实例分割最新最全面综述:从Mask R-CNN到BlendMask
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|AI算法与图像处理
前面的话
实例分割(Instance Segmentation)是视觉经典四个任务中相对最难的一个,它既具备语义分割(Semantic Segmentation)的特点,需要做到像素层面上的分类,也具备目标检测(Object Detection)的一部分特点,即需要定位出不同实例,即使它们是同一种类。因此,实例分割的研究长期以来都有着两条线,分别是自下而上的基于语义分割的方法和自上而下的基于检测的方法,这两种方法都属于两阶段的方法,下面将分别简单介绍。
自上而下的实例分割方法
思路是:首先通过目标检测的方法找出实例所在的区域(bounding box),再在检测框内进行语义分割,每个分割结果都作为一个不同的实例输出。
自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:
mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask
特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask
下采样(使用步长大于1的卷积)导致的位置信息丢失
自下而上的实例分割方法
思路是:首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:
对密集分割的质量要求很高,会导致非最优的分割
泛化能力较差,无法应对类别多的复杂场景
后处理方法繁琐
单阶段实例分割(Single Shot Instance Segmentation),这方面工作其实也是受到了单阶段目标检测研究的影响,因此也有两种思路,一种是受one-stage, anchor-based 检测模型如YOLO,RetinaNet启发,代表作有YOLACT和SOLO;一种是受anchor-free检测模型如 FCOS 启发,代表作有PolarMask和AdaptIS。
下面是对其中一些方法在COCO数据集上的指标对比:
Method |
AP |
AP50 |
AP75 |
APs |
APm |
APL |
FCIS |
29.2 |
49.5 |
7.1 |
31.3 |
50.0 |
|
Mask R-CNN |
37.1 |
60.0 |
39.4 |
16.9 |
39.9 |
53.5 |
YOLACT-700 |
31.2 |
50.6 |
32.8 |
12.1 |
33.3 |
47.1 |
PolarMask |
32.9 |
55.4 |
33.8 |
15.5 |
35.1 |
46.3 |
SOLO |
40.4 |
62.7 |
43.3 |
17.6 |
43.3 |
58.9 |
PointRend |
40.9 |
|||||
BlendMask |
41.3 |
63.1 |
44.6 |
22.7 |
44.1 |
54.5 |
下面详细介绍一下几个代表性方法:
1.双阶段的 Mask R-CNN (2017.3)
Mask-RCNN通过增加不同的分支可以完成目标分类,目标检测,语义分割,实例分割,人体姿态估计等多种任务。对于实例分割来讲,就是在Faster-RCNN的基础上(分类+回归分支)增加了一个分支用于语义分割,其抽象结构如下图所示:

可以看到其结构与Faster RCNN非常类似,但有3点主要区别:
在基础网络中采用了较为优秀的ResNet-FPN结构,多层特征图有利于多尺度物体及小物体的检测。原始的FPN会输出P2、P3、P4与P54个阶段的特征图,但在Mask RCNN中又增加了一个P6。将P5进行最大值池化即可得到P6,目的是获得更大感受野的特征,该阶段仅仅用在RPN网络中。
提出了RoI Align方法来替代RoI Pooling,原因是RoI Pooling的取整做法损失了一些精度,而这对于分割任务来说较为致命。Maks RCNN提出的RoI Align取消了取整操作,而是保留所有的浮点,然后通过双线性插值的方法获得多个采样点的值,再将多个采样点进行最大值的池化,即可得到该点最终的值。
得到感兴趣区域的特征后,在原来分类与回归的基础上,增加了一个Mask分支来预测每一个像素的类别。具体实现时,采用了FCN(Fully Convolutional Network)的网络结构,利用卷积与反卷积构建端到端的网络,最后对每一个像素分类,实现了较好的分割效果。
Mask R-CNN算法的主要步骤为:
-
首先,将输入图片送入到特征提取网络得到特征图。
然后对特征图的每一个像素位置设定固定个数的ROI(也可以叫Anchor),然后将ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,以获得精炼后的ROI区域。
对上个步骤中获得的ROI区域执行论文提出的ROIAlign操作,即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来。
最后对这些ROI区域进行多类别分类,候选框回归和引入FCN生成Mask,完成分割任务。
总的来说,在Faster R-CNN和FPN的加持下,Mask R-CNN开启了R-CNN结构下多任务学习的序幕。它出现的时间比其他的一些实例分割方法(例如FCIS)要晚,但是依然让proposal-based instance segmentation的方式占据了主导地位(尽管先检测后分割的逻辑不是那么地自然)。
Mask R-CNN利用R-CNN得到的物体框来区分各个实例,然后针对各个物体框对其中的实例进行分割。显而易见的问题便是,如果框不准,分割结果也会不准。因此对于一些边缘精度要求高的任务而言,这不是一个较好的方案。同时由于依赖框的准确性,这也容易导致一些非方正的物体效果比较差。
2. 单阶段实例分割方法
2.1 Instance-sensitive FCN(2016.3)
该方法的思想是相对FCN在每个像素上输出语义的label,其需要输出是否在某个实例的相对位置上(以3x3的网格为例,即要确定像素点是在网格的哪个位置(9个位置对应9个通道))。虽然理解上不是特别直观,但其主要思想还是编码了位置信息(类似方向信息)以便区分同一语义下的实例。
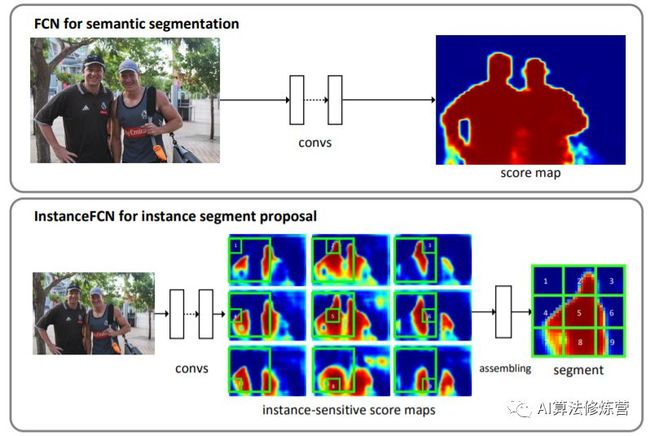
当然在构造groundtruth时,也需要sliding window的方式把实例上各个像素分配到各个位置上去。
在推理阶段,仅仅依靠sliding window去生成结果是不够的。在相近位置上会得到相似的结果,这就需要对物体本身进行整体的判别,以确定物体(中心)的准确位置。如下instance sensitive FCN增加了物体检测分支,通过物体的外接框以及得分,利用NMS得到最终无重复的实例分割结果。
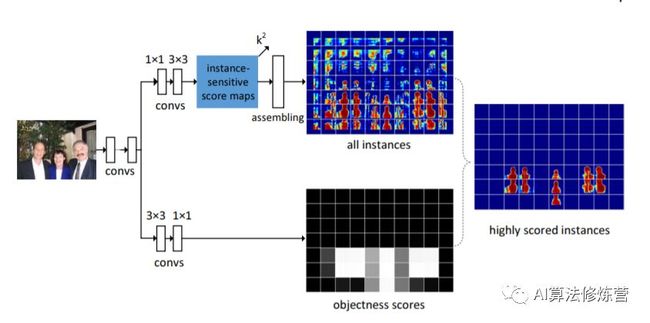
虽然该方法效果在当时并不突出,但请先记住这样的思想,后续SOLO会进一步升华。下面要讲到的R-FCN同样利用了单个像素编码(附带)相对位置信息的思路,除了类别信息外,该像素还需要判断自己在物体区域的相对位置,相对位置通过固定的通道得以表征。
2.2 FCIS(2017.4)
FCN 最终输出的是类别的概率图,只有类别输出,没有单个对象输出,InstanceFCN输出3*3的位置信息图, 只有单个对象输出,没有类别信息,需要单独的downstream网络完成类别信息。FCIS通过计算position-sensitive inside/outside score maps,同时输出 instance mask 和类别信息。

InstanceFCN提出了positive-sensitive score map,每个score表示一个像素在某个相对位置上属于某个物体实例的似然得分。所以FCIS也采用position-sensitive score maps,只不过在物体实例中区分inside/outside,目的是想引入一点context信息。
作者认为以往的SDS、Hypercolumn、CFM等算法,具有相似的结构:两个子网络分别用于对象分割和检测子任务,且两个网络的结构、参数、执行顺序随机。作者认为分离的网络没有真正挖掘到两个认为的联系,提出共同的 “position-sensitive score map” ,同时用于object segmentation and detection子任务。
除了加入背景部分的通道外,FCIS还基于ROI作了类别检测,而不是再引入另外一个分支作这项任务。
2.3 YOLCAT(2019.4)
YOLACT将掩模分支添加到现有的一阶段(one-stage)目标检测模型,其方式与Mask R-CNN对 Faster-CNN 操作相同,但没有明确的定位步骤。
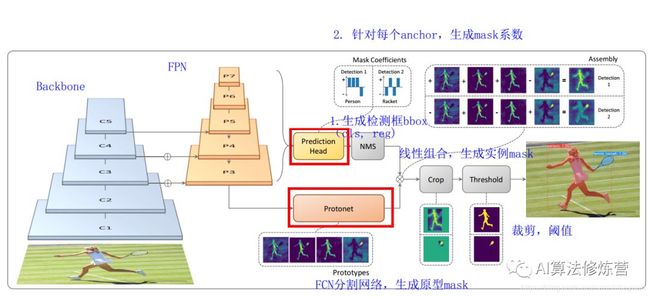
YOLACT将实例分割任务拆分成两个并行的子任务:(1)通过一个Protonet网络, 为每张图片生成 k 个 原型mask;(2)对每个实例,预测k个的线性组合系数(Mask Coefficients)。最后通过线性组合,生成实例mask,在此过程中,网络学会了如何定位不同位置、颜色和语义实例的mask。
YOLACT将问题分解为两个并行的部分,利用 fc层(擅长产生语义向量)和 conv层(擅长产生空间相干掩模)来分别产生“掩模系数”和“原型掩模” 。然后,因为原型和掩模系数可以独立地计算,所以 backbone 检测器的计算开销主要来自合成(assembly)步骤,其可以实现为单个矩阵乘法。通过这种方式,我们可以在特征空间中保持空间一致性,同时仍然是一阶段和快速的。
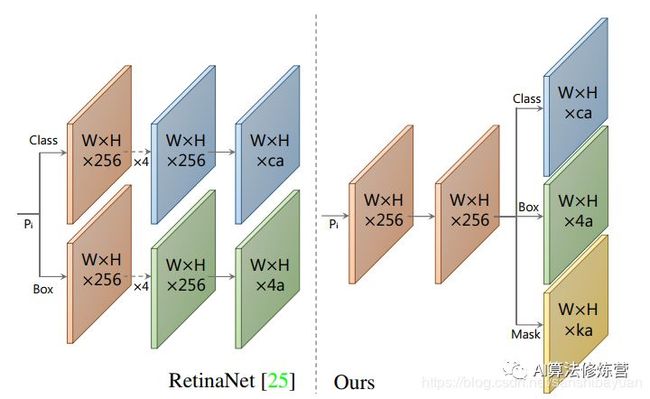
Backbone:Resnet 101+FPN,与RetinaNet相同;Protonet:接在FPN输出的后面,是一个FCN网络,预测得到针对原图的原型mask;Prediction Head:相比RetinaNet的Head,多了一个Mask Cofficient分支,预测Mask系数,因此输出是4*c+k。
可以看到head上增加了一支mask系数分支用于将prototypes进行组合得到mask的结果。当然按NMS的位置看,其同样需要有bbox的准确预测才行,并且该流程里不太适合用soft NMS进行替代。需要注意的是,在训练过程中,其用groundtruth bbox对组合后的全图分割结果进行截取,再与groundtruth mask计算损失。这同样需要bbox结果在前作为前提,以缓解前后景的像素不均衡情况。
至于后续的YOLCAT++,则主要是加入了mask rescoring的概念和DCN结构,进一步提升精度。(1)参考Mask Scoring RCNN,添加fast mask re-scoring分支,更好地评价实例mask的好坏;(2)Backbone网络中引入可变形卷积DCN;(3)优化了Prediction Head中的anchor设计。
2.4 PolarMask(2019.10)
相比RetinaNet,FCOS将基于anchor的回归变成了中心点估计与上下左右四个边界距离的回归,而PolarMask则是进一步细化了边界的描述,使得其能够适应mask的问题。PolarMask最重要的特点是:(1) anchor free and bbox free,不需要出检测框;(2) fully convolutional network, 相比FCOS把4根射线散发到36根射线,将instance segmentation和object detection用同一种建模方式来表达。
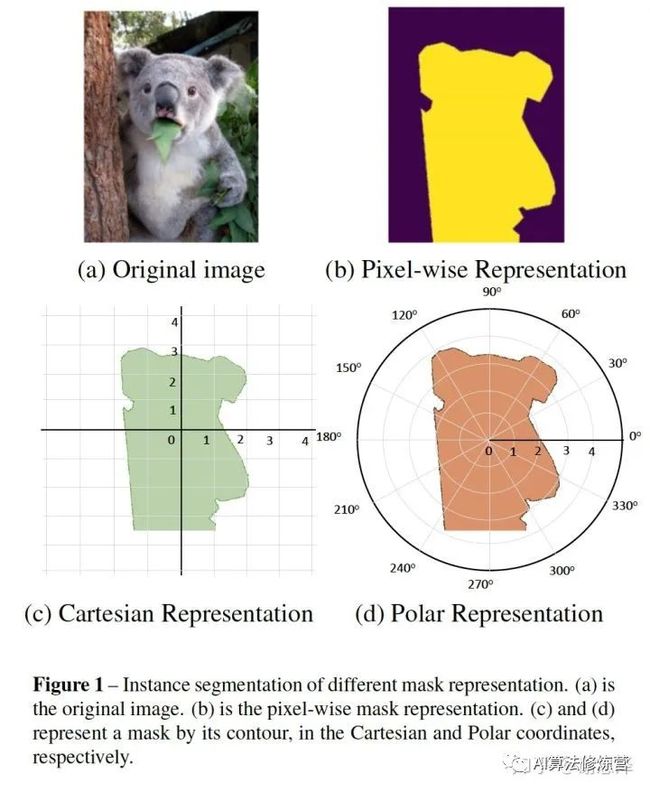
两种实例分割的建模方式:
1 像素级建模 类似于图b,在检测框中对每个pixel分类
2 轮廓建模 类似于图c和图d,其中,图c是基于直角坐标系建模轮廓,图d是基于极坐标系建模轮廓
PolarMask 基于极坐标系建模轮廓,把实例分割问题转化为实例中心点分类(instance center classification)问题和密集距离回归(dense distance regression)问题。同时,我们还提出了两个有效的方法,用来优化high-quality正样本采样和dense distance regression的损失函数优化,分别是Polar CenterNess和 Polar IoU Loss。没有使用任何trick(多尺度训练,延长训练时间等),PolarMask 在ResNext 101的配置下 在coco test-dev上取得了32.9的mAP。 这是首次,证明了更复杂的实例分割问题,可以在网络设计和计算复杂度上,和anchor free物体检测一样简单。
网络结构
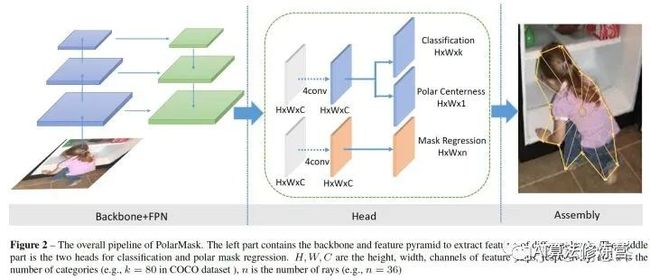
整个网络和FCOS一样简单,首先是标准的backbone + fpn模型,其次是head部分,我们把fcos的bbox分支替换为mask分支,仅仅是把channel=4替换为channel=n, 这里n=36,相当于36根射线的长度。同时我们提出了一种新的Polar Centerness 用来替换FCOS的bbox centerness。可以看到,在网络复杂度上,PolarMask和FCOS并无明显差别。
建模方式
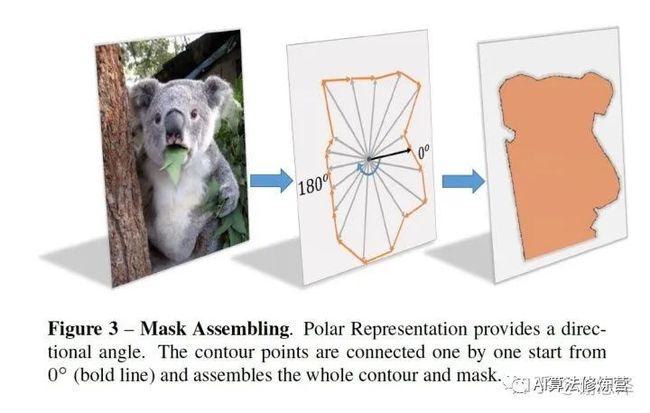
首先,输入一张原图,经过网络可以得到中心点的位置和n(n=36 is best in our setting)根射线的距离,其次,根据角度和长度计算出轮廓上的这些点的坐标,从0°开始连接这些点,最后把联通区域内的区域当做实例分割的结果。
实验结果
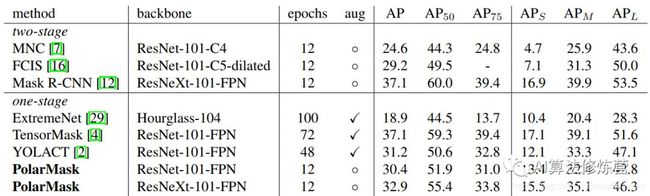
从实验结果可以看到,PolarMask的精度并不是很高,而且速度上也没有优势,但是它的思路是非常巧妙的,对后面的研究有着很大的启发意义。具体细节可参考论文原文。
2.5 SOLO(2019.12)
和FCIS的类似,单个像素不是单纯输出类别,而是带有位置信息的类别,同时考虑到尺度的问题,借助网络结构来解决。
要理解SOLO的思想,重点就是要理解SOLO提出的实例类别(Instance Category)的概念。作者指出,实例类别就是量化后的物体中心位置(location)和物体的尺寸(size)。下面就解释一下这两个部分。
位置(location)
SOLO将一张图片划分S×S的网格,这就有了S*S个位置。不同于TensorMask和DeepMask将mask放在了特征图的channel维度上,SOLO参照语义分割,将定义的物体中心位置的类别放在了channel维度上,这样就保留了几何结构上的信息。
本质上来说,一个实例类别可以去近似一个实例的中心的位置。因此,通过将每个像素分类到对应的实例类别,就相当于逐像素地回归出物体的中心、这就将一个位置预测的问题从回归的问题转化成了分类的问题。这么做的意义是,分类问题能够更加直观和简单地用固定的channel数、同时不依赖后处理方法(如分组和学习像素嵌入embedding)对数量不定的实例进行建模。
尺寸(size)
对于尺寸的处理,SOLO使用了FPN来将不同尺寸的物体分配到不同层级的特征图上,依次作为物体的尺寸类别。这样,所有的实例都被分别开来,就可以去使用实例类别去分类物体了。
网络实现
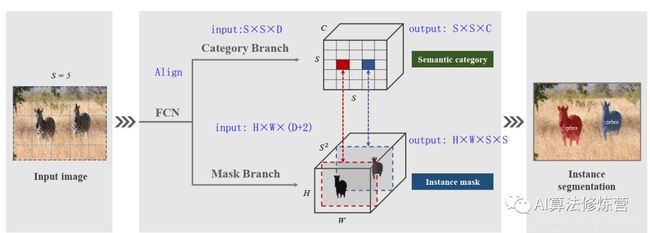
SOLO将图片划分成S×S的网格,如果物体的中心(质心)落在了某个网格中,那么该网格就有了两个任务:(1)负责预测该物体语义类别(2)负责预测该物体的instance mask。这就对应了网络的两个分支Category Branch和Mask Branch。同时,SOLO在骨干网络后面使用了FPN,用来应对尺寸。FPN的每一层后都接上述两个并行的分支,进行类别和位置的预测,每个分支的网格数目也相应不同,小的实例对应更多的的网格。
Category Branch:Category Branch负责预测物体的语义类别,每个网格预测类别S×S×C,这部分跟YOLO是类似的。输入为Align后的S×S×C的网格图像,输出为S×S×C的类别。这个分支使用的损失函数是focal loss。
Mask Branch:预测instance mask的一个直观方法是类似语义分割使用FCN,但FCN是具有空间不变性(spatiallly invariant)的,而我们这边需要位置上的信息。因此,作者使用了CoordConv,将像素横纵坐标x,y(归一化到[-1,1])与输入特征做了concat再输入网络中。这样输入的维度就是 H*W*(D+2)了。
实验结果
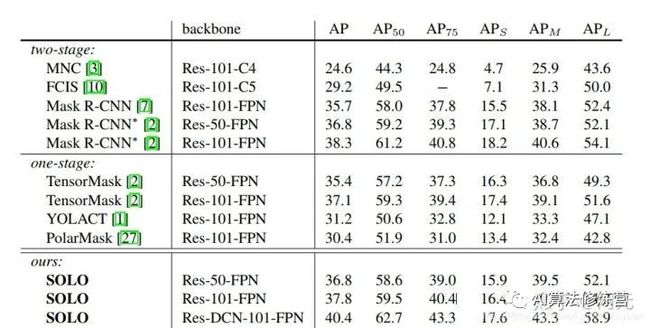
可以看到,SOLO的精度已经超越了Mask R-CNN,相较思路类似的PolarMask也有较大的优势。
2.6 RDSNet & PointRend(2019.12)
RDSNet方法的出发点是检测阻碍不应该成为分割效果的阻碍,两种应该循环相互促进。有可能存在的情况是分割本身是比较准确的,但是因为定位不准,导致分割结果也比较差;这时候如果能提前知道分割的结果,那么检测的结果也会更好些。
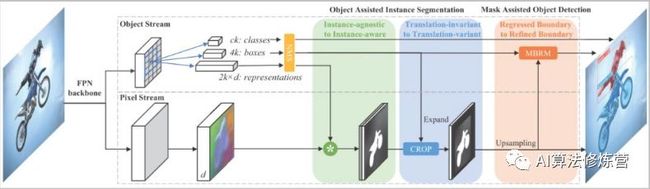
这里就有用到YOLCAT的方式,去获得提取获取分割结果。当然这里从embedding的角度出发,还结合了前后景的处理(实验中说明前后景correlation比单前景linear combination要好)。得到bbox预测结果后是需要进行NMS,以及expand操作的,以确保尽可能多的有效区域被选进来(训练时1.5,测试时1.2)。之后再通过Mask-based Boundary Refinement模块对物体的边框进行调整。为了使该过程可导,作者还设计了贝叶斯分布估计的方式,不太懂。
PointRend借鉴了Render的思想,在尺度方式变化时由于采样的方式(不是连续坐标的设定吗),使得锯齿现象不会很明显。因此PointRend是利用一种非均匀采样的方式来确定在分辨率提高的情况下,如何确定边界上的点,并对这些点归属进行判别。本质上其实是一个新型上采样方法,针对物体边缘的图像分割进行优化,使其在难以分割的物体边缘部分有更好的表现。

PointRend 方法要点总结来说是一个迭代上采样的过程:
while 输出的分辨率 < 图片分辨率:
对输出结果进行2倍双线性插值上采样得到 coarse prediction_i。
挑选出 N 个“难点”,即结果很有可能和周围点不一样的点(例如物体边缘)。
对于每个难点,获取其“表征向量”,“表征向量”由两个部分组成,其一是低层特征(fine-grained features),通过使用点的坐标,在低层的特征图上进行双线性插值获得(类似 RoI Align),其二是高层特征(coarse prediction),由步骤 1 获得。
使用 MLP 对“表征向量”计算得到新的预测,更新 coarse prediction_i 得到 coarse prediction_i+1。这个 MLP 其实可以看做一个只对“难点”的“表征向量”进行运算的由多个 conv1x1 组成的小网络。
2.7 BlendMask(2020.1)
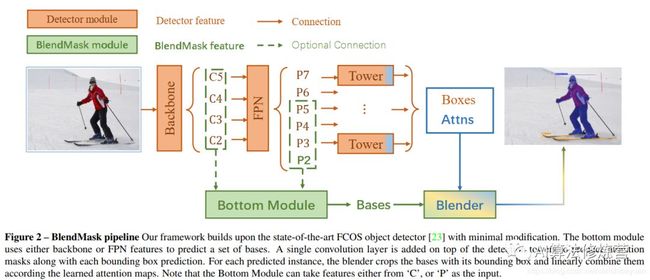
BlendMask是一阶段的密集实例分割方法,结合了Top-down和Bottom-up的方法的思路。它通过在anchor-free检测模型FCOS的基础上增加了Bottom Module提取low-level的细节特征,并在instance-level上预测一个attention;借鉴FCIS和YOLACT的融合方法,提出了Blender模块来更好地融合这两种特征。最终,BlendMask在COCO上的精度(41.3AP)与速度(BlendMask-RT 34.2mAP, 25FPS on 1080ti)都超越了Mask R-CNN。
detector module直接用的FCOS,BlendMask模块则由三部分组成:bottom module用来对底层特征进行处理,生成的score map称为Base;top layer串接在检测器的box head上,生成Base对应的top level attention;最后是blender来对Base和attention进行融合。
BlendMask 的优势:
计算量小:使用一阶段检测器FCOS,相比Mask R-CNN使用的RPN,省下了对positon-sensitive feature map及mask feature的计算,
还是计算量小:提出attention guided blender模块来计算全局特征(global map representation),相比FCN和FCIS中使用的较复杂的hard alignment在相同分辨率的条件下,减少了十倍的计算量;
mask质量更高:BlendMask属于密集像素预测的方法,输出的分辨率不会受到 top-level 采样的限制。在Mask R-CNN中,如果要得到更准确的mask特征,就必须增加RoIPooler的分辨率,这样变回成倍增加head的计算时间和head的网络深度;
推理时间稳定:Mask R-CNN的推理时间随着检测的bbox数量增多而增多,BlendMask的推理速度更快且增加的时间可以忽略不计
Flexible:可以加到其他检测算法里面
总结
综上所述,我们大致可以看出两个趋势:一个是YOLCAT,RDSNet,BlendMask(RetinaNet, FCOS,PolarMask发展而来)单阶段基于硬编码(embedding)的实例分割;另一个是SOLO(FCIS)区分位置信息的方式。
两者没有特别大的区别,特别当embedding的通道数等于位置数目时。剩下的PointRend其实可以引出一个计算资源分配的问题,如何在有限次计算的情况下提升分割边缘的准确性。以上这些还是针对检测目的的,所以分割精度上有时在意,有时也不在意。在精确分割方面仍然有值得探索的地方,除了目前很火的attention机制,其实我觉得依然得回头去关注下标注不那么精细的情况下如何去提升边缘的分割精度(当然这又可能是个ill问题,或者是个外插问题,不过从guided filter的角度看至少还有些图像结构信息可以作为先验知识利用起来)
参考:
1.https://blog.csdn.net/sanshibayuan/article/details/103642419
2.https://blog.csdn.net/sanshibayuan/article/details/104011910
3.https://zhuanlan.zhihu.com/p/102231853
4.https://zhuanlan.zhihu.com/p/84890413
5.https://zhuanlan.zhihu.com/p/98351269
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

