢复为原始对象的过程。反序列化是将字节流转化为对象的过程。反序列化是对象序列化的逆过程,通过反序列化操作能够在接收端恢复出与发送端相同的对象。当我们需要对存储的对象进行读取操作时,就需要对序列化的字节流进行反序列化操作,将字节流转化为原始的对象信息。
二、序列化和反序列化的实现方式
Java 中的序列化和反序列化可以通过实现 Serializable 接口来完成。Serializable 是一种标记接口,它没有方法定义,但它具有一个特别的作用,就是用于在描述 java 类可序列化时做类型判断的信息。当一个类实现 Serializable 接口时,表明这个类是可序列化的。Serializable 接口只是一个标识接口,我们并不需要重载任何方法。
在实现 Serializable 接口后,就可以通过 ObjectOutputStream 来将对象序列化,并将序列化后的字节流输出到文件或网络中;同时,也可以通过 ObjectInputStream 来将序列化后的字节流反序列化成对象。 java.io.ObjectOutputStream 继承自 OutputStream 类,因此可以将序列化后的字节序列写入到文件、网络等输出流中。
来看 ObjectOutputStream 的构造方法: ObjectOutputStream(OutputStream out)
一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口open in new window,否则会抛出NotSerializableException。 - 该类的所有字段都必须是可序列化的。如果一个字段不需要序列化,则需要使用
transient关键字open in new window进行修饰。 - 该构造方法接收一个 OutputStream 对象作为参数,用于将序列化后的字节序列输出到指定的输出流中。
示例代码如下:
import java.io.*;
public class SerializationDemo {
public static void main(String[] args) {
// 序列化对象
Person person = new Person("Tom", 20);
try {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("person.txt"));
objectOutputStream.writeObject(person);
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
// 反序列化对象
try {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("person.txt"));
Person restoredPerson = (Person) objectInputStream.readObject();
System.out.println(restoredPerson);
objectInputStream.close();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
在上述代码中,我们定义了一个 Person 类,该类实现了 Serializable 接口。在序列化过程中,我们使用 ObjectOutputStream 类将 person 对象写出到文件中;在反序列化过程中,我们使用 ObjectInputStream 类读取文件中的字节流,并将其转换为 Person 对象。
三、序列化和反序列化的注意事项
- 私有化序列号属性
序列化和反序列化需要使用对象的序列号属性(serialVersionUID)来判断版本号是否一致,从而防止在新版本和旧版本之间发生不兼容的情况。如果没有显式地声明 serialVersionUID,则编译器会自动生成一个 serialVersionUID,但这种方式是不可靠的,因为在修改过程中可能会产生 serialVersionUID 的变化,从而导致不兼容问题。
因此,在 Java 序列化中,最好显式地声明 serialVersionUID 属性,并进行私有化,避免意外的修改。例如:
private static final long serialVersionUID = 1L;
- 实现 readObject 和 writeObject 方法
readObject 和 writeObject 是在序列化和反序列化过程中用于自定义序列化的方法。通常情况下,我们可以直接使用默认的序列化方法,但是有时我们需要对序列化内容进行一些处理,这时就需要实现 readObject 和 writeObject 方法。例如,对于对象中敏感数据的处理,我们可以在 writeObject 方法中对数据进行加密处理,在 readObject 方法中解密处理。
需要注意的是,在实现 readObject 和 writeObject 方法时,必须要调用默认方法,默认方法可以通过 ObjectInputStream 和 ObjectOutputStream 类的 defaultReadObject 和 defaultWriteObject 方法调用。
四、序列化和反序列化的优点和缺点
序列化和反序列化的优点是:
对象的序列化方便了对象在不同应用之间的传递、存储和恢复。
通过序列化可以实现分布式计算,在不同的机器上对同一对象进行操作和协作。
序列化提供了数据持久化的能力,即将对象的状态保存在硬盘等介质中,下次可以直接从硬盘中读取数据,避免了频繁地进行数据库读写操作。
序列化和反序列化的缺点是:
在进行序列化和反序列化操作时,需要消耗额外的时间和开销,特别是当对象比较大或者嵌套较深的时候,可能会导致严重的性能问题。
序列化和反序列化可能存在安全性问题,如果被攻击者篡改了序列化后的字节流数据,那么反序列化后的对象可能会出现意外行为,如获得不应该获得的权限。
五、总结
Java 对象的序列化和反序列化是一种将对象转换成字节流并存储在硬盘或网络中,以及从字节流中重新加载对象的操作。序列化和反序列化均需要实现 Serializable 接口,并使用 ObjectOutputStream 和 ObjectInputStream 类来完成。序列化和反序列化可以方便地实现对象在不同应用之间的传递、存储和恢复等功能,但也存在一些缺点,如可能会导致严重的性能问题和安全性问题。在使用过程中,需要根据具体的业务场景和需求进行选择和优化,以达到最佳的效果。

在实际的 Java 开发中,序列化和反序列化是一个非常常见的操作,例如在分布式系统中,需要将对象序列化后通过网络传输,在不同的机器上进行反序列化以得到原始对象。
以下是一些使用序列化和反序列化的示例场景:
- 缓存
在实际的开发中,我们经常需要对一些数据进行缓存,使用序列化可以将对象序列化为字节数组,然后将字节数组存储到文件或者缓存中。当需要使用缓存中的对象时,再进行反序列化操作,重新获得原始对象。
- 远程调用
在分布式系统中,需要将对象序列化后通过网络传输,在不同的机器上进行反序列化以得到原始对象。例如在 Dubbo 框架中,就使用了对象序列化和反序列化机制。
- 持久化数据
在实际的开发中,我们需要将某些对象的状态保存到数据库或者文件中,使用序列化可以将对象序列化为字节数组,然后将字节数组存储到数据库或者文件中。当需要读取数据时,再进行反序列化操作,获得原始对象。
一般使用 Java 序列化和反序列化只需要实现 Serializable 接口即可,但是也可以使用一些工具依赖来简化操作。以下是一些常用的序列化和反序列化工具依赖:
1. Jackson
Jackson 是一个非常常用的序列化和反序列化工具,在 Spring Boot 等框架中也被广泛使用。Jackson 可以将对象序列化为 JSON 或者 XML 格式,同时也可以将 JSON 或者 XML 反序列化为对象。
2. Gson
Gson 是另一个常用的序列化和反序列化工具,同样可以将对象序列化为 JSON 格式,也可以将 JSON 反序列化为对象。
3. Protobuf
Protobuf 是 Google 开源的一种轻量级、高效、可扩展的序列化框架,支持多种编程语言。与 Java 序列化相比,Protobuf 使用效率更高,序列化后的字节流更小,但需要预定义消息格式。
4. Kyro
Kryo 是一个高性能的 Java 序列化和反序列化工具,可以将 Java 对象序列化为字节数组,适合于网络通信和数据持久化等场景。Kryo 能够快速地序列化和反序列化 Java 对象,相对于 Java 自带的序列化机制,它的速度更快,序列化后的字节数组也更小。
以上是一些常用的序列化和反序列化工具依赖,根据不同的业务需求和场景需要选择适合的工具。
到此这篇关于一文详解Java对象的序列化和反序列化的文章就介绍到这了,更多相关Java对象的序列化和反序列化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!