ch05-学习率调整策略、可视化与Hook
ch05-学习率调整策略、可视化与Hook
-
- 0.引言
- 1.学习率调整策略
-
- 1.1.为什么要调整学习率?
- 1.2.Pytorch提供的六种学习率调整策略
- 1.3.学习率调整策略总结
- 2.TensorBoard 介绍
-
- 1.1.SummaryWriter
- 1.2.add_scalar
- 1.3.add_scalars
- 1.4.add_histogram
- 1.5.模型指标监控
- 1.6.add_image
- 1.6.torchvision.utils.make_grid
- 1.7.AlexNet 卷积核与特征图可视化
- 1.8.add_graph
- 1.9.torchsummary
- 3.Hook 函数与 CAM 算法
-
- 3.1.Hook 函数概念
- 3.2.hook函数实现机制
- 3.3.Hook 函数提取网络的特征图
0.引言
1.学习率调整策略
-
官方文档
-
参考博客1
-
参考博客2
前面的课程学习了优化器的概念,优化器中有很多超参数如学习率lr,momentum动量、weight_decay系数,这些超参数中最重要的就是学习率。学习率可以直接控制模型参数更新的步伐,此外,在整个模型训练过程中学习率也不是一成不变的,而是可以调整变化的。本节内容就可以分为以下3方面展开,分别是:
- (1)为什么要调整学习率?
- (2)Pytorch的六种学习率调整策略;
- (3)学习率调整总结。
1.1.为什么要调整学习率?
- 仅考虑学习率的梯度下降:
w i + 1 = w i − l r ∗ g ( w i ) w_{i+1}=w_i-lr*g(w_i) wi+1=wi−lr∗g(wi)
- 加入momentum系数后随机梯度下降更新公式:
v i = m ∗ v i − 1 + ∗ g ( w i ) v_{i}=m*v_{i-1}+*g(w_i) vi=m∗vi−1+∗g(wi) w i + 1 = w i + l r ∗ v i w_{i+1}=w_i+lr*v_{i} wi+1=wi+lr∗vi
从梯度下降法公式可知,参数更新这一项中会有学习率乘以梯度或更新量( l r ∗ g ( w i ) o r ( l r ∗ v i lr*g(w_i) or (lr*v_{i} lr∗g(wi)or(lr∗vi),学习率lr直接控制了模型参数更新的步伐。通常,在模型训练过程中,学习率给的比较大,这样可以让模型参数在初期更新比较快;到了后期,学习率有所下降,让参数更新的步伐减慢。可是,为什么会在模型训练时对学习率采用 “前期大、后期小” 的赋值特点呢?
由图可知,一开始球距离洞口很远,将球打进洞口这一过程形如模型训练中让Loss逐渐下降至0这一过程。
- (1)球距离洞口很远,利用较大的力度去打球,让球快速的飞跃到洞口附近,这就是一开始采用大学习率训练模型的原因;
- (2)球来到洞口附近,调整力度,轻轻击打球,让球可控、缓慢的朝洞口接近。这就是学习率到了后期,让参数更新的步伐小一点,使得Loss逐渐下降。
这就学习率前期大、后期小的1个形象比喻。下面以函数的优化过程理解学习率“前期大、后期小”的原因。

Pytorch提供的六种学习率调整策略都是继承于LRScheduler基类,因此首先学习LRScheduler基本属性和基本方法。
(1)class_LRScheduler
class_LRScheduler(object)
主要属性:
- optimizer:关联的优化器
- last_epoch:记录epoch数
- base_lrs:记录初始学习率
主要属性:
- optimizer:学习率所关联的优化器。已知优化器如torch.optim.SGD才是存放学习率lr的,LRScheduler 会去修改优化器中的学习率。所以LRScheduler必须要关联1个优化器才能改动优化器里面的学习率。
optim.SGD(params,lr=<object object>, momentum=0,dampening=0, weight_decay=0,nesterov=False) - last_epoch:记录epoch数。整个学习率调整是以epoch为周期,不要以iteration。
- base_lrs:记录初始学习率。
(2)LRScheduler的_init_函数
class_LRScheduler(object)
def_init_(self,optimizer.last_epoch=-1):
只接受2个参数,分别是optimizer和last_epoch = -1。
主要方法
-
step()——
更新下一个epoch的学习率 一定要放在epoch中而不是iteration。 -
get_lr()——虚函数,
计算下一个epoch的学习率
1.2.Pytorch提供的六种学习率调整策略
1、StepLR
- 功能:等间隔调整学习率
lr_scheduler.StepLR(optimizer,step_size,gamma,last_epoch=-1)
- 主要参数:step_size调整间隔数 gamma调整系数。设置step_size=50,每隔50个epoch时调整学习率,具体是用当前学习率乘以gamma即(lr=lr*gamma) ;
- 调整方式:( l r = l r ∗ g a m m a lr=lr*gamma lr=lr∗gamma) (gamma通常取0.1缩小10倍、0.5缩小一半)
实验
LR = 0.1 //设置初始学习率
iteration = 10
max_epoch = 200
# --------- fake data and optimizer ---------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
//构建虚拟优化器,为了 lr_scheduler关联优化器
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ---------------- 1 Step LR --------
# flag = 0
flag = 1
if flag:
//设置optimizer、step_size等间隔数量:多少个epoch之后就更新学习率lr、gamma
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
//优化器参数更新
optimizer.step()
optimizer.zero_grad()
//学习率更新
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
结果

2、MultiStepLR
- 功能:按给定间隔调整学习率
lr_scheduler.MultiStepLR(optimizer,milestones,gamma,last_epoch=-1)
- 主要参数:milestones设定调整时刻数 gamma调整系数.如构建个list设置milestones=[50,125,180],在第50次、125次、180次时分别调整学习率,具体是用当前学习率乘以gamma即(lr=lr*gamma) ;
- 调整方式:( l r = l r ∗ g a m m a lr=lr*gamma lr=lr∗gamma) (gamma通常取0.1缩小10倍、0.5缩小一半)
# ------------------------------ 2 Multi Step LR ------------------------------
# flag = 0
flag = 1
if flag:
milestones = [50, 125, 160]
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
3、ExponentialLR
- 功能:按指数衰减调整学习率
lr_scheduler.ExponentialLR(optimizer,milestones,gamma,last_epoch=-1)
- 主要参数: gamma指数的底。如构建个list设置milestones=[50,125,180],在第50次、125次、180次时调整学习率,具体是用当前学习率乘以gamma即( l r = l r ∗ g a m m a lr=lr*gamma lr=lr∗gamma) ;
- 调整方式:( l r = l r ∗ g a m m a ∗ ∗ e p o c h lr=lr*gamma**epoch lr=lr∗gamma∗∗epoch) (gamma通常会设置为接近于1的数值,如0.95;( l r = l r ∗ g a m m a e p o c h → 0.1 ∗ 0.9 5 1 → 0.1 ∗ 0.9 5 2 lr=lr*gamma^{epoch}→0.1*0.95^1→0.1*0.95^2 lr=lr∗gammaepoch→0.1∗0.951→0.1∗0.952))
# ------------- 3 Exponential LR -----------
# flag = 0
flag = 1
if flag:
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
...
结果
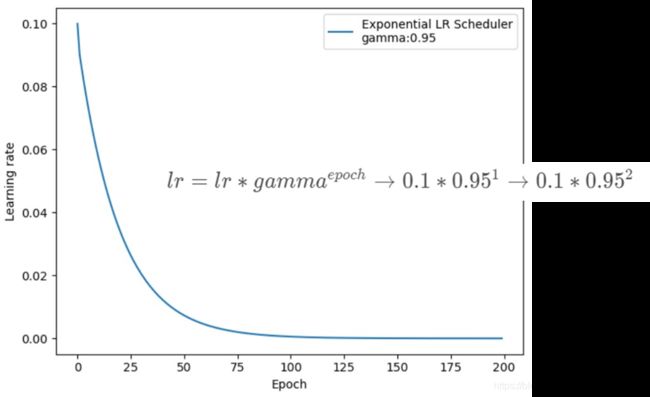
按指数衰减调整学习率ExponentialLR
4、CosineAnnealingLR
- 功能:余弦周期调整学习率
lr_scheduler.ExponentialLR(optimizer,T_max,eta_min=0,last_epoch=-1)
- 主要参数: T_max下降周期,eta_min学习率下限
调整方式:
η t = η m i n + 1 2 ( η m a x − η m i n ) ( 1 + c o s ( T c u r T m a x π ) ) \eta_t=\eta_{min}+\frac{1}{2}(\eta_{max}-\eta_{min})(1+cos(\frac{T_{cur}}{T_{max}}\pi)) ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ))
结果

余弦周期调整学习率CosineAnnealingLR
5、ReduceLRonPlateau
- 功能:监控指标,当指标不再变化则调整(很实用)。比如监控Loss不再下降、或者分类准确率acc不再上升就进行学习率的调整。
lr_scheduler.ExponentialLR(optimizer,mode='min',
factor=0.1,patience=10,verbose=False,threshold=0.0001,
threshold_mode='rel',cooldown=0,min_lr=0,eps=1e-08)
主要参数:
- mode:min/max两种模式;
- 在min模式下,观察监控指标是否下降,用于监控Loss;
- 在max模式下观察监控指标是否上升,用于监控分类准确率acc。
- fator调整系数——相当于上面几种调整策略中的gamma值;
- patience:“耐心”,接收几次不变化;一定要连续多少次不发生变化(patience=10,某指标连续10次epoch没有变化就进行lr调整)
- cooldown:“冷却时间”,停止监控一段时间;(cooldown=10,某指标连续10次epoch没有变化就进行lr调整)
- verbose:是否打印日志;布尔变量;
- min_lr:学习率下限;
- eps:学习率衰减最小值。
# ------------------- 5 Reduce LR On Plateau -----
# flag = 0
flag = 1
if flag:
loss_value = 0.5
accuray = 0.9
factor = 0.1
mode = "min"
patience = 10
cooldown = 10
min_lr = 1e-4
verbose = True
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,
cooldown=cooldown, min_lr=min_lr, verbose=verbose)
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
# if epoch == 5:
# loss_value = 0.4
scheduler_lr.step(loss_value)
6、LambdaLR
- 功能:自定义调整策略
lr_scheduler.ExponentialLR(optimizer,lr_lambda,last_epoch=-1)
- 主要参数:
- lr_lambda:function or list
- 如果是1个list,每1个元素也必须是1个function。
该方法适用于对不同的参数组设置不同的学习率调整策略。
# ------------------------------ 6 lambda ------------------------------
# flag = 0
flag = 1
if flag:
lr_init = 0.1
weights_1 = torch.randn((6, 3, 5, 5))
weights_2 = torch.ones((5, 5))
optimizer = optim.SGD([
{'params': [weights_1]},
{'params': [weights_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
scheduler.step()
lr_list.append(scheduler.get_lr())
epoch_list.append(epoch)
print('epoch:{:5d}, lr:{}'.format(epoch, scheduler.get_lr()))
plt.plot(epoch_list, [i[0] for i in lr_list], label="lambda 1")
plt.plot(epoch_list, [i[1] for i in lr_list], label="lambda 2")
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.title("LambdaLR")
plt.legend()
plt.show()
1.3.学习率调整策略总结
- 1、有序调整:Step、MultiStep、Exponential 和CosineAnnealing
学习率更新之前,就知道学习率在什么时候会调整、调整为多少; - 2、自适应调整:ReduceLROnPleateau
监控某一个参数,当该参数不再上升或下降就进行学习率调整。 - 3、自定义调整:lambda
存在多个参数组,且需要对多个参数组设置不同的学习率调整策略可采用。
要调整学习率,至少应当具有初始学习率,那么该如何设置初始学习率?
- (1)设置较小数:10e-2(0.01)、10e-3(0.001)、10e-4(0.0001);
- (2)搜索最大学习率 《Cyclical learning Rates for Training Nerual Networks》
2.TensorBoard 介绍
- 参考博客1
- 参考博客2
- 参考博客3
TensorBoard 是 TensorFlow 中强大的可视化工具,支持标量、文本、图像、音频、视频和 Embedding 等多种数据可视化。

- 学习之前,回顾tensorboard运行机制:首先在python脚本里
- ①记录要可视化的数据,然后,这些
- ②数据以event file形式存储到硬盘中,最后在
- ③终端读取event file在tensorboard可视化,展示在web端。
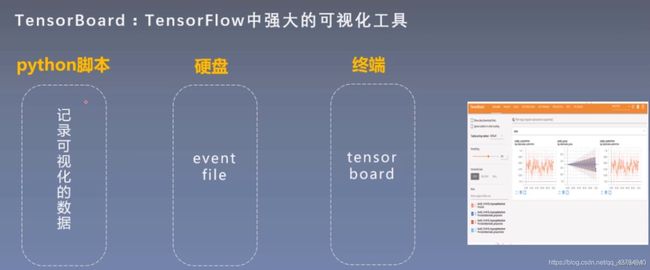
在 PyTorch 中也可以使用 TensorBoard,具体是使用 TensorboardX 来调用 TensorBoard。除了安装 TensorboardX,还要安装 TensorFlow 和 TensorBoard,其中 TensorFlow 和 TensorBoard 需要一致。
TensorBoardX 可视化的流程需要首先编写 Python 代码把需要可视化的数据保存到 event file 文件中,然后再使用 TensorBoardX 读取 event file 展示到网页中。
下面的代码是一个保存 event file 的例子:
import numpy as np
import matplotlib.pyplot as plt
from tensorboardX import SummaryWriter
from common_tools import set_seed
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x)
writer.close()
上面具体保存的数据,我们先不关注,主要关注的是保存 event file 需要用到 SummaryWriter 类,这个类是用于保存数据的最重要的类,执行完后,会在当前文件夹生成一个runs的文件夹,里面保存的就是数据的 event file。
然后在命令行中输入 tensorboard --logdir=lesson5/runs启动 tensorboard 服务,其中lesson5/runs是runs文件夹的路径。然后命令行会显示 tensorboard 的访问地址.
我启动成功的命令行:
tensorboard --logdir=runs --bind_all
# 需要关闭科学上网
TensorBoard 1.15.0 at http://*****:6006 (Press CTRL+C to quit)
在浏览器中打开,显示如下:

最上面的一栏显示的是数据类型,由于我们在代码中只记录了 scalar 类型的数据,因此只显示SCALARS。
右上角有一些功能设置

点击INACTIVE显示我们没有记录的数据类型。设置里可以设置刷新 tensorboard 的间隔,在模型训练时可以实时监控数据的变化。
左边的菜单栏如下,点击Show data download links可以展示每个图的下载按钮,如果一个图中有多个数据,需要选中需要下载的曲线,然后下载,格式有 csv和json可选。
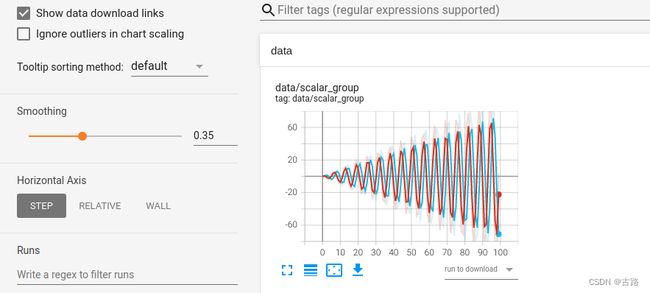
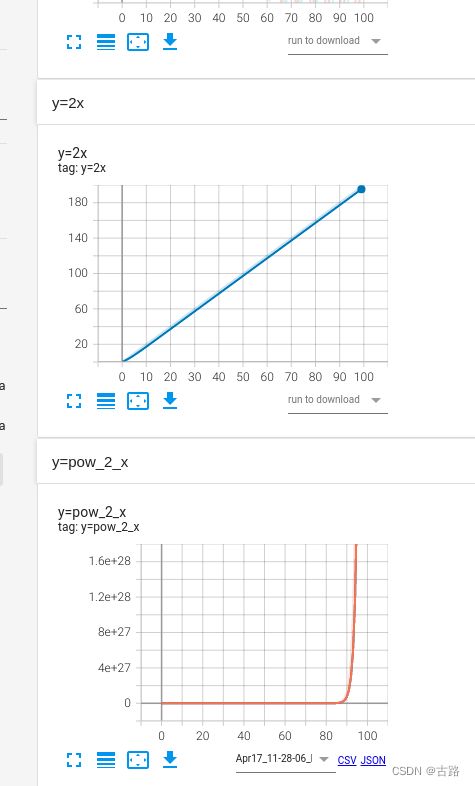
第二个选项Ignore outliers in chart scaling可以设置是否忽略离群点,在y_pow_2_x中,数据的尺度达到了 1 0 18 10^{18} 1018,勾选Ignore outliers in chart scaling后 y 轴的尺度下降到 1 0 17 10^{17} 1017。

Soothing 是对图像进行平滑,下图中,颜色较淡的阴影部分才是真正的曲线数据,Smoothing 设置为了 0.6,进行了平滑才展示为颜色较深的线。

Smoothing 设置为 0,没有进行平滑,显示如下:

Smoothing 设置为 1,则平滑后的线和 x 轴重合,显示如下:

Horizontal Axis表示横轴:STEP表示原始数据作为横轴,RELATIVE和WALL都是以时间作为横轴,单位是小时,RELATIVE是相对时间,WALL是绝对时间。
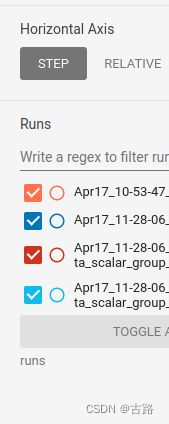
runs显示所有的 event file,可以选择展示某些 event file 的图像,其中正方形按钮是多选,圆形按钮是单选。
1.1.SummaryWriter
torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
- 功能:提供创建 event file 的高级接口
主要功能:
- log_dir:event file 输出文件夹,默认为runs文件夹
- comment:不指定 log_dir 时,runs文件夹里的子文件夹后缀
- filename_suffix:event_file 文件名后缀
代码如下:
log_dir = "./train_log/test_log_dir"
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
# writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
运行后会生成train_log/test_log_dir文件夹,里面的 event file 文件名后缀是12345678。

但是我们指定了log_dir,comment参数没有生效。如果想要comment参数生效,把SummaryWriter的初始化改为writer = SummaryWriter(comment='_scalars', filename_suffix="12345678"),生成的文件夹如下,runs里的子文件夹后缀是_scalars。

writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
主要属性:
- log_dir:event file 输出文件夹
- comment:不指定log_dir时,文件名后缀
- filename_suffix:event file文件名后缀
3个属性都与要创建的路径有关。
- (1)log_dir:event_file 输出文件夹,通常采用默认参数即不设置;如果不设置log_dir,会在当前 .py文件当前文件夹下创建1个runs文件夹(如:runs/Aug18_16-09-46_LAPTOP-73TM5PNOtest_tensorboard/event…)

- (2)comment:不指定log_dir时,添加文件名后缀
- (3)filename_suffix:添加 event file文件名后缀
实验
- (1)设置log_dir,创建出来的文件有什么特点?
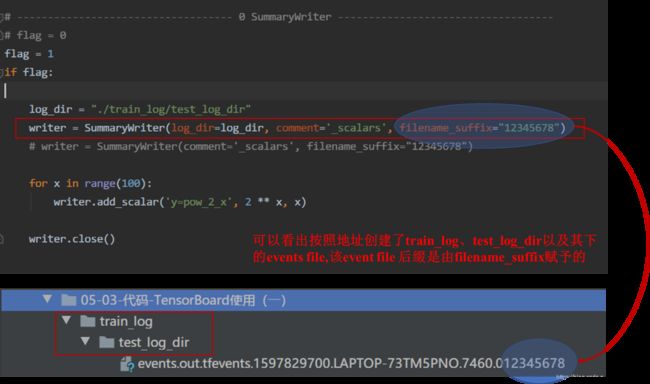
- (2)不设置log_dir,创建出来的文件有什么特点?

通常不会采用默认形式,而是要设置log_dir的具体路径,保证代码和训练数据隔离开来,便于管理。
1.2.add_scalar
add_scalar(tag, scalar_value, global_step=None, walltime=None)
- 功能:记录标量
- tag:图像的标签名,图的唯一标识
- scalar_value:要记录的标量,y 轴的数据
- global_step:x 轴的数据
1.3.add_scalars
上面的add_scalar()只能记录一条曲线的数据。但是我们在实际中可能需要在一张图中同时展示多条曲线,比如在训练模型时,经常需要同时查看训练集和测试集的 loss。这时我们可以使用add_scalars()方法
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
- main_tag:该图的标签
- tag_scalar_dict:用字典的形式记录多个曲线。key 是变量的 tag,value 是变量的值
代码如下:
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x)
writer.close()
运行后生成 event file,然后使用 TensorBoard 来查看如下:
1.4.add_histogram
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
- 功能:统计直方图与多分位折线图
- tag:图像的标签名,图的唯一标识
- values:要统计的参数,通常统计权值、偏置或者梯度
- global_step:第几个子图
- bins:取直方图的 bins
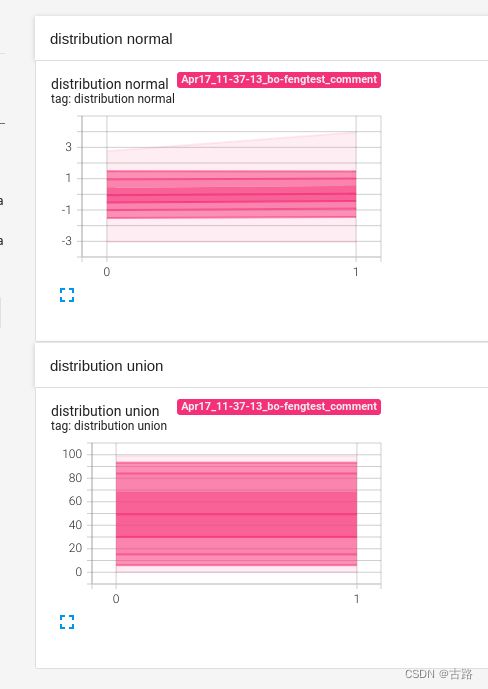
下面的代码构造了均匀分布和正态分布,循环生成了 2 次,分别用matplotlib和 TensorBoard 进行画图。
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
data_union = np.arange(100)
data_normal = np.random.normal(size=1000)
writer.add_histogram('distribution union', data_union, x)
writer.add_histogram('distribution normal', data_normal, x)
plt.subplot(121).hist(data_union, label="union")
plt.subplot(122).hist(data_normal, label="normal")
plt.legend()
plt.show()
writer.close()
matplotlib画图显示如下:


TensorBoard 显示结果如下。
正态分布显示如下,每个子图分别对应一个 global_step:

均匀分布显示如下,显示曲线的原因和bins参数设置有关,默认是tensorflow:

除此之外,还会得到DISTRIBUTIONS,这是多分位折线图,纵轴有 9 个折线,表示数据的分布区间,某个区间的颜色越深,表示这个区间的数所占比例越大。横轴是 global_step。这个图的作用是观察数方差的变化情况。显示如下:
1.5.模型指标监控
下面使用 TensorBoard 来监控人民币二分类实验训练过程中的 loss、accuracy、weights 和 gradients 的变化情况。
首先定义一个SummaryWriter。
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
然后在每次训练中记录 loss 和 accuracy 的值
# 记录数据,保存于event file
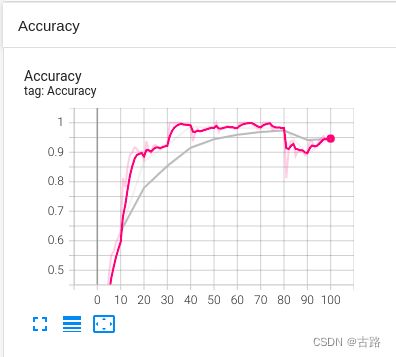
writer.add_scalars("Loss", {"Train": loss.item()}, iter_count)
writer.add_scalars("Accuracy", {"Train": correct / total}, iter_count)
并且在验证时记录所有验证集样本的 loss 和 accuracy 的均值
writer.add_scalars("Loss", {"Valid": np.mean(valid_curve)}, iter_count)
writer.add_scalars("Accuracy", {"Valid": correct / total}, iter_count)
并且在每个 epoch 中记录每一层权值以及权值的梯度。
# 每个epoch,记录梯度,权值
for name, param in net.named_parameters():
writer.add_histogram(name + '_grad', param.grad, epoch)
writer.add_histogram(name + '_data', param, epoch)
在训练还没结束时,就可以启动 TensorBoard 可视化,Accuracy 的可视化如下,颜色较深的是训练集的 Accuracy,颜色较浅的是 验证集的样本:
Loss 的可视化如下,其中验证集的 Loss 是从第 10 个 epoch 才开始记录的,并且 验证集的 Loss 是所有验证集样本的 Loss 均值,所以曲线更加平滑;而训练集的 Loss 是 batch size 的数据,因此震荡幅度较大:

上面的 Loss 曲线图与使用matplotlib画的图不太一样,因为 TensorBoard 默认会进行 Smoothing,我们把 Smoothing 系数设置为 0 后,显示如下:

而记录权值以及权值梯度的 HISTOGRAMS 显示如下,记录了每一层的数据:

展开查看第一层的权值和梯度。

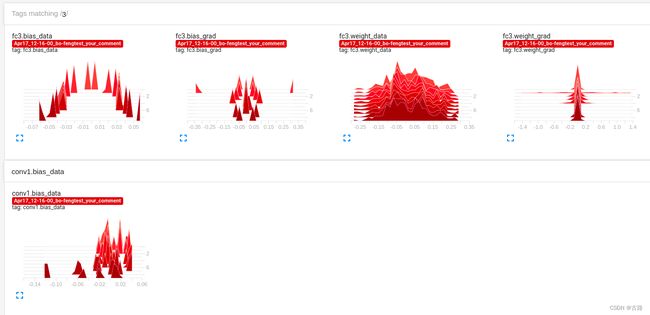
可以看到每一个 epoch 的梯度都是呈正态分布,说明权值分布比较好;梯度都是接近于 0,说明模型很快就收敛了。通常我们使用 TensorBoard 查看我们的网络参数在训练时的分布变化情况,如果分布很奇怪,并且 Loss 没有下降,这时需要考虑是什么原因改变了数据的分布较大的。如果前面网络层的梯度很小,后面网络层的梯度比较大,那么可能是梯度消失,因为后面网络层的较大梯度反向传播到前面网络层时已经变小了。如果前后网络层的梯度都很小,那么说明不是梯度消失,而是因为 Loss 很小,模型已经接近收敛。
1.6.add_image
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
- 功能:记录图像
- tag:图像的标签名,图像的唯一标识
- img_tensor:图像数据,需要注意尺度
- global_step:记录这是第几个子图
- dataformats:数据形式,取值有’CHW’,‘HWC’,‘HW’。如果像素值在 [0, 1] 之间,那么默认会乘以 255,放大到 [0, 255] 范围之间。如果有大于 1 的像素值,认为已经是 [0, 255] 范围,那么就不会放大。
代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# img 1 random
# 随机噪声的图片
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)
# img 2 ones
# 像素值全为 1 的图片,会乘以 255,所以是白色的图片
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image("fake_img", fake_img, 2)
# img 3 1.1
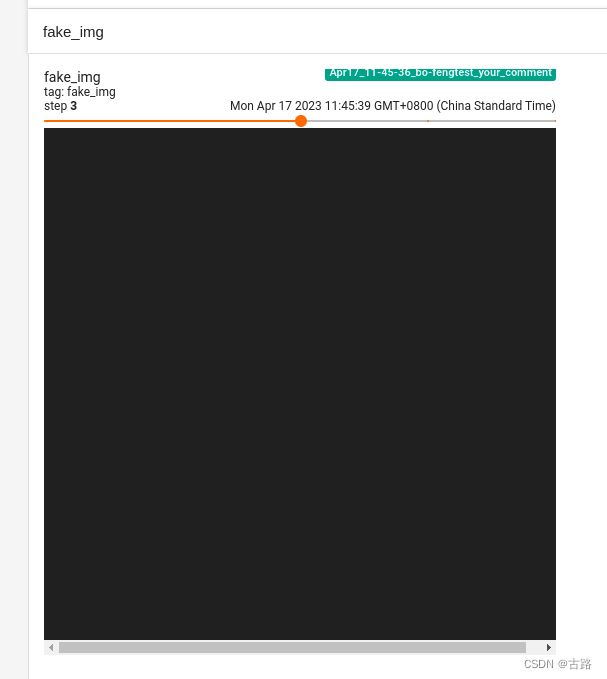
# 像素值全为 1.1 的图片,不会乘以 255,所以是黑色的图片
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)
# img 4 HW
fake_img = torch.rand(512, 512)
writer.add_image("fake_img", fake_img, 4, dataformats="HW")
# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")
writer.close()
使用 TensorBoard 可视化如下:

图片上面的step可以选择第几张图片,如选择第 3 张图片,显示如下:
1.6.torchvision.utils.make_grid
上面虽然可以通过拖动显示每张图片,但实际中我们希望在网格中同时展示多张图片,可以用到make_grid()函数。
torchvision.utils.make_grid(tensor: Union[torch.Tensor, List[torch.Tensor]], nrow: int = 8, padding: int = 2, normalize: bool = False, range: Optional[Tuple[int, int]] = None, scale_each: bool = False, pad_value: int = 0)
- 功能:制作网格图像
- tensor:图像数据,B \times C \times H \times W 的形状
- nrow:行数(列数是自动计算的,为:\frac{B}{nrow})
- padding:图像间距,单位是像素,默认为 2
- normalize:是否将像素值标准化到 [0, 255] 之间
- range:标准化范围,例如原图的像素值范围是 [-1000, 2000],设置 range 为 [-600, 500],那么会把小于 -600 的像素值变为 -600,那么会把大于 500 的像素值变为 500,然后标准化到 [0, 255] 之间
- scale_each:是否单张图维度标准化
- pad_value:间隔的像素值
下面的代码是人民币图片的网络可视化,batch_size 设置为 16,nrow 设置为 4,得到 4 行 4 列的网络图像
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
split_dir = os.path.join(enviroments.project_dir, "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
# train_dir = "path to your training data"
# 先把宽高缩放到 [32, 64] 之间,然后使用 toTensor 把 Image 转化为 tensor,并把像素值缩放到 [0, 1] 之间
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader))
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
# img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)
writer.close()
TensorBoard 显示如下:

1.7.AlexNet 卷积核与特征图可视化
使用 TensorBoard 可视化 AlexNet 网络的前两层卷积核。其中每一层的卷积核都把输出的维度作为 global_step,包括两种可视化方式:一种是每个 (w, h) 维度作为灰度图,添加一个 c 的维度,形成 (b, c, h, w),其中 b 是 输入的维度;另一种是把整个卷积核 reshape 到 c 是 3 的形状,再进行可视化。详细见如下代码:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True)
# 当前遍历到第几层网络的卷积核了
kernel_num = -1
# 最多显示两层网络的卷积核:第 0 层和第 1 层
vis_max = 1
# 获取网络的每一层
for sub_module in alexnet.modules():
# 判断这一层是否为 2 维卷积层
if isinstance(sub_module, nn.Conv2d):
kernel_num += 1
# 如果当前层大于1,则停止记录权值
if kernel_num > vis_max:
break
# 获取这一层的权值
kernels = sub_module.weight
# 权值的形状是 [c_out, c_int, k_w, k_h]
c_out, c_int, k_w, k_h = tuple(kernels.shape)
# 根据输出的每个维度进行可视化
for o_idx in range(c_out):
# 取出的数据形状是 (c_int, k_w, k_h),对应 BHW; 需要扩展为 (c_int, 1, k_w, k_h),对应 BCHW
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
# 注意 nrow 设置为 c_int,所以行数为 1。在 for 循环中每 添加一个,就会多一个 global_step
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
# 因为 channe 为 3 时才能进行可视化,所以这里 reshape
kernel_all = kernels.view(-1, 3, k_h, k_w) #b, 3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=kernel_num+1)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()
使用 TensorBoard 可视化如下。
这是根据输出的维度分批展示第一层卷积核的可视化

这是根据输出的维度分批展示第二层卷积核的可视化

这是整个第一层卷积核的可视化

这是整个第二层卷积核的可视化

下面把 AlexNet 的第一个卷积层的输出进行可视化,首先对图片数据进行预处理(resize,标准化等操作)。由于在定义模型时,网络层通过nn.Sequential() 堆叠,保存在 features 变量中。因此通过 features 获取第一个卷积层。把图片输入卷积层得到输出,形状为 (1, 64, 55, 55),需要转换为 (64, 1, 55, 55),对应 (B, C, H, W),nrow 设置为 8,最后进行可视化,代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "./lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# forward
# 由于在定义模型时,网络层通过nn.Sequential() 堆叠,保存在 features 变量中。因此通过 features 获取第一个卷积层
convlayer1 = alexnet.features[0]
# 把图片输入第一个卷积层
fmap_1 = convlayer1(img_tensor)
# 预处理
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()
使用 TensorBoard 可视化如下:

1.8.add_graph
add_graph(model, input_to_model=None, verbose=False)
- 功能:可视化模型计算图
- model:模型,必须继承自 nn.Module
- input_to_model:输入给模型的数据,形状为 BCHW
- verbose:是否打印图结构信息
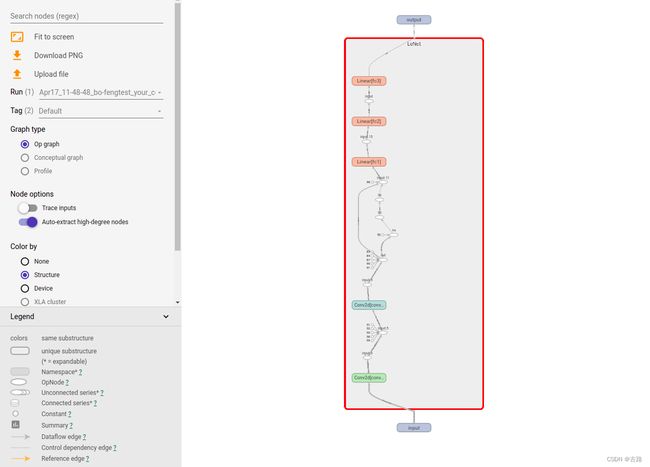
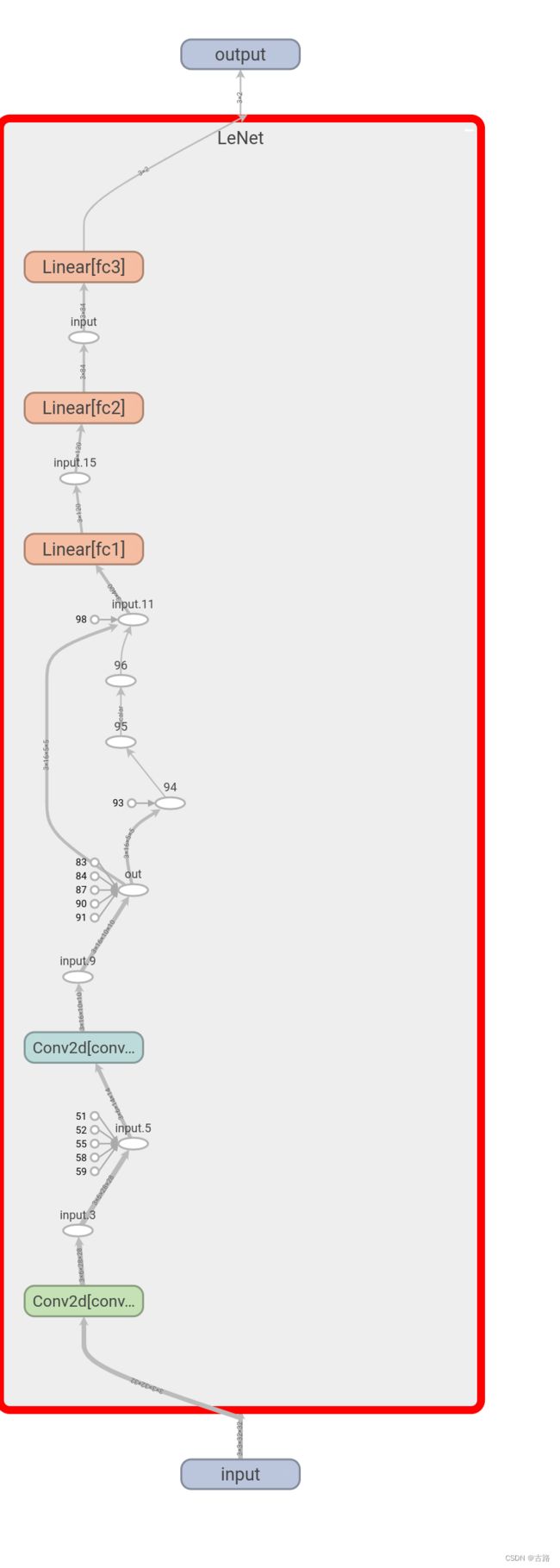
查看 LeNet 的计算图代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
使用 TensorBoard 可视化如下:
1.9.torchsummary
模型计算图的可视化还是比较复杂,不够清晰。而torchsummary能够查看模型的输入和输出的形状,可以更加清楚地输出模型的结构。
torchsummary.summary(model, input_size, batch_size=-1, device="cuda")
功能:查看模型的信息,便于调试
- model:pytorch 模型,必须继承自 nn.Module
- input_size:模型输入 size,形状为 CHW
- batch_size:batch_size,默认为 -1,在展示模型每层输出的形状时显示的 batch_size
- device:“cuda"或者"cpu”
查看 LeNet 的模型信息代码如下:
# 模型:
lenet = LeNet(classes=2)
print(summary(lenet, (3, 32, 32), device="cpu"))
输出如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 456
Conv2d-2 [-1, 16, 10, 10] 2,416
Linear-3 [-1, 120] 48,120
Linear-4 [-1, 84] 10,164
Linear-5 [-1, 2] 170
================================================================
Total params: 61,326
Trainable params: 61,326
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.23
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
上述信息分别有模型每层的输出形状,每层的参数数量,总的参数数量,以及模型大小等信息。
我们以第一层为例,第一层卷积核大小是 (6, 3, 5, 5),每个卷积核还有一个偏置,因此 6 × 3 × 5 × 5 + 6 = 456 6 \times 3 \times 5 \times 5+6=456 6×3×5×5+6=456。
3.Hook 函数与 CAM 算法
这篇文章主要介绍了如何使用 Hook 函数提取网络中的特征图进行可视化,和 CAM(class activation map, 类激活图)
3.1.Hook 函数概念
Hook 函数是在不改变主体的情况下,实现额外功能。由于 PyTorch 是基于动态图实现的,因此在一次迭代运算结束后,一些中间变量如非叶子节点的梯度和特征图,会被释放掉。在这种情况下想要提取和记录这些中间变量,就需要使用 Hook 函数。
PyTorch 提供了 4 种 Hook 函数。
(1)torch.Tensor.register_hook(hook)
- 功能:注册一个反向传播 hook 函数,仅输入一个参数,为张量的梯度。
hook函数:
hook(grad)
参数:grad:张量的梯度
代码如下:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
# 保存梯度的 list
a_grad = list()
# 定义 hook 函数,把梯度添加到 list 中
def grad_hook(grad):
a_grad.append(grad)
# 一个张量注册 hook 函数
handle = a.register_hook(grad_hook)
y.backward()
# 查看梯度
print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad)
# 查看在 hook 函数里 list 记录的梯度
print("a_grad[0]: ", a_grad[0])
handle.remove()
结果如下:
gradient: tensor([5.]) tensor([2.]) None None None
a_grad[0]: tensor([2.])
在反向传播结束后,非叶子节点张量的梯度被清空了。而通过hook函数记录的梯度仍然可以查看。
hook函数里面可以修改梯度的值,无需返回也可以作为新的梯度赋值给原来的梯度。代码如下:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
a_grad = list()
def grad_hook(grad):
grad *= 2
return grad*3
handle = w.register_hook(grad_hook)
y.backward()
# 查看梯度
print("w.grad: ", w.grad)
handle.remove()
结果是:
w.grad: tensor([30.])
(2)torch.nn.Module.register_forward_hook(hook)
-
功能:注册 module 的前向传播hook函数,可用于获取中间的 feature map。
-
hook函数:
hook(module, input, output)
- 参数:
- module:当前网络层
- input:当前网络层输入数据
- output:当前网络层输出数据
下面代码执行的功能是 3×3 的卷积和 2×2 的池化。我们使用register_forward_hook()记录中间卷积层输入和输出的 feature map。

class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
# 观察
print("output shape: {}\noutput value: {}\n".format(output.shape, output))
print("feature maps shape: {}\noutput value: {}\n".format(fmap_block[0].shape, fmap_block[0]))
print("input shape: {}\ninput value: {}".format(input_block[0][0].shape, input_block[0]))
输出如下:
output shape: torch.Size([1, 2, 1, 1])
output value: tensor([[[[ 9.]],
[[18.]]]], grad_fn=)
feature maps shape: torch.Size([1, 2, 2, 2])
output value: tensor([[[[ 9., 9.],
[ 9., 9.]],
[[18., 18.],
[18., 18.]]]], grad_fn=)
input shape: torch.Size([1, 1, 4, 4])
input value: (tensor([[[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]]]),)
(3)torch.Tensor.register_forward_pre_hook()
-
功能:注册 module 的前向传播前的hook函数,可用于获取输入数据。
-
hook函数:
hook(module, input)
- 参数:
- module:当前网络层
- input:当前网络层输入数据
(4)torch.Tensor.register_backward_hook()
-
功能:注册 module 的反向传播的hook函数,可用于获取梯度。
-
hook函数:
hook(module, grad_input, grad_output)
- 参数:
- module:当前网络层
- input:当前网络层输入的梯度数据
- output:当前网络层输出的梯度数据
代码如下:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
net.conv1.register_forward_pre_hook(forward_pre_hook)
net.conv1.register_backward_hook(backward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
loss_fnc = nn.L1Loss()
target = torch.randn_like(output)
loss = loss_fnc(target, output)
loss.backward()
输出如下:
forward_pre_hook input:(tensor([[[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]]]),)
backward hook input:(None, tensor([[[[0.5000, 0.5000, 0.5000],
[0.5000, 0.5000, 0.5000],
[0.5000, 0.5000, 0.5000]]],
[[[0.5000, 0.5000, 0.5000],
[0.5000, 0.5000, 0.5000],
[0.5000, 0.5000, 0.5000]]]]), tensor([0.5000, 0.5000]))
backward hook output:(tensor([[[[0.5000, 0.0000],
[0.0000, 0.0000]],
[[0.5000, 0.0000],
[0.0000, 0.0000]]]]),)
3.2.hook函数实现机制
hook函数实现的原理是在module的__call()__函数进行拦截,__call()__函数可以分为 4 个部分:
- 第 1 部分是实现 _forward_pre_hooks
- 第 2 部分是实现 forward 前向传播
- 第 3 部分是实现 _forward_hooks
- 第 4 部分是实现 _backward_hooks
由于卷积层也是一个module,因此可以记录_forward_hooks。
def __call__(self, *input, **kwargs):
# 第 1 部分是实现 _forward_pre_hooks
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
# 第 2 部分是实现 forward 前向传播
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
# 第 3 部分是实现 _forward_hooks
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
# 第 4 部分是实现 _backward_hooks
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
3.3.Hook 函数提取网络的特征图
下面通过hook函数获取 AlexNet 每个卷积层的所有卷积核参数,以形状作为 key,value 对应该层多个卷积核的 list。然后取出每层的第一个卷积核,形状是 [1, in_channle, h, w],转换为 [in_channle, 1, h, w],使用 TensorBoard 进行可视化,代码如下:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "imgs/lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# 注册hook
fmap_dict = dict()
for name, sub_module in alexnet.named_modules():
if isinstance(sub_module, nn.Conv2d):
key_name = str(sub_module.weight.shape)
fmap_dict.setdefault(key_name, list())
# 由于AlexNet 使用 nn.Sequantial 包装,所以 name 的形式是:features.0 features.1
n1, n2 = name.split(".")
def hook_func(m, i, o):
key_name = str(m.weight.shape)
fmap_dict[key_name].append(o)
alexnet._modules[n1]._modules[n2].register_forward_hook(hook_func)
# forward
output = alexnet(img_tensor)
# add image
for layer_name, fmap_list in fmap_dict.items():
fmap = fmap_list[0]# 取出第一个卷积核的参数
fmap.transpose_(0, 1) # 把 BCHW 转换为 CBHW
nrow = int(np.sqrt(fmap.shape[0]))
fmap_grid = vutils.make_grid(fmap, normalize=True, scale_each=True, nrow=nrow)
writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)
使用 TensorBoard 进行可视化如下:

CAM(class activation map, 类激活图)
todo