学习笔记-Spark环境搭建与使用
一、 20.04 Ubuntu安装
- 清华源ISO源
https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04/
下载链接
https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04/ubuntu-20.04.5-desktop-amd64.iso - 下载Mobaxterm
https://mobaxterm.mobatek.net/download-home-edition.html - 在VM下安装 Ubuntu
- 点击创建新的虚拟机,一直下一步
- 选择系统,然后下一步
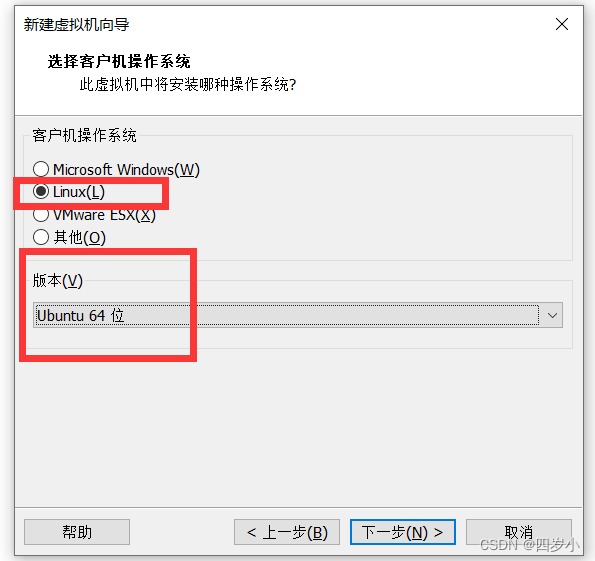
- 网络选择NAT模式,一直下一步,直到完成
- 点击改虚拟机,点击编辑虚拟机设置,导入ISO镜像

- 开启虚拟机,点击install Ubuntu
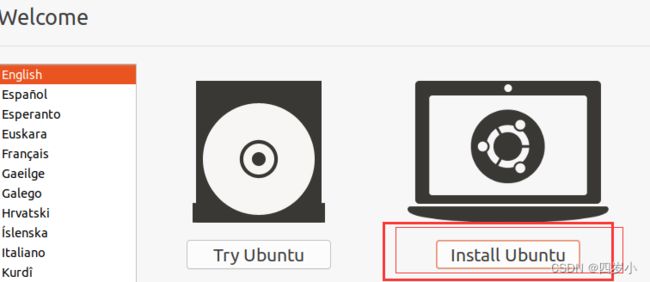
- 选择一个minimal就行,取消掉Download(要不然安装太慢了)
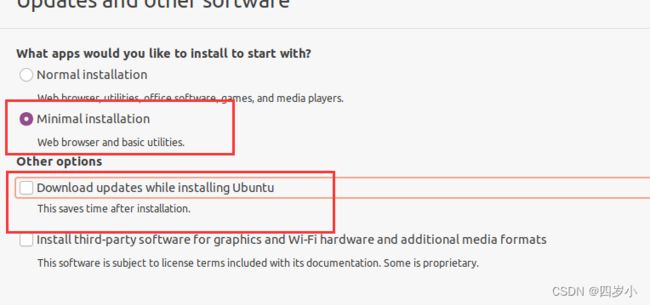
- 选择自动分配磁盘

- 选择时区、设置用户名与密码,等待安装完成即可。
- 安装anaconda
1. 下载anaconda
2. 根据提示安装
3. 输入 source activate 命令激活环境
4. 创建虚拟环境,conda create -n pyspark python=3.8
二、Hadoop搭建—一主二从
- 安装多个节点Ubuntu虚拟机
将Node1安装成功以后,选择右键管理->克隆,即可。克隆选项选择克隆链接,节省空间。
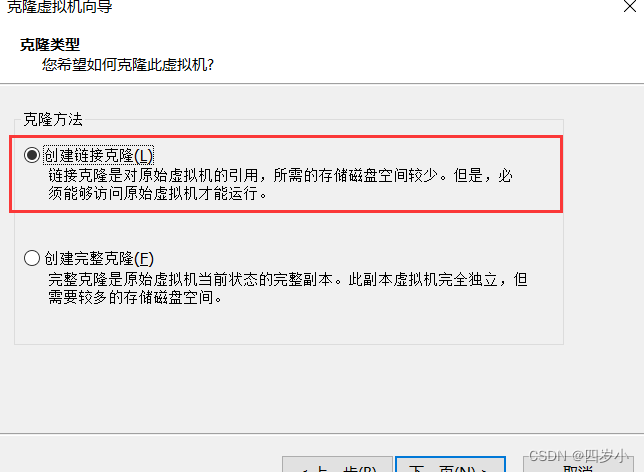
- MobaxTerm连接
- 查看虚拟机ip地址,
ifconfig - 下载ssh,
sudo apt-get install openssh-server - 打开mobaxTerm,代开session,选择ssh,输入ip,勾选用户名(默认),输入密码。
- 查看虚拟机ip地址,
- JDK 8 下载
https://www.oracle.com/java/technologies/downloads/
往下查看,JDK 8 在页面下面
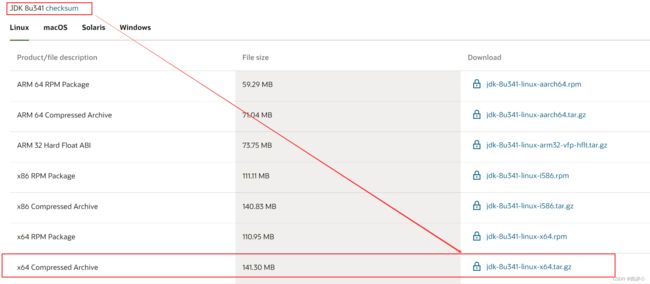
- Hadoop下载
https://hadoop.apache.org/releases.html
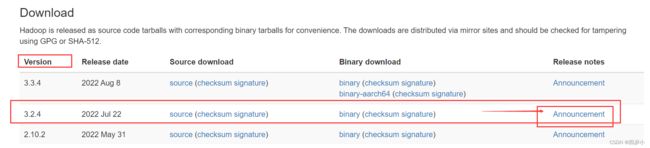
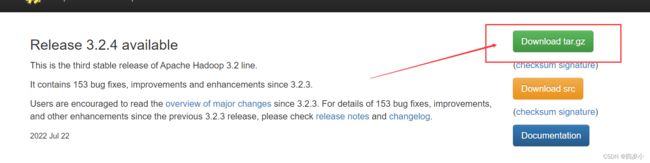
- 关闭防火墙与打开SSH
# 关闭防火墙
sudo ufw disable
# 检查ssh
sudo ps -e |grep ssh
# 如果有ssh,但是无sshd,则ssh未打开
sudo service ssh start
# 如果没有ssh,则下载
sudo apt-get update
sudo apt-get install openssh-server
- 配置hostname、hosts(所有节点都需要操作)
# 配置hostname,自定义主机名,写本机的即可
sudo vim /etc/hostname
# 配置hosts,将127.0.1.1这一行删除,加入所有节点的ip、hostname,查看ip:ifconfig
sudo vim /etc/hosts
# 重启
reboot
# 测试下是否配置成功, 注意:这个节点名不是本机的,是非本机的其他节点名
ping 节点名
- 设置SSH免密通信
- 主节点上
# 输出命令,摁下三次enter,会生成秘钥,其中也会告诉你.ssh文件夹保存的位置
ssh-keygen -t rsa
# 进入.ssh文件夹中,里面有两个文件,.pub的是公钥,另外一个是私钥,复制一份公钥,并修改权限
cat id_rsa.pub >> authorized_keys
chmod 777 authorized_keys
# 将公钥传输给其余从节点,首次需要输入yes与密码
scp authorized_keys 用户名@节点名:~/
2. 从节点
# 生成秘钥
ssh-keygen -t rsa
# 将从主节点拷贝过来的公钥移动到.ssh文件下
mv ~/authorized_keys ~/.ssh/
# 修改其权限
chmod 600 authorized_keys
3. 如果还是需要输入密码,则删除.ssh文件下know开头的文件,然后将所有的公钥加入到authoried_keys下,重新试下。
- 配置安装JDK8(主从节点都需要)
# 创建目录
mkdir /usr/java
mkdir /usr/java/jdk
# 解压上传的jdk到指定目录下
sudo tar -xvf jdk-8u341-linux-x64.tar.gz -C /usr/java/jdk
# 修改文件名,方便配置
sudo mv jdk1.8.0_341 jdk8
# 添加配置,追加内容,vim /etc/profile
export JAVA_HOME=/usr/java/jdk/jdk8
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# 使其生效,并测试
source /etc/profile
java -version
- 安装Hadoop(主从节点都要做)
# 创建文件夹
mkdir /usr/hadoop
# 将上传的hadoop解压到指定文件夹中
sudo tar -xvf ~/Softwarejar/hadoop-3.2.4.tar.gz -C /usr/hadoop/
# 重命名
mv hadoop-3.2.4 hadoop
# 设置配置,/etc/profile
export HADOOP_HOME=/usr/hadoop/hadoop
export CLASSPATH=$HADOOP_HOME/bin/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使其生效并测试
source /etc/profile
hadoop version
- 配置Hadoop(只需要在主节点配置即可)
在文件目录下进行 /xxxx/hadoop/etc/hadoop- 配置 hadoop-env.sh文件
export JAVA_HOME=/xxxx/java/jdk/jdk8
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
2. 配置yarn-env.sh文件
export JAVA_HOME=/xxxx/java/jdk/jdk8
3. 配置 core-site.xml。(这个配置的hdfs的本地端口号,而不是hdfs的web界面端口号)
fs.defaultFS</name>
hdfs://Node1:9000</value>
</property>
hadoop.tmp.dir</name>
/usr/hadoop/hadoop/tmp</value>
</property>
4. 配置hdfs-site.xml文件
dfs.replication</name>
1</value>
<!--对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,本教程只有一个Slave节点作为数据节点,即集群中只有一个数据节点,数据只能保存一份,所以,dfs.replication的值还是设置为 1-->
</property>
dfs.namenode.name.dir</name>
/usr/hadoop/hadoop/tmp/dfs/name</value> <!--不需要我们提前建好文件夹,如果没有,等会儿格式化名称节点时它会帮我们自动创建-->
</property>
dfs.datanode.data.dir</name>
/usr/hadoop/hadoop/tmp/dfs/data</value>
</property>
dfs.namenode.http-address</name>
Node1:50070</value>
</property>
5. 配置yarn-site.xml文件
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.resourcemanager.hostname</name>
master</value>
</property>
yarn.resourcemanager.address</name>
Node1:18040</value>
</property>
yarn.resourcemanager.scheduler.address</name>
Node1:18030</value>
</property>
yarn.resourcemanager.resource-tracker.address</name>
Node1:18025</value>
</property>
yarn.resourcemanager.admin.address</name>
Node1:18141</value>
</property>
yarn.resourcemanager.webapp.address</name>
Node1:18088</value>
</property>
yarn.application.classpath</name>
/usr/hadoop/hadoop/etc/hadoop:/usr/hadoop/hadoop/share/hadoop/common/lib/*:/usr/hadoop/hadoop/share/hadoop/common/*:/usr/hadoop/hadoop/share/hadoop/hdfs:/usr/hadoop/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/hadoop/share/hadoop/hdfs/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/*:/usr/hadoop/hadoop/share/hadoop/yarn:/usr/hadoop/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/hadoop/share/hadoop/yarn/*
</value>
</property>
6. 配置mapred-site.xml文件
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.jobhistory.address</name>
Node1:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
Node1:19888</value>
</property>
yarn.app.mapreduce.am.env</name>
HADOOP_MAPRED_HOME=/usr/hadoop/hadoop</value>
</property>
mapreduce.map.env</name>
HADOOP_MAPRED_HOME=/usr/hadoop/hadoop</value>
</property>
mapreduce.reduce.env</name>
HADOOP_MAPRED_HOME=/usr/hadoop/hadoop</value>
</property>
mapreduce.application.classpath</name>
/usr/hadoop/hadoop/etc/hadoop:/usr/hadoop/hadoop/share/hadoop/common/lib/*:/usr/hadoop/hadoop/share/hadoop/common/*:/usr/hadoop/hadoop/share/hadoop/hdfs:/usr/hadoop/hadoop/share/hadoop/hdfs/lib/*:/usr/hadoop/hadoop/share/hadoop/hdfs/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/usr/hadoop/hadoop/share/hadoop/mapreduce/*:/usr/hadoop/hadoop/share/hadoop/yarn:/usr/hadoop/hadoop/share/hadoop/yarn/lib/*:/usr/hadoop/hadoop/share/hadoop/yarn/*
</value>
</property>
7. 从主节点传送到从节点
scp -r hadoop 用户名@hostname:/xxxx/hadoop/
8. 首次启动需要格式化
# 在/xxxx/hadoop/bin目录下执行命令
hdfs namenode -format
参考:hadoop搭建
- 启动Hadoop
# 1. 启动hadoop与yarn
./start-all.sh
# 2.如果通过jps查看发现少了jobhistoryserver这个,则进入hadoop/sbin目录输入如下命令进行启动
./mr-jobhistory-daemon.sh start historyserver
# 3. 关闭则将start改为stop即可
./stop-all.sh
# 4. 登录hdfs文件系统与yarn的Web UI界面,端口号可以分别查看hdfs-site.xml、yarn-site.xml查看
http://主机名:50070
https://主机名:18088
# 5. 如果遇见hdfs启动报in safe mode,则执行:
hdfs dfsadmin -safemode leave
三、 Spark 搭建
- 安装python环境,下载anaconda进行安装
https://mirrors.tuna.tsinghua.edu.cn/anaconda/. - Spark下载地址,找到对应hadoop的版本的Spark下载,点进去会有对应的hadoop的版本。
https://archive.apache.org/dist/spark/ - 上传下载的spark安装包,解压到指定的位置
- Scala 安装
# 下载链接
https://www.scala-lang.org/download/2.12.16.html
# 选择tgz文件进行下载
1. Local单机模式
# 1. 解压scala、spark到指定的位置
tar -xvf scala安装包 -C 指定位置
tar -xvf spark安装包 -C 指定位置
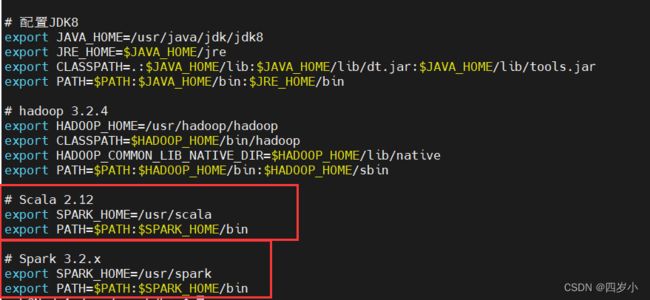
# 2. 配置scala、spark环境
sudo vim /etc/profile
# 2.1 加入
# Scala 2.12
export SPARK_HOME=/usr/scala
export PATH=$PATH:$SPARK_HOME/bin
# Spark 3.2.x
export SPARK_HOME=/usr/spark
export PATH=$PATH:$SPARK_HOME/bin
# 2.2 生效
source /etc/profile
# 3. 测试
spark-shell

2. Standalone模式
- 主节点配置(在local模式的基础上)
# 1. 进入spark/conf文件下,有两个文件:spark-env.sh.template、workers.template(有可能也叫slaves.template)
cp spark-env.sh.template spark-env.sh
cp workers.template worker
# 1.1 进入spark-env.sh,追加内容
# Spark
export SCALA_HOME=/usr/scala
export JAVA_HOME=/usr/java/jdk/jdk8
export SPARK_HOME=/usr/spark
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_WORKER_CORES=2
export SPARK_EXECUTOR_CORES=2
# 1.2 进入worker,将localhost修改为一下的主从节点hostname
Node1
Node2
- 从节点配置(注意/etc/profile里面的路径也要修改成Local里面的)
# 1. 将主节点配置好的scala、spark传输到从节点
sudo scp -r /xxxx/spark 用户名@从节点hostname:/usr
sudo scp -r /xxxx/spark 用户名@从节点hostname:/usr
# 注意可能提示permission denied,进行主从节点对应下要传入的文件位置的权限修改
chmod 777 文件夹
- 启动Spark各个节点
# 进入spark/sbin目录,执行start-all.sh
# 主节点执行
./start-master.sh
# 从节点执行 # 或者是执行,注意7077是根据你打开的网页上显示的端口来的,slave启动成功会在网页上的worker显示对应的数量,一个从节点就是1,两个从节点就是2
./start-slave.sh spark://主节点的hostname:7077
# 启动历史服务
./start-history-server.sh
# 验证,输入网址
http://主节点名:8080
# 输入jps
jps
# 进入spark/bin目录,在命令行中运行Spark,使用.pyspark来进入,指定master
./pyspark --master spark://Node1:7077
# 运行由spark写的程序,采用./spark-submit来
./spark-submit --master spark://Node1:7077 /usr/spark/examples/src/main/python/pi.py 1000
![]()
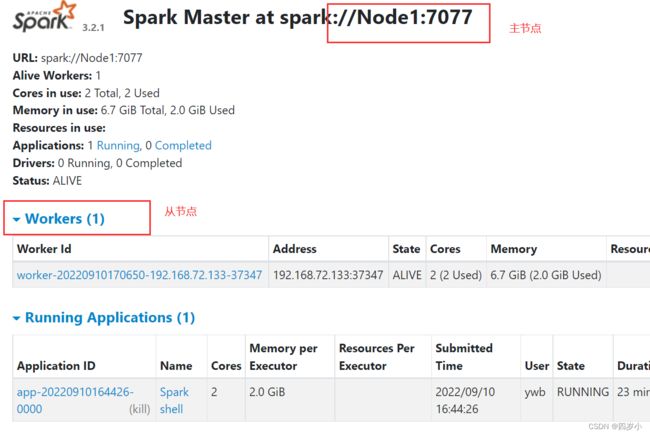
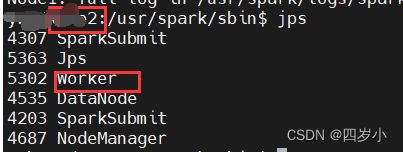

3. Spark YARN
1.主从节点都基于standalone,只要在主节点的spark.env.sh文件下加入以下内容:
HADOOP_CONF_DIR=/xxx/hadoop/etc/hadoop
YARN_CONF_DIR=/xxx/hadoop/etc/hadoop
- 启动hadoop和yarn即可(spark就无需启动了),使用
./start-all.sh - 执行
spart/bin/pyspark --master yarn
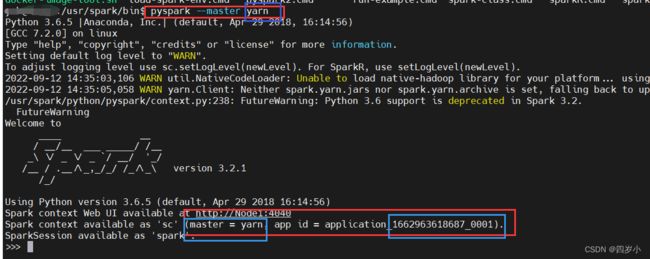
- 在Hadoop的yarn集群上查看下,
http://主机名:18088

四. Pycharm本地连接与远程连接服务器配置
1. 本地windows连接
请自行去找教程
2. 远程连接服务器配置
- 打开pycharm创建一个项目,虚拟环境随便创建一个或者使用1中的本地虚拟环境。
- 点击pycharm右下角的编辑环境,弹出框,选择框中右上角的设置符号,选择add操作。
- 选择SSH 配置,输入主机名、用户名点击下一步。
- 输入用户的密码。
- 输入服务器上环境配置的路径,修改为对应路径,如
/home/ywb/anaconda3/envs/pyspark/bin/python,注意python一定不能漏。
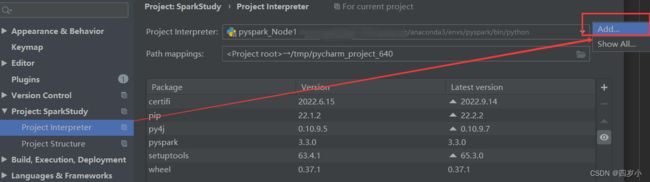

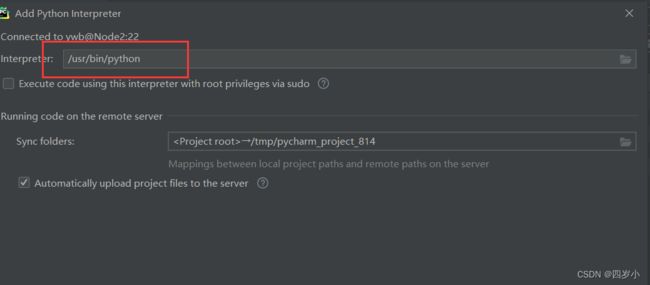
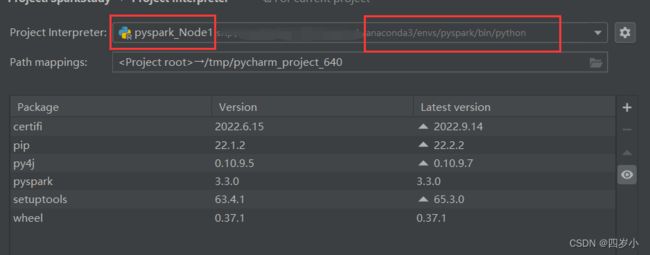
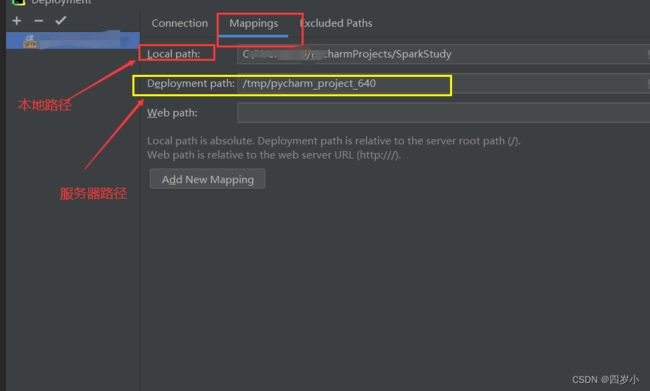
- 查看远程服务器将本地项目上传存储的位置,tools–>deployment–>configuration

PySpark 程序运行错误问题可能出现
1. 程序1
# 程序1
# coding:utf-8
# 第一行,防止中文乱码
from pyspark import SparkConf, SparkContext
# 第3行,导入包
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('WordCountHelloWorld')
# 第7行,通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
问题1
# 上述程序可能会报这个错误,原因是由于没有设置JAVA_HOME
JAVA_HOME is not set
RuntimeError: Java gateway process exited before sending its port number
# 解决办法1:一劳永逸
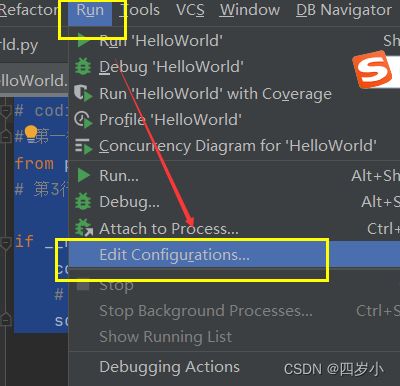
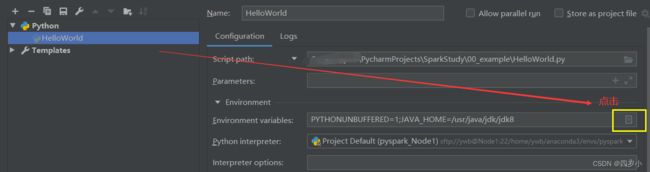
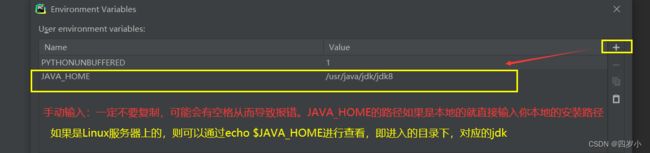
1. Pycharm-->Run-->edit Configurations --> Enviroment variables 的文件图标 --> 点击+ --> 添加JAVA_HOME环境变量,保存。
2. 重新运行下程序,则不会报错。
# 解决办法2: 临时,在程序首行加入一下两行代码,jdk路径是你自己的路径,不要写成我的。
import os
os.environ['JAVA_HOME'] = "/usr/java/jdk/jdk8"


2. 程序2
# coding:utf-8
# 第一行,防止中文乱码
from pyspark import SparkConf, SparkContext
# 第3行,导入包
if __name__ == '__main__':
conf = SparkConf().setMaster('local[*]').setAppName('WordCountHelloWorld')
# 第7行,通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
# 需求:wordcount单词计数,读取HDFS上的words.txt文件,对其内部中单词统计出现次数
# 读取文件
# 如果没有这个文件,注意,这里的端口号是hadoop中core-site.xml的端口号,则不是hdfs web界面的端口号
# 注意:如果首次修改运行出错,则多运行几次就好,可能是hadoop没响应过来
# 因为我这里的core-site.xml设置的是18080,所以填18080,如果是9000,则写9000即可
# file_rdd = sc.textFile('hdfs://Node1:9000/data/words.txt')
# 第二种读远程服务器的hdfs下的文件,直接下远程文件下的绝对路径即可
# file_rdd = sc.textFile('/tmp/pycharm_project_640/data/input/words.txt')
# 注意,这里尽量写绝对路径,相对路径可能会报错
file_rdd = sc.textFile('C:/Users/ywb/PycharmProjects/SparkStudy/data/input/words.txt')
# 将单词进行切割,得到一个存储全部单词的集合对象
words_rdd = file_rdd.flatMap(lambda line: line.split(' '))
# 将单词转化为元组对象
words_with_one_rdd = words_rdd.map(lambda x: (x, 1))
# 将元组的value 按照key来分组,对所有的value执行聚合操作
result_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a+b)
# 通过collect方法手机RDD的数据并打印输出结果
print(result_rdd.collect())
运行成功

问题2
# 报错
py4j.protocol.Py4JJavaError: An error occurred while calling o23.partitions.
: org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "C"
# 解决办法1
多运行几次,可能是hadoop没响应过来
# 解决办法2
重启下pycharm,再运行即可
# 解决办法3
查看core-site.xml中的端口,看与程序中的端口是否一致,不一致则修改,让二者保持一致。
问题3
如果修改了文件内容,或者其他内容,导致输出结果依旧是上一次执行的结果,这样可以通过以下方式解决:
重启下pycharm即可。