代码知识点
JS&基础知识篇:
1、事件流
分为捕获型、冒泡型,addEventListener的第三个参数,为true是捕获型,为false是冒泡型(即默认不写是冒泡型)
常用的事件:click、mouseover(支持冒泡)、mouseout(支持冒泡)、mouseenter(不支持冒泡)、mouseleave(不支持冒泡)、blur(失焦支持冒泡)、focus(聚焦支持冒泡)、keyup(释放键盘)、keydown(按住键盘)、resize。
详见:JavaScript事件类型 - Wayne-Zhu - 博客园
event对象:target(事件触发的dom对象)、currentTarget(监听事件的dom对象)、stopPropagation(阻止冒泡)、preventDefault(阻止默认事件)
兼容写法:
event.preventDefault ? event.preventDefault() : (event.returnValue = false);
event.stopPropagation ? event.stopPropagation() : (event.cancelBubble = true);
event.stopPropagation其实是阻止事件的传播,并不是仅仅只是阻止冒泡,他连捕获事件也会阻止的
event.stopImmediatePropagation是在stopPropagation的基础上,把当前节点的同类事件也给阻止
document.getElementById('app').addEventListener('click', (e) => {
// 如果是e.stopPropagation()的话,下面会执行
e.stopImmediatePropagation()
console.log(e.currentTarget.tagName)
})
document.getElementById('app').addEventListener('click', (e) => {
// 这里不会执行
console.log(e.currentTarget.tagName)
})
document.getElementById('app').addEventListener('custom', () => {});
document.getElementById('app').dispatchEvent('custom', 'aaa')
2、原型链
每一个function方法都有一个prototype,每一个由方法new出来的对象都有一个_proto_,然后function的prototype和对象的_proto_是相等的,可以利用这个特性实现js的继承
A.prototype = new B();
Function和Object的关系
Function和Object都是构造函数,他们都是Function的实例对象,即Function.__proto__ === Function.prototoye
Object.__proto__ === Function.prototype
Object instanceof Function === true Function instanceof Object === true
3、面向对象
封装(函数封装)、继承(原型链继承)、多态(arguments参数多态)
4、内存泄漏
闭包、遗忘的定时器、dom引用
5、call bind apply
function test(a, b, c) {
console.log(a, b, c);
}
Function.prototype.bindNew = function() {
var self = this
var params = arguments
var context = params[0]
var args = Array.prototype.slice.call(params, 1)
return (...rest) => {
self.apply(context, args.concat(rest))
}
}
test.bindNew(window, 1, 2)(3);
6、闭包
在外部获取函数体内部变量的值,就叫闭包
function test() {
var num = 1;
return function() {
return num;
}
}
var data = test()();
console.log(data);
//输出5个5
for (var i = 0; i < 5;i++) {
setTimeout(() => {
console.log(i)
}, 100)
}
通过闭包可以解决问题,输出01234
for (var i = 0; i < 5;i++) {
(function(a){
setTimeout(() => {
console.log(a)
}, 100)
})(i)
}
通过let也可以解决,输出01234
for (let i = 0; i < 5;i++) {
setTimeout(() => {
console.log(i)
}, 100)
}
setTimeout的第三个参数,可以给第一个参数的方法传递参数,也可以做到输出01234
for (var i = 0; i < 5;i++) {
setTimeout((a) => {
console.log(a)
}, 100, i)
}7、伪类 伪元素
伪类:
:link
:visited
:hover
:active
:first-child
:first-of-type
:last-child
:last-of-type
伪元素:
::before
::after
.xxx:first-child和.xxx:first-of-type 的区别?
(https://www.jianshu.com/p/b6981849ab3b)
:first-child匹配的是某个父元素的第一个子节点的class是否为xxx,如果不是,就没有
:first-of-type匹配的是某个父元素的第一个class为xxx的子节点(父元素的第二个子节点为xxx也能匹配到)
为什么要清除浮动?
因为子元素是浮动,就脱离了文档流,父元素的高度就会出现异常,如果这个时候给父元素设置背景色或者边框什么的样式的话,就和想象中不一致,这个时候就必须要用清除浮动来撑开父元素的高度
清除浮动:
Document
8、深浅拷贝
值引用(为了解决下面这个问题,就出现了深浅拷贝):
var obj1 = { a: 1 };
var obj2 = obj1 ;
obj2.b = 2;
console.log(obj1);
console.log(obj2);
深拷贝:
lodash的cloneDeep
for in 循环可以循环一个对象的原型链的属性,Object.keys就拿不到原型链里的属性
for in 通过hasOwnProperty可以判断是否是自己的属性,而不是原型链的属性
浅拷贝:
var obj1 = { a: 1 };
var obj2 = $.extend({}, obj1); // 或者用var obj2 = Object.assign({}, obj1)
obj2.b = 2;
console.log(obj1);
console.log(obj2);
浅拷贝有一个问题就是,多层次会有问题,多层次直接覆盖对象,不会进行合并
var a = {a:1, b: {c:1, d:2}}
var b = {a:2, b: {c:2, e:3}}
var c = Object.assign(a, b) // 或者var c = $.extend(a, b)
console.log(a) // 输出 {a:2, b: {c:2, e:3}}
console.log(c) // 输出 {a:2, b: {c:2, e:3}}
console.log(a === c) // 输出 true
a.b.c = 4
console.log(a) // 输出 {a:2, b: {c:4, e:3}}
console.log(c) // 输出 {a:2, b: {c:4, e:3}}
这个时候的浅拷贝,实际b还是个指针形式,a改变了还是c会被改变
用lodash的merge方法,可以实现想要的merge
var a = {a:1, b: {c:1, d:2}}
var b = {a:2, b: {c:2, e:3}}
var c = _.merge(a, b)
console.log(c) // {a:2, b: {c:2, d:2, e:3}}
console.log(a) // {a:2, b: {c:2, d:2, e:3}}
深拷贝的循环引用使用 weakMap 做缓存,遇到value在weakMap中,就不做深拷贝,直接用 weakMap 中的值
9、盒子模型
margin、border、padding、content
box-sizing: border-box; // IE盒子 width=content+padding+border
box-sizing: content-box; // W3C标准盒子 width=content10、flex布局的注意事项(flex布局的注意事项_初漾的博客-CSDN博客)
11、从输入 URL 到页面加载完成的过程中都发生了什么事情?(从输入URL到页面加载完成的过程中都发生了什么事情? - SegmentFault 思否)
(网络 | 前端进阶之道)
1、DNS解析域名获取到IP
2、客户端和服务端建立连接(三次握手)
3、客户端向服务端发起请求
4、服务端根据不同请求返回不同的状态码和对应数据给客户端(200,304缓存,404,500等)
5、客户端拿到数据之后开始解析,根据HTML生成DOM树,CSS文件生成CSSOM树,然后由这2个树生成一个渲染树对页面进行渲染
图片资源如果是display:none,也会发网络请求DNS解析域名过程
1、浏览器查看缓存是否有该域名的访问记录,有的话返回IP
2、本机查询hosts文件中是否有该域名的配置,有的话返回IP
3、路由器查询缓存中是否有该域名的访问记录,有的话返回IP
4、再到ISP(互联网服务提供商)DNS缓存中查询该域名的IP,有的话返回IP
5、到全球仅有的13个根域名服务器群中查询,有的话返回IP
6、顶级域名服务器中查询,有的话返回IP递归解析:一直透传
迭代解析:先查询浏览器缓存是否有记录,如果没有,就返回,然后再到hosts文件中查询是否有记录,没有就再返回。。
12、GET请求和POST请求的区别
13、doctype有什么作用?
14、跨域问题 srcipt标签src跨域 POSTMESSAGE access-control-allow-origin
1、form表单可以跨域,因为form表单提交之后,是收不到响应的,浏览器认为这样是安全的。
2、浏览器的同源策略,限制的是不能从其他域拿到数据,但是它并不阻止你向其他域发请求
3、form表单提交会带cookie,比如就会带上
baidu.com的cookie,但是baidu.com如果限制了samesite的cookie,是不会带的,form表单提交是可以做csrf攻击的
4、ajax和fetch跨域的时候默认是不会携带cookie的,如果要携带的话,fetch可以增加credentials参数(same-origin默认值、include携带、omit不携带),ajax可以增加withCredentials参数(true携带、false不携带),但是samesite的cookie一样是不会带的。另外在增加了credentials和withCredentials参数之后,后端设置Access-Control-Allow-Origin不能为*,只能为指定的域名,且后端必须设置 Access-Control-Allow-Credentials: trueCORS——跨域请求那些事儿 - 云享 - 博客园
15、AMD和CMD、CommonJS和ESModule区别
AMD依赖前置,CMD依赖就近。AMD依赖加载完再往下运行,CMD由上往下,边加载依赖,边运行
1、CommonJS是被加载的时候运行,ESModule是编译的时候运行
2、CommonJS输出的是值的浅拷贝,ESModule输出的是引用
3、CommonJS第一次require模块的时候会运行整个文件并输出,后面再次require就会从内存中取值
16、为什么利用多个域名来存储网站资源会更有效?(为什么用多个域名来存储网站资源会更有效 - (f)VV>)
17、浏览器兼容性问题
18、H5 Android IOS兼容性问题
19、rem布局(rem布局实现不同分辨率移动终端的自适应、整体缩放_irokay的博客-CSDN博客)
移动端基础知识概述与适配(前端基础知识概述 -- 移动端开发的屏幕、图像、字体与布局的兼容适配 - 掘金)
移动端视口
视口总结 - 掘金
移动端兼容性问题(移动端适配及PC端适配心得总结体会(一) (可能比较全 - 掘金) (移动端适配及PC端适配心得总结体会(二) (可能比较全 - 掘金)
设计稿是750px的,以iphone6为准,iphone6设备是750px宽,它上面的html字体大小是75px,然后设计稿中为375px宽的按钮,就是5rem,公式是rem = (设计稿上的像素 / 75) * 1rem;就是1rem=75px
H5和客户端通信 => JSBridge
1、客户端调用H5,客户端可以通过代码调用webview里面的window下的方法,将需要传递的数据通过参数传给H5
2、H5调用客户端,客户端会在webview中注册一个方法放在window下,然后H5调用window下的这个方法,就可以将数据传递给客户端20、H5 iphoneX适配问题(iPhoneX适配方案_enoyao的博客-CSDN博客_iphonex分辨率)
@media only screen and (device-width: 375px) and (device-height: 812px) and (-webkit-device-pixel-ratio: 3) {
.container{
padding: constant(safe-area-inset-top) 0 constant(safe-area-inset-bottom) 0;
padding: env(safe-area-inset-top) 0 env(safe-area-inset-bottom) 0;
}
.prepare{
padding-top: pxToRem(75px);
padding-bottom: pxToRem(75px);
.btn{
margin-top: pxToRem(44px);
}
}
.balance-con{
margin-bottom: constant(safe-area-inset-bottom);
margin-bottom: env(safe-area-inset-bottom);
}
.invite-code{
bottom: 0 0 constant(safe-area-inset-bottom) 0;
bottom: 0 0 env(safe-area-inset-bottom) 0;
}
.service{
bottom: constant(safe-area-inset-bottom);
}
}
21、H5 点击穿透 滚动穿透
点击穿透:
touch事件分为touchstart、touchend,touch和click中间相隔300ms
为什么有300ms延迟:是因为移动端要有双击缩放的需求,就用了300ms的延迟
遮盖的元素绑定touch事件,
被遮盖的元素绑定click事件,就会有点击穿透,被遮盖的元素也会触发click事件
解决方法:
1、在遮盖元素延时350ms再隐藏
2、遮盖元素绑定touchend事件,在事件中让被遮盖元素增加一个样式pointer-events:none;
去除300ms的途径:
1、meta设置禁用缩放
2、FastClick的实现原理是在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉
滚动穿透:
弹出框是fixed,然后再弹出啊框滑动的时候,会让页面滑动
解决方法:
如果弹出框内部不需要滑动:
$('.mask').on('touchmove', (e)=> {
e.preventDefault();
})
阻止默认事件,能阻止页面滑动
如果弹出框内部需要滑动
在弹出框出现的时候,设置$('html,body').css('overflow', 'hidden');
在弹出框消失的时候,设置$('html,body').css('overflow', 'auto');
22、微信小程序
23、使用 CSS 预处理器(如less、sass、suitcss)的优缺点有哪些?
24、React Redux
25、promise (经常在请求jsonp配置文件的时候用,就是写一个promise,他的内部是一个异步获取数据的过程,获取成功resolve,失败reject,然后promise.then分别处理成功和失败的回调)
var promise = new Promise((resolve, reject) => {
if (true) {
setTimeout(() => {
resolve(1);
});
} else {
setTimeout(() => {
reject(0);
});
}
});
promise.then((res) => {
console.log(res);
});
26、cookie、session
cookie的作用:
1.可以在客户端上保存用户数据,起到简单的缓存和用户身份识别等作用。
2.保存用户的登陆状态,用户进行登陆,成功登陆后,服务器生成特定的cookie返回给客户端,客户端下次访问该域名下的任何页面,将该cookie的信息发送给服务器,服务器经过检验,来判断用户是否登陆。
3.记录用户的行为。
cookie弊端:
1.增加流量消耗,每次请求都需要带上cookie信息。
2.安全性隐患,cookie使用明文传输。如果cookie被人拦截了,那人就可以取得所有的session信息。
3.Cookie数量和长度的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉
27、前端模块加载,webpack
28、es6
29、婚礼微信小程序
30、ant desigh Pro
31、垂直居中
32、层级上下文
33、箭头函数和普通函数区别 箭头函数与普通函数的区别 - biubiu小希希 - 博客园
1、箭头函数不能用new
2、箭头函数this指向是上下文,构造函数this指向生成的对象,其他的函数this指向是调用函数的对象
3、箭头函数没有prototype
4、箭头函数没有arguments,取而代之的是rest参数
const func = (...rest) => {
console.log(rest); // [1,2,3]
}
func(1,2,3);
34、new干了啥(https://www.cnblogs.com/faith3/p/6209741.html )
var obj = new AAA();
等同于
var obj = {};
obj._proto_ = AAA.prototype;
AAA.call(obj);
(1) 创建一个新对象;
(2) 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象) ;
(3) 执行构造函数中的代码(为这个新对象添加属性) ;
(4) 返回新对象。
实现new的功能
function SelfNew() {
var params = Array.prototype.slice.call(arguments, 1)
var func = arguments[0]
var obj = {}
obj.__proto__ = func.prototype
var result = func.apply(obj, params)
if (typeof result === 'object' && result !== null) {
return result
} else {
return obj
}
}
function A(a, b) {
this.a = a
this.b = b
return 1
}
var a = SelfNew(A, 1, 2)
console.log(a)
console.log(new A(1,2))
构造函数如果return了基础数据类型,就对new出来的对象无影响,
如果return了复杂数据类型,就是return的那个对象
function A() {
this.name = 'name'
this.sex = 'male'
return 1
}
function B() {
this.name = 'name'
this.sex = 'male'
return {}
}
var a = new A()
var b = new B()
console.log(a) // {name: 'name', sex: 'male}
console.log(b) // {}
new.target可以判断一个函数是否是以构造函数的形式被调用的
function Person(name) {
if (new.target !== undefined) {
this.name = name;
} else {
throw new Error('必须使用 new 命令生成实例');
}
}
// 另一种写法
function Person(name) {
if (new.target === Person) {
this.name = name;
} else {
throw new Error('必须使用 new 命令生成实例');
}
}
35、作用域链 javascript学习中自己对作用域和作用域链理解 - 萧诺 - 博客园
个人理解:从里到外的作用域形成的链
分为全局作用域和函数作用域,然后函数内部可以通过作用域链去访问到他的父函数乃至全局作用域下的一些变量。
var a = 1;
function A() {
var b = 2;
function B() {
var c = 3;
console.log(a); //1
console.log(b); //2
}
}
函数B可以通过作用域链,访问到父函数A环境下里的变量b,也可以访问到全局环境的变量a首先先来了解什么是作用域,即变量(变量作用域又称上下文)和函数生效(能被访问)的区域或集合
换句话说,作用域决定了代码区块中变量和其他资源的可见性 我们一般将作用域分成:
-
全局作用域:任何不在函数中或是大括号中声明的变量,都是在全局作用域下,全局作用域下声明的变量可以在程序的任意位置访问
-
函数作用域:函数作用域也叫局部作用域,如果一个变量是在函数内部声明的它就在一个函数作用域下面。这些变量只能在函数内部访问,不能在函数以外去访问
-
块级作用域:ES6引入了
let和const关键字,和var关键字不同,在大括号中使用let和const声明的变量存在于块级作用域中。在大括号之外不能访问这些变量
什么是作用域链:当在Javascript中使用一个变量的时候,首先Javascript引擎会尝试在当前作用域下去寻找该变量,如果没找到,再到它的上层作用域寻找,以此类推直到找到该变量或是已经到了全局作用域
如果在全局作用域里仍然找不到该变量,它就会在全局范围内隐式声明该变量(非严格模式下)或是直接报错
36、作用域 JS中的块级作用域,var、let、const三者的区别_hot_cool的博客-CSDN博客_块级作用域
1、var定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问。
2、let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问。
3、const用来定义常量,使用时必须初始化(即必须赋值),只能在块作用域里访问,而且不能修改。
为什么要有let和块级作用域??
函数作用域会有这样的现象,函数内部的同名变量会覆盖外层的变量,块级作用域就不会有这样的问题,let创建的变量会出现块级作用域,let声明的变量不会出现变量提升,不能重名,因为会出现暂时性死区
37、jQuery.fn = jQuery.prototype
38、进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。
39、线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。线程由CPU独立调度执行,在多CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
40、同步就是得到结果才会返回,异步没得到结果就返回
41、并发是一个CPU执行多个程序,并行是多个CPU执行多个程序
42、阻塞就是调用返回结果之前,线程会挂起,这时候就是阻塞,非阻塞就是调用结果返回之前,不会阻塞当前线程
43、null undefined String Number Boolean Object Symbol typeof '11' == String
== 会做类型转换
=== 不会做类型转换
Object.is会在===的基础上,特殊处理了NaN,0,-0的情况
NaN === NaN // false
0 === -0 // true
Object.is(NaN,NaN) // true
Object.is(0,-0) // false
为什么typeof可以检测类型?
js在底层存储变量的时候会在变量的机器码的低位1-3位存储其类型信息(000:对象,010:浮点数,100:字符串,110:布尔,1:整数),但是null所有机器码均为0,直接被当做了对象来看待
var a = new String('11'); a instanceof String == true
null表示没有对象,即此处不应该有值。undefined表示缺少值,即此处应该有值,但没有定义
44、web前端性能优化 更快速将你的页面展示给用户[前端优化篇] - wingkun - 博客园
1、图片预加载,请求懒加载
2、工程化压缩合并js、css文件,减少文件请求数量
3、用多个域名存放文件
4、本地缓存localstorage
5、css动画替换js动画,H5播放器替换flash播放器
6、webpack图片压缩插件,路由拆分代码,按需加载
请求优化
图片延迟加载
ajax局部加载数据
预加载
资源优化
资源压缩(uglify-js,clean-css)
资源合并
自动化构建(gulp)
图片合并csssprite
iconfont
引用优化
单独域名存放资源
缓存
Cache-Control缓存策略
离线存储
本地存储localStorage
其它的
css3替换js动画
替换flash
结语
45、xss(XSS攻击原理及防御措施 - 很好玩 - 博客园)
xss是跨站脚本,在输入的地方写html或js,然后服务端接受到了,在其他客户端会收到这串脚本,就会执行
Html
encode防止xss,js-xss库防止xss
46、csrf(CSRF攻击原理及防御 - 很好玩 - 博客园)(https://www.v2ex.com/t/516357)
csrf是跨站请求攻击,恶意用户通过某种途径拿到了正常用户的cookie,然后通过cookie去模拟正常用户去发送一些恶意请求
验证 HTTP Referer 字段,判断来源
Token防止csrf,尽量不要在cookie中暴露用户隐私信息
same-site字段防止第三方网站
举例:
比如你登录了一个银行网站A,银行网站A里面有个请求是更新你的账户数据的,然后这个时候你进入了一个危险网站B,这个危险网站B里面会调用银行网站A里面的这个更新数据的接口,那么你就会发出一个银行网站A的更新数据的请求,并且会带上银行网站A的cookie,这个时候就是csrf
用token,就可以在调用这个接口的时候,让你带不上这个token,带不上token服务端就不会进行更新操作了
问题:如果token被盗用了怎么办?
token 不是用来做用户信息加密的,而是和 session 一样用来做身份鉴别的,至于信道安全性还是需要用 https 保证47、变量提升和函数提升(JavaScript 声明提升 | 菜鸟教程)
JavaScript 中,函数及变量的声明都将被提升到函数的最顶部。
JavaScript 中,变量可以在使用后声明,也就是变量可以先使用再声明。48、Array数组方法(js数组方法大全 - 流sand - 博客园)
slice(): 第一个参数是开始位置(第一个从0开始),第二个参数(可省)是结束位置,
如果没有第二个参数,默认就是最后一个位置,但不包括结束位置的项,为负数就加上数组长度进行转换。
源数组不会改变。
var arr = [1,3,5,7,9,11];
var arrCopy = arr.slice(1);
var arrCopy2 = arr.slice(1,4);
var arrCopy3 = arr.slice(1,-2);
var arrCopy4 = arr.slice(-4,-1);
console.log(arr); //[1, 3, 5, 7, 9, 11](原数组没变)
console.log(arrCopy); //[3, 5, 7, 9, 11]
console.log(arrCopy2); //[3, 5, 7]
console.log(arrCopy3); //[3, 5, 7]
console.log(arrCopy4); //[5, 7, 9]
splice():
2个参数代表删除,第一个参数是开始位置(第一个从0开始),第二个参数是要删除的个数(传0代表不删除),源数组会改变。
3个参数(或者更多参数)代表删除后再插入,第一个参数是开始位置(第一个从0开始),第二个参数是要删除的个数(传0代表不删除),第三个参数为插入的值。
var arr = [1,3,5,7,9,11];
var arrRemoved = arr.splice(0,2);
console.log(arr); //[5, 7, 9, 11]
console.log(arrRemoved); //[1, 3]
var arrRemoved2 = arr.splice(2,0,4,6);
console.log(arr); // [5, 7, 4, 6, 9, 11]
console.log(arrRemoved2); // []
var arrRemoved3 = arr.splice(1,1,2,4);
console.log(arr); // [5, 2, 4, 4, 6, 9, 11]
console.log(arrRemoved3); //[7]49、JS运行机制(彻底搞懂JavaScript事件循环 - 掘金)
场景题:js|面试中常被问到的场景题 - 掘金
1、JavaScript是单线程,一个时间段内,JavaScript只能干一件事情。
2、任务队列分为同步任务和异步任务
3、异步任务包括setTimeout、setInterval、dom事件绑定(addEventListener)、ES6的Promise
4、所以同步任务都会在主线程上执行,然后异步任务会放到任务队列中去,一旦主线程的同步任务执行完,系统就会去读取异步任务的返回结果并执行异步任务
阮一峰的解释:
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
Event Loop
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
那么问题来了,为什么要将任务队列分为微任务和宏任务呢,他们之间的本质区别是什么呢?
JavaScript在遇到异步任务时,会将此任务交给其他线程来执行(比如遇到setTimeout任务,会交给定时器触发线程去执行,待计时结束,就会将定时器回调任务放入任务队列等待主线程来取出执行),主线程会继续执行后面的同步任务。
对于微任务,比如promise.then,当执行promise.then时,浏览器引擎不会将异步任务交给其他浏览器的线程去执行,而是将任务回调存在一个队列中,当执行栈中的任务执行完之后,就去执行promise.then所在的微任务队列。
所以,宏任务和微任务的本质区别如下:
微任务:不需要特定的异步线程去执行,没有明确的异步任务去执行,只有回调;
宏任务:需要特定的异步线程去执行,有明确的异步任务去执行,有回调;50、webpack
1、出口入口
2、style-loader、css-loader、file-loader(图片)、babel-loader(es6、react)
3、HtmlWebpackPlugin(html模板)
4、devServer(模块热替换,简称热加载)
5、devtool(source-map,可以在浏览器中调试源代码)
6、css文件处理,先经过css-loader将@import和url这种外部资源处理为require,再经过style-loader将CSS代码插入到dom中
7、plugin是一个具有apply方法的对象,他可以在webpack编译流程中处理很多东西,loader是处理非js模块的,loader是从右往左顺序执行的,loader就像是一个管道,一个字符串进,一个字符串出
8、module是开发的时候的一个模块,比如export一个模块,chunk就是由多个module组成的块,比如entry chunk,bundle是由多个chunk组成的,打包出来的最终文件
9、tree-shaking是将没有被import的export干掉,然后由uglify去把多余的代码删除,比如:
export function A() {
console.log(111)
}
这个时候没有去import {A} from 'xxx'
tree-shaking就会去把export干掉,然后uglify会把function A(){ console.log(111) }干掉
另外CommonJS规范不能用tree-shaking,因为他是加载的时候运行的,有些插件宣称可以对CommonJS进行tree-shaking,但是也会有一些限制(webpack-common-shake插件)
51、window和document的区别,BOM对象
1、document是window的一个属性,window.document
2、window是整个浏览器打开的一个窗口
3、document是窗口下面的文档,用来访问文档里面的元素
4、常见的BOM对象:
window、alert、setTimeout、setInterval、location、navigator、history、screen52、函数防抖和函数节流
拿resize或者scroll事件来说,在resize窗口的时候,resize的callback会调用很多次,
这样性能会很差,这就是函数防抖和函数节流的需要发挥作用的时候了
1、函数防抖:就是在多次连续resize的时候,只执行1次resize
2、函数节流:就是在多次连续resize的时候,会按照时间间隔去执行resize。
就是说如果连续很长时间执行resize,就会500ms执行一次,然后过500ms再执行一次,然后过500ms再执行一次。。。
函数防抖实现:
function func(fn, context, delay) {
var timer = null;
return function() {
clearTimeout(timer);
timer = setTimeout(function() {
fn.call(context);
}, delay);
}
}
window.onscroll = func(function() {console.log(1);}, window, 500);
window.onresize = func(function() {console.log(1);}, window, 500);
函数节流实现:
function func(fn, context, delay) {
var timer = null;
var last = 0;
return function() {
var date = Date.now();
if (date - last > delay) {
last = Date.now();
timer = setTimeout(function() {
fn.call(context);
}, delay);
}
}
}
window.onscroll = func(function() {console.log(1);}, window, 500);
window.onresize = func(function() {console.log(1);}, window, 500);53、http协议相关
1、长轮询和短轮询
短轮询是简单的setInterval()做的轮询,服务端收到请求就立马返回,然后客户端根据时间间隔去请求
长轮询是是对短轮询的改进版,客户端发送HTTP给服务端之后,服务端看有没有新消息,如果没有新消息,就一直等待,把请求挂起。当有新消息的时候,才会返回给客户端。在这段时间中,如果请求超时了,客户端会在超时的回调方法中,继续发起下一个请求,直到收到服务端的正常的返回。当客户端收到服务端正常的返回之后,客户端在正常返回的回调里面,也会继续发起下一个请求
2、长连接和短连接
短连接是客户端和服务端每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。也可以这样说:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
长连接是客户端和服务端进行的HTTP操作,建立一次连接之后,不会马上断开连接,HTTP1.1之后,出现了Connection: keep-alive,这个就是说默认是长连接
3、三次握手和四次挥手
三次握手:
1、客户端像服务端发起请求报文段
2、服务端拿到客户端发出的请求之后,再返回给客户端一个响应
3、客户端当收到服务端的响应报文之后,就再发出一个请求,告诉服务端自己收到了响应
四次挥手:
1、客户端没有数据要请求了,就会发出关闭连接的请求
2、服务端接到关闭连接请求之后,会再返回客户端一个响应告诉客户端自己收到这个关闭连接的请求了
3、服务端会把需要传输到客户端的数据全部传输完成之后,再发出一个连接释放的响应给客户端
4、客户端收到了响应之后,就再发出一个确认请求,告知服务端可以释放连接了,然后客户端会经过一段时间之后就完全关闭了,服务端这个时候接到客户端的确认请求之后,也就关闭了
问题1:为什么需要3次握手才能建立连接,而不是2次就可以了
答:因为如果服务端收到的客户端的请求是早已经超时的那种,服务端就算返回了响应,也不能正确的建立连接,必须需要第三次的请求来得知客户端是不是确认收到了响应
问题2:为什么需要4次挥手关闭连接
答:因为当建立连接的时候服务端可以将SYN和ACK同时给客户端,但是当关闭连接的时候,服务端必须保证他的数据全部传输完成之后,再关闭连接,所以第一次接到客户端的请求的时候,只会先发送一个ACK报文给客户端告知它自己已经知道要关闭连接了,然后再等待所有数据传输完成之后,再发送一个响应告知客户端要关闭连接,自己的数据发送完了,就多了这么一次54、数据结构
栈:先进后出
队列:先进先出
二叉树:二叉树拥有一个根节点,每个节点最多有2个子节点。
满二叉树:如果除最后一层无任何子节点外,每一层上的所有结点都有两个子结点二叉树,就叫满二叉树
完全二叉树:如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树
二分查找树:二叉树 + 每个节点都比左边的子节点值大,比右边的子节点值小
堆:满二叉树 + 每个节点都比它的子节点值小(大),如果小的话叫最小堆,大的话叫最大堆
DFS(Depth First Search):深度优先搜索(二叉树的DFS包括先序遍历、中序遍历、后序遍历)
BFS(Breath First Search):广度优先搜索
JS基础数据类型存在栈中,复杂数据类型存在堆中,栈是一种先进后出的数据结构,堆是一棵树http://c.biancheng.net/view/3384.html


55、类数组
1、function里面的arguments
2、document.getElementsByTagName()返回值
3、jQuery对象 $('#id')
function A() {
console.log(arguments)
console.log(arguments.length)
console.log(Array.prototype.slice.call(arguments))
console.log(Array.prototype.slice.call(arguments).length)
console.log(Array.from(arguments))
console.log(Array.from(arguments).length)
}
A(1,2)
arguments是有length属性的,用Array.prototype.slice.call或者Array.from可以将arguments转成真实数组,但是Array.from有兼容性问题,IE不支持56、script(浅谈script标签中的async和defer - 贾顺名 - 博客园)
defer:
如果script标签设置了该属性,则浏览器会异步的下载该文件并且不会影响到后续DOM的渲染;
如果有多个设置了defer的script标签存在,则会按照顺序执行所有的script;
defer脚本会在文档渲染完毕后,DOMContentLoaded事件调用前执行。
async:
async的设置,会使得script脚本异步的加载并在允许的情况下执行
async的执行,并不会按着script在页面中的顺序来执行,而是谁先加载完谁执行。
总结:
1、defer的加载和async的加载都不会阻塞DOM的渲染
2、defer的执行会在文档渲染完之后,再去一个个脚本去执行(注意:在实际中,多个defer脚本不一定会严格按照顺序去执行,所以最后只搞一个defer脚本,from javascript高级程序设计 https://segmentfault.com/a/1190000014201139)
3、async的执行是脚本加载完之后就立马执行
4、defer的执行是不会阻塞DOM渲染的,因为defer执行的时候,文档已经渲染完了
5、async的执行是会阻塞DOM渲染的,因为这个时候文档还可能没有渲染完57、BFC
BFC(Block Formatting Context)块级格式化上下文
怎么触发BFC:
1、float不为none(left、right)
2、overflow不为visible(auto、hidden、scroll)
3、position绝对定位(absolute、fixed)
4、display(inline-block、table-cells、flex)
典型案例:
1、边距折叠
两个DIV上下分布,margin-bottom和margin-top会重叠,这个时候给上面的div包裹一个父级div,给父级div设置一个overflow: auto;就可以解决边距折叠了
Document
2、高度塌陷(浮动)(https://www.jianshu.com/p/641a72e5fc5f)
父元素中有一个div设置float之后,会脱离文档流,这个时候,父元素的高度就塌陷了。可以有3种方式解决问题
1) 开启父元素的BFC,比如给父元素增加overflow:auto;就可以解决
2) 在父元素的尾部增加一个div,给他设置clear:both;display:block; 这样就把父元素整个给撑开了,clear也清除了浮动
3) 用伪元素::after替换增加div,就可以解决一直要多加div的问题了58、Babel(Babel 插件原理的理解与深入 - SegmentFault 思否)
Babel就是一个编译器,他可以把ES6 ES7规范的代码写法编译为ES5规范的代码。
他编译的过程主要包括下面几步:
解析 Parse (babylon)
1、对代码进行词法分析和语法分析,将代码解析为AST语法树
转换 Transform (babel-traverse)
2、对AST语法树做一些增删改的操作,生成一个新的AST语法树
生成 Generate (babel-generator)
3、将新的AST语法树转换为js代码和源码映射
AST语法树(https://astexplorer.net/)59、浏览器缓存机制(深入理解浏览器的缓存机制 - 简书)
https://github.com/frontend9/fe9-interview/issues/29
强缓存:
Expires:是缓存的过期时间,以服务端的时间为主(HTTP1.0)
Cache-Control:可以设置不同类型来控制缓存策略(HTTP1.1)
协商缓存:主要是强缓存失效之后,浏览器携带缓存标识向服务器发起请求,由服务器根据标识来判断是否要使用缓存
协商缓存生效状态码返回304,失效返回200
Last-Modified:浏览器第一次访问资源,服务器会返回这个值,然后下一次浏览器再次访问资源会带上这个Last-Modified,服务器会判断这个时间内资源有没有修改,修改了就返回200,没修改就使用缓存返回304
ETag:浏览器第一次访问资源,服务器会返回这个值,然后下一次浏览器再次访问资源会带上这个ETag,服务器会判断这个时间内资源有没有修改,修改了就返回200,没修改就使用缓存返回304
from memory cache:直接从内存中拿资源,浏览器会将一部分资源(小图片base64)放在内存中缓存
from disk cache:直接从磁盘中拿资源。浏览器会将一部分资源(js、css、大图片)放在磁盘中缓存
优先 memory cache,其次disk cache,都没有就http
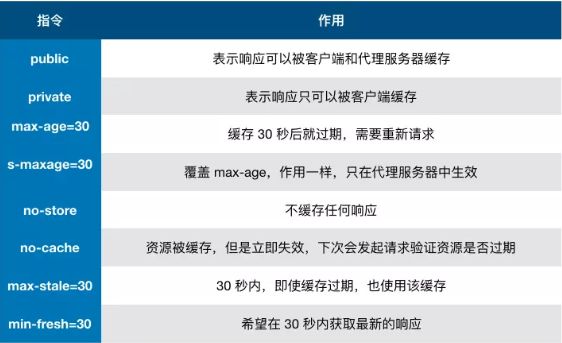
no-cache和no-store:
no-cache是浏览器需要咨询服务器这个缓存是否更新了,进而使用协商缓存进行对比,Last-Modified和etag,服务器告知变更了,就拿服务器最新的,没有变更就继续用缓存
https://blog.51cto.com/u_15766933/5629135
no-store是浏览器不缓存,每次都从服务器拿1.服务器首先产生Etag,服务器可在稍后使用它来判断页面是否被修改。本质上,客户端通过该记号传回服务器要求服务器验证(客户端)缓存
2.304是 HTTP的状态码,服务器用来标识这个文件没有被修改,不返回内容,浏览器接受到这个状态码会去去找浏览器缓存的文件
3.流程:客户端请求一个页面A。服务器返回页面A,并在A上加一个eTag客服端渲染该页面,并把eTag也存储在缓存中。客户端再次请求页面A 并将上次请求的资源和ETag一起传递给服务器。服务器检查eTag.并且判断出该页面自上次客户端请求之后未被修改。直接返回304
last-modified: 客服端请求资源,同时有一个last-modified的属性标记此文件在服务器最后修改的时间 客服端第二次请求此url时,根据http协议。浏览器会向服务器发送一个If-Modified-Since报头, 询问该事件之后文件是否被修改,没修改返回304
问题:有了Last-Modified,为什么还要用ETag?
1、因为如果在一秒钟之内对一个文件进行两次更改,Last-Modified就会不正确(Last—Modified不能识别秒单位的修改)
2、某些服务器不能精确的得到文件的最后修改时间
3、一些文件也行会周期新的更改,但是他的内容并不改变(仅仅改变修改的事件),这个时候我们并不希望客户端认为文件被修改,而重新Get
问题:有了ETag,为什么还要用Last-Modified?
1、两者互补,ETag的判断的缺陷,比如一些图片等静态文件的修改
2、如果每次扫描内容都生成ETag比较,显然要比直接比较修改时间慢的多。
ETag是被请求变量的实体值(文件的索引节,大小和最后修改的时间的Hash值) 1、ETag的值服务器端对文件的索引节,大小和最后的修改的事件进行Hash后得到的。


60、函数式编程
函数式编程的思想是:
1、函数是一等公民
2、函数一定要是纯函数,纯函数就是没有副作用,副作用比如splice,会影响原数组,纯函数的好处就是,他的可移植性,可测试性
3、柯里化是将多参数的函数拆分为单个参数的函数,内部再返回一个函数,这个函数是接收后面的参数,依次处理,就是缩小了函数的适用范围
function curry(func) {
var self = this
return function fn(...params) {
if (params.length === func.length) {
return func.apply(self, params)
}
return (...innerParams) => {
return fn.apply(self, [...params, ...innerParams])
}
}
}
function test(a,b,c) {
console.log(a,b,c)
}
var func1 = curry(test)
var func2 = func1(1)
var func3 = func2(2)
func3(3)
// 反柯里化是将一些方法扩大使用范围,比如将Array.prototype.push等这样的已经成型的方法扩大使用范围,让不是数组类型也对象也能使用
function uncurry(fn) {
return (target, ...params) => {
return fn.apply(target, params)
}
}
var slice = uncurry(Array.prototype.slice)
function test() {
var result = slice(arguments, 1)
console.log(result)
}
test(1,2,3,4)
// 第二种反柯里化方法
Function.prototype.uncurry = function() {
var self = this
return (...params) => {
return Function.prototype.call.apply(self, params)
}
}
var slice = Array.prototype.slice.uncurry()
function test() {
var result = slice(arguments, 1)
console.log(result)
}
test(1,2,3,4)
4、函数组合(compose),参数是多个纯函数,返回值是一个带参数的函数
function compose(f, g) {
return function(x) {
return g(f(x))
}
}61、弹幕场景
模拟弹幕业务场景,通过socket-io向前端推送数据,每次推送10000条数据,总共推送3次,然后前端去处理渲染弹幕。
思路:首先,肯定不能拿到10000条数据,就直接在react中进行setState,这样会一帧直接渲染10000条弹幕dom,会导致内存溢出。需要增加缓冲池,通过requestAnimationFrame这个API去一条条或者一批一批的渲染弹幕;并增加策略,同时存在弹幕列表的dom最多只有200条,超过200条就删除,这样子的页面性能就会好很多。
62、https和http的关系,http2、以及https的工作原理和加密过程
1、http和https的关系和区别
首先,http协议是明文传输的,黑客可以拦截一些关键数据,https在http基础上,增加了SSL/TLS协议,
增强了安全性,http协议的端口号是80,https协议的端口号是443
2、SSL/TLS协议
TLS协议相当于是升级版的SSL协议吧,SSL协议主要用到了2种类型的加密技术,一种是对称加密,
一种是非对称加密
3、对称加密
对称加密是有一个秘钥,通过秘钥和加密算法对明文进行加密,得到一串加密之后的密文,
解密也需要同样的秘钥对密文进行解密。
对称加密的优点:效率高,计算时间少
对称加密的缺点:一般秘钥都是放在服务器的,客户端发请求拿到秘钥可能会被黑客拦截,这样的话就不安全了
4、非对称加密
非对称加密是有公钥和私钥,公钥和私钥是通过加密算法生成出来的一对,通过公钥和加密算法
对明文进行加密,得到一串加密之后的密文,解密则需要用私钥进行解密,才能拿到正确的明文
非对称加密的优点:安全性高,一般公钥和私钥都是放在服务器的,客户端发请求拿到公钥,就算
公钥被黑客拦截了,黑客没有私钥也不能解密
非对称加密的缺点:效率低,计算时间长
5、https的加密解密工作原理和过程
https是集合了对称加密和非对称加密2种方式去做的,首先服务端会有一个SSL证书,然后客户端
会拿到SSL证书,客户端拿到证书后,会去验证证书,验证不通过的话,就会提示不安全,验证通过就会继续往下。SSL证书就主要包括一个公钥,然后客户端拿到公钥之后,就会自己生成一个随机码,
这个随机码就是对称加密的秘钥,然后通过公钥将随机码加密,然后将加密之后的内容发送给服务器,
服务器拿到之后,就将密文通过私钥解密,解密之后就能得到对称加密的秘钥,这样客户端和服务器都
拿到了相同的秘钥可以进行对称加密了,后面每次发送的数据,就都会通过秘钥进行加密和解密
整个过程中,就算公钥和被加密的秘钥被黑客拿到,黑客没有私钥也没办法,对数据的加密解密用到了
对称加密,效率也提高了
6、https的坏处
页面加载时间变长、需要申请证书、证书要钱
7、http2的特性
header压缩、多路复用、服务端推送
header压缩:http2采用HPACK的压缩算法来压缩header,在服务端和客户端共同有一个静态索引表来维护索引值-key-value,如果静态索引表中找不到的就会维护一张动态索引表里面
多路复用:http2采用帧和流的方式去做,在头部进行压缩之后,http2会把报文拆分为多个二进制帧的形式进行传输,二进制帧主要包括
帧长度 3byte 默认上限为16k 最大为2^24
帧类型 1byte 大致分为数据帧和控制帧,最高可表示256种,可自己扩展
标志位 1byte 携带简单的控制信息
流ID 4byte 其中最高位为0,客户端发起的流id为奇数,服务器发起的流id为偶数,0号流为控制流
一个流就相当于是http1的一个连接
8、http1.1、http2、http3分别解决了什么问题
http1.1:keep-alive(解决了没发一次请求都重新建立连接的问题,可以减少建立连接次数,三次握手),强缓存协商缓存(*缓存策略,不多说了)
http2:多路复用(能够做到一个域名下只需要一个连接就能发多个请求了)、服务端推送(不多说了)
http3:使用QUIC(底层基于UDP),解决了http2基于TCP会有队首阻塞问题
https://zhuanlan.zhihu.com/p/46998803263、H5拖拽
JS Bin
draggable可以分解为下面几步:
1、onmousedown 2、onmousemove 3、onmouseup
64、排序(10大排序算法)
重温前端10大排序算法(长文建议收藏) - 掘金
65、引用和操作符优先级
var a = { x: 1 };
var b = a;
a = a.x = { x: 1 };
console.log(a);
console.log(b);
先输出{x:1}
再输出{x:{x:1}}
a = a.x = { x: 1 };这一步相当于:
a.x = { x: 1 }
a = a.x
后面a和b之所以不一样,是因为a引用后面更改了指向,指向了a.x,b还是指向原来a指向的那个地址66、二维码扫描登录
1、PC客户端端请求服务端,获取了一个uuid,然后根据uuid生成二维码
2、手机端已经登录了的,扫二维码之后,获取到uuid,然后将uuid和token传到服务端
3、服务端拿到uuid和token之后,将这2个作为一个映射,然后给PC端推送登录成功
如果不要推送,就要轮询
1、PC客户端端请求服务端,获取了一个uuid,然后根据uuid生成二维码,开始轮询调用服务端接口是否有登录成功
2、手机端已经登录了的,扫二维码之后,获取到uuid,然后将uuid和token传到服务端
3、服务端拿到uuid和token之后,将这2个作为一个映射
4、轮询接口发现登录成功67、浏览器渲染机制
1、解析HTML,遇到img标签的时候会加载图片文件 => 构建DOM树
2、解析CSS,遇到背景图片的时候不会马上加载背景图片 => 构建CSSOM树
3、DOM树和CSSOM树合成构建渲染树(此时开始加载CSS中的背景图片)
4、计算元素位置进行布局
5、根据计算的布局进行绘制(开始渲染图片)
总结:img标签中的图片是在构建dom树的时候加载的,背景图片是在构建渲染树后加载的
注:下面的加载都是说的是网络请求图片
情况一:img标签的图片比css的背景图片要先加载
 .bg1 {
background: url('./aaa/bg.png');
}
情况二:设置了display:none的元素的图片还是会加载,但是不会绘制
.bg1 {
background: url('./aaa/bg.png');
}
情况三:设置了display:none的元素的子元素的图片,img标签会加载图片,css背景图片不会加载,两者都不会绘制(浏览器是将display:none的元素的子元素都纳入到不可绘制元素,这些不可绘制元素不会在渲染树中)
.bg1 {
background: url('./aaa/bg.png');
}
情况四:重复的图片只会加载一次(浏览器缓存原因)
.bg1 {
background: url('./aaa/bg.png');
}
情况五:不存在元素的背景图片不会被加载(不存在的元素不会存在于dom树中,因此也不会存在于渲染树中)
.bg1 {
background: url('./aaa/bg.png');
}
.bg2 {
background: url('./aaa/bg2.png');
}
情况六:伪类的背景图片,只会在触发伪类的时候才会加载
.bg1:hover {
background: url('./aaa/bg.png');
}
.bg1 {
background: url('./aaa/bg.png');
}
情况二:设置了display:none的元素的图片还是会加载,但是不会绘制
.bg1 {
background: url('./aaa/bg.png');
}
情况三:设置了display:none的元素的子元素的图片,img标签会加载图片,css背景图片不会加载,两者都不会绘制(浏览器是将display:none的元素的子元素都纳入到不可绘制元素,这些不可绘制元素不会在渲染树中)
.bg1 {
background: url('./aaa/bg.png');
}
情况四:重复的图片只会加载一次(浏览器缓存原因)
.bg1 {
background: url('./aaa/bg.png');
}
情况五:不存在元素的背景图片不会被加载(不存在的元素不会存在于dom树中,因此也不会存在于渲染树中)
.bg1 {
background: url('./aaa/bg.png');
}
.bg2 {
background: url('./aaa/bg2.png');
}
情况六:伪类的背景图片,只会在触发伪类的时候才会加载
.bg1:hover {
background: url('./aaa/bg.png');
}68、Promise面试题
https://www.jianshu.com/p/4bb1521343ba
69、设计模式
1、单例模式
概念:指的是一个类只需要一个实例,会暴露一个方法获取唯一的实例
应用场景:登录弹窗,界面永远只会有一个登录弹窗
优点:一个类只有一个变量,可以适用于一些特定的业务场景
缺点:不适用于需要经常变化的对象,开发的时候用到单例模式要记住不能通过new直接调用
// es5
function Singleton(name) {
this.name = name
this.instance = null
}
Singleton.prototype.getName = function() {
console.log(this.name)
}
Singleton.getInstance = function(name) {
if (!this.instance) {
this.instance = new Singleton(name)
}
return this.instance
}
var a = Singleton.getInstance('a')
var b = Singleton.getInstance('b')
console.log(a === b)
//es6
class Singleton {
constructor(name) {
this.name = name
this.instance = null
}
getName() {
console.log(this.name)
}
static getInstance(name) {
if (this.instance) {
this.instance = new Singleton(name)
}
return this.instance
}
}
var a = Singleton.getInstance('a')
var b = Singleton.getInstance('b')
console.log(a === b)
2、工厂模式
概念:是一种用来创建对象的设计模式,他将具体的业务逻辑写在工厂里面,根据传递不同的类型的值决定创建什么类型的对象
应用场景:分析魔方创建组件实例,一般的组件、容器类组件等等
优点:实例创建的代码都在一块,方便维护,多用于创建多种不同类型的对象
缺点:创建出来的对象都是Factory实例,识别不出来具体的类型,除非在每个对象中都加上一个type的属性来识别
class Factory {
constructor(type, ...args) {
if (type && ['man', 'woman', 'superman', 'superwoman'].includes(type)){
this[type](...args)
}
}
man(name, age) {
this.sex = 'man'
this.isSuper = false
this.name = name
this.age = age
}
woman(name, age) {
this.sex = 'woman'
this.isSuper = false
this.name = name
this.age = age
}
superman(name, age) {
this.sex = 'man'
this.isSuper = true
this.name = name
this.age = age
}
superwoman(name, age) {
this.sex = 'woman'
this.isSuper = true
this.name = name
this.age = age
}
}
var man = new Factory('man', 'wangzilong', 27)
var woman = new Factory('woman', 'woman', 28)
var superman = new Factory('superman', 'superman', 29)
var superwoman = new Factory('superwoman', 'superwoman', 30)
console.log(JSON.stringify(man))
console.log(JSON.stringify(woman))
console.log(JSON.stringify(superman))
console.log(JSON.stringify(superwoman))
3、发布订阅模式
概念:发布订阅模式又叫观察者模式,它定义对象间的一对多的依赖关系,当一个对象的状态变化时,所有订阅了他的对象都会得到通知。在JS中我们一般用事件去处理
应用场景:简单的模块与模块之间的数据交互
优点:支持简单的广播通信,实现数据交互很方便
缺点:过多的使用会让代码的可读性变差,会到处去找订阅和发布的关系,维护发布和订阅的关系也需要耗费一定的内存
class Observer {
constructor() {
this.cache = {}
}
on(key, callback) {
if (!this.cache[key]) {
this.cache[key] = []
}
this.cache[key].push(callback)
}
trigger(key, ...params) {
var callbacks = this.cache[key]
callbacks.forEach(callback => {
callback(...params)
})
}
remove(key) {
this.cache[key] = null
delete this.cache[key]
}
}
var observer = new Observer()
export default observer
70、react高阶组件
概念:高阶组件是一个参数为组件、返回值为一个新组件的函数
优点:在有多个组件中有一些公共的业务逻辑的时候,可以使用高阶组件的方法进行公共业务逻辑的抽象
缺点:嵌套地狱,看代码找数据的时候会很难受
高阶组件和mixins的异同点:
1、高阶组件和mixins都是为了抽象一些公共的业务逻辑
2、mixins是混入,会将mixins里面的内容混入到使用mixins的组件中,高阶组件是一个参数为组件,返回值为一个新组件的参数,react的高阶组件是来源于函数式编程的高阶函数,和mixins的概念还是不太一样
例子:
function withSubscription(WrappedComponent, selectData) {
// ...并返回另一个组件...
return class extends React.Component {
constructor(props) {
super(props);
this.handleChange = this.handleChange.bind(this);
this.state = {
data: selectData(DataSource, props)
};
}
componentDidMount() {
// ...负责订阅相关的操作...
DataSource.addChangeListener(this.handleChange);
}
componentWillUnmount() {
DataSource.removeChangeListener(this.handleChange);
}
handleChange() {
this.setState({
data: selectData(DataSource, this.props)
});
}
render() {
// ... 并使用新数据渲染被包装的组件!
// 请注意,我们可能还会传递其他属性
return 71、异常处理
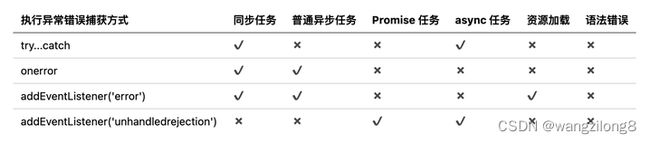
一般采用window.onerror的方式捕获同步异步任务,Promise和await用addEventListener('unhandledrejection') 监听,资源加载用addEventListener('error')捕获
72、position:sticky
CSS 定位详解 - 阮一峰的网络日志
73、set、map、weakset、weakmap
https://github.com/sisterAn/blog/issues/24
- Set
- 成员唯一、无序且不重复
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有:add、delete、has
- WeakSet
- 成员都是对象
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存DOM节点,不容易造成内存泄漏
- 不能遍历,方法有add、delete、has
- Map
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
- WeakMap
- 只接受对象作为键名(null除外),不接受其他类型的值作为键名
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有get、set、has、delete
74、FP、FCP、FMP、LCP
https://zhuanlan.zhihu.com/p/495649475
- load(Onload Event),它代表页面中依赖的所有资源加载完的事件。
- DCL(DOMContentLoaded),DOM解析完毕。
- FP(First Paint),表示渲染出第一个像素点。FP一般在HTML解析完成或者解析一部分时候触发。
- FCP(First Contentful Paint),表示渲染出第一个内容,这里的“内容”可以是文本、图片、canvas。
- FMP(First Meaningful Paint),首次渲染有意义的内容的时间,“有意义”没有一个标准的定义,FMP的计算方法也很复杂。
- LCP(largest contentful Paint),最大内容渲染时间。
75、微前端
76、monorepo
为什么需要 monorepo?
因为仓库太多,本地开发需要频繁的切项目,分支模型和研发流程和CI流程都非常繁琐
monorepo 需要解决的问题:
1、React + Typescript + Jest + Webpack 这一系列技术栈,如何有效的使用 monorepo,采用了lerna,统一 tsconfig,统一 webpack 配置
2、分支模型、研发流程、CI流程如何简化
3、打包速度慢,缓存构建的问题,turborepo
77、es6 es5区别
1、let、const、模板字符串
2、函数和数组都扩展了一些API,比如箭头函数和Array.from这种
3、map、set
4、Generator
(async、await是es7的)78、变量防止外部修改的方案
1:ts的private(类内部)、 protected(类内部和子类内部) 、public(类内部和子类内部和new的变量)
class A {
private a = 1;
protected b = 1;
public c = 1;
}
class B extends A {
public fn() {
console.log(this.a) // Property 'a' is private and only accessible within class 'A'
console.log(this.b) // 1
console.log(this.c) // 1
}
}
var bInstance = new B();
console.log(bInstance.a) // Property 'a' is private and only accessible within class 'A'
console.log(bInstance.b) // Property 'b' is protected and only accessible within class 'A' and its subclasses
console.log(bInstance.c) // 12、es2022
class Foo {
#bar;
method() {
this.#bar; // Works
}
}
let foo = new Foo();
foo.#bar; // Invalid!
79、jssdk全埋点相关
1、全埋点是什么:指的是直接集成sdk,然后开启全埋点,sdk就能自动上报某些事件,比如页面浏览、元素点击、视区停留
2、全埋点实现原理:
页面浏览($pageview):每次打开页面发一次数据,单页面通过监控hashchange以及代理pushstate来实现。
元素点击($webclick):通过事件委托方式,监听document的点击,实现监控所有元素的点击监听。
视区停留($webstay):通过监听页面滚动及页面关闭时判断停留时间是否超过一定停留时间。
3、三个事件的属性有哪些 https://manual.sensorsdata.cn/sa/latest/web-js-sdk-100106527.html
$pageview包括域名(domain)、页面路径(path)
$webclick包括域名(domain)、页面路径(path)、节点信息(id、class、tagName、dataset、position位置)
$webstay包括域名(domain)、页面路径(path)、停留时间、视区宽度、视区高度、视区距离页面顶部的top值80、CDN是什么
CDN (Content Delivery Network)内容分发网络,举个现实例子,就是你要买东西,这个东西在北京,你在网上下了单,最初是要从北京发到你所在地,有了CDN之后,就是会在你所在地建立仓库,仓库里面有你要的东西,可以直接从仓库发给你,就更快,CDN其实就是类似的东西,在很多地方分布了缓存服务器,会根据你的位置来动态获取对应的资源。
CSS篇
http://www.w3school.com.cn/cssref/index.asp
行内元素:不可以设置宽高,但是可以和行内元素并排,span,img,input,select,button
块级元素:可以设置宽高,可以设置margin、padding,会单独排一行,div,p,h1,h2,ul,li,form,br
disabled和readonly有什么区别?
1、readonly只针对(input、textarea)有效,但是disabled可以在所有表单元素(select、radio、checkbox、button)里面生效
2、readonly在表单提交的时候,会把值提交出去,但是disabled不会将值提交出去
边框
1、圆角 border-radius
2、阴影 box-shadow 10px 10px 0px #333333 (阴影水平位移 垂直位移 模糊半径(清晰度) 阴影颜色)
3、border-image
背景
1、background-size: 100% 100%(相对于父元素的宽高,也可以写像素)
2、background-origin: content-box padding-box border-box(背景图片可以放置于 content-box、padding-box 或 border-box 区域)
3、background-clip: content-box padding-box border-box(背景图片可以放置于 content-box、padding-box 或 border-box 区域)
文字效果
1、text-overflow:ellipsis 溢出...
2、text-shadow: 5px 5px 5px #FF0000 (阴影水平位移 垂直位移 模糊半径(清晰度) 阴影颜色)
3、word-wrap:break-word; 长单词换行
盒子box-sizing
1、content-box,设置了宽高,padding和border是不占用宽高的
2、border-box,设置了宽高,padding和border是占用宽高的
width: auto 是该节点的content+border+padding+margin=父元素的content的宽度
width: 100% 是该节点的content=父元素的content的宽度
flex布局
父元素篇
1、主轴方向 flex-direction: row row-reverse column column-reverse
2、主轴换行 flex-wrap: wrap nowrap wrap-reverse
3、主轴的简写 flex-flow: row wrap (主轴对齐为row 主轴换行为wrap)
4、主轴对齐方式 justify-content: flex-start flex-end center space-between space-around (space-between: 与主轴两端对齐 space-around: 每个元素左右间隔一模一样)
5、每个子元素交叉轴对齐方式 align-items: flex-start flex-end center baseline stretch (baseline: 项目的第一行文字的基线对齐。 stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。)
6、子元素交叉轴多根轴线的对齐方式,如果只有一根轴线该元素不生效,flex-wrap必须为wrap,就是换行后多根轴线的对齐方式 align-content: flex-start flex-end center space-between space-around stretch
子元素篇(css弹性盒子-------桃园三兄弟之:flex-grow、flex-shrink、flex-basis详解_wxk_前端开发的博客-CSDN博客_flex-grow)
1、order 插队必备,数值小的在前面
2、flex-basis 项目占据的主轴空间,有flex-basis的时候,子元素设置width就不生效了,flex-basis会覆盖width
3、flex-grow 单个子元素放大比例,默认为0,当父元素的宽度没有被子元素占满的时候,就看每个子元素的flex-grow的值,大于0就按照比例去把父元素多余的宽度平分
4、flex-shrink 单个子元素缩小比例,默认为1,当父元素的宽度小于子元素的总宽度的时候,就看每个子元素的flex-shrink的值,flex-shrink如果不配置,默认为1的话,就会每个元素缩小的比例相同,如果有的子元素flex-shrink设置为0,那这个子元素就不缩小了
5、align-self 单个子元素与大局不一样的对齐方式 align-self: auto | flex-start | flex-end | center | baseline | stretch;
transform(CSS3属性transform详解 - 网站自由开发者 - 博客园)
X轴为电脑屏幕X轴,Y轴为电脑屏幕Y轴,Z轴为垂直于电脑屏幕的轴,就是正对着眼睛的轴
1、旋转 transform: rotate(45deg); 正数为顺时针旋转,负数为逆时针旋转 (3D旋转 rotateX() rotateY() rotateZ() )
2、缩放 transform: scale(0.5) scale(0.5, 2)
一个参数时:表示水平和垂直同时缩放该倍率
两个参数时:第一个参数指定水平方向的缩放倍率,第二个参数指定垂直方向的缩放倍率。
3、倾斜 transform:skew(30deg, 30deg) 第一个参数指定水平方向的倾斜角度,第二个参数指定垂直方向的倾斜角度。
4、位移 transform:translate(45px, 150px) 水平位移和垂直位移 (3D位移 translateX() translateY() translateZ())
5、基准点transform-origin: 10px 10px transform-origin: center center (为像素值时就是相对于左上角原点的位置,无该属性的时候,都是基于中心点为基准点)
过渡
css3 cubic-bezier用赛贝尔曲线定义速度曲线 - 梦珀 - 博客园
transition: width 2s linear 1s;
transition-property: width; /*过渡属性 width、background、transform属性,默认值为all*/
transition-duration: 2s; /*持续时间*/
transition-timing-function: linear; /*过渡类型 linear | ease | ease-in | ease-out | ease-in-out*/
transition-delay: 1s; /*过渡开始延时时间*/
| 值 | 描述 |
|---|---|
| linear | 规定以相同速度开始至结束的过渡效果(等于 cubic-bezier(0,0,1,1))。 |
| ease | 规定慢速开始,然后变快,然后慢速结束的过渡效果(cubic-bezier(0.25,0.1,0.25,1))。 |
| ease-in | 规定以慢速开始的过渡效果(等于 cubic-bezier(0.42,0,1,1))。 |
| ease-out | 规定以慢速结束的过渡效果(等于 cubic-bezier(0,0,0.58,1))。 |
| ease-in-out | 规定以慢速开始和结束的过渡效果(等于 cubic-bezier(0.42,0,0.58,1))。 |
| cubic-bezier(n,n,n,n) | 在 cubic-bezier 函数中定义自己的值。可能的值是 0 至 1 之间的数值。 |
动画
animation: move 5s linear infinite;
animation-name: move; /*名称*/
animation-duration: 5s; /*持续时间*/
animation-timing-function: linear; /*动画类型 linear | ease | ease-in | ease-out | ease-in-out*/
animation-iteration-count: infinite; /*循环次数*/
css优先级
!important > 行内样式>ID选择器 > 类选择器 = 伪类选择器 > 标签选择器 > 通配符 > 继承 > 浏览器默认属性
grid布局
父元素篇
1、display:grid
2、定义每一列的列宽 grid-template-columns: 100px 100px 100px || 33.33% 33.33% 33.33% || repeat(3, 33.33%) || repeat(192, 1fr)
3、定义每一行的行高 grid-template-rows: 100px 100px 100px || 33.33% 33.33% 33.33% || repeat(3, 33.33%) || repeat(108, 1fr)
4、间距 grid-row-gap: 20px 20px; grid-row-gap:20px; grid-column-gap:20px;
5、单元格内容水平位置对齐 justify-items: start | end | center | stretch;
6、单元格内容垂直位置对齐 align-items: start | end | center | stretch;
7、整个内容区域水平位置对齐 justify-content: start | end | center | stretch | space-around | space-between | space-evenly
8、整个内容区域垂直位置对齐 align-content: start | end | center | stretch | space-around | space-between | space-evenly
子元素篇
1、单元格区域 grid-area:1/1/3/3
React篇
1、react生命周期
ComponentWillMount 很少用到
render
ComponentDidMount 发ajax请求,可以setState
ComponentWillReceiveProps 刚接收到新的props,可以记录日志,可以setState,我们可以访问下一个 props (通过nextProps)和我们当前的 props (通过this.props)
shouldComponentUpdate 很少用到
ComponentWillUpdate 很少用到
render
ComponentDidUpdate 可以setState
ComponentWillUnmount
2、react ref属性
可以为input、textarea、select设置ref属性,可以获取到当前元素对应的值
React函数式组件使用Ref - JavaShuo
3、非受控组件和受控组件
非受控组件就是input、textarea、select这样的,然后react内部不获取维护他们的状态
受控组件就是在input、textarea、select的基础上,增加onChange事件,每次改变的时候调用setState更新state的值
4、redux流程理解
1、使用redux的createStore方法,创建reducer并传入到createStore里面中去,最后得到一个store
2、在组件中引入这个store,store.dispatch方法可以dispatch一个action,在reducer中接收到action后,就去处理,会得到一个新的state
3、store.subscribe()方法可以监测reducer中的值的变化,进而使用store.getState()方法获取reducer中的值
注:
1、reducer中的方法都是纯函数,就是不能修改state,需要使用深浅拷贝去返回新的state
2、store只能创建一个
3、一般使用react-redux库中的connect方法在组件中获取reducer的值,这个方法内部已经处理了一些性能优化,来避免不必要的重复渲染
react的生命周期中dispatch一个action,然后reducer接收到action之后,就改变reducer中的state,state改变,react组件中的数据也发生了改变
简易描述Redux的使用步骤 - 简书
5、react优化
shouldComponentUpdate能拿到下一个props和当前的props,通过设置规则,让react不需要每次都重新渲染
PureComponent替代Component,这个会自动提供一个shouldComponentUpdate方法,去做浅比较,比如引入会比较地址
多个相同类型的元素设置keys,能让react快速找到
react首次渲染的时候,没有真实dom快,这个问题,结合弹幕重构es6
6、react 事件合成系统 (React17事件机制 - 掘金)
React16:https://codesandbox.io/s/quirky-khayyam-cfe9r3
React17:https://codesandbox.io/s/aged-fire-r35epj
1、为什么React实现了自己的事件机制
将事件都代理到了根节点上,减少了事件监听器的创建,节省了内存。
磨平浏览器差异,开发者无需兼容多种浏览器写法。
对开发者友好。只需在对应的节点上编写如onClick、onClickCapture等代码即可完成click事件在该节点上冒泡节点、捕获阶段的监听,统一了写法。
2、React事件机制怎么实现的
17之前将所有事件委托在document节点上,17之后是委托在root节点上,然后通过将事件对应的数据都存在内存中的一个映射表中,真实的dom事件触发的时候就拿到对应的事件,然后生成合成事件执行。
3、17为什么 document => root?
做这个改动是为了应对如果一个页面上有多个子应用,他们都会在document节点上注册事件,如果在一个子应用中调用了stopPropagation,是没办法阻止事件冒泡到document上的,因为真实事件已经冒泡到document上了,这样可能会影响其他子应用。
4、17和16的事件合成机制上的区别?
在React16中,当真实事件冒泡到document之后触发绑定的回调函数,在回调函数中重新模拟一次 捕获-冒泡 的行为,所以React合成事件中的e.stopPropagation()无法阻止原生事件的捕获和冒泡,因为原生事件的捕获和冒泡已经执行完了。
即:原生事件document捕获 => 原生事件parent捕获 => 原生事件child捕获 => 原生事件child冒泡 => 原生事件parent冒泡 => 原生事件document冒泡 => 合成事件parent捕获 => 合成事件child捕获 => 合成事件child冒泡=> 合成事件parent冒泡
在React 17中,
当root接收到真实捕获事件时,先触发一次React合成事件的捕获阶段,然后再执行原生事件的捕获传播。所以React事件的捕获阶段调用e.stopPropagation()能阻止原生事件的传播。
当root接受到真实冒泡事件时,会触发一次React事件的冒泡阶段,此时原生事件的冒泡传播已经传播到根了,所以React事件的冒泡阶段调用e.stopPropagation()不能阻止原生事件向root的传播,但是能阻止root到document的传播
即:原生事件root捕获 => 合成事件parent捕获 => 合成事件child捕获 => 原生事件parent捕获 => 原生事件child捕获 => 原生事件child冒泡 => 原生事件parent冒泡 => 原生事件root冒泡 => 合成事件child冒泡 => 合成事件parent冒泡7、Ant Desigh Pro (DVA流程理解)
react做UI层,在react中dispatch一个请求,然后这个请求到model的effect中,在effect里面dva会用到es6的Generator,就是用yeild操作符把异步操作用来写成同步形式的
然后在effect中利用封装好的request.js去发请求,这个request.js是基于fetch的封装,然后获取到服务端的数据之后,调用reducer去做更新state,然后react做出相应变化
8、fetch和ajax的区别
ajax是用XmlHttpRequest来请求数据
fetch是window的一个对象,fetch方法返回的是一个promise
9、setState
1、setState 只在合成事件和钩子函数中是“异步”的,在原生事件和 setTimeout 中都是同步的。
2、setState的“异步”并不是说内部由异步代码实现,其实本身执行的过程和代码都是同步的,只是合成事件和钩子函数的调用顺序在更新之前,导致在合成事件和钩子函数中没法立马拿到更新后的值,形式了所谓的“异步”,当然可以通过第二个参数 setState(partialState, callback) 中的callback拿到更新后的结果。
3、setState 的批量更新优化也是建立在“异步”(合成事件、钩子函数)之上的,在原生事件和setTimeout 中不会批量更新,在“异步”中如果对同一个值进行多次 setState , setState 的批量更新策略会对其进行覆盖,取最后一次的执行,如果是同时 setState 多个不同的值,在更新时会对其进行合并批量更新。10、react16新特性
1、react hook 推荐不用class去写react组件
2、react fiber 原来的react如果有一个很复杂的组件,组件上层修改了state,那么会导致调用栈就会很长,从而会造成一些不好的体验,fiber就是解决这个问题的。fiber是一个虚拟的堆栈帧,调度器会按照优先级去调用这些帧,从而使原来的同步渲染变为异步渲染,在不影响的体验的情况下去做分段更新。
reconciliation 阶段是可以被打断的,所以 reconciliation 阶段会执行的生命周期函数就可能会出现调用多次的情况,从而引起 Bug11、函数式组件与类组件有何不同? (函数式组件与类组件有何不同? — Overreacted)
1、底层渲染不同,组件在渲染时会判组件类型,假设是class组件会先new一个实例,再通过实例.render()拿到node节点,而函数组件则是直接调用通过return得到渲染节点。
2、编码方式不同,class更多依赖生命周期钩子,而后者早期并没有state的概念,在引入hooks后更倾向于函数式编程。
3、有没有this的区别,对于this理解薄弱的同学而言,函数组件确实更清晰易懂。
react hooks的优点和缺点:
优点:
1、逻辑复用方便,可通过高阶函数,自定义hooks这些方式抽离公共逻辑
2、组件状态逻辑清晰
缺点:
1、存在闭包陷阱,必须标明deps依赖,写错会导致使用之前的值
2、不能在if等条件判断语句中使用hooks12、React Fiber(React技术揭秘)
先明确几个概念:
1、React 15之前只有 Reconciler(协调器, 负责找出变化的组件)、Render(渲染器,负责将变化的组件渲染到页面上),缺点是 Reconciler 采用递归的方式,如果组件树层级特别深,那么递归会占用线程太多时间,造成卡顿。(就是一帧的时间完成不了工作)
2、React 16之后,增加了一个 Scheduler(调度器,负责管理调用任务的优先级,可以插队,高优先级的任务可以插队进入Reconciler),React是实现了 requestIdleCallback 的 polyfill,实现了在空闲时触发回调的功能之外,还实现了调度任务按照优先级执行。
再明确几个问题:
1、为什么需要Fiber架构?
在React15及以前,Reconciler 采用递归的方式创建虚拟DOM,递归过程是不能中断的。如果组件树的层级很深,递归会占用线程很多时间,造成卡顿。
为了解决这个问题,React16将递归的无法中断的更新重构为异步的可中断更新,由于曾经用于递归的虚拟DOM数据结构已经无法满足需要。于是,全新的Fiber架构应运而生。
2、Fiber是什么?
fiber包含三层含义
第一层含义是架构上的区别,React15之前 Reconciler 是采用递归的方式,数据存储在递归调用栈中,所以又称为是 Stack Reconciler,React16 Reconciler 是基于 Fiber 节点来实现,被称为是 Fiber Reconciler。
第二层含义是作为静态数据结构来说,每个 Fiber 节点对应一个 React element,他保存了组件类型、对应的 dom 节点信息等
第三层含义是作为动态的工作单元来说,每个 Fiber 节点保存了本次更新中该组件改变的状态、要执行的工作(要被添加、被更新、被删除)
3、为什么Fiber能可中断的?
因为Fiber数据结构是链表,16之前的版本是树形结构{chidrens:[{childrens: []}]},采用递归处理,16之后是链表结构,可以随时中断,因为链表结构知道位置之后就可以知道下次如何进来
4、React是采用”双缓存“的方式来完成2棵 Fiber 树的替换的,即在内存中维护新老两棵树,新的树构建完成之后,就通过改变指针的指向,来完成切换
5、React 如何来比对2个 Fiber 树的?(diff算法)
有几个原则
第一个原则是只做同级比对,跨级比对会导致复杂度太高
第二个原则是如果节点的类型不一样,比如div => p,那么节点就销毁重建
第三个原则是key,可以设置key来标记,告诉react进行节点复用
总结就是:
逐层比对,先比对节点类型,再比对节点属性。key来标识告知react进行节点复用
6、单节点Diff和多节点Diff的区别?(https://react.iamkasong.com/diff/multi.html#%E6%A6%82%E8%A7%88)
单节点Diff就比较简单,就是做同级比对,类型不一样的就删除,一样的就比对属性,挨个往下
多节点Diff就主要用于List、Table场景,都带了key的,这里面也有很多种情况,就是要判断节点是否是新增、删除、更新、还有移动的,这个就需要遍历2次。
1)第一次遍历新节点,新的节点(newChildren[i])和老的节点(oldFiber)是否可以复用,可以的话就继续往下,i++,oldFiber = oldFiber.sibling。如果不能复用,就跳出循环。
2)此时有4种情况,分别是:
2.1) 新的节点已经遍历完+老的节点已经遍历完,这种情况,皆大欢喜
2.2) 新的节点已经遍历完+老的节点没有遍历完,这种情况,老的节点就是需要删除的
2.3) 新的节点没有遍历完+老的节点已经遍历完,这种情况,新的节点就是需要增加的
2.4)新的节点没有遍历完+老的节点没有遍历完,这种情况,需要判断是否移动
3)继续第二次遍历,先把老的节点(oldFibers)搞成一个Map,创建一个变量lastPlacedIndex(最后一个可复用的节点在oldFiber中的位置索引),然后遍历剩下的新的节点(newChildren[i]),获取新节点在老节点Map中的位置,如果没有,就是要删除,如果有,记录下老节点的位置(oldIndex),然后如果lastPlacedIndex>=oldIndex,这个节点是不需要移动的,然后lastPlacedIndex=oldIndex,如果lastPlacedIndex 13、React.Element React.Component JSX分别是什么
1、React.Element React.Component JSX分别是什么?
Element是React用来描述真实dom的一个数据结构。
Component是一个函数或者class,函数或者class的render返回的内容是React.Element。
JSX是一种语法吧,babel会将jsx编译成React.createElement(),当然新的React版本与babel合作改变了JSX的编译方式,实现了一个jsx-runtime,然后不将jsx编译成React.createElement()了。
2、ts类型中的ReactNode、ReactElement、JSX.Element的区别
ReactNode是很多的或关系(或者叫集合),ReactNode | string | undefined | null 等等
ReactElement 就是React用来描述真实dom的一个数据结构,由type和props组成
JSX 是一个全局的命名空间,不同的库对 JSX 都可以有自己不同的实现,JSX.Element 在 React 中是等效于 ReactElement 的
ReactNode:
type ReactText = string | number;
type ReactChild = ReactElement | ReactText;
interface ReactNodeArray extends Array {}
type ReactFragment = {} | ReactNodeArray;
type ReactNode = ReactChild | ReactFragment | ReactPortal | boolean | null | undefined;
ReactElement :
type Key = string | number
interface ReactElement = string | JSXElementConstructor> {
type: T;
props: P;
key: Key | null;
}
JSX.Element:
declare global {
namespace JSX {
interface Element extends React.ReactElement { }
}
}
14、React闭包陷阱
原因:
闭包陷阱产生的原因就是 useEffect 等 hook 里用到了某个 state,但是没有加到 deps 数组里,这样导致 state 变了却没有执行新传入的函数,依然引用的之前的 state。
解决方式一:
把 state 设置到 deps依赖项 里,并添加清理函数;闭包陷阱的解决也很简单,正确设置 deps 数组就可以了,这样每次用到的 state 变了就会执行新函数,引用新的 state。不过还要注意要清理下上次的定时器、事件监听器等。
解决方式二:
useRef;闭包陷阱产生的原因就是 useEffect 的函数里引用了某个 state,形成了闭包,那不直接引用不就行了?useRef 是在 memorizedState 链表中放一个对象,current 保存某个值。通过 useRef 保存回调函数,然后在 useEffect 里从 ref.current 来取函数再调用,避免了直接调用,也就没有闭包陷阱的问题了。
15、react.memo、useMemo、useCallback的使用场景memo()、useCallback()、useMemo()使用场景 - 掘金
React.memo:
在父组件state变化时,但是子组件的props没有变化,这时候父组件会重新渲染,如果用React.memo包裹子组件,子组件是不会渲染的
useCallback:
父组件传递一个函数给子组件调用,在父组件state变化时,父组件会重新生成这个函数,即函数的引用变化了,这时候子组件判断是props变化了,就会重新渲染,给这个函数包裹上useCallback,子组件就不会重新渲染了
useMemo:
和useCallback类似,只是把函数换成了对象
父组件传递一个对象数据给子组件,在父组件state变化时,父组件会重新生成这个对象,即对象的引用变化了,这时候子组件判断是props变化了,就会重新渲染,给这个对象包裹上useMemo,子组件就不会重新渲染了16、React useState和useEffect实现原理(见interview-code中的代码)
useState的实现原理:function useState(initialState)
首先会维护一个全局状态memorizeStates,这个是一个数组,还有一个index,这个index是不同的useState的存放顺序(第1个useState存放的index是0)。
初始化阶段会在memorizeStates中设置默认值,然后生成setState函数,同时setState函数也是会和index进行绑定的,然后就返回state和setState;
更新阶段会设置这个state的值,然后去触发渲染render,render之后需要把index还原为0
useEffect的实现原理:function useEffect(callback, deps)
首先会维护一个全局状态allDeps,这个是一个数组,还有一个index,这个index是不同的useEffect的存放顺序(第1个useEffect存放的index是0)。
初始化阶段(如果allDeps[index]为空),就会把deps添加到allDeps中,然后执行callback。
更新阶段(即allDeps[index]不为空),就会判断依赖是否变化,根据新传入的deps和缓存中的allDeps[index]进行对比,不同就会触发渲染render,render之后需要把index还原为017、React hooks useState、useEffect 为什么不能放在循环、条件语句或者嵌套函数中使用
[译] React Hooks: 没有魔法,只是数组 - 知乎
useState是用数组存储state的,如果有条件语句或者循环什么的,会导致顺序错乱,导致重复渲染的state读取顺序会乱,进而拿到的state也不对18、redux和flux的区别
1、flux可以多个store,redux只能一个store
2、flux是action => dispatch => store => view
redux是action => reducer => store => view19、useContext 能不能替代 redux
不能
1、useContext存在re-render问题
2、redux一般用于极其复杂的多组件交互的场景,useContext可以用于比较简单的一些数据共享,但是需要memo来配合使用
业务数据交互复杂度
低 => 中 => 高 => 极其高
useContext => recoil => mobx => redux
Recoil 的大致原理是这样的:
1、创建一个 atom 对象
2、使用 selector 的时候,会通过 get 来获取到依赖的 atom,生成一个 Map 映射关系
3、使用 useRecoilState Hook 的时候,会将当前 atom/selector 和组件的 forceUpdate 方法进行映射
4、当对状态进行修改的时候,会从映射关系里面取出来对应的组件 forceUpdate 方法,进行精准更新
20、useContext 如何优化re-render
1、需要共享多个数据(比如一个大对象时),尽量是拆分成多个 context,这样某一个context value变化时,只会是使用到这个 context 的组件re-render
2、配合 memo 一起使用,可以防止没有使用到的子组件不会re-render
// context.ts
import { createContext } from 'react';
export default createContext('default');
// context2.ts
import { createContext } from 'react';
export default createContext([1, 2, 3]);
// app.tsx
import './App.css';
import CustomContext1 from './context';
import CustomContext2 from './context2';
import B from './B';
import A from './A';
import { useState } from 'react';
function App() {
const [data1, setData1] = useState([1, 2, 3]);
const [name, setName] = useState('wzl');
return (
);
}
export default App;
// A.tsx
import React, { memo, useContext } from 'react';
import CustomContext2 from './context2';
const A = (props: any) => {
console.log('A re-render use data1');
const obj = useContext(CustomContext2);
return (
A{obj.join(',')}
);
};
export default memo(A);
// B.tsx
import React, { memo, useContext } from 'react';
import CustomContext from './context';
const B = (props: any) => {
console.log('B re-render use name');
const obj = useContext(CustomContext);
return (
B
{obj}
{/* {obj.data.join(',')} */}
);
};
export default memo(B);
21、useRef、forwardRef、useImperativeHandle
1、useRef返回一个ref对象,返回的ref对象在组件的整个生命周期保持不变
主要用于两个场景,ref 获取dom对象,ref保存某个数据
2、forwardRef是将父组件的ref传递给子组件,然后子组件将这个ref绑定到自己的某个对象上,这样父组件就能拿到子组件的某个对象
3、useImperativeHandle就是用来定义子组件给父组件暴露哪些属性或函数的api
forwardRef((props: ICarouselProps, ref) => {
const divRef = useRef();
useImperativeHandle(ref, () => {
return {
variable: 1,
focus: () => {
divRef.current.focus();
}
}
})
return 22、React.Fragment和<>区别
React.Fragment可以用key,<>不能
23、React 自定义组件为什么必须用大写?
因为babel编译的时候,需要识别哪些是自定义组件,哪些是原生组件,比如div是原生是小写,
SelfComponent是自定义组件是大写
Vue篇
vue面试总结 - SegmentFault 思否
1.什么是vue生命周期?
答: Vue 实例从创建到销毁的过程,就是生命周期。也就是从开始创建、初始化数据、编译模板、挂载Dom→渲染、更新→渲染、卸载等一系列过程,我们称这是 Vue 的生命周期。
它的生命周期中有多个事件钩子,让我们在控制整个Vue实例的过程时更容易形成好的逻辑。
2.Vue生命周期总共有几个阶段?
它可以总共分为8个阶段:创建前/后, 载入前/后,更新前/后,销毁前/销毁后。
创建前/后: 在beforeCreated阶段,vue实例的挂载元素$el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象data有了,$el还没有。
载入前/后:在beforeMount阶段,vue实例的$el和data都初始化了,但还是挂载之前为虚拟的dom节点,data.message还未替换。在mounted阶段,vue实例挂载完成,data.message成功渲染。
更新前/后:当data变化时,会触发beforeUpdate和updated方法。
销毁前/后:在执行destroy方法后,对data的改变不会再触发周期函数,说明此时vue实例已经解除了事件监听以及和dom的绑定,但是dom结构依然存在。
beforeCreate $el和data都没有
created data有了 $el没有
beforeMount data有了 $el没有
mounted data有了 $el有了
beforeUpdate
updated
beforeDestory
destoryed data没了 $el没了父子顺序:
父beforeCreate -> 父created -> 父beforeMount -> 子beforeCreate -> 子created -> 子beforeMount -> 子mounted -> 父mounted->父beforeUpdate->子beforeUpdate->子updated->父updated->父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
3.第一次页面加载会触发哪几个钩子?
答:第一次页面加载时会触发 beforeCreate, created, beforeMount, mounted 这几个钩子
4.Vue的双向数据绑定原理是什么?
答:vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。Object.defineProperty不支持IE8,而且不能监听数组,Vue内部是重写的数组的方法
具体步骤:
第一步:需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter和getter
这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
第二步:compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
第三步:Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是:
1、在自身实例化时往属性订阅器(dep)里面添加自己
2、自身必须有一个update()方法
3、待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
第四步:MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
5.axios的特点有哪些?
答:
一、Axios 是一个基于 promise 的 HTTP 库,支持promise所有的API
二、它可以拦截请求和响应
三、它可以转换请求数据和响应数据,并对响应回来的内容自动转换成 JSON类型的数据
四、安全性更高,客户端支持防御 XSRF
6.对于MVVM的理解?
MVVM 是 Model-View-ViewModel 的缩写。
Model代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑。
View 代表UI 组件,它负责将数据模型转化成UI 展现出来。
ViewModel 监听模型数据的改变和控制视图行为、处理用户交互,简单理解就是一个同步View 和 Model的对象,连接Model和View。
在MVVM架构下,View 和 Model 之间并没有直接的联系,而是通过ViewModel进行交互,Model 和 ViewModel 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上。
ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理。
7.Vue组件间的参数传递
1.父组件与子组件传值
父组件传给子组件:子组件通过props方法接受数据;
子组件传给父组件:$emit方法传递参数
2.非父子组件间的数据传递,兄弟组件传值
eventBus,就是创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。项目比较小时,用这个比较合适。(虽然也有不少人推荐直接用VUEX,具体来说看需求咯。技术只是手段,目的达到才是王道。)
8.Vue的路由实现:hash模式 和 history模式
hash模式:在浏览器中符号“#”,#以及#后面的字符称之为hash,用window.location.hash读取;
特点:hash虽然在URL中,但不被包括在HTTP请求中;用来指导浏览器动作,对服务端安全无用,hash不会重加载页面。
hash 模式下,仅 hash 符号之前的内容会被包含在请求中,如 http://www.xxx.com,因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回 404 错误。
history模式:history采用HTML5的新特性;且提供了两个新方法:pushState(),replaceState()可以对浏览器历史记录栈进行修改,以及popState事件的监听到状态变更。
history 模式下,前端的 URL 必须和实际向后端发起请求的 URL 一致,如 http://www.xxx.com/items/id。后端如果缺少对 /items/id 的路由处理,将返回 404 错误。Vue-Router 官网里如此描述:“不过这种模式要玩好,还需要后台配置支持……所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。”
9.Vue与Angular以及React的区别?
(版本在不断更新,以下的区别有可能不是很正确。我工作中只用到vue,对angular和react不怎么熟)
1.与AngularJS的区别
相同点:
都支持指令:内置指令和自定义指令;都支持过滤器:内置过滤器和自定义过滤器;都支持双向数据绑定;都不支持低端浏览器。
不同点:
AngularJS的学习成本高,比如增加了Dependency Injection特性,而Vue.js本身提供的API都比较简单、直观;在性能上,AngularJS依赖对数据做脏检查,所以Watcher越多越慢;Vue.js使用基于依赖追踪的观察并且使用异步队列更新,所有的数据都是独立触发的。
2.与React的区别
相同点:
React采用特殊的JSX语法,Vue.js在组件开发中也推崇编写.vue特殊文件格式,对文件内容都有一些约定,两者都需要编译后使用;中心思想相同:一切都是组件,组件实例之间可以嵌套;都提供合理的钩子函数,可以让开发者定制化地去处理需求;都不内置列数AJAX,Route等功能到核心包,而是以插件的方式加载;在组件开发中都支持mixins的特性。
不同点:
React采用的Virtual DOM会对渲染出来的结果做脏检查;Vue.js在模板中提供了指令,过滤器等,可以非常方便,快捷地操作Virtual DOM。
10.vue路由的钩子函数
首页可以控制导航跳转,beforeEach,afterEach等,一般用于页面title的修改。一些需要登录才能调整页面的重定向功能。
beforeEach主要有3个参数to,from,next:
to:route即将进入的目标路由对象,
from:route当前导航正要离开的路由
next:function一定要调用该方法resolve这个钩子。执行效果依赖next方法的调用参数。可以控制网页的跳转。
11.vuex是什么?怎么使用?哪种功能场景使用它?
只用来读取的状态集中放在store中; 改变状态的方式是提交mutations,这是个同步的事物; 异步逻辑应该封装在action中。
在main.js引入store,注入。新建了一个目录store,….. export 。
场景有:单页应用中,组件之间的状态、音乐播放、登录状态、加入购物车
state
Vuex 使用单一状态树,即每个应用将仅仅包含一个store 实例,但单一状态树和模块化并不冲突。存放的数据状态,不可以直接修改里面的数据。
mutations
mutations定义的方法动态修改Vuex 的 store 中的状态或数据。
getters
类似vue的计算属性,主要用来过滤一些数据。
action
actions可以理解为通过将mutations里面处里数据的方法变成可异步的处理数据的方法,简单的说就是异步操作数据。view 层通过 store.dispath 来分发 action。
modules
项目特别复杂的时候,可以让每一个模块拥有自己的state、mutation、action、getters,使得结构非常清晰,方便管理。
12.vue中 key 值的作用?
答:当 Vue.js 用 v-for 正在更新已渲染过的元素列表时,它默认用“就地复用”策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序, 而是简单复用此处每个元素,并且确保它在特定索引下显示已被渲染过的每个元素。key的作用主要是为了高效的更新虚拟DOM。
13.$route和$router的区别
答:$route是“路由信息对象”,包括path,params,hash,query,fullPath,matched,name等路由信息参数。而$router是“路由实例”对象包括了路由的跳转方法,钩子函数等。
14.什么是vue的计算属性?
答:在模板中放入太多的逻辑会让模板过重且难以维护,在需要对数据进行复杂处理,且可能多次使用的情况下,尽量采取计算属性的方式。
好处:
①使得数据处理结构清晰;
②依赖于数据,数据更新,处理结果自动更新;
③计算属性内部this指向vm实例;
④在template调用时,直接写计算属性名即可;
⑤常用的是getter方法,获取数据,也可以使用set方法改变数据;
⑥相较于methods,不管依赖的数据变不变,methods都会重新计算,但是依赖数据不变的时候computed从缓存中获取,不会重新计算。
15.什么是MVC?
MVC允许在不改变视图的情况下改变视图对用户输入的响应方式,用户把对View的操作交给了Controller处理,在Controller中响应View的事件调用Model的接口对数据进行操作,一旦Model发生变化便通知相关视图进行更新。
如果前端没有框架,只使用原生的html+js,MVC模式可以这样理解。将html看成view;js看成controller,负责处理用户与应用的交互,响应对view的操作(对事件的监听),调用Model对数据进行操作,完成model与view的同步(根据model的改变,通过选择器对view进行操作);将js的ajax当做Model,也就是数据层,通过ajax从服务器获取数据。
16.MVVM与MVC区别?
MVVM与MVC两者之间最大的区别就是:MVVM实现了对View和Model的自动同步,也就是当Model的属性改变时,我们不用再自己手动操作Dom元素来改变View的变化,而是改变其属性后,该属性对应的View层数据会自动改变。
以Vue为例:
{{ title }}
var vueDemo = new Vue({
el: '#vueDemo',
data: {
title: 'Hello Vue!'
},
methods: {
clickEvent: function () {
this.title = "hello word!"
}
}
})复制代码这里的html => View层,可以看到这里的View通过模板语法来声明式的将数据渲染进DOM元素,当ViewModel对Model进行更新时,通过数据绑定更新到View。
Vue实例中的data相当于Model层,而ViewModel层的核心是Vue中的双向数据绑定,当Model发生变化时View也可以跟着实时更新,同理,View变化也能让Model发生变化。
总的看来,MVVM比MVC精简很多,不仅简化了业务与界面的依赖,还解决了数据频繁更新的问题,不用再用选择器操作DOM元素。因为在MVVM中,View不知道Model的存在,Model和ViewModel也观察不到View,这种低耦合模式提高代码的可重用性。
17、Vue虚拟dom和diff算法VirtualDOM与diff(Vue实现)_染陌的博客-CSDN博客
18、slot-scope 作用域插槽,可以拿到数据,然后在slot中使用数据
19、keep-alive内置组件
keep-alive内置组件是vue的一个内置组件,通常做组件切换的时候,如果我们想要将不活跃的组件保留他内部的状态和数据,就需要使用它,它内部实现原理就是,组件不活跃不会将组件销毁,而是将组件保存在内存当中。它提供了3个参数,include(字符串或正则)表示名称匹配的组件会被缓存,exclude(字符串或正则)表示名称匹配的组件不会被缓存,max表示最多缓存多少个组件
20、vue-loader为什么要配合VueLoaderPlugin一起使用,VueLoaderPlugin是干了什么?
VueLoaderPlugin的作用是将你定义过的其它规则复制并应用到 .vue 文件里相应语言的块,比如对.js定义的规则,会应用到.vue文件中的script,对.css定义的规则,会应用到.vue文件中的style
21、vue data为什么是函数
因为如果data是一个对象,对象是引用类型,那复用的所有组件实例都会共享这些数据,就会导致修改一个组件实例上的数据,其他复用该组件的实例上对应的数据也会被修改,
如果data是一个函数,函数虽然也是引用类型,但是函数是有作用域的,函数内的变量不能被外部访问到,这样每个组件实例都会有个独立的拷贝同时又因为函数作用域的限制修改自己的数据时其他组件实例的数据是不会受到影响的
总结:
对象是引用类型,且没有作用域,会导致一改全改;
函数是引用类型,但它有作用域,不会彼此受牵连。
虚拟DOM和DIFF算法
树的递归:
1、新的节点的tagName和key与旧的节点不同,这种情况就要替换旧的节点,并且都不需要去遍历子节点了
2、新的节点的tagName和key与旧的节点相同,则去遍历子节点
判断属性的更改:
1、遍历旧的属性列表,判断是否在新的属性列表中,如果不在,就记录下来要删除
2、遍历新的属性列表,判断新的属性是否存在于旧的属性列表中,不存在就要记录下来增加这个属性,存在就再判断新的属性值和旧的值是否相同,不同就记录下来要修改
列表的差异算法:
1、遍历旧的列表,判断是否在新的列表中,如果不在,就记录下来要删除
2、遍历新的列表,判断是否在旧的列表中,如果不在,就记录下来要增加,同时也要判断节点是否有移动
webpack篇
1、代码分离 CommonsChunkPlugin CommonsChunkPlugin | webpack 中文文档
webpack中ensure方法和CommonsChunkPlugin中的children选项-秋天爱美丽-专业的技术网站(关于CommonsChunkPlugin的children和ensure选项)
2、代码分离 SplitChunksPlugin webpack4——SplitChunksPlugin使用指南_xhsdnn的博客-CSDN博客_splitchunksplugin
3、webpack优化有哪些
打包的bundle如何更小
1、splitChunk代码分离,将公共模块提取出来
2、利用 DllPlugin 和 DllReferencePlugin 预编译资源模块
3、externals配置常用库
4、css提取插件提取css,css压缩插件
5、js压缩插件
6、用bundle分析工具分析bundle,之前我搭建过一个react脚手架,开发环境用到了mockjs,然后我在生产环境打包时候发现包增大了很多,然后就发现我在代码里面是直接引用了mockjs,然后用bundle分析工具分析后,想到一个办法,就是在开发环境中的entry增加mock.js,这样在开发环境中就可以直接引用mock.js,在生产环境中不用引用mock.js,减少了mock.js的包
7、图片压缩插件
打包如何更快
1、happyPack和Thread-loader开启多进程打包,发挥多核CPU的作用
2、开启缓存,babel-loader缓存、terser-webpack-plugin开启缓存
3、speed-measure-webpack-plugin插件分析速度4、Webpack是一个插件的架构,他的内部实现是由很多个插件组成,他的插件系统的核心是一个叫tapable的库,这个东西提供了注册插件和调用插件的功能,然后每个插件都有一个apply方法,在这个apply方法里可以给在webpack的每一个生命周期里注册回调方法,从而实现不同功能
5、webpack打包一定比ES5写的代码的大吗
非模块化文件打包 · webpack指南
不一定,比如如果只有一行代码,webpack也会将一些runtime的代码写入。
runtime的代码包括webpack内部实现的一个__webpack_require__方法,
还有如果是打包的umd格式的文件,会判断是否AMD或者commonjs格式,然后对应去加载不同格式的模块6、css文件处理,先经过css-loader将@import和url这种外部资源处理为require,再经过style-loader将CSS代码插入到dom中
7、plugin是一个具有apply方法的对象,他可以在webpack编译流程中处理很多东西,loader是将非js模块处理为js模块,loader就像是一个管道,一个字符串进,一个字符串出
8、module是开发的时候的一个模块,比如export一个模块,chunk就是由多个module组成的块,比如entry chunk,bundle是由多个chunk组成的,打包出来的最终文件
9、tree-shaking是将没有被import的export干掉,然后由uglify去把多余的代码删除,比如:
export function A() {
console.log(111)
}
这个时候没有去import {A} from 'xxx'
tree-shaking就会去把export干掉,然后uglify会把function A(){ console.log(111) }干掉
另外CommonJS规范不能用tree-shaking,因为他是加载的时候运行的,有些插件宣称可以对CommonJS进行tree-shaking,但是也会有一些限制(webpack-common-shake插件)
10、多页面打包就用多个entry,多个HtmlWebpackPlugin
11、webpack热更新流程
首先webpack-dev-sever会启动一个node服务,然后每次有文件变化的时候webpack会重新编译
,编译完会通过websocket跟浏览器进行交互,通知浏览器文件产生变化了,然后浏览器就进行刷新了
详细步骤:
1、服务端和客户端通过websocket通信
2、webpack监听文件变化会触发重新编译,编译完成会有hash和文件的变更,服务端通过websocket通知客户端
3、客户端通过hash值请求服务端拿到一个mainfest文件
4、客户端根据mainfest文件获取新的js模块的代码
5、拿到新的js模块的代码之后,会更新module trees
6、调用之前通过module.hot.accept注册好的回调12、webpack编译构建的流程
1、准备阶段,webpack会合并很多自定义的配置和默认配置,创建compiler和compilation对象
2、编译阶段,webpack会解析项目依赖的所有modules,然后根据modules生成chunk
2.1) 依赖收集是通过在解析一个module之后,会递归调用他依赖的module去进行解析,是使用parser(acorn)进行的。这种递归是属于深度优先
2.2) 使用loader-runner去处理非JS模块。然后解析完所有的module之后,就会开始生成chunk。
2.3) chunk的生成规则
1、webpack会将entry配置的module生成新的chunk
2、然后会遍历这些module依赖的module,将这个module会依次加入对应的chunk,如果是共用的module不做splitChunk的配置的话,这个共用的module会被打到多个chunk里头去,有重复的出现,如果设置了splitChunk就作为公共chunk单独生成
3、如果一个module是动态引入的module(比如require.ensure、动态import),webpack会创建一个新的chunk,然后再将依赖加入的chunk中
3、文件生成阶段,webpack会根据chunk生成最终的bundle文件,这个过程会有hash的更新,还有就是一些文件操作13、webpack和gulp/grunt的区别
gulp/grunt是一种工具,为了优化前端工作流程,可以用来压缩js、css,编译less等等,他们的过程就是遍历文件去匹配一个一个的规则,就进行打包了
webpack它是一个预编译的模块化的解决方案,在webpack中其实也可以使用插件系统来调用gulp的功能做一些事情,webpack会分析依赖关系,然后做到很多新的优化,比如code split,路由懒加载等等14、webpack的scope hoisting
1、一个模块依赖另外一个模块,没有scope hoisting的话,是会有2个闭包的小模块,但是有scope hoisting之后,webpack就会把被依赖的模块打包到主模块里去
假如现在有两个文件分别是
util.js:
export default 'Hello,Webpack';
main.js:
import str from './util.js';
console.log(str);
没有scope hoisting的话,打包是这样的:
[
(function (module, __webpack_exports__, __webpack_require__) {
var __WEBPACK_IMPORTED_MODULE_0__util_js__ = __webpack_require__(1);
console.log(__WEBPACK_IMPORTED_MODULE_0__util_js__["a"]);
}),
(function (module, __webpack_exports__, __webpack_require__) {
__webpack_exports__["a"] = ('Hello,Webpack');
})
]
有scope hoisting的话,打包是这样的:
[
(function (module, __webpack_exports__, __webpack_require__) {
var util = ('Hello,Webpack');
console.log(util);
})
]
这样的好处是:
1、代码体积变小
2、代码在运行时,函数作用域变少,内存开销也变少了
2、开启scope hoisting的方式:
webpack有一个插件叫做ModuleConcatenationPlugin,这个插件是内置的
3、webpack必须要es6模块化才会使用scope hoisting,因为要做模块之间的依赖分析,如果是非es6模块化,就不会做scope hoisting15、webpack的相关loader
1、css-loader主要职责是将css中的@import和url都转成require,css-loader 返回的其实不是css的内容,而是一个对象,只不过这个对象的 toString() 方法会直接返回css的样式内容
2、style-loader主要职责是将css插入到header中,他首先会通过require来获取css文件内容,得到一个字符串,然后再将这个插入的header中,style-loader是一个pitch-loader
3、file-loader主要职责是复制图片到指定目录,他会根据配置来调用webpack提供的方法将图片复制到指定目录,他返回的是一个新的图片路径
4、url-loader主要职责是将小于limit限制的图片转为base64进行返回,大于limit限制的图片调用file-loader进行处理,小图返回的是base64编码后的字符串16、webpack的 compiler 和 compilation 区别
1、compiler 是 webpack(config) 返回的一个实例对象,在 webpack 构建之初就已经创建,并且贯穿webpack整个生命周期 ( before - run - beforeCompiler - complie - make - finishMake - afterComplier - done)
2、compilation是到准备编译模块时,才会创建compilation对象,是 compile - make 阶段主要使用的对象
3、为什么需要compilation
在使用watch,源代码发生改变的时候就需要重新编译模块,但是compiler可以继续使用。
如果使用compiler则需要初始化注册所有plugin,但是plugin没必要重新注册
这时候就需要创建一个新的compilation对象
而只有修改新的webpack配置才需要重新运行 npm run build 来重新生成 compiler对象
4、可以这么理解,compiler是整个webpack生命周期的对象,compilation是一次构建会生成一个,一次构建指的是收集依赖、生成chunk、生成bundle17、webpack module federation
module federation 是指webpack提供了一种机制,可以让模块在不同应用直接共享,原来只有dll,但是没办法跨应用,现在提供了module federation,可以remotes使用其他应用的模块,也可以指定自己这个应用可以被其他应用使用哪些模块(exposes)
NodeJS篇
1、什么是中间件
中间件就是接到请求到返回数据这中间的执行的一系列函数,就叫做中间件,一般有一些日志记录啊,拦截器处理呀等等
ts篇
1、any、unknow、nerver和void
ts中any和unknown的区别 - 掘金
any、unknown、never、void 区别 - 掘金
any 与 unknown 的区别: never 与 void 的区别:用于函数时, |
2、ts常用高级方法(keyof、pick、record、partial、required、exclude、omi……)
https://github.com/beichensky/Blog/issues/12
3、type 和 interface 的区别
相同点:
type和interface 都能实现继承
不同点:
1、type 可以别名基本类型,但是interface不行,interface只能声明 Object,type基本类型和Object都可以别名
2、type是别名,interface是类型声明
3、type不能被修改,interface可以声明合并,对外的ts可以用interface来写,方便别人扩展
type 与 interface 的区别_左边@右边的博客-CSDN博客_interface和type区别
4、///
/// TypeScript学习(五)三斜线指令 - 走看看
5、enum什么时候用
1、在状态码(0、1、2)对应选项(成功、失败、pending)的时候用,状态码是数字
2、permission权限,配合位运算一起用
6、类型收窄有什么方式(Ts 类型收窄的应用场景分析_咱们得站着的博客-CSDN博客)
type Rect = {
height: number;
width: number;
};
type Circle = {
center: [number, number];
radius: number;
};
1、typeof、instanceof,但是这些都比较有限
2、in 操作符(不适用函数)
function getType(a: Circle|Square) {
if ('center' in a) {
console.log('Circle')
}
if ('height' in a) {
console.log('Square')
}
}
3、is(比较万能)
function isRect(x: Rect | Circle): x is Rect {
return 'width' in x && 'height' in x;
}
function getType(x: Rect | Circle) {
if (isRect(x)) {
console.log(x.width);
}
}
4、可辨别联合,给类型加个key,这种就能区分了
type Rect = {
key: 'Rect';
height: number;
width: number;
};
type Circle = {
key: 'Circle';
center: [number, number];
radius: number;
};7、as const有什么作用
// 加 as const 了之后,下面的Math.atan2才不报错
// 加了之后是让 ts 给这个变量推断出尽量收窄的类型,加了之后类型是[8,5],不加类型是number[]
// 而 Math.atan2 函数只接受 2 个参数,所以如果是number[]就报错了,加了as const为[8,5]就不报错
const arr = [8,5] as const;
const angle = Math.atan2(...args);
8、typeof、keyof、in
type functionT = () => { a: number }
// typeof 后面只能跟具体的值,不能跟类型
type test1 = typeof { name: string; age: number }; // 报错
type test2 = typeof functionT; // 报错
type test3 = typeof '1'; // number,实际会缩小到 1
// keyof
type test4 = keyof { name: string; age: number }; // 'name' | 'age'
type test5 = keyof functionT; // never
// in
'name' in { name: string; age: number } // true
type aaaaaaa = {
[p in keyof { name: string; age: number }]: { name: string; age: number }[p]
}9、babel和tsc编译 .ts 的区别(掘金小册)
1、tsc支持最新的es标准和很少一部分草案的特性(没有进入es标准的草案,比如装饰器),babel是支持最新的es标准(@babel/preset-env)和很多草案的特性(@babel/proposal-xxx),在这方面babel做的更全面一些
2、做polyfill方面,tsc没有做polyfill,需要自己在入口处全量引入core-js,@babel/preset-env是通过targets和useBuiltIns配置进行core-js的按需引入
3、tsc做类型检查,babel不做类型检查
4、babel不支持一部分的ts语法,如 const enum10、协变、逆变、双向协变(Ts高手篇:22个示例深入讲解Ts最晦涩难懂的高级类型工具 - 掘金)
简单说就是,具有父子关系的多个类型,在通过某种构造关系构造成的新的类型,如果还具有父子关系则是协变的,而关系逆转了(子变父,父变子)就是逆变的。可能听起来有些抽象,下面我们将用更具体的例子进行演示说明。双向协变是可以双向赋值,但是这种是不安全的,ts支持双向协变,通过修改tsconfig的strictFunctionType来进行开关。
interface Parent {
name: string;
}
interface Child extends Parent {
age: number;
}
let parent: Parent;
let child: Child;
parent = child; // 可以执行
child = parent; // 报错
上面原因:Child 是 Parent 的子类型,子类型的属性限制多一些,父类型的限制少,所以子可以赋值给父,但是父不能赋值给子
协变:
type ArrayParent = Array;
type ArrayChild = Array;
let parent: ArrayParent;
let child: ArrayChild;
parent = child; // 可以执行
child = parent; // 报错
上面数组的构造,对于父子类型的赋值逻辑还是不变的,这种情况就叫做协变。
逆变:
type FunctionParent = (parent: Parent) => void;
type FunctionChild = (parent: Child) => void;
let parent: FunctionParent;
let child: FunctionChild;
parent = child; // 报错,这里反过来是因为 FunctionChild 的约束紧密一些,在调用parent({name: 111})的时候,会少参数,所以不能这样赋值
child = parent; // 反过来是可以执行
上面函数的构造,对于父子类型的赋值逻辑还是反向变化的,这种情况就叫做逆变。
双向协变:
是指可以双向赋值,但是这样不安全,tsconfig中的strictFunctionTypes来进行开关
路由篇
1、分为hash模式和history模式,核心原理是监听url变化,然后跳转到对应不同的界面
2、hash模式原理是hashChange监听url变化,然后对应跳转到不同的界面,不会导致页面刷新。
3、history模式原理是H5的history.pushState()和history.replaceState()方法在历史记录中添加一条新的URL,然后通过popState事件监听变化,进而跳转到不同界面,不会导致页面刷新
面试问题:
1.js地址 函数参数传递分为值传递和引用传递 object和基础数据类型 https://www.cnblogs.com/chenwenhao/p/7009606.html
2.JavaScript中判断函数是new还是()调用的
https://m.jb51.net/article/26768.htm
3.怎么看这个请求是跨域的,header上有啥特殊的
4.实现map 参数要注意,还有要注意
https://m.runoob.com/jsref/jsref-map.html
https://segmentfault.com/q/1010000018371206
5.深浅拷贝 assign
6.栈 {{}}遇到{ push 遇到}pop
7.rematch
8.fastclick
9.方法实现一个判断是什么数据类型的
10.webpack如何让构建的更快
11.301 302 303 304 401 402 403
12.import和require底层实现 commonjs和esmodule
4、for of循环
一个数据结构只要部署了Symbol.iterator属性,就被视为具有 iterator 接口,就可以用for...of循环遍历它的成员。也就是说,for...of循环内部调用的是数据结构的Symbol.iterator方法
for...of循环可以使用的范围包括数组、Set 和 Map 结构、某些类似数组的对象(比如arguments对象、DOM NodeList 对象)、后文的 Generator 对象,以及字符串
var arr = ['a', 'b', 'c', 'd'];
for (let a of arr) {
console.log(a); // a b c d
}
var engines = new Set(["Gecko", "Trident", "Webkit", "Webkit"]);
for (var e of engines) {
console.log(e);
}
// Gecko
// Trident
// Webkit
var es6 = new Map();
es6.set("edition", 6);
es6.set("committee", "TC39");
es6.set("standard", "ECMA-262");
for (var [name, value] of es6) {
console.log(name + ": " + value);
}
let es6 = {
edition: 6,
committee: "TC39",
standard: "ECMA-262"
}
for (let e of es6) {
console.log(e);
}for in 循环可以循环一个对象的原型链的属性,Object.keys就拿不到原型链里的属性
for in 通过hasOwnProperty可以判断是否是自己的属性,而不是原型链的属性
5、vue虚拟dom和diff算法,虚拟dom在哪个阶段创建,哪个阶段销毁,怎么去比较的
6、体现深度广度和性能优化的经历,有什么工具去做性能优化
7、闭包为什么可以访问内部变量,进而垃圾回收机制
https://www.jianshu.com/p/702f5bcb57e1
8、H5的android和ios兼容性问题
9、token被拿到了还在有效期怎么防止
10、react的setState怎么合并的
11、https的坏处
12、webpack的模块复用、tree-shaking
13、webpack打包一定比ES5写的代码的大吗
不一定,比如如果只有一行代码,webpack也会将一些runtime的代码写入。
runtime的代码包括webpack内部实现的一个__webpack_require__方法,还有如果是打包的umd格式的文件,会判断是否AMD或者commonjs格式,然后对应去加载不同格式的模块
非模块化文件打包 · webpack指南
14、块级作用域和全局作用域
15、技术深度
16、BASE64编码会大多少 (base64原理浅析)
大1/3,就是原来的4/3倍,因为使用6位的BASE64编码去表达原来的8位的ASCII码,需要4个BASE64编码才能有3个ASCII码相同的位数,然后这样就大了1/3
17、基于视频区的W3C弹幕规范(https://w3c-proposal-incubation.github.io/danmaku-proposal/)
18、性能优化
19、localstorage最大每个域5M,超出了之后浏览器会怎么办?
不存储数据, 也不会覆盖现有数据。引发 QUOTA_EXCEEDED_ERR 异常。
20、运营商劫持(防止运营商劫持,前端解决办法 - 简书)(干货!防运营商劫持 - 掘金)(防止运营商劫持,前端解决办法 - 简书)(http://bigsec.com/bigsec-news/wechat-16824-yunyingshangjiechi)
DNS劫持:把你重定向到其它网站
HTTP劫持:使用HTTP请求一个网站页面的时候,网络运营商会在正常的数据流中,插入精心设计的网络数据报文,
让客户端(浏览器)展示“错误”的数据,通常是一些弹窗,宣传性广告或者直接显示某个网站的内容
解决办法:
1、设置HTTPS,HTTPS的话就被劫持的可能性低了很多,因为HTTPS是加密
2、CSP,设置Meta头,设置白名单,将不是白名单里面的脚本全部remove掉
可以进行投诉,到运营商那投诉,实在不行到工信部投诉21、怎么取消dom的点击事件
Document
asd
22、TCP连接怎么判断关闭
23、为什么要有OPTION请求
24、前端页面报错监控的经验
25、正则表达式实现trim()
26、HTTP3.0
1、事件循环里有几个宏任务队列
6个
2、webpack5 新特性
缓存,模块联邦,移除了nodejs的polyfill,tree-shaking升级
3、前端基建
UI 组件库、业务组件库、monorepo、分支模型、CICD、前端规范(代码规范、接口规范、代码提交规范、组件版本发布规范semver)、异常监控、单测、主题换肤
4、antd 的按需加载原理 babel-plugin-import
babel-plugin-import的作用就是将你在代码中引用的 import {Button} from 'antd' 转换成了 import Button from 'antd/es/button'; import 'antd/es/button/style';另外提一句,现在antd是默认支持基于ESModule的tree shaking,不需要配 babel-plugin-import 都可以
5、如何搭建一个 UI 组件库
代码目录结构、分支规范、构建规范、发版规范(changelog生成)、文档规范、单测指标,除了技术层面,业务层面和UI设计师沟通每个组件的设计
6、微前端的常见问题
qiankun的样式隔离原理就是在进入子应用的时候加载css,离开子应用的时候卸载css。但是这样只能解决子应用和子应用的样式冲突,不能解决主应用和子应用的样式冲突问题,解决方式qiankun有个开关,开了之后会包一层shadowdom,但是shadowdom也会带来别的问题,shadowdom内部事件被外部捕获的时候,event.target会被重定向和shadow host节点,react17之后解决了这个问题,在这之前社区也有一个库可以解决这个问题。样式隔离问题我们自己可以通过postcss插件的方式,在主应用和子应用的前面都添加命名空间可以解决。
qiankun的JS沙箱隔离分为三种,legacy(单实例)、proxy(多实例)、snapshot(降级),snapshot是不支持proxy的浏览器才会生效,proxy是用于多实例场景(同时加载多个子应用),legacy是用于单实例场景。
7、Map和Object区别
1、key值的范围不同,Object的key只能是string、symbol,Map可以是任意值,包括对象、函数、数组
2、Map的key值是有序的(这一点和其他语言不一样,其他语言map都是无序的),Object早期是无序的,现在部分浏览器做了兼容是有序的,对于需要有序的场景建议用Map,不用Object
3、遍历方式不一样,Map是for of循环,因为有迭代器,Object用Object.keys或者for in8、React useState 状态机
9、远程加载组件如何实现,即通过url下载umd格式的js,如何实例化组件
远程组件加载方案实践 - 掘金
方案一:Script标签加载,然后得到window.xxx实例
方案二:eval(umdStr),得到window.xxx实例
方案三:new Function(umdStr),得到window.xxx实例
得到实例之后,通过Vue、React的动态组件进行渲染:
Vue:10、source-map 深入浅出之 Source Map - 掘金
11、图片懒加载的方案
【前端】图片懒加载的原理和三种实现方式_hxxfight的博客-CSDN博客_前端懒加载及其实现方式
如果图片是未知高度且样式不给图片设置高度的话,初始化会出现计算图片位置是0的情况,这种情况可以通过图片预加载的方式,图片递归预加载,然后加起来高度,超过屏幕高度之后,再开始调用懒加载函数,这样就可以提前知道最上面的一些图片的高度,解决计算图片位置是0的情况
12、自动滚动到某个元素
1、window.scrollTo(0, document.getElementById('aaaaaaa').getBoundingClientRect().top)
2、document.getElementById('aaaaaaa').scrollIntoView();13、react实现form表单校验
核心考点:原生form的api(在form上绑定onSubmit,button上增加type="submit")
import React, { useState } from 'react';
const reg = /[\u4e00-\u9fa5]/gm;
const Test = () => {
const [nameError, setNameError] = useState();
const [descError, setDescError] = useState();
const [sexError, setSexError] = useState();
const onSubmit = (e: React.SyntheticEvent) => {
e.preventDefault();
const target = e.target as typeof e.target & {
name: { value: string };
desc: { value: string };
sex: { value: string };
};
const name = target.name.value;
const desc = target.desc.value;
const sex = target.sex.value;
let nameFlag = false;
let descFlag = !desc;
let sexFlag = !sex;
if (reg.test(name)) {
setNameError('不能输入中文');
nameFlag = true;
} else {
setNameError(!name ? '请填写名称' : '');
nameFlag = !name;
}
setDescError(!desc ? '请填写描述' : '');
setSexError(!sex ? '请填写性别' : '');
if (nameFlag) {
document.getElementById('name')?.scrollIntoView();
return;
}
if (descFlag) {
document.getElementById('desc')?.scrollIntoView();
return;
}
if (sexFlag) {
document.getElementById('sex')?.scrollIntoView();
return;
}
};
return (
);
};
export default Test;
综合方面
管理上的经验:
分为两部分吧
1、项目管理,当你作为项目的owner,需要能够把控项目进度,对过程中发生的问题能做到快速推动解决,组织问题方快速进行沟通,对于项目中无法解决的问题要做到及时向上汇报,不要死扛,普通研发解决不了的就找资深研发,资深不行就找架构,架构不行就找TC
2、人员管理,人员管理第一大部分我觉得也是项目相关,就是每个版本都会有很多项目,要能安排不同级别的同学支撑不同的项目,对于项目需要有需求评审,技术评审,codereview等等环节,然后形成一个人员梯队,对于比较资深一些的同学,他们其实也有带人的需求,可以安排资深的同学作为一些刚入职的新员工的导师,然后在一些比较复杂的项目中,带着低阶一点的同学一起做,然后对于低阶一点的同学,需要让他们快速熟悉团队相关的业务和技术栈,然后最初让他们跟导师一起完成某个项目,熟悉之后再慢慢地培养他们去单独承接一个项目。再就是团队氛围的营造,一部分是技术氛围,组织一些技术分享会、文档建设新人文档、业务文档,要持续的发现团队当前面临的问题,比如当前技术架构有哪些问题,哪些点是效率比较低下的,如果解决这些问题来达到提效的效果,并安排不同的人进行调研并解决这些问题,在这期间给出指导
关键词总结:项目管理:把控进度、推动问题解决、高效沟通、及时上报进度和疑难问题
人员管理:安排项目、人员梯队、导师制度(高阶带低阶)、模块owner划分、文档建设、技术分享、持续提效、给出指导、定期one one,one one主要沟通最近的感觉,有没有遇到什么问题,对未来自己个人想要往哪个方向发展,
技术视野方面:
1、微前端
2、分支模型(https://doc.sensorsdata.cn/pages/viewpage.action?pageId=136423516)
3、monorepo & multirepo
4、CI/CD持续集成的流程
5、单测
6、监控
7、异常诊断工具
8、主题换肤
9、公共组件
10、性能优化
11、前端规范 eslint、theme、ts、代码规范 react/vue
12、配置化 动态表单 formily
13、国际化
nestjs技术选型思路:第一框架要满足很多基本要求,比如规范约束、扩展机制、安全、高效业务开发,除了这些,团队也能得到成长,根据这些条件,选择了eggjs和nestjs,然后最终选择了nestjs,nestjs基于express,eggjs基于koa,他们的设计思路也不一样,nestjs是面向对象编程,通过装饰器实现依赖注入,和java的spring比较类似,并且提出了很多像filter、guard、pipe这样的概念,他的规范制定的比较明确,eggjs是一种插件机制,比较严重的一点就是,eggjs不能很好的支持ts,这一点nestjs就要好多了,nestjs最近的更新也比eggjs多很多