从RCNN、FastRCNN到FasterRCNN
文章目录
-
- RCNN
-
- RCNN的步骤
- RCNN的整体框架
- RCNN 存在的问题:
- fast RCNN
- faster RCNN
- Faster RCNN
-
- 环境配置
- 文件结构
- 预训练权重模型
- 训练方法
- faster RCNN 源码解析
-
- 训练过程 mobilenet
- 自定义数据集
- fastrcnn 框架
-
- framework 部分
- transform部分
- transform部分
RCNN
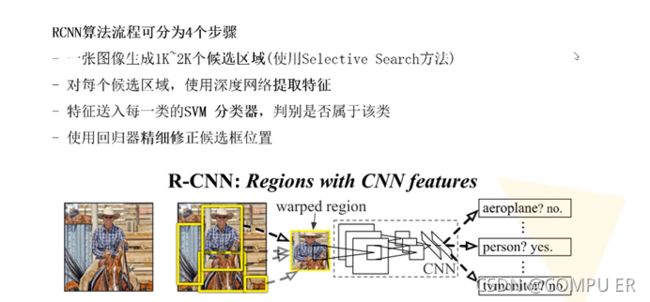
RCNN的步骤
-
通过selective search生成建议框,2k个;
-
将2000个候选区域缩放到统一尺寸227*227,输入到图像分类CNN网络,获得一个2000*4096的特征矩阵;
-
将特征矩阵送进每一类的SVM分类器权值矩阵409620,得到200020的分类结果,然后对每一列进行非极大值抑制(NMS)以剔除重复目标,保留高质量候选框**。**
-
使用回归器精细修正候选框的位置,最小二乘法进行回归训练。
非极大值抑制提出重叠建议框的依据是两张图片的交并比,即IOU intersection over union, (A∩B)/(A∪B) ,具体步骤
-
寻找得分最高的目标
-
计算该目标和其他目标的iou值
-
删除所有iou值大于给定阈值的目标
-
重复步骤一
RCNN的整体框架

RCNN 存在的问题:
-
检测速度太慢了,仅仅是selective search提取候选框,一张图片需要花费2秒钟;
-
训练速度较慢;
-
训练所需空间也比较大。
fast RCNN
回顾:RCNN的算法流程
- 通过selective search 生成建议框 2k左右
- 通过cnn网络提取特征,backbone 一般为 resnet101,输入为每一个特征向量
- 通过svm进行分类处理
- bounding box regression
fast rcnn 算法流程:
- ss算法生成候选区域;
- 将整幅图像输入cnn网络得到特征图,并将ss算法生成的候选框投影到特征图上获得相应的特征矩阵
- 通过ROI pooling的操作,将每个特征矩阵缩放到7*7大小的特征图,展平后通过全连接层得到目标分类结果和边界框回归结果。
不同之处:
- fast rcnn 是将整幅图像作为输入,而不是将每个投影框作为输入,大大减少了计算量,解决了rcnn的计算冗余的问题,此处参考的是sspnet;
- 用FC代替 svm分类
注意:
训练过程中的 正样本和负样本,例子:猫狗分类的数据不平衡的问题,原论文对2000个候选区域,根据IOU的大小,采集正负样本。

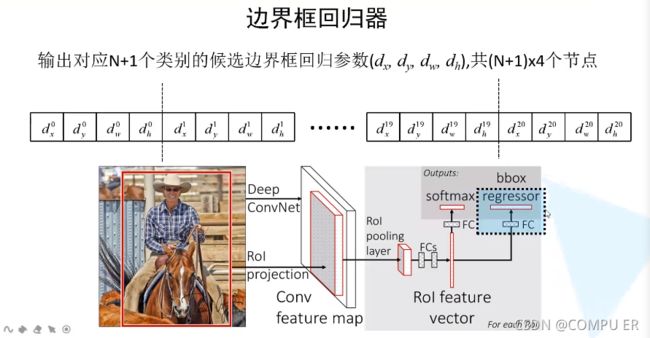

如何计算损失?
- 分类损失
- 边界框回归损失

分类损失 交叉熵损失


L l o c L_{loc} Lloc由四部分组成,分别对应 x i u 、 y i u 、 w i u 、 h i u x_i^u、y_i^u、w_i^u、h_i^u xiu、yiu、wiu、hiu
[u>=1]=1,when u>=1 other =1
补充: 交叉熵损失
多分类问题 softmax H = − ∑ i o i ∗ l o g ( o i ) H=-\sum_{i}o_i^*log(o_i) H=−∑ioi∗log(oi)
此处的o指的是onehot,真实标签的输出的onehot为 [0,0,0,1,0] 而 预测的softmax 的输出为 [0.1,0.2,0.1,0.5,0.1],所以说交叉熵的外面是 实际标签,不然会出现无穷大。
针对二分类问题,应该使用的是 sigmoid 输出,每个输出节点之间互不相关
H = − 1 N ∑ i [ o i ∗ l o g ( o i ) + ( 1 − o i ∗ ) l o g ( 1 − o i ) ] H=-\frac{1}{N}\sum_i{[o_i^*log(o_i)+(1-o_i^*)log(1-o_i)]} H=−N1∑i[oi∗log(oi)+(1−oi∗)log(1−oi)]
总结:

相当于将 classification&bounding-box regression 纳入到 cnn的网络
faster RCNN
作者: Ross Girshick
核心: RPN region proposal network
回顾 fastrcnn的算法流程:
- 通过selective search 方法获得2k候选区域;
- 将整张图片作为输入到cnn网络中,back bone一般为 resnet101,然后对应得到每个候选区域的特征矩阵;
- 通过ROI pooling的操作,将特征矩阵打平,输入到全连接层,输出 2k预测结果和 4k bounding box regression.
faster rcnn的算法流程:
- 将图像输入网络得到特征图;
- 使用rpn生成候选框,将候选框投影到特征图得到特征矩阵;
- 通过ROI pooling,得到统一尺寸的特征图,输入到 全连接层,得到 分类结果和bounding box regression.
相当于是 fast rcnn+RPN

这里的anchor 相当于只完成了 检测是否有目标,而不进行分类
anchor的 面积有三种选择,128^2 , 256^2, 512^2,而三种比例,1:1,1:2,2:1,一共有九种anchor。
注意: 作者阐明了通过较小的anchor也可以对较大的感受野进行判别。
这里反推之前的anchor坐标,就是卷积尺寸变化公式的逆式。
此处,应该舍弃掉一跨过边界的anchor,对于RPN生成的候选框的cls得分,采用非极大值抑制,舍弃掉很多的候选框。
定义正样本的两种方式:
- IOU>=0.7
- 与grand truth 相交最大的anchor。
RPN的损失函数
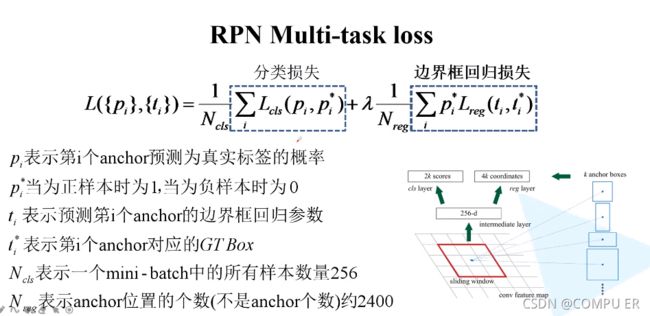
pi*与艾弗森括号作用相同。
N_reg表示anchor位置的个数,不用×9。
分类损失

注意:这里虽然区分的是背景和前景,这是个二分类问题,但是用的是多分类的softmax.
如果使用二分类损失函数,则输出为k个分数,如下图所示(pytorch官方版本使用二分类损失函数)。

RPN 的边框回归损失,和fast rcnn完全一样。

faster rcnn 训练方法:
现在采用的是联合训练方法,原始论文是分步训练。


Faster RCNN
可以在 torchvision.models.detection.faster_rcnn查看
或者是官方仓库pytorch.vision.refrence.detection
环境配置
- pytorch 3.6/3.7
- pytorch 1.5 以上 cuda 10.1以上
- pycocotools
linux环境下配置pip install pycocotools
windowspip install pycocotools-win但是有一定几率报错,需要安装VS C++ 14 - unbuntu centos 训练
- 最好使用 GPU
文件结构
- backbone 主干特征提取网络 resnet50+FPN
- train_utils 训练验证相关模块
- my_dataset.py 自定义dataset,用于读取 VOC数据集
- train_mobilenet.py , mobilenet v2 作为backbone,但是不经常使用,因为没有好用的预训练权重模型;
- train_restnet50_fpn.py 以resnet50+FPN作为backbone 进行训练
- train_multi_GPU.py 与4 5 不同,需要在并命令行使用
- predict.py 简单的预测脚本
- pascal_voc_classes.json 标签文件
预训练权重模型
训练方法
多GPU训练
若要使用多GPU训练,使用python -m torch.distributed.launch --nproc_per_node=8 --use_env train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量
faster RCNN 源码解析
torchvision.models.detection.fasterrcnn
和训练相关的代码在 torch.refrence.detection
**配置: Python 3.6+ pytorch1.5+ **
pip install pycocotools-win
文件结构:
- backbone
- network_files
- train_utils 训练相关模块
- my_datasets 自定义dataset读取voc数据集
- train_mobilenet backbone为mobilenet,只提供了backbone的预训练参数
- train_resnet50_fpn backbone为resnet+fpn,有比较完整的预训练模型,fastrcnn+rpn
- train_multi_GPU 针对多GPU的用户
- predict 预测脚本
- Pascal_voc_labels.json 每个目标对应的数字
- split_data.py 生成类似于Pascal voc
数据集: Pascal_voc_2012数据集
split_data.py
训练过程 mobilenet
预训练权重初始化backbone,然后冻结backbone,只训练后面的rpn和后面的全连接层(classification和bounding box regression)
学习率的确定,每隔一顶步数降低学习率
自定义数据集
split_data.py
my_dataset.py
class VOC2012DataSet(Dataset)
注意继承自 torch.utils.data.Dataset 需要重写__len__和__getitem__方法,还可以实现
fastrcnn 框架
train_mobilenet.py 训练mobilenet网络
from math import gamma
import os
import datetime
import torch
from torch.nn import parameter
import torchvision
import transforms
from network_files import FasterRCNN,AnchorsGenerator
from backbone import MobileNetV2,vgg
from my_dataset import VOC2012DataSet
from train_utils import train_aval_utils as utils
def create_model(num_classes):
# backbone
backbone=MobileNetV2(weights_path='./backbone/mobilenet_v2.pth').features
backbone.out_channels=1280
# anchor_generator
anchor_generator=AnchorsGenerator(
sizes=((32,64,128,256,512),),
aspect_ratios=((0.5,1.0,2.0),))
# roi_poolling
roi_pooler=torchvision.ops.MultiScaleRoIAlign(
feature_names=['0'],
output_size=[7,7],
sampling_ratio=2)
# model
model=FasterRCNN(
backbone=backbone,
num_classes=num_classes,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler
)
# return
return model
def main():
# device
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('using {} device training.'.format(device.type))
# results_file
results_file='results{}.txt'.format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
# weight_files
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
# data_trasnforms
data_transform={
'train':transforms.Compose(
transforms.ToTensor(),
transforms.RandomHorizontalFlip()
),
'val':transforms.Compose(
transforms.ToTensor()
)
}
# dataset
VOC_root='./'
if os.path.exists(os.path.join(VOC_root,'VOCdevkit')) is False:
raise FileNotFoundError("VOCdevkit dose not is path:'{}'.".format(VOC_root))
# load train dataset
train_data_set=VOC2012DataSet(VOC_root,data_transform['train'],'train.txt')
batch_size=8
nw=min([os.cpu_count(),batch_size if batch_size>1 else 0,8])
print('Using {%g} dataloader workers'.format(nw))
train_data_loader=torch.utils.data.DataLoader(
train_data_set,
batch_size=batch_size,
shuffle=True,
num_worker=nw,
collate_fn=train_data_set.collate_fn
)
# load validation dataset
val_data_set=VOC2012DataSet(VOC_root,data_transform['val'],'val.txt')
val_dat_loader=torch.utils.data.DataLoader(
val_data_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn
)
# model
model=create_model(num_classes=21)
model.to(device)
train_loss=[]
learning_rate=[]
val_map=[]
# train step1: frozen backbone and train 5 epochs
# 1. frozen backbone
for param in model.backbone.parameters():
param.requires_grad=False
# 2. define parameters
params=[p for p in model.parameters() if p.requires_grad]
optimizer=torch.optim.SGD(params,lr=0.005,momentum=0.9,weight_decay=0.0005)
# 3. train
init_epochs=5
for epoch in range(init_epochs):
# train for one epoch, printing every 10 iterations
mean_loss,lr=utils.train_one_epoch(model,optimizer,train_data_set,device,epoch,print_freq=50,warmup=True)
train_loss.append(mean_loss.item())
learning_rate.append(lr)
# evaluate on the validation dataset
coco_info=utils.evaluate(model,val_dat_loader,device=device)
# wirte into txt
with open(results_file,'a') as f:
result_info=[str(round(i,4)) for i in coco_info+[mean_loss.item()]] +[str(round(lr,6))]
txt='epoch:{} {}'.format(epoch,' '.join(result_info))
f.wirte(txt,'.\n')
val_map.append(coco_info[1])
torch.save(model.state_dict(),'./save_weights/pretrain.pth')
# train step2: unfrozen backbone and train all network
# 1. unfrozen some paramters
for name,parameter in model.backbone.named_parameters():
split_name=name.split('.')[0]
if split_name in ['0','1','2','3']:
parameter.requires_grad=False
else:
parameter.requires_grad=True
# 2. define optimizer
params=[p for p in model.parameters() if p.requires_grad]
optimter=torch.optim.SGD(params,lr=0.005,momentum=0.9,weight_decay=0.0005)
lr_scheduler=torch.optim.lr_scheduler.StepLR(
optimizer,step_size=3,gamma=0.003
)
num_epochs=20
for epoch in range(init_epochs,num_epochs+init_epochs,1):
# train for one epoch, printing every 50 iterations
mean_loss,lr=utils.train_one_epoch(model,optimizer,train_data_loader,device,epoch,print_freq=50)
train_loss.append(mean_loss.item())
learning_rate.append(lr)
# updata the learning rate
lr_scheduler.step()
# evaluate o n the test dataset
coco_info=utils.evaluate(model,val_dat_loader,device=device)
# write into txt
with open(results_file,'a') as f:
result_info=[str(round(i,4)) for i in coco_info+[mean_loss.item()]]+[str(round(lr,6))]
txt='epoch:{} {}'.format(epoch,' '.join(results_file))
f.wirte(txt+'.\n')
val_map.append(coco_info[1])
# save weights
if epoch in range(num_epochs+init_epochs)[-5:]:
save_files={
'model':model.state_dict(),
'optimizer':optimizer.state_dict(),
'lr_scheduler':lr_scheduler.state_dict(),
'epoch':epoch
}
torch.save(save_files,'./save_weights/mobile-model-{}.pth'.format(epoch))
# plot loss and lr curve
if len(train_loss) !=0 and len(learning_rate)!=0:
from plot_curve import plot_loss_and_lr
plot_loss_and_lr(train_loss,learning_rate)
# plot mAP curve
if len(val_map)!=0:
from plot_curve import plot_map
plot_map(val_map)
if __name__=="__main__":
main()
在resnet50的模型中,会自动冻结部分底层权重
使用混合精度,训练速度会翻倍
predict.py
import os
import time
import json
import torch
import torchvision
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
from network_files import FasterRCNN, FastRCNNPredictor, AnchorsGenerator
from backbone import resnet50_fpn_backbone, MobileNetV2
from draw_box_utils import draw_box
def create_model(num_classes):
# mobileNetv2+faster_RCNN
# backbone = MobileNetV2().features
# backbone.out_channels = 1280
#
# anchor_generator = AnchorsGenerator(sizes=((32, 64, 128, 256, 512),),
# aspect_ratios=((0.5, 1.0, 2.0),))
#
# roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
# output_size=[7, 7],
# sampling_ratio=2)
#
# model = FasterRCNN(backbone=backbone,
# num_classes=num_classes,
# rpn_anchor_generator=anchor_generator,
# box_roi_pool=roi_pooler)
# resNet50+fpn+faster_RCNN
# 注意,这里的norm_layer要和训练脚本中保持一致
backbone = resnet50_fpn_backbone(norm_layer=torch.nn.BatchNorm2d)
model = FasterRCNN(backbone=backbone, num_classes=num_classes, rpn_score_thresh=0.5)
return model
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
def main():
# get devices
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# create model
model = create_model(num_classes=21)
# load train weights
train_weights = "./save_weights/model.pth"
assert os.path.exists(train_weights), "{} file dose not exist.".format(train_weights)
model.load_state_dict(torch.load(train_weights, map_location=device)["model"])
model.to(device)
# read class_indict
label_json_path = './pascal_voc_classes.json'
assert os.path.exists(label_json_path), "json file {} dose not exist.".format(label_json_path)
json_file = open(label_json_path, 'r')
class_dict = json.load(json_file)
category_index = {v: k for k, v in class_dict.items()}
# load image
original_img = Image.open("./test.jpg")
# from pil image to tensor, do not normalize image
data_transform = transforms.Compose([transforms.ToTensor()])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
predictions = model(img.to(device))[0]
t_end = time_synchronized()
print("inference+NMS time: {}".format(t_end - t_start))
predict_boxes = predictions["boxes"].to("cpu").numpy()
predict_classes = predictions["labels"].to("cpu").numpy()
predict_scores = predictions["scores"].to("cpu").numpy()
if len(predict_boxes) == 0:
print("没有检测到任何目标!")
draw_box(original_img,
predict_boxes,
predict_classes,
predict_scores,
category_index,
thresh=0.5,
line_thickness=3)
plt.imshow(original_img)
plt.show()
# 保存预测的图片结果
original_img.save("test_result.jpg")
if __name__ == '__main__':
main()
framework 部分
- 传入参数: backbone,rpnHead,roi_heads(ROI pooling & fast RCNNHeader & classification)
- forward 方法,传入参数
imagestargets,来源是my_dataset.py FasterRCNNBase类:网络结构FasterRCNN设置初始参数,是构造在FasterRCNNBase基础以上的- 初始化参数的设置,backbone, num_classes(包括背景的class的个数)
- RPN参数设置,包括在非极大值抑制中的保留候选框的数量,注意训练和测试保留的数量不相同,以及在这个过程中的 iou数量
transform部分
对voc数据集进行标准化处理 和 resize,transform.py
normalize函数,标准化处理,注意将mean转化为三维的tensorresize函数,缩放因子scale_factor, 通过torch.nn.functional.interpolate(...)进行缩放,如果是验证模式直接返回图片,如果是train mode,则要将box也进行缩放。batch_images函数,将一批大小不同的图片打包成一个batch,但是这里并不是进行resize,而是进行补零操作。
ROI pooling & fast RCNNHeader & classification)
- forward 方法,传入参数
imagestargets,来源是my_dataset.py FasterRCNNBase类:网络结构FasterRCNN设置初始参数,是构造在FasterRCNNBase基础以上的- 初始化参数的设置,backbone, num_classes(包括背景的class的个数)
- RPN参数设置,包括在非极大值抑制中的保留候选框的数量,注意训练和测试保留的数量不相同,以及在这个过程中的 iou数量
transform部分
对voc数据集进行标准化处理 和 resize,transform.py
normalize函数,标准化处理,注意将mean转化为三维的tensorresize函数,缩放因子scale_factor, 通过torch.nn.functional.interpolate(...)进行缩放,如果是验证模式直接返回图片,如果是train mode,则要将box也进行缩放。batch_images函数,将一批大小不同的图片打包成一个batch,但是这里并不是进行resize,而是进行补零操作。