容器系列: 1 docker的底层技术和快速实践
故事

程序员小张: 刚毕业,参加工作1年左右,日常工作是CRUD

架构师老李: 多个大型项目经验,精通各种屠龙宝术;
有一天,小张碰到了老李,他想向老李请教有关Docker的知识。于是,小张走向老李并问道:“老李,我听说你懂得很多关于Docker的知识,请问你能否给我讲讲Docker的基本结构和组件?”
老李微笑着点了点头,开始向小张介绍Docker的基本结构和组件。他告诉小张,Docker由三个主要概念构成:镜像、容器和仓库。其中,镜像是一个只读的模板,容器则是基于这个模板创建的可运行实例,而仓库则是用于存储镜像的地方。
随后,老李详细地介绍了Docker的各个组件,包括Docker客户端、Docker守护进程、Docker镜像以及Docker容器。他为小张讲解了每个组件的作用以及它们之间如何相互配合来实现Docker的功能。
在老李的深入讲解下,小张逐渐理解了Docker的基本结构和组件,并感到非常兴奋。他决定在未来的工作中深入研究Docker,并将其应用于项目中,以提高团队的效率和质量。
Docker是一个开源平台,用于快速开发、部署和运行应用程序。它由多个组件组成,以下是Docker的主要组件:
- Docker Daemon:它是Docker的核心组件,负责管理镜像、容器、网络和卷等资源,并将Docker API暴露给客户端。
- Docker Client:它是与Docker Daemon通信的主要接口,可以通过命令行或API向Daemon发送请求。
- Docker镜像(Docker Image):它是一个只读的模板,它包含了所有用于运行应用程序所需要的代码、库文件、环境变量和配置文件等内容。
- Docker容器(Docker Container):它是基于Docker镜像创建的可运行实例。每个容器都是一个独立的、轻量级的操作系统,它们之间相互隔离并且可以共享主机的内核。
- Docker Registry:它是用于存储和分发Docker镜像的公共或私有仓库。Docker Hub是最流行的公共Registry,而Docker Trusted Registry则是一种常见的私有Registry解决方案。
- Docker Compose:它是一个工具,用于定义和运行多个容器的应用程序。使用Docker Compose,可以通过一个简单的配置文件来描述应用程序的各个组件,从而使它们可以在一个统一的环境中运行。
- Docker Swarm:它是Docker的原生集群管理工具,用于协调和管理多个Docker节点。使用Docker Swarm,可以将多个Docker节点组成一个大型的虚拟集群,并在其中部署、管理和扩展Docker容器。
这些组件共同构成了Docker的核心功能,使得开发人员和系统管理员能够更加便捷地开发、部署和管理应用程序。
接下来,我们深入到docker内部,分析和学习一下它的底层实现核心技术,并对常见的操作进行实践操作。
容器vs虚拟机
容器是一种沙盒技术,可以看成集装箱,这样应用之间就有了边界而不至于互相干扰,方便搬动;
程序运行起来的计算机执行环境的总和 就是进程;
容器的核心功能: 通过约束和修改进程的动态表现,创造出一个边界;
制造约束: Cgroups技术 修改进程视图: Namespace技术
容器的本质:
int pid = clone(main_function, stack_size,CLONE_NEWPID|SIGCHLD,NULL);多次调用clone方法可以创建多个pid的进程NameSpace ,每个namespace中都会人为自己是第一号进程,看不到宿主机的进程空间也看不到其它的pid的进程空间;
除了PID Namespace ,linux还提供了Mount (挂载点信息), UTS , IPC , Network (网络设备和配置), User这些namespace,来对各种不同的进程上下文进行障眼法操作;
只能看到namespace所限定的资源,文件,设备,状态,配置 ;对宿主机和其它的不相关程序完全看不到;
所以,容器是一种限定了namespace的进程而已;
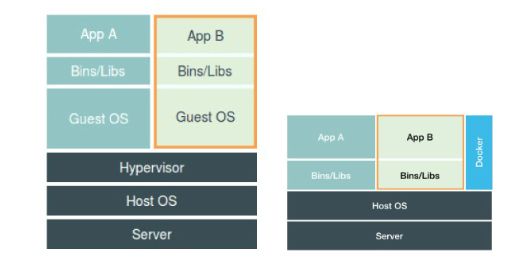
旁路式的辅助和管理工作;
| 对比项目 | 虚拟机 | docker容器 |
|---|---|---|
| 真实存在 | 真实存在,并运行一个完整的GuestOs | 不真实存在,只是辅助作用 |
| 会带来额外的资源消耗和占用 | 100-200M内存,通过虚拟化软件的拦截和处理 | 无消耗 |
| 内核 | 多个虚拟机可以使用不同的内核 | 共享操作系统内核 |
敏捷和高性能 是容器相比于虚拟机最大的优势;
缺点: 容器隔离的不彻底
多个容器之间使用的还是同一个宿主机的操作系统内核;
linux内核中很多资源和对象不能被namespace化,比如时间;(基于虚拟化和独立内核技术的容器实现隔离)
容器的底层实现基础
cgroups
容器对宿主机操作系统来说是一个普通进程,普通进程的资源限制如果设置,会挤占别的进程的资源。
Linux Control Groups : 限制一个进程组使用的资源上限,包括: CPU, 内存,磁盘,网络带宽。对进程进行优先级设置,审计,对进程挂起和恢复操作。
/sys/fs/cgoup
可以对资源进行独特的限制:
| blkio | 块设备设定io限制 |
|---|---|
| cpuset | 进程分配单独的cpu和对应的内存节点 |
| memory | 设定内存使用限制 |
在docker run启动的时候可以传递这些资源限制参数:
--cpu-period=100000 --cpu-quota=20000 缺点: 容器中 linux的 /proc top 显示的是宿主机的信息 lxcfs
namespace
进程看到的经过特殊处理的视图。
nt 设备挂载点
network 网络
user 用户目录
UTS host
IPC 进程通信
rootfs
进入容器之后,看到的文件系统,即容器镜像,它保持了应用在不同环境下的一致性。
主要使用了下面两种技术来实现。
| 技术 | 操作效果 |
|---|---|
| mount Namespace | 对容器进程视图的改变,伴随着挂载操作才能生效; |
| 容器中看到的是一个独立的隔离环境,而不是继承宿主机的文件系统; | |
| chroot/pivot_root | 改变进程的根目录 |
rootfs只包含了操作系统的文件,但是不包含操作系统的内核。
这个就是容器镜像: 挂载在容器的根目录上,用来为容器进程提供隔离后的执行环境的文件系统,就是所谓的容器镜像。
一致性: 应用+操作系统的文件和目录; 镜像是打包操作系统的能力;打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟;
容器镜像将会成为未来软件的主流发布方式。
分层+联合文件系统 union file system ; AUFS ;
目录:
/var/lib/docker/aufs/diff/layerid /var/lib/docker/aufs/mnt
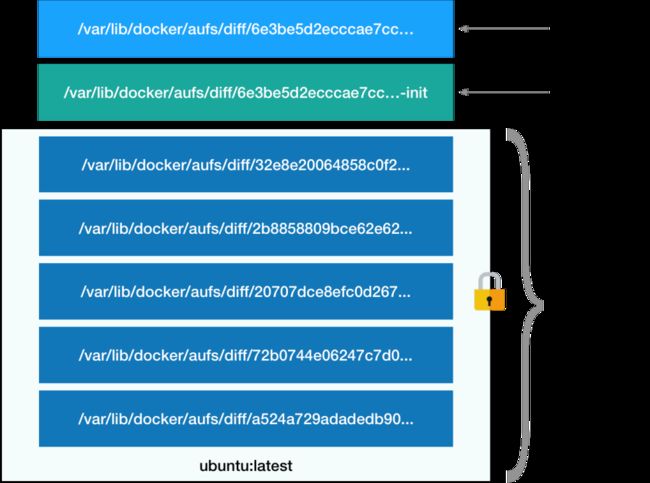
层分成三个部分:
- 可读写层;(修改层)
- init层;(配置层) /etc/hosts /etc/resolv.conf等配置信息 只针对当前容器有效,不能提交
- 只读层;(操作系统本身)
docker基本操作
1 购买一个cvm
为了学习和实验的目的,先购买一个远程的linux机器。
| 条目 | 选择 |
|---|---|
| 1.进入购买页面 腾讯云的轻量级别cvm | https://console.cloud.tencent.com/cvm/overview |
| 2.新建实例, | 选择 竞价实例 最便宜 |
| 3.选择区域 | 选择离你最近的区域 |
| 4.选择最低的配置 | S6.MEDIUM2 2C4G 哪个最便宜买哪个 |
| 5.镜像选择 | TencentOS,最新版本 |
| 6.带宽 | 选择按照使用流量计费 , 带宽可以选择10Mbps |
| 7.安全组 | 默认放行所有的请求和响应 这里是测试目的 |
| 8.设置root账号和密码 | 自己设置 |
| 9.其他的免费的开通即可 | 总价格大概是0.1元/小时 流量 0.8元/GB 流量基本用不上 |
购买成功页面如下:
然后使用一个ssh工具,比如xshell或者finalshell 登录上去;
登录进去之后,先确认一下cpu和内存是否对得上。
top
然后按 1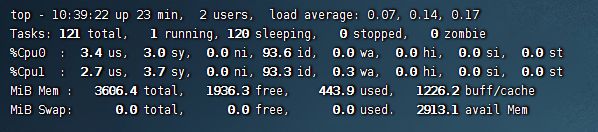
2 安装最新版本docker
指令:
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io
#启动docker
sudo systemctl start docker.service
#确认docker可以使用
docker search redis
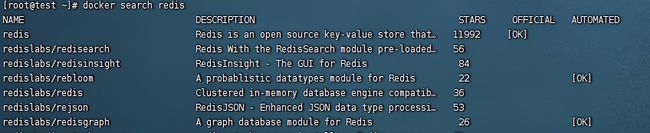
3 docker helloworld
一个简单的python程序。
from flask import Flask
import socket
import os
app = Flask(__name__)
@app.route('/')
def hello():
html = "Hello {name}!
" \
"Hostname: {hostname}
"
return html.format(name=os.getenv("NAME", "world"), hostname=socket.gethostname())
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)Flask# 使用官方提供的Python开发镜像作为基础镜像
FROM python:2.7-slim
# 将工作目录切换为/app
WORKDIR /app
# 将当前目录下的所有内容复制到/app下
ADD . /app
# 使用pip命令安装这个应用所需要的依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 允许外界访问容器的80端口
EXPOSE 80
# 设置环境变量
ENV NAME World
# 设置容器进程为:python app.py,即:这个Python应用的启动命令
CMD ["python", "app.py"]代码放在我的gitlhub上。
制作镜像:
# cd 到Dcokerfile所在的目录
docker build -t p1:v1 .
# 运行
docker run --name p1 -p 80:80 -it p1:v1运行效果:
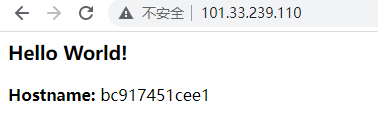
Dockerfile的每个语句执行后,都会生成一个对应的镜像层。
查看本地镜像指令:
docker images4 保存镜像到仓库
docker tag p:v1 carter880522hn/app:pythondemo
docker login
#输入你的docker hub的账号密码,即可推送到你的私有仓库 当然你也可以使用其他公有云厂商的镜像仓库
docker push carter880522hn/app:pythondemo
5 docker commit 原理
也可以进到正在运行的镜像,做一些修改,然后提交之后,推送到基础镜像。
docker ps
# 可以找到运行的容器id
docker commit ContainerId 远程tag按照分层逻辑。
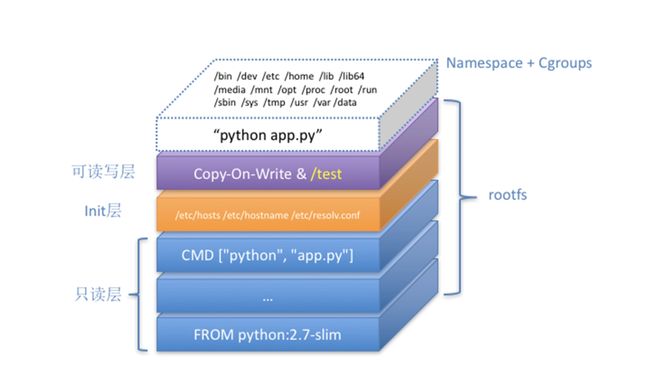
镜像分为三层:
- 只读层,操作系统;
- init层, hosts, sysctl.conf文件;
- 读写层,程序相关的层;
docker commit实际上是在容器运行之后,把最上层的可读写层,加上原来容器的只读层,打包成了一个新的镜像,只读层是宿主机共享,不占用额外空间。
6 docker exec 原理
这个命令是如何进入到容器内部的呢?
容器本质上是宿主机创建的进程,进程的namespace在机器上是实实在在文件。
查看容器在宿主机上的进程编号:
docker inspect --format '{{.State.Pid}}' bc917451cee1查看宿主机上的namespace文件。
ls -lh /proc/容器PID/ns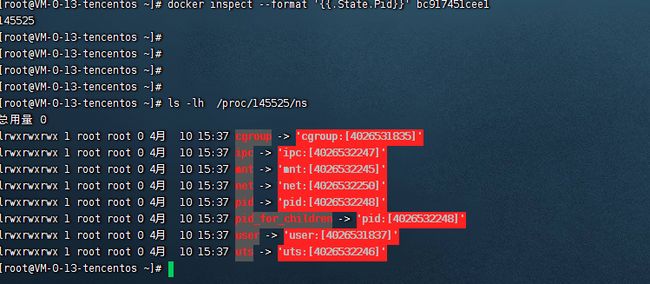
容器内部的namespace实际上在宿主机上有对应的文件进行对应。 所以,我们可以使用 exec 去控制容器的文件。
linux中一个进程是可以选择加入到某个进程已有的namespace,从而达到进入进程所在容器的目的。
下面的参数,启动容器的时候,可以进入另外一个容器的network namesapce;
--net container:4ddf4638572d7 volume原理
容器内部的新建的文件,如何让宿主机获取到? 宿主机上的文件,容器内部如何访问?
答案就是Volume,即数据卷。
语法如下:
docker run -v /local:/container ...rootfs的挂载过程:
- 容器被创建,开启Mount Namespace ;
- 执行chroot或者 pivot_root ;
volume,是在 1,2之间的时机,把volune指定的宿主机和容器目录对应关系进行绑定,从而完成挂载; 做这个挂载的时候,容器进程已经创建了,Mount Namespace已经开启了,这个挂载信息只在容器可见,在宿主机是看不见这个挂载点的,保证了容器的隔离性不被Volume打破。
利用的是linux的 bind mount机制。linux的文件系统节点叫做inode, 文件指针叫做dentry , bind mount实际修改的是dentry , 这样容器内部和宿主机对应的目录修改,就指向了同一个inode .
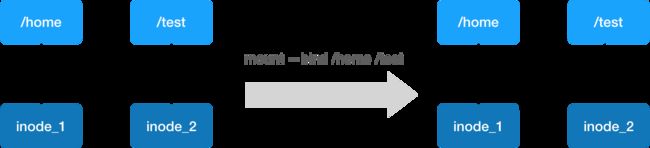
volume中的文件,不会写到镜像,但是如果你这个时候进行docker commit 操作, 这个volume对应的容器目录会被提交。
docker 镜像结构图:
容器运行环境
在宿主机上,
应用的静态表现即
应用的动态表现即容器,是一个使用cgroups和namesace 限制隔离的进程组。
| 维度 | 说明 |
|---|---|
| 应用静态表现 | 各种镜像,镜像即位于 /var/lib/docker/aufs/mnt上的 rootfs ; |
| 应用的动态表现 | 容器,是一个使用cgroups和namesace 限制隔离的进程组。 |
| 容器编排 | 把用户提交的镜像运行起来 |
| 扩展生态 | CI/CD、监控、安全、网络、存储 |
k8s
k8s: google和redhat公司联合推出的开源项目
价值: 基于容器构建分布式系统的基础依赖;
k8s的架构:
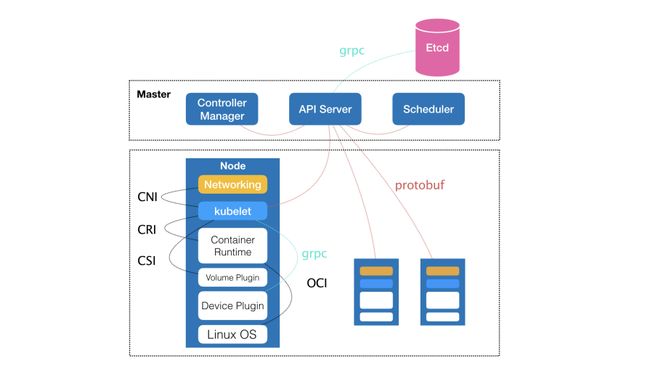
解决的问题: 编排,管理,调度用户提交的作业。 大规模集群中的各种任务,实际上存在各种关系,对这些关系的处理才是作业编排和管理系统最困难的地方。
docker只是CRI的一种实现方式。
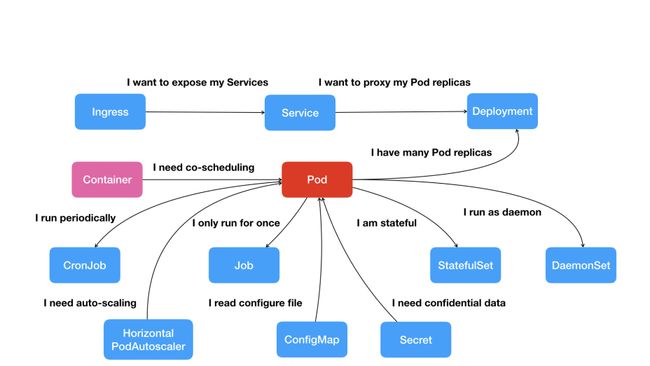
| 物理部署/虚机部署 | k8s部署 |
|---|---|
| 应用 | pod |
| 访问关系 直接维护配置文件 | service |
| 配置信息管理 通过文件 | configmap/secret |
| daemon 做日志收集,灾难恢复,数据备份 每台主机只运行一个 | daemonset |
| 定时任务 | cronjob |
| 一次性任务 | job |
| 两台nginx做负载均衡 | |
| keepalive做一个vip | |
| 部署两个nginx | 一个deployment,一个service |
处理思路: 1.通过pod,job来描述你管理的应用; 2.定义一些平台级的服务对象来编排: service,secret,autoscaler ;
小结
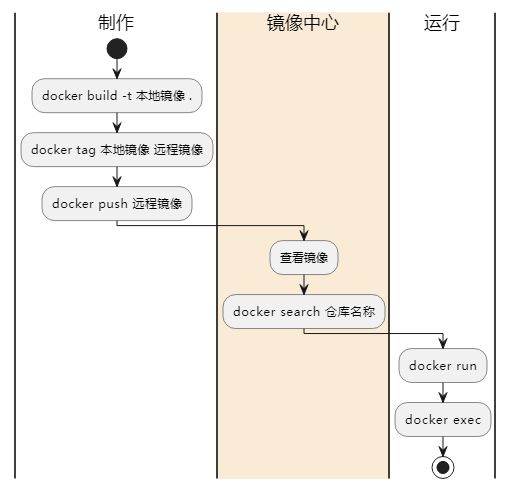
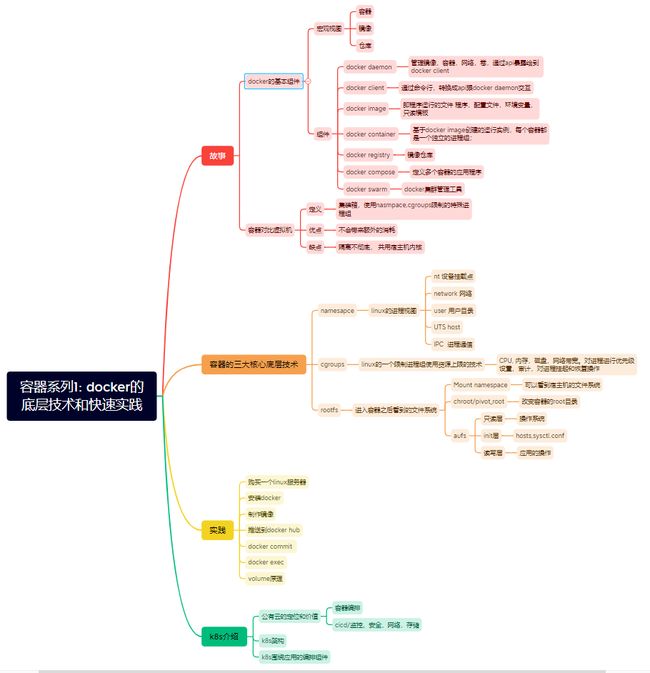
本文从一个了解docker的故事出发,详细分析了docker的三大底层核心技术,cgroups,namesapce,rootfs ; 并从实践出发,购买一个远程的linux机器,安装docker, 运行一个简单的python应用,并结合底层核心技术,讲述了docker exec , docker commit ,volume的实现原理,然后简单介绍了k8s的架构和解决的问题,一些核心概念的引出;
原创不易,关注诚可贵,转发价更高!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。