小黑子—Java从入门到入土过程:第七章
Java零基础入门7.0
- Java系列第七章
-
- 1. 游戏打包exe
- 2. API
-
- 2.1 Math
- 2.2 练习
-
- 2.2.1 判断质数
- 2.2.2 判断水仙花数(自幂数)
- 2.3 System
- 2.4 Runtime
- 2.5 Object
-
- 2.5.1 Object 的成员方法
-
- (1) toString
- (2) equals 比较两个对象是否相等
- (3) clone方法(Object对象中的方法)
- 2.5.2 Objects
- 2.6 BigInteger(大的整数)
-
- 2.6.1 Biglnteger构造方法:
-
- (1) public BigInteger(int num,Random rnd) 获取随机大范围整数
- (2) public BigInteger(String val) 获取指定的大整数
- (3) public BigInteger(String val,int radix) 获取指定进制的大整数
- (4) BigInteger.valueOf(long val)
- 2.6.2 BigInteger常见成员方法
- 2.6.3 BigInteger底层存储方式
- 2.7 BigDecima(大的小数)
-
- 2.7.1 Bigdecimal的常见方法
- 2.7.2 Bigdecimal的底层存储方式
- 2.7 正则表达式
-
- 2.7.1 正则表达式的字符
- 2.7.2 正则表达式的数量词
- 2.7.3 正则表达式练习
-
- 一、
- 二、
- 2.7.4 爬虫
-
- 一、带条件的数据爬取
- 二、贪婪爬取和非贪婪爬取
- 2.7.5 正则表达式在字符串方法中的使用
- 2.7.6 分组
-
- (1)捕获分组
- (2)非捕获分组
- 2.8 JDK7时间
-
- 2.8.1 Date 时间
Java系列第七章
1. 游戏打包exe
游戏打包exe要考虑的因素:

游戏打包核心步骤:

2. API
2.1 Math
Math是一个帮助我们用于进行数学计算的工具类私有化构造方法,所有的方法都是静态的
在源码中的定义
public final class Math extends Object
即Math是一个最终类,不能被继承
Math是一个帮助计算的工具类 私有化构造方法,所有方法都是静态的
类Math包含用于执行基本数字运算的方法,例如基本指数,对数,平方根和三角函数
Math中的方法基本上都是静态修饰,可以直接通过类名调用
Math. 方法名()
例如:
Math.abs(-11)
常用方法:

abs的bug
以int为例
int类型的取值范围是-2147483648~2147483647如果没有正数与负数对应,那么传递负数结果有误
解决方案
使用absExact方法,当取值超过数据类型范围时,会有报错
System.out.println(Math.abs(88));//88
System.out.println(Math.abs(-88));//88
System.out.println(Math.absExact(-2147483648));//报错

ceil 向上取整
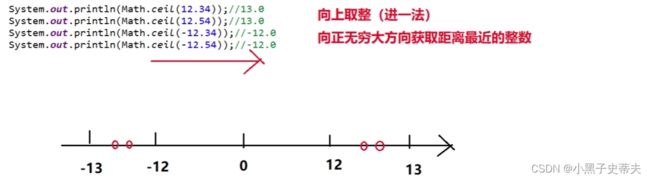
floor 去尾法

round 四舍五入

max 获取两个整数的最大值

min 获取两个整数的最小值
![]()
pow 获取a的b次幂

sqrt 开方 和 cbrt 开立方

random 获取随机数
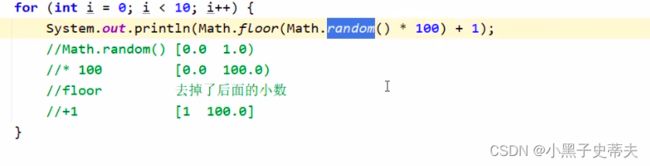
2.2 练习
2.2.1 判断质数

但是这样遍历的话,如果要求的数非常大,那么就要从2开始依次遍历,非常麻烦
寻找因子的规律:

在左边因子当中,必定是小于等于该数(比如16)的平方根的
在右边因子当中,必定是大于等于该数(比如16)的平方根的

假设两个左右两边的数都是哪怕大于4的一点点,那么就不等于16
同理小于4的一点点时,也不等于

故其中一个因子当中一定是有小于等于平方根的,还有就是大于等于平方根的
以下因子情况:

所以判断一个数是否为质数的时候,不需要把所有的数全部遍历一遍,只需要把左边的因子数遍历判断就可以了
代码实现:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
System.out.println("请输入一个整数:");
Scanner sc = new Scanner(System.in);
int number = sc.nextInt();
System.out.println(isPrime(number));
}
public static boolean isPrime(int number) {
int count =0;
for (int i = 2; i <= Math.sqrt(number); i++) {
count++;
if (number % i == 0) {
return false;
}
}
System.out.println("循环了"+count+"次"+","+number+"是质数");
return true;
}
}

2.2.2 判断水仙花数(自幂数)

public class Main {
public static void main(String[] args) {
int count=0;
//得到每一个三位数
for (int i = 100; i < 999; i++) {
//个位 十位 百位
int ge =i%10;
int shi = i/10%10;
int bai = i/100%10;
//判断:
//每一位的三次方之和 跟本身进行比较
double sum = Math.pow(ge,3)+Math.pow(shi,3)+Math.pow(bai,3);
if(sum==i){
count++;
System.out.println(i);
}
}
System.out.println("循环了"+count+"次");
}
}

2.3 System

计算器机的时间原点:

currentTimeMillis()来判断程序运行时间

long l = System.currentTimeMillis();
System.out.println(l);
//表示从开始到结束,采用了运行多少时间
arraycopy 数组拷贝
/*
第一个参数:数据源,表示被拷贝的数组
第二个参数:从数据原中的第几个索引开始拷贝
第三个参数:目的地,我要把数据拷贝到那个数组中
第四个参数:目的地数组的索引
第五个参数:拷贝的个数
*/
System.arraycopy(arr1,0,arr2,2,4);
for (int i = 0; i < arr2.length; i++) {
System.out.println(arr2[i]);
}

arraycopy的细节:
- 1.如果数据原数组和目的地数组的值都是基本数据类型,那么两者的类型必须保持一致,否则会报错
- 2.在拷贝的时候,需要考虑数组的长度,如果超出范围也会报错
- 3.如果数据原数组和目的地数组的值都是引用数据类型,那么,子类类型可以赋值给父类类型
//Person是Student的父类
Student s1=new Student("zhangsan",18);
Student s2=new Student("sanwu",18);
Student s3=new Student("lisan",18);
Student []arr1={s1,s2,s3};
Person []arr2=new Person[3];
//这里是可以赋值的,但在遍历arr2的时候,要把数据类型再进行转换,换成Student
System.arraycopy(arr1,0,arr2,0,3);
for(i=0;i<arr2.length.i++){
Student stu=(Student)arr2[i];
sout(stu.getname()+" "+stu.getage())

小结:

2.4 Runtime
Runtime表示当前虚拟机的运行环境
主要可以用来监视虚拟机的内存
这个类的方法不是静态的,需要先获取对象才能调用方法

1.获取Runtime的对象
//获取Runtime对象
//java的Runtime对象只有一个
Runtime r1=Runtime.getRuntime();
Runtime r2=Runtime.getRuntime();
System.out.println(r1==r2);

2.exit 停止虚拟机
这个实际上就是System.exit(0)的底层源码
Runtime.getRuntime().exit(0);
3.ailableProcessors 获取cpu线程数
System.out.println(Runtime.getRuntime().availableProcessors());

4.maxMemory 可以获得的总内存大小,单位byte字节
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024);

5.totalMemory 已经获得的内存大小,单位byte字节
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024);

6.freeMemory 虚拟机中剩余内存的大小
System.out.println(Runtime.getRuntime().freeMemory());

7. 运行cmd命令
//以字符串的形式运行cmd命令
//notepad,打开记事本
//shutdown,关机
//加上参数才能运行
//-s,默认一分钟之后关机
//-s -t 指定关机时间
//-a 取消关机操作
//-r 关机并重启
Runtime.getRuntime().exec("notepad");
2.5 Object

Object中没有成员变量,所以没有带参构造,只有空参构造方法
public Object
Object 的构造方法

2.5.1 Object 的成员方法

(1) toString
返回对象的字符串表现形式
public class Test1 {
public static void main(String[] args) {
Object obj = new Object();
String str1 = obj.toString();
System.out.println(str1);//java.lang.Object@4eec7777 @之前是包名+类名,@后是对象的地址值
sout(obj);//打印出来也是java.lang.Object@4eec7777
}
}
System.out.println(参数)语句的解析
System是类名,out是一个静态变量,System.out:获取被打印的对象,println则是一个方法,参数就表示要打印的内容
核心逻辑:
当我们打印一个对象时,底层会调用对象的toString方法,把对象变成字符串,然后再打印在控制台上,打印完成后换行处理
将toString()打印地址值改成打印对象属性值的解决方案:
重写父类Object中的toString方法
toString方法的结论:
- 如果打印一个对象,想要看到属性值的话,那么在子类中重写toString方法就行可以了
- 在重写的方法中,把对象属性值进行拼接返回
@Override
public String toString() {
return name+","+age;
}
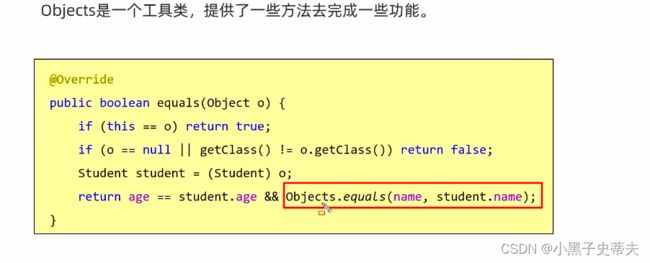
(2) equals 比较两个对象是否相等

原本比较的是地址值,通过重写(直接用alt+回车的重写)可以比较对象里的属性值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && name.equals(student.name);
}
//测试
Student stu1=new Student("zhangsan",18);
Student stu2=new Student("zhangsan",18);
// System.out.println(stu1);
boolean s1=stu1.equals(stu2);
System.out.println(s1);//结果为true
结论:
- 如果没有重写equals方法,那么默认使用Object中的方法进行比较,比较的是地址值是否相等
- 一般来讲地址值对我们意义不大,所以会进行方法的重写,将equals重写后比较的就是对象内部的属性值了
注:
String类中的equals方法会先判断参数是否为字符串,如果是字符串,再比较内部的属性,但是如果不是字符串,直接返回false
StringBuilder中没有equals方法,所以会直接使用Object中的equals方法,也就是比较地址值是否相等
(3) clone方法(Object对象中的方法)
clone()对象克隆
protected Object clone()
把A对象的属性值完全拷贝给B对象,也叫对象拷贝,对象复制


clone()源码,被protected修饰,所以不能直接调用,需要在子类里重写,
ctrl+鼠标点击就可以查看java源码
Cloneable接口
- 如果一个接口中没有抽象方法
- 表示当前接口是一个标记性接口
- 当标记性接口(现在Cloneable表示)一旦实现,那么当前类的对象就可以被克隆
- 如果没有实现,当前类的对象就不能克隆 即,要想一个对象被克隆的话,就必须实现Cloneable这个接口,然后才能被克隆
alt + 回车 选择第二个异常签名,让克隆不报错

User类:
import java.util.StringJoiner;
public class User implements Cloneable{//实现额外的接口
private int id;//游戏角色
private String username;//用户名
private String password;//密码
private String path;//游戏图片
private int[] data;//游戏进度
public User() {
}
public User(int id, String username, String password, String path, int[] data) {
this.id = id;
this.username = username;
this.password = password;
this.path = path;
this.data = data;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
public int[] getData() {
return data;
}
public void setData(int[] data) {
this.data = data;
}
public String toString(){
return "角色编号为:"+id+",用户名 "+username+",密码"+password+",游戏图片"+path+",游戏进度"+arrToString();
}
public String arrToString(){
StringJoiner sj = new StringJoiner(",","[","]");
for (int i = 0; i < data.length; i++) {
sj.add(data[i]+"");
}
return sj.toString();
}
@Override
protected Object clone() throws CloneNotSupportedException {
//调用父类中的clone方法
//相当于让Java帮我们克隆一个对象,并把克隆之后的对象返回出去
return super.clone();
}
}
测试类:
public class ObjectDemo2 {
public static void main(String[] args) throws CloneNotSupportedException {
//1.先创建一个对象
int[] data ={1,2,3,4,5,6,7,8,9};
User u1 = new User(1,"maghua","12345","girl1",data);
//2.克隆对象,不能直接克隆
//因为当前方法是受保护的,表示当前的克隆方法只能被本包的类、还有其他包中的子类所使用
//又Object是定义再java.lang包下的,不能把代码写再lang包下
//所以,如果想要clone()方法,只能去User重写克隆方法
//细节:
//方法在底层会帮我们创建一个对象,并把原对象中的数据拷贝过去。
//书写细节:
//1.重写object中的clone方法
//2.让javabean类实现cloneable接口
//3.创建原对象并调用clone就可以了
User u2 = (User)u1.clone();//由于克隆出来的对象是用户对象,所以要进行强转
System.out.println(u1);
System.out.println(u2);
}
}
![]()
图解:

Cloneable接口:
package java.lang;
public interface Cloneable {
}
对象克隆方式一:
浅克隆(浅拷贝)
拷贝时,先创建一个新的对象,然后 基本数据类型就拷贝其数值, 引用数据类型就拷贝其地址值

深克隆(深拷贝)
拷贝时,也会先创建一个新的对象,然后 基本数据类型就拷贝其数值,
- 引用数据类型在拷贝时,如果是new出来的,就会在堆内存中开辟出一块新的空间,然后把之前老空间里的数据复制到新空间里,再把新空间的新地址值赋值给拷贝的变量,如果不是new出来的,像字符串,数据在串池里的,就会把之前的数据复用

实现代码:
上方User类的重写方法修改:
@Override
protected Object clone() throws CloneNotSupportedException {
//调用父类中的clone方法
//相当于让Java帮我们克隆一个对象,并把克隆之后的对象返回出去
//先把被克隆对象中的数组获取出来
int[] data = this.data;
//创建新的数组
int[] newData = new int[data.length];
//拷贝数组中的数据
for (int i = 0; i < data.length; i++) {
newData[i] = data[i];
}
//调用父类中的方法克隆对象
User u = (User)super.clone();
//因为父类中的克隆方法是浅克隆,替换克隆出来对象的数组地址值
u.data = newData;
return u;
}
测试类:
User u2 = (User)u1.clone();
int[] arr =u1.getData();
arr[0] = 100;
System.out.println(u1);
System.out.println(u2);
![]()
以后用到深克隆到实际项目当中时,就会使用第三方的一个工具
使用步骤:
- 1.先创建一个lib(Library)包,将第三方的工具导入当前项目中
- 2.编写代码
//先创建一个工具的对象
Gson gson=new Gson();
//把对象变成一个字符串
String s= gson.toJson(u1);
User user=gson.fromJson(s,User.class);
//打印对象
System.out.println(user);
这个深克隆的工具放到自己了解的路径当中
导入后,再点击添加到库中,如果有问题,看160集

有问题了看这篇文章
小结:

即
- 浅克隆:不管对象内部的属性是基本数据类型还是引用数据类型,都完全拷贝过来
- 深克隆:基本数据类型拷贝过来,字符串复用,引用数据类型还会重新创建新的
总结:

2.5.2 Objects
objects是一个工具类,提供了一些方法去完成一些功能。
objects的成员方法:

Studnet s1 = null;
Stundent s2 = new Student("zhangsan",33);
boolean result=Objects.equals(s1,s2);
sout(Objects.isNull(s3));
sout(Objects.nonNull(s4));
直接使用Objects调用
细节:
- 1.Objects的equals方法的底层会先判断s1是否为null,如果时null,直接返回false
- 2.如果s1不为null,那么就利用s1再调用equals方法
- 3.此时的s1为Student类型,所以调用的还是Student的equals方法,如果没有重写,调用的就是Object的equals方法,比较地址值,如果重写了,就会比较属性值。
总结:

2.6 BigInteger(大的整数)
BigInteger(大的整数):
BigInteger可以表示超出long范围的整数,上限可以看作无限

2.6.1 Biglnteger构造方法:

(1) public BigInteger(int num,Random rnd) 获取随机大范围整数
public BigInteger(int num,Random rnd) 获取随机大范围整数
范围[0~2的num次方-1],包含0和2的num次方-1
Random r = new Random();
BigInteger bd1 = new BigInteger(4,r);
System.out.println(bd1);//2^4-1之内出现
(2) public BigInteger(String val) 获取指定的大整数
BigInteger bd2 = new BigInteger("999999999999999999999999999999999999999999999999999999999999999");//照样输出不会报错
BigInteger bd2 = new BigInteger("1.1");//有小数,直接报错
BigInteger bd2 = new BigInteger("abc");//字符串直接报错
(3) public BigInteger(String val,int radix) 获取指定进制的大整数
细节;
1.字符串中的数字必须是整数
2.字符串中的数字必须要跟进制吻合。
比如二进制中,那么只能写0和1,写其他的就报错。
BigInteger bd1=new BigInter("100",10);//这里获取的就是10进制的100,打印出来就是100
BigInteger bd2=new BigInter("100",2);//这里获取的就是2进制的100,打印出来就是4
BigInteger bd3=new BigInter("123",2);//这里代码就会报错,因为二进制中没有2和3
(4) BigInteger.valueOf(long val)
valueOf(long val),BigInteger的静态方法,可以获取BigInteger的对象,内部有优化
BigInteger(String val)与valueOf(long val)的不同之处
先来看相同的地方:他们都是创建一个大整数对象
BigInteger bd1=new BigInteger("100");
BigInteger bd1=BigInteger.valueOf(100);
不同:
1.valueOf能表示的范围比较小,只能在long的范围之内,不能超出long的范围
2.在内部,对常用的数字,-16到16进行了优化,提前把-16到16的BigInteger对象创建好了,多次获取时不会创建新的对象
3.如果超出了范围,就没有优化了,即使相同也会报错
BigInteger bd1=BigInteger.valueOf(16);
BigInteger bd2=BigInteger.valueOf(16);
sout(bd1==bd2);//==号比较的是地址值,结果是true,证明bd1和bd2是同一个对象
BigInteger bd3=BigInteger.valueOf(17);
BigInteger bd4=BigInteger.valueOf(17);
sout(bd3==bd4);//==号比较的是地址值,结果是false,证明bd3和bd4不是同一个对象.
- 如果不知道数据的范围有多大,就使用BigInteger(String val)
去获取,如果知道数据的范围在long范围内,就使用valueOf来获取 - 由于BigInteger对象一旦创建,内部记录的值就不能发生改变,所以,只要进行计算,像加减乘除在内的计算都会产生一个新的BigInteger对象
小结:

2.6.2 BigInteger常见成员方法

因为BigInteger是一个对象,不能直接相加减,要通过方法来完成
一些方法的使用:
import java.math.BigInteger;
public class BigIntegerTest {
public static void main(String[] args) {
BigInteger bd1=BigInteger.valueOf(15);
BigInteger bd2=BigInteger.valueOf(5);
//加
BigInteger bd3=bd1.add(bd2);
System.out.println(bd3);
//减
BigInteger bd4=bd1.subtract(bd2);
System.out.println(bd4);
//乘
BigInteger bd5=bd1.multiply(bd2);
System.out.println(bd5);
//除
BigInteger bd6=bd1.divide(bd2);
System.out.println(bd6);
//除,获取商的同时获取余数
//返回值是一个数组,第一个值记录商,第二个值记录余数
BigInteger[] bd7=bd1.divideAndRemainder(bd2);
System.out.println(bd7);
System.out.println(bd7[0]);
System.out.println(bd7[1]);
//比较是否相同
Boolean a=bd1.equals(bd2);
System.out.println(a);
//次幂
BigInteger bd9=bd1.pow(3);
BigInteger bd10=bd2.pow(3);
System.out.println(bd9+ " "+bd10);
//返回较大值
BigInteger bd11=bd1.max(bd2);
System.out.println(bd11);
//返回较小值
BigInteger bd12=bd1.min(bd2);
System.out.println(bd12);
//转换类型
int b=bd1.intValue();
System.out.println(b);
}
}
2.6.3 BigInteger底层存储方式

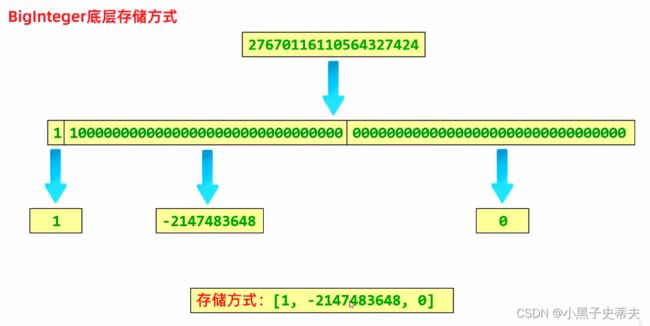
就是将一个大的整数分成多段存入数组中
1.先将数转化成补码
2.将补码32位分成一段,然后分成多段
3.再将多段补码转化为多段十进制整数
4.再将十进制整数存入数组
数组的最大长度就是int的最大值:2147483647(理论值)

总结:

2.7 BigDecima(大的小数)
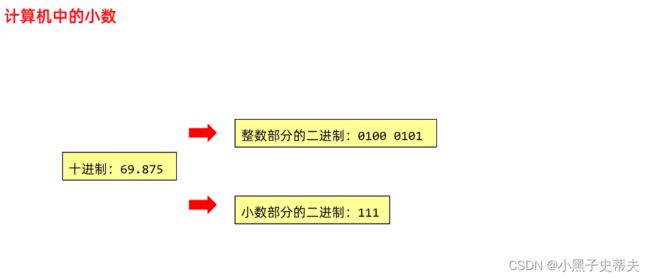


计算机中的小数的存储方式
由于小数在计算机中用二进制表示时会很多,而每一种数据类型能够占用的空间是有限的,所以就会导致小数在计算机中的存储是不精确的
在实际应用中:

BigDecimal的作用:
- 用于小数的精确计算
- 用很大的小数
BigDecimal的一些构造方法:
| 方法名 | 说明 |
|---|---|
public BigDecimal(double val) |
将 double 转换为 BigDecimal,但是,此构造方法的结果有一定的不可预知性,即还是有可能是不精确的,所以不推荐使用 |
public BigDecimal(String val) |
将字符串转换为 BigDecimal。,它不会遇到 BigDecimal(double) 构造方法的不可预知问题。 |
与BigInteger一样,BigDecimal也有valueOf(long val)的静态方法,可以获取BigDecimal的对象,可以传递整数。
import java.math.BigDecimal;
public class BigDecimalTest {
public static void main(String[] args) {
//通过传递double类型的小数来创建对象
//这种方式有可能不精确,不推荐使用
BigDecimal bd1=new BigDecimal(0.01);
BigDecimal bd2=new BigDecimal(0.09);
System.out.println(bd1);
System.out.println(bd2);
//结果为
//0.01000000000000000020816681711721685132943093776702880859375
//0.0899999999999999966693309261245303787291049957275390625
//通过传递字符串表示的小数来创建对象
//常用的方式1
BigDecimal bd3=new BigDecimal("0.01");
BigDecimal bd4=new BigDecimal("0.09");
System.out.println(bd3);
System.out.println(bd4);
//结果为
//0.01
//0.09
//通过静态方法获取对象
BigDecimal bd6 = BigDecimal.valueOf(10);
BigDecimal bd7 = BigDecimal.valueOf(10);
System.out.println(bd6 == bd7);//true
BigDecimal bd6 = BigDecimal.valueOf(10.0);
BigDecimal bd7 = BigDecimal.valueOf(10.0);
System.out.println(bd6 == bd7);//false
}
}
通过传递字符串表示的小数来创建对象与valueOf静态方法的差别
- 如果表示的数字没有超出double的取值范围,推荐使用静态方法
- 如果要表示的数字比较大,超出了double的取值范围,建议使用构造方法
- 在静态方法中,如果传递的是0~10之间的整数(包括0和10),那么,方法会返回已经创建好的对象,不会重新new,跟BigInteger是一样的原理,但是,如果传递的是小数的话,就不会有优化,会创建新的对象
2.7.1 Bigdecimal的常见方法

//前面几个跟BigInteger没什么差别
//主要是除法
BigDecimal bd1 = BigDecimal.valueOf(10.0);
BigDecimal bd2 = BigDecimal.valueOf(3.0);
//除法
BigDecimal bd6 = bd1.divide(bd2);
System.out.println(bd6);//报错
//当除不尽时,public BigDecimal divide(BigDecimal val)这个方法就会报错,
//此时,就要使用
//public BigDecimal divide(BigDecimal val,精确几位,舍入模式)。这个方法
BigDecimal bd6 = bd1.divide(bd2,2,BigDecimal.ROUND_HALF_UP);
System.out.println(bd6);//结果为3.33
其他的舍入模式可以在api文档中的RoundingMode类中可以找到:
数轴表示:

2.7.2 Bigdecimal的底层存储方式
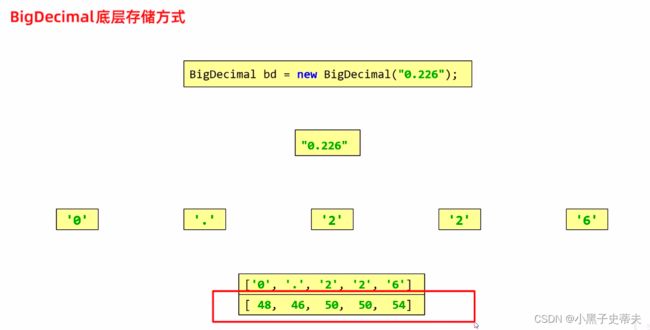
Bigdecimal会先得到字符串里的字符,将字符串分成一个个单独的字符,在将字符转化为ascll码表上的数值,再存储到数组里。
例如:

总结:

2.7 正则表达式
正则表达式用于校验字符串的相关操作,可以很方便
字符串通过使用matches方法来匹配相应的正则表达式
"abc".matches("[bcd]");//结果为false
练习:

public static void main(String[] args) {
//规则:6位及20位之内,0不能在开头,必须全部是数字
//一个编程思想:
// 先把异常数据进行过滤,
// 过滤后得到的就是满足要求的数据了
String qq = "1234567890";
//System.out.println(checkQQ(qq));但是这样写就稍微麻烦了
System.out.println(qq.matches("[1-9]\\d{5,19}"));//[5,19]表示6位到20位
}
public static boolean checkQQ(String qq){
int len =qq.length();
if(len<6||len>20){
return false;
}
//0不能在开头
if(qq.startsWith("0")){
return false;
}
//必须全部是数字
for (int i = 0; i < qq.length(); i++) {
char c = qq.charAt(i);
if(c<'0'||c>'9'){
return false;
}
}
return true;
}
}

正则表达式的作用:
- 1.校验字符串是否满足规则
- 2.在一段文本中查找满足要求的内容

2.7.1 正则表达式的字符

上面的方括号([ ]) 在正则表达式中表示一个字符的范围,字符串里出现的字符一定要在这个范围之内,不在范围之内的话会返回false
^在正则表达式中表示取反的意思&&在正则表达式中表示取交集的意思()是分组|在方括号外表示并集
在java中,\表示转义字符,改变后面那个字符原本的含义
sout(" \" ")打印出来的就是,sout(" " ")这样写会报错
\\就表示一个普通的\符号,不表示转义字符
1.字符类例子:
取值判断
sout("a".metches("[abc]"));//true
sout("ab".metches("[abc]"));//false,因为这里的正则表达式只能表示一个字符的范围
//,如果想表示两个字符的范围的话,可以这样写
sout("ab".metches("[abc][abc]"));//这样才可以表示两个字符
取反
sout("a".metches("[^abc]");//false
sout("d".metches("[^abc]");//true
sout("zz".metches("[^abc]"));//false
sout("zz".metches("[^abc][^abc]"));//false
a-z A-Z(包括头尾的范围)
sout("a".metches("[a-zA-Z]");//true
sout("z".metches("[a-zA-Z]");//true
sout("aa".metches("[a-zA-Z]");//false
sout("zz".metches("[a-zA-Z]");//false
sout("zz".metches("[a-zA-Z][a-zA-Z]");//true
sout("0".metches("[a-zA-Z0-9]");//ture
[a-d[m-p]]: a到d,或m到p
sout("a".metches("[a-d[m-p]]");//true
sout("d".metches("[a-d[m-p]]");//true
sout("m".metches("[a-d[m-p]]");//true
sout("p".metches("[a-d[m-p]]");//true
sout("e".metches("[a-d[m-p]]");//false
[a-z&&[def]]: a-z和def的交集。为: d, e, f
//如果要求两个范围的交集,那么需要写符号&&
//这里如果只写了一个&,那么就不表示为一个交集了,就是单纯的一个&符号,没有任何含义
sout("a".metches("[a-z&&[def]]");//false
sout("a".metches("[a-z&[def]]");//true
sout("d".metches("[a-z&&[def]]");//true
sout("&".metches("[a-z&[def]]");//true
sout("0".metches("[a-z&[def]]");//false
[a-z&&[^bc]:a-z和非bc的交集。(等同于[ad-z])
sout("a".metches("[a-z&&[^bc]");//ture
sout("b".metches("[a-z&&[^bc]");//false
sout("0".metches("[a-z&&[^bc]");//false
[a-z&&[^m-p]:a到z和除了m到p的交集。(等同于[a-lq-z])
sout("a".metches("[a-z&&[^m-p]");//true
sout("m".metches("[a-z&&[^m-p]");//false
sout("0".metches("[a-z&&[^m-p]");//false
2.预定义字符类:
.表示任意一个字符
sout("你".metches(".."))//false,因为有两个. ,所以需要两个字符
sout("你是".metches(".."))//true,
sout("你".metches("."))//true
\\d
因为\是转义字符,所以用\\来表示一个普通的\,则\\d就表示\d,而\d表示任意的一个数字
// 简单来记: 两个\表示一个\
sout("0".metches("\\d"))//true
sout("n".metches("\\d"))//false
sout("21".metches("\\d"))//false
sout("21".metches("\\d\\d"))//true
\\D
sout("n".metches("\\D"))//true
sout("1".metches("\\D"))//false
\\w 只能是一位单词字符[a-zA-Z_0-9]
sout("n".metches("\\w"))//true
sout("_".metches("\\w"))//true
sout("8".metches("\\w"))//true
sout("你".metches("\\w"))//false
\\W 非单词字符
sout("n".metches("\\W"))//false
sout("_".metches("\\W"))//false
sout("0".metches("\\W"))//false
sout("你".metches("\\W"))//true
2.7.2 正则表达式的数量词
正则表达式的数量词,可以一次表示多个字符

// x{6,} 至少出现6位
sout("234jnhs".matches("\\w{6,}"));//true
sout("23sx".matches("\\w{6,}"));//false
//x{4}必须是4位
sout("3424".matches("[a-zA-Z0-9]{4}"))//true
sout("3A424".matches("[a-zA-Z0-9]{4}"))//false
忘记的可以看api文档Pattern类
2.7.3 正则表达式练习
一、

public static void main(String[] args) {
//细节:
//拿着一个正确的数据,从做到右依次去写
//13112345678
//分成三部分:
//第一部分:1表示手机号码只能以1开头
//第二部分:[3-9]表示手机号码第二位只能是3-9之间的
//第三部分: \\d{9}表示任意数字可以出现9次,也只能出现9次
String regex1 = "1[3-9]\\d{9}";
System.out.println("13112345678".matches(regex1));
System.out.println("131".matches(regex1));
System.out.println("------------------------------------------");
//座机号码
//020-2324242 02122442 027-42424 0712-3242434
//思路:
//在书写座机号正则的时候需要把正确的数据分为三部分
//一:区号 0\\d{2,3}
// 0:表示区号一定是以0开头的
// \\d{2,3}:表示区号从第二位开始可以是任意的数字,可以出现2到3次
//二:- ?表示次数,0或一次
//三:号码 号码的第一位也不能以0开头,从第二位开始可以是任意的数字,号码的总长度:5-10位
String regex2 = "0\\d{2,3}-?[1-9]\\d{4,9}";
System.out.println("020-2324242".matches(regex2));
System.out.println("0712-3242434".matches(regex2));
System.out.println("------------------------------------------");
//邮箱号码
//[email protected] [email protected] [email protected] [email protected]
//思路:
//在书写邮箱号码正则的时候需要把正确的数据分为三部分
//第一部分:@的左边 \\w+,一个非单词字符串出现多次
//任意的字母数字下划线,至少出现一次就可以了
//第二部分:@ 只能出现一次
//第三部分: . 的左边可以是字符也可以是数字 [\\w&&[^_]]{2,6}
// 任意的字母加数字,总共出现2-6次(此时不能出现下划线)
// . \\.
// 大写字母,小写字母都可以,只能出现2-3次[a-zA-Z]{2,3)
String regex3 = "\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2}";
System.out.println("[email protected]".matches(regex3));
System.out.println("[email protected]".matches(regex3));
}

在实际开发中,使用anyrule插件可以快捷创建正则表达式
右键点击

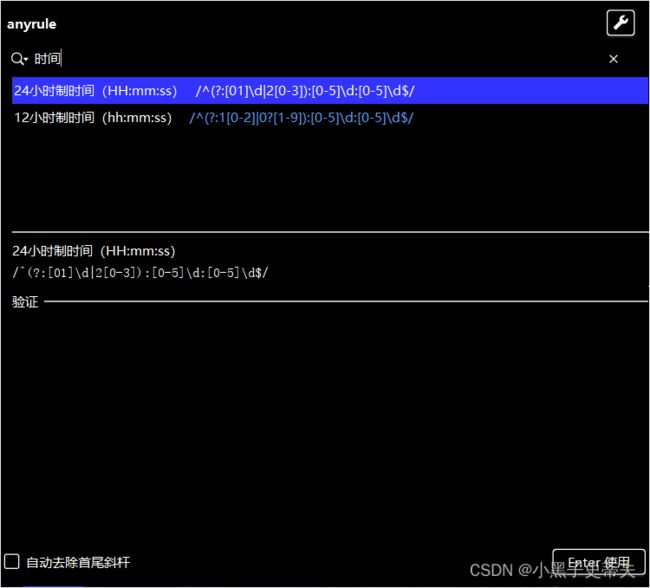
根据时间需求,把开头和末尾的符号删掉
String regex4="(?:[01]\\d|2[0-3]):[0-5]\\d:[0-5]\\d";
以:作为区分
//24小时的正则表达式 23:11:11
String regex4 = "([01]\\d|2[0-3]):[0-5]\\d:[0-5]\\d";
System.out.println("23:11:11".matches(regex4));//true
//优化
String regex5 = "([01]\\d|2[0-3])(:[0-5]\\d){2}";
System.out.println("23:11:11".matches(regex5));//true
二、

public static void main(String[] args) {
//用户名要求:大小写字母,数字,下划线一共4-16位
String regex1 = "\\w{4,16}";
System.out.println("magua".matches(regex1));
System.out.println("------------------------------------------");
//身份证号码的简单校验:
//18位,前17位任意数字,最后一位可以是数字可以是大写或小写的x
String regex2 = "[1-9]\\d{16}(\\d|X|x)";
System.out.println("41080119930228457x".matches(regex2));
//另类写法方式一
String regex3 = "[1-9]\\d{16}[\\dXx]";
System.out.println("510881197609822309".matches(regex3));
System.out.println("------------------------------------------");
//忽略大小写的书写方式
//在匹配的时候忽略abc的大小写
//方式二
String regex4 = "a((?i)b)c";//表示只忽略a后面b的大小写
System.out.println("abc".matches(regex4));//true
System.out.println("ABC".matches(regex4));
System.out.println("aBc".matches(regex4));
System.out.println("------------------------------------------");
//方式三
String regex5 = "[1-9]\\d{16}(\\d|(?i)x)";
System.out.println("15040119810705387X".matches(regex5));
System.out.println("------------------------------------------");
//身份证号码的严格校验
//4108011993 02 28 457x
//前面6位:省份,市区,派出所等信息﹑第一位不能是0,后面5位是任意数字 [1-9]\\d{5}
//年的前半段:18 19 20 (18|19|20)
//年的后半段:任意数字出现两次 \\d{2}
//月份: 01 ~ 09 10 11 12 (0[1-9]|1[0-2])
//日期: 01 ~ 31 10~19 20~29 30 31 (0[1-9]|[12]\\d|3[01])
//后面四位:
//任意数字出现3次最后一位可以是数字也可以是大写x或者小写x \\d{3}[\\dXx]
//编写正则的小心得:
//第一步:按照正确的数据进行拆分
//第二步:找每一部分的规律,并编写正则表达式
//第三步:把每一部分的正则拼接在一起,就是最终的结果书写的时候:从左到右去书写。
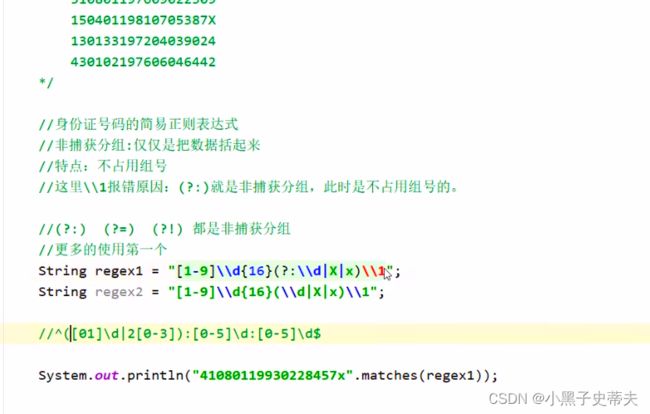
String regex6 = "[1-9]\\d{5}(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\\d|3[01])\\d{3}[\\dXx]";
String regex7 = "[1-9]\\d{5}(18|19|20)\\d{2}(0\\d|10|11|12)(0[1-9]|[1-2]\\d|30|31)\\d{3}[\\dXx]";
System.out.println("41080119930228457x".matches(regex6));
System.out.println("41080119930228457x".matches(regex7));
}

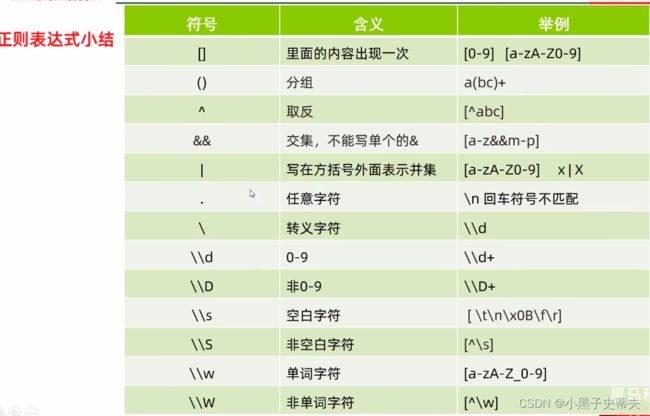
小结(一些符号的作用):

2.7.4 爬虫
爬虫即在一段文本中查找满足的内容
使用的两个类:
- Pattern:表示正则表达式
获取正则表达式的对象:
通过Pattern的静态方法complie获取正则表达式的对象
Pattern p=Pattern.compile(“Java\d{0,2}”);
- Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取,在大字符串中去找符合匹配规则的字串
1.通过Matcher获取文本匹配器的对象
Matcher m=p.matcher(str);(用m读取str,按照p的规则找里面的小串)2.通过循环获取每一个满足条件的值,循环里通过Matcher的group方法获取具体字符串,循环的条件是由Matcher对象的find方法来判断循环是否停止
练习1:

ctrl + alt + m 快捷键 选中内容快捷包含生成一个方法
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public static void main(String[] args) {
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版木,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//通过Pattern的静态方法complie获取正则表达式的对象
//获取文本匹配器的对象
//m:文本匹配器的对象
//str:大串
//p:规则
//解释:m要在str中找符合p规则的小串
Matcher m = p.matcher(str);
//拿着文本匹配器从头开始读取,寻找是否有满足规则的子串
//如果没有,方法返回false
//如果有,返回true,在底层记录字串的起始索引喝结束索引+1
//0,4
boolean b = m.find();
//方法底层会根据find方法记录的索引进行字符串的截取
//subString(起始索引,结束索引);包头不包尾
//(0,4)但是不包含4索引
//会把截取的小串进行返回
String s1 = m.group();
System.out.println(s1);
//第二次在调用find的时候,会继续读取后面的内容
//读取到第二个满足要求的字串,方法会继续返回true
//并把第二个子串的起始索引和结束索引+1,进行记录
b = m.find();
//第二次调用group方法的时候,会根据find方法记录的索引再次截取子串
String s2 = m.group();
System.out.println(s2
);
}

但是,这样写有个弊端,就是不能找到所有符合p正则条件的
修改:
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版木,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//method1(str);
//1.获取正则表达式的对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//2.获取文本匹配器的对象
//拿着m去读取str,找到符合p规则的字符
Matcher m = p.matcher(str);
//3.利用循环获取所以符合p规则的
while(m.find()){
String s = m.group();
System.out.println(s);
}

练习2:

import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexDemo1 {
public static void main(String[] args) {
/*
手机号正则表达式:1[3-9]\d{9}
邮箱正则表达式:\w+@[\w&&[^_]]{2,6}(\.[a-zA-Z]{2,3}}){1,2}
座机电话表达式:0\d{2,3}-?[1-9]\d{4,9}
热线电话表达式:400-?[1-9]\\d{2}-?[1-9]\\d{3}
*/
String s ="来黑马程序员学习Java, "+
"电话:18512516758,18512508907"+
"或者联系邮箱: [email protected], " +
"座机电话: 01036517895,010-98951256"+
"邮箱: [email protected]," +
"热线电话: 400-618-9090 , 400-618-4080,4006184008,4006189090";
String regex = "(1[3-9]\\d{9})" +
"|(\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}}){1,2})" +
"|(0\\d{2,3}-?[1-9]\\d{4,9})" +
"|(400-?[1-9]\\d{2}-?[1-9]\\d{3})";
//1.获取正则表达式的对象
Pattern p = Pattern.compile(regex);
//2.获取文本匹配器的对象
//利用m去读取s,会按照p的规则找里面的小串
Matcher m = p.matcher(s);
//3.利用循环获取每一个数据
while (m.find()){
String str = m.group();
System.out.println(str);
}
}
}

一、带条件的数据爬取

import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String s="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版木是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.定义正则表达式
//?理解位前面的数据Java
//=表示在Java后面要跟随的数据
//但是在获取的时候,只获取前半部分
//需求1:
String regex1 = "((?i)Java)(?=8|11|17)";
//需求2:
String regex2 = "((?i)Java)(8|11|17)";
String regex3 = "((?i)Java)(?:8|11|17)";//?:同样表示2的效果,选取中有的
//需求3:
String regex4 = "((?i)Java)(?!8|11|17)";
Pattern p = Pattern.compile(regex1);
Matcher m = p.matcher(s);
while (m.find()){
System.out.println(m.group());
}
}
}

二、贪婪爬取和非贪婪爬取
- 贪婪爬取:在爬取时,尽可能多的爬取数据
- 非贪婪爬取:尽可能少爬取数据

Java默认为贪婪爬取
如果我们在数量词+ *后加上问号,那么此时就是非贪婪爬取

import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String s="Java自从95年问世以来,abbbbbbbbbbbbbbbbaaaaaaaaaaaaaaaaaaaa" +
"经历了很多版本,目前企业中用的最多的是Java8和Java11," +
"因为这两个是长期支持版本,下一个长期支持版木是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
String regex1 = "ab+?";
String regex2 = "ab+";
Pattern p1 = Pattern.compile(regex1);
Matcher m1 = p1.matcher(s);
Pattern p2 = Pattern.compile(regex2);
Matcher m2 = p2.matcher(s);
while(m1.find()){
System.out.println(m1.group());
}
while(m2.find()){
System.out.println(m2.group());
}
}
}

2.7.5 正则表达式在字符串方法中的使用

如果说字符串方法的形参名字为regex,那么就能识别正则表达式

练习:
public static void main(String[] args) {
String s="小实时jasndjasnoid1231小淡淡ndasjkldnan213131小灰灰";
//细节:
//方法在底层跟之前一样也会创建文本解析器的对象
//然后从头开始去读取字符串的内容,只要有满足的,那么久用第二个参数去替换
String result = s.replaceAll("[\\w&&[^_]]+","vs");
System.out.println(result);
String[] arr = s.split("[\\w&&[^_]]+");
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}

2.7.6 分组
分组就是一个小括号
与数学的计算相似
在正则表达式中,\\x(组号)就表示把第x组的数据再拿出来用一次
每组是有组号的 ,也就是序号
- 规则1;从1开始,连续不间断
- 规则2;
以左括号为基准,最左边的是第一组,其次为第二组,依次类推

(1)捕获分组
练习1:

public static void main(String[] args) {
//a123a b2324b c1234c d2131a(false)
String regex1="(.).+\\1";
// (.)表示首字符可以是任意的
// .+表示在该中间是任意的
// \\1 表示把第1组的内容再拿出来用一次,也就是(.)里面的首字母,再后面也必须要相同
System.out.println("a123a".matches(regex1));
System.out.println("b2324b".matches(regex1));
System.out.println("c1234c".matches(regex1));
System.out.println("d2131a".matches(regex1));
System.out.println("——————————————————————————————————————————————————");
//abc213abc
String regex2="(.+).+\\1";
// (.+)表示任意一个字符至少出现一次
System.out.println("abc123abc".matches(regex2));
System.out.println("bc2324bc".matches(regex2));
System.out.println("csx1234csx".matches(regex2));
System.out.println("dz2131ac".matches(regex2));
System.out.println("——————————————————————————————————————————————————");
//aaa123aaa
//括起来两个括号之后,表示两组,\\1 就要变成 \\2了
//这里的\\2:把第2组再拿出来再使用
// *: 作用于\\2,表示是后面重复的内容出现0次或多次
// 大括号的一个整体,后面的\\1表示拿出来一个整体用
String regex3="((.)\\2*).+\\1";
System.out.println("aaa123aaa".matches(regex3));
System.out.println("aaa123aab".matches(regex3));
}


练习2:

public static void main(String[] args) {
String str="我要学学编编编编编编编编程程程程程程程程程程程";
//需求:把重复的内容替换为单个的学学
//学学 学
//编编编编 编
//程程程程程程 程
//(.) 表示把重复内容的第一个字符看作第一组
// \\1 表示第一个字符再次出现
// + 表示至少一次
// $1 表示把正则表达式中第一组的内容,再拿出来用
String result = str.replaceAll("(.)\\1+","$1");
System.out.println(result);
}

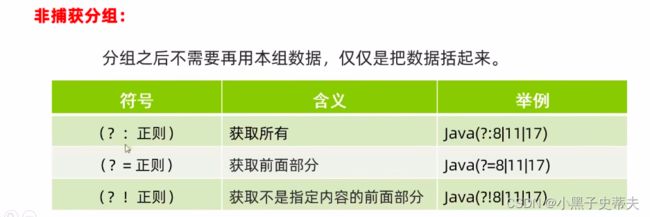
(2)非捕获分组
分组之后不需要再用本组数据,仅仅是把数据括起来,不占用组号,不能用\\组号来使用非捕获
上述表格就的具体案例就在带条件的数据爬取
小结:

2.8 JDK7时间
JDK7时间有三个类
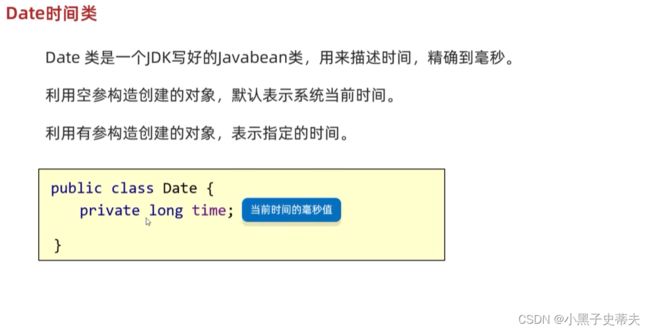
Date:时间类
SimpleDateFormat: 格式化时间类

Calender: 日历类
2.8.1 Date 时间
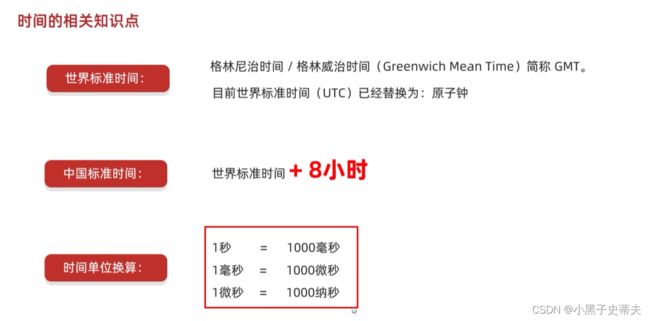
时间的相关知识
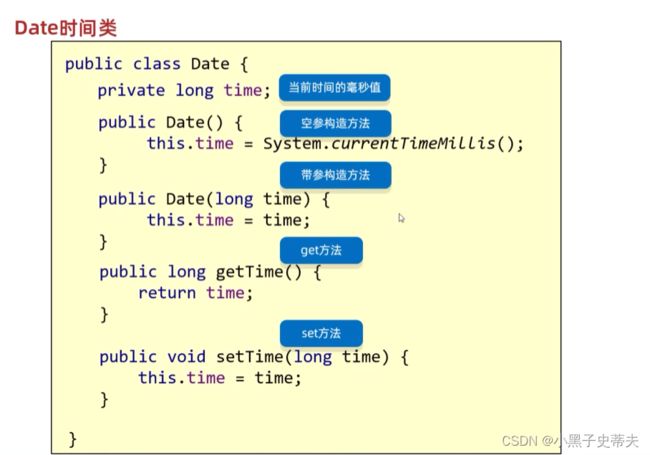
Date的常用方法:
| 方法名 | 作用 |
|---|---|
| public Date() | 创建Date对象,表示当前时间 |
| public Date(long date) | 创建Date对象,表示指定时间 |
| public void setTime(long time) | 设置/修改毫秒值 |
| public long getTime | 获取时间对象的毫秒值 |
展示:
注意导包一定要点java.lang的
public static void main(String[] args) {
//1.创建对象表示一个时间
Date d1 = new Date();
System.out.println(d1);
//2.创建对象表示一个指定的时间
Date d2 = new Date(0L);//对于long类型的,可以加个L
System.out.println(d2);//表示从时间原点开始过了0毫秒
//3.setTime 修改时间
d2.setTime(1000L);
System.out.println(d2);//在时间原点上过了1000毫秒,也就是1秒
//4.getTime获取当前时间的毫秒值
long time = d2.getTime();//在左边基础上 ctrl + alt + v
System.out.println(time);
}
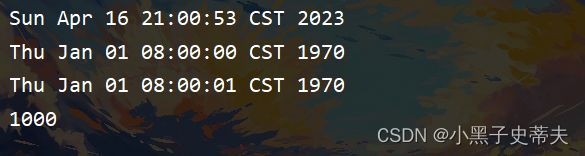
练习:

public static void main(String[] args) {
Random r=new Random();
//创建两个时间对象
Date d2=new Date(Math.abs(r.nextInt()));
Date d3=new Date(Math.abs(r.nextInt()));
long time1 = d2.getTime();
long time2 = d3.getTime();
if(time1>time2){
System.out.println("第一个时间在后面,第二个时间在前面");
}else if(d2.getTime()< d3.getTime()){
System.out.println("第二个时间在后面,第一个时间在前面");
}else{
System.out.println("表示两个时间一样");
}
method1();
}
private static void method1() {
//1.创建一个对象,表示时间原点
Date d1=new Date(0L);
//2.获取的时间的毫秒值
long time=d1.getTime();
//3.在这个基础上我们要加一年的毫秒值即可
time=time+1000L*60*60*24*365;
//4.把计算之后的时间毫秒值,再设置回d1当中
d1.setTime(time);
System.out.println(d1);
}

小结:
