第3章 数据科学的5个步骤
第3章 数据科学的5个步骤
文章目录
-
-
- 第3章 数据科学的5个步骤
-
- 3.1 数据科学简介
- 3.2 5个步骤概览
- 3.2.1 提出有意思的问题
- 3.2.2 获取数据
- 3.2.3 探索数据
- 3.2.4 数据建模
- 3.2.5 可视化和分享结果
- 3.3.1 数据探索的基本问题
- 3.3.2 数据集1:Yelp点评数据
-
- DataFrame
- Series
- 定性数据的探索技巧
- 3.3.3 数据集2:泰坦尼克
-
3.1 数据科学简介
数据科学严格遵循结构化、一步一步的操作过程,保证了分析结果的可靠性。
3.2 5个步骤概览
- 提出有意思的问题
- 获取数据
- 探索数据
- 数据建模
- 可视化和分享结果
3.2.1 提出有意思的问题
你可能想到一个问题,然后自言自语说:“我打赌没有这样的数据可以帮到我们!”然后就将它从问题列表里删除。千万不要这样做,把它留在你的问题列表中!
3.2.2 获取数据
一旦你确定了需要关注的问题,接下来就需要全力收集回答上述问题所需要的数据。正如之前所说,数据可能来自多个数据源,所以这一步非常具有挑战性。
3.2.3 探索数据
一旦得到数据,我们将使用第2章学习的知识,将数据归类到不同的数据类型。这是数据科学5个步骤中最关键的一步。当这一步骤完成时,分析师通常已经花费了数个小时学习相关的领域知识,利用代码或其他工具处理和探索数据,对数据蕴含的价值有了更好的认识。
3.2.4 数据建模
这一步涉及统计学和机器学习模型的应用。我们不仅仅选择模型,还通过在模型中植入数学指标,对模型效果进行评价。
3.2.5 可视化和分享结果
毫无疑问,可视化和分享结果是最重要的一步。分析结果也许看起来非常明显和简单,但将其总结为他人易于理解的形式比看起来困难得多。
3.3.1 数据探索的基本问题


3.3.2 数据集1:Yelp点评数据
我们使用的第1个数据集来自点评网站Yelp的公开数据,数据集中所有的身份识别信息都已经被删除。首先读取数据,如下图所示。
import pandas as pd
yelp_raw_data=pd.read_csv("yelp.csv")
yelp_raw_data.head()
上述代码的作用是:
- 导入Pandas包,并缩写为pd
- 读取文件yelp.csv,并命名为yelp_raw_data
- 查看数据的表头(仅前几行)
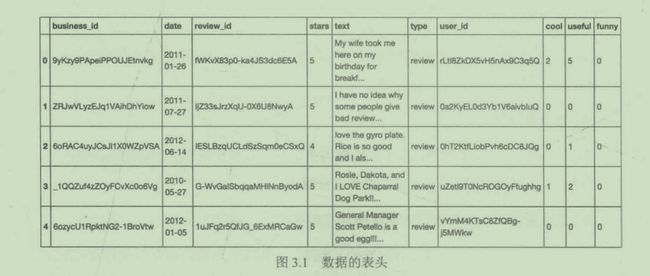
问题1:数据是有组织格式的,还是无组织格式的?
数据源是非常好的行列结构,我们可以认为它是有组织格式的。
问题2:每一行代表什么?
很明显,每一行代表一条用户的评价。我们还会查看每一行和每一列的数据类型。我们使用DataFrame的shape方法查看数据集的大小。
yelp_raw_data.shape
#(10000,10)
结果显示,数据集有10000行和10列。换言之,数据集有10000个观测值和10个观测特征。
问题3:每一列代表什么?
- business_id:本列看起来是每条评价对应的交易的唯一标识码。本列是定类尺度,因为识别码没有天然的顺序。
- date:本列是每条评价的提交日期。请注意,它只精确到了年、月和日。虽然时间通常被认为是连续数据,但本列应该被视为离散数据。本列属于定序尺度,因为日期有天然的顺序。
- review_id:本列看起来是每条评价的唯一识别码。本列同样属于定类尺度,因为识别码没有天然的顺序。
- stars:本列看起来是评价者给每一个餐馆的最终评分。本列是有次序的定性数据,因此属于定序尺度。
- text:本列看起来是用户撰写的评价。对于大部分文本数据,我们将其归类为定类尺度。
- type:本列的前5行均为"review",我们猜测它是标记每行是否为"review"的列,也就是说很可能存在不是"review"的行。我们随后将进行更深入的分析。本列属于定类尺度。
- user_id:本列是每个提交评价的用户的唯一识别码。和其他唯一识别码一样,本列也属于定类尺度。
问题4:是否有缺失值?
使用isnull方法判断是否有缺失值。比如,对于名为awesome_dataframe的DataFrame数据集,使用Python代码awesome_dataframe.isnull().sum()可显示每一列的缺失值总数。
问题5:是否需要对某些列进行数据转换?
我们想知道是否需要改变定量数据的数值范围,或者是否需要为定性数据创建哑变量(dummy variables)
由于本数据集只有定性数据,所以我们将焦点放在定序和定类范围。
在进行数据探索之前,我们先对Python数据分析包Pandas的术语做一个简单了解。
DataFrame
当我们读取数据集时,Pandas将创建一个名为DataFrame类型的对象。你可以将它想象成Python版本的电子表格(但是更好用)。在本例中,变量yelp_raw_data就是一个DataFrame。
type(yelp_raw_data)
#pandas.core.frame.Dataframe
DataFrame本质上是一种二维结构,它和电子表格一样以行列结构存储数据。但是相对于电子表格,DataFrame最重要的优点就是它可以处理的数据量远超大多数电子表格。如果你熟悉R语言,可能认识DataFrame这个词,因为Python中的DataFrame正是从R语言借过来的!
由于我们处理的大部分数据都是有组织数据,所以DataFrame是Pandas中使用频率仅次于Series的对象。
Series

定性数据的探索技巧
下面我们使用以上两个Pandas数据类型开始数据探索。对于定性数据,我们主要关注定类尺度和定序尺度。
定类尺度列
对于定类尺度列,列名描述了该列的含义,数据类型是定性数据。在Yelp数据集中,定类尺度列有business_id、review_id、text、type和user_id。我们使用Pandas进行更深入的分析,如下所示:
yelp_raw_data['business_id'].describe()
#count 10000
#unique 4174
#top JokKtdXU7zXHcr20Lrk29A
#freq 37
describe函数用于输出指定列的快速统计信息。请注意,Pandas自动识别出business_id列为定性数据,所以给出的快速统计是有意义的。实际上,当describe函数作用于定性数据时,我们将得到以下4个统计信息。
- count:该列含有多少个值。
- unique:该列含有多少个非重复值。
- top:该列出现次数最多的值。
- freq:该列出现次数最多的值的次数。
对于定类尺度数据,我们通常观察以下几个特征,以决定是否需要进行数据转换。
- 非重复项的个数是否合理(通常小于20个)?
- 该列是自由文本吗?
- 该列所有的行都不重复吗?
我们已经知道business_id列有10000个值,但千万别被骗了!这并不意味着真的有10000条交易评价,它仅仅意味着business_id列被填充了10000次。统计指标unique显示数据集有4174个不重复的餐馆,其中被评价次数最多的餐馆是JokKtdXU7zXHcr20Lrk29A,总评价次数是37次。
yelp_raw_data['review_id'].describe()
#count 10000
#unique 10000
#top eTa5KD-LTgQv6UT1Zmijmw
#freq 1
count和unique值均为10000。请你思考几秒,这个结果合理吗?请结合每一行每一列代表的意思。
…
当然是合理的!因为该列是每条评价的唯一识别码,每一行代表独立的、不重复的点评,所以review_id列含有10000个不重复值是合理的。但为什么eTa5KD-LTgQv6UT1Zmijmw是出现次数最多的值呢?它只是从10000个值中随机选择的结果。
yelp_raw_data['text'].describe()
#count 10000
#unique 9998
#top This review is for the chain in general.The l...
#freq 2
text列有点意思,它是用户撰写的评价。理论上,我们认为它和review_id列一样是不重复的文本,因为如果两个不同的人撰写的评价完全一致会非常诡异。但是,数据集中恰恰有两条评价完全一样!下面让我们花点时间学习一下DataFrame的数据筛选功能,然后再研究这一奇怪现象。
Pandas中的筛选
我们先从**筛选(filtering)**的机制说起。在Pandas中,基于特定条件对行进行筛选非常简单。对于DataFrame对象,如果想依据某些筛选条件对行进行过滤,只需一行一行检查该行是否满足特定条件即可,同时Pandas将判断结果(真或假)存在一个Series对象中。
真和假的判断依据如下。
- 真:该行满足条件
- 假:该行不满足条件
所以我们首先需要设定一个条件。下面从数据集中提取出现两次的文本:
duplicate_text=yelp_raw_data['text'].describe()['top']
以下是重复的文本:
"This review is for the chain in general.The location we went to is new so it isn't in Yelp yet.Once it is I will put this review there as well......"
我们马上发现这可能是同一个人给隶属于同一家连锁餐馆的两家店撰写的两条完全相同的评价。但是,在没有进一步证据之前,这仅仅是猜测。
duplicate_text变量是文本类型。
我们已经找出了重复文本,下面来创建判断真或假的Series对象。
text_is_the_duplicate=yelp_raw_data['text']==duplicate_text
上面的代码将数据集中的text列和重复文本duplicate_text进行比较。这看起来有点不可思议,因为将含有10000个元素的列表和1条文本做比较,对比结果应该是假,不是吗?
事实上,这是Series对象一个非常有意思的功能。当我们将Series对象和另一个对象做比较时,相当于将Series中每个元素和该对象做比较,返回的结果是一个和Series对象长度相同的新Series对象。非常便捷!
type(text_is_the_duplicate) #it is a Series of Trues and Falses
text_is_the_duplicate.head() #shows a few Falses out of the Series
在Python中,我们可以像对1和0一样,对真和假进行相加或相减。比如,真+假-真+假+真==1。所以,我们可以通过将Series对象的值相加来验证其是否正确。由于只有两行文本重复,所以Series对象合计值应为2
sum(text_is_the_duplicate) # ==2
现在,我们已经有了布尔型Series对象,我们可以用括号将它传入DataFrame数据集中,得到筛选后的结果。
filtered_dataframe=yelp_raw_data[text_is_the_duplicate]
#the filtered Dataframe
filtered_dataframe

看起来我们之前的猜测是对的:某人在同一天,给同一连锁品牌的两家餐馆,撰写了相同的评语。
我们接着分析其他列:
yelp_raw_data['type'].describe()
count 10000
unique 1
top review
freq 10000
统计显示该列的列值只有一个:review。
yelp_raw_data['user_id'].describe()
count 10000
unique 6403
top fczQCSmaWF78toLEmb0Zsw
freq 38
和business_id类似,数据集由6403个用户的评价组成,其中评价次数最多的用户评价了38次!
在本例中,我们无须进行数据转换。
定序尺度列
只有date和stars列属于定序尺度。我们先看看describe方法返回哪些信息。
yelp_raw_data['stars'].describe()
#count 10000.000000
#mean 3.777500
#std 1.214636
#min 1.000000
#25% 3.000000
#50% 4.000000
#75% 5.000000
#max 5.000000
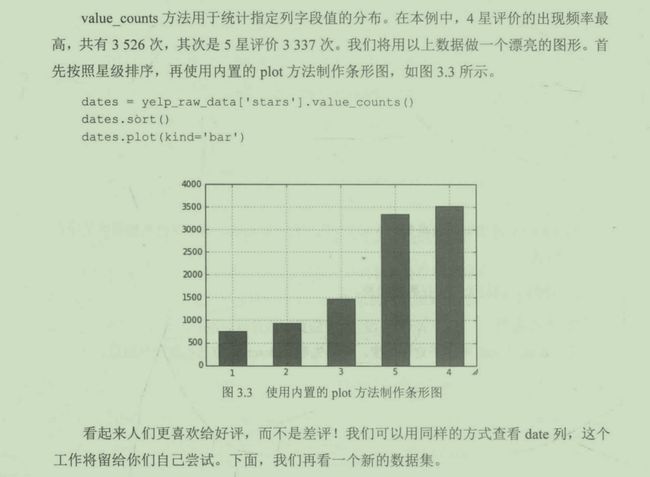
虽然该列是定序尺度,但describe方法将其看作定量数据,并返回相应的统计信息。这是因为软件识别到一串数值后,以为我们希望查看平均值、最小值和最大值,这是正确的。我们接着使用value_counts方法查看字段值的分布情况。
yelp_raw_data['stars'].value_counts()
#4 3526
#5 3337
#3 1461
#2 927
#1 749
3.3.3 数据集2:泰坦尼克
泰坦尼克数据集是一个包含1912年泰坦尼克号撞上冰山时乘客信息的样本数据。我们首先导入数据集。
titanic=pd.read_csv('short_titanic.csv')
titanic.head()

数据集包含很多列,但在本例中,我们仅关注图中显示的列。
显然,泰坦尼克数据集和大部分电子表格一样是有组织的行列结构。下面我们快速查看它的大小:
titanic.shape
#(891,5)
数据集有891行和5列,每一行代表一名乘客,每一列的含义如下。
- Survived:这是一个二元变量(binary variable),表示乘客是否在灾难中幸存,1表示幸存,0表示罹难。该字段为定类尺度,因为字段值仅有两个。
- Pclass:这是乘客的舱位等级,3表示三等舱,以此类推。该字段为定序尺度。
- Name:这是乘客的姓名。该字段毫无疑问是定类尺度。
- Sex:这是乘客的性别,定类尺度。
- Age:这个字段有些特殊。理论上,年龄既可以是定性数据,也可以是定量数据,然而,我认为年龄应该具有定量的特征,因此它属于定比尺度。
通常情况下,数据转换是指忽略被转化列的定性特征,将其转为数值型。对于泰坦尼克数据集,我们需要将Name列和Sex列转换为数值型。对于Sex列,我们可以用1表示女性,0表示男性。下面使用Pandas进行数据转换。我们导入一个叫Numpy的Python模块。
import numpy as np
titanic['Sex']=np.where(titanic['Sex']=='female',1,0)
np.where方法有3个参数:
- 第1个是布尔型判断(真或假)
- 第2个是新值
- 第3个是备选值
当第一个参数为真时,用新值(本例中的1)替换原值,否则用备选值(本例中的0)替换原值,最终生成一个和原Sex列表示相同含义的数值列。
titanic['Sex']
#0 0
#1 1
#2 1
#3 1
#4 0
#5 0
#6 0
#7 0
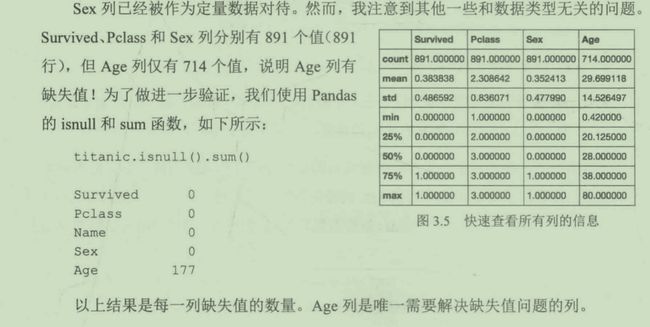
下面快速查看所有列的信息。
titanic.describe()
当我们面对缺失值时,通常有两个选择:
- 删除含有缺失值的行
- 尝试填充数据
删除行是最简单的选择,但你面临着丢失有价值数据的风险。例如,在本例中,我们有177行缺失年龄信息,数量接近全部891行数据的20%。为了填充数据,我们要么查阅历史资料,找出每一个乘客的真实年龄,要么用占位符进行填充。
下面我们用数据集中所有乘客的平均年龄填充缺失值,用到的两个新方法分别是mean和fillna。我们用isnull找出缺失值,用mean计算Age列的平均值,再通过fillna方法用新值替换所有的缺失值。
print(sum(titanic['Age'].isnull())) # ==177 missing values
average_age=titanic['Age'].mean() # get the average age
titanic['Age'].fillna(average_age,inplace=True) # use the fillna method to remove null values
print(sum(titanic['Age'].isnull())) # ==0 missing values
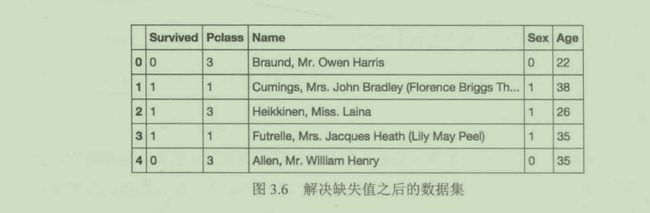
完成啦!我们已经用平均年龄29.69替换了所有的缺失值。
titanic.isnull().sum()
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
非常棒!我们在没有删除任何行的情况下,解决了缺失值问题。
有了以上数据集,我们就可以回答更复杂的问题。比如,男性或女性的平均年龄分别是多少?我们可以先按性别进行筛选,再计算平均值。Pandas由内置函数做这件事情,叫做groupby,用法如下:
titanic.groupby('Sex')['Age'].mean()
上述代码的意思是按照Sex列进行分组,然后计算每个组的年龄平均值。计算结果如下:
Sex
0 30.505824
1 28.216730
0
Name 0
Sex 0
Age 0
非常棒!我们在没有删除任何行的情况下,解决了缺失值问题。
[外链图片转存中...(img-szGoUSi7-1681435672192)]
有了以上数据集,我们就可以回答更复杂的问题。比如,男性或女性的平均年龄分别是多少?我们可以先按性别进行筛选,再计算平均值。Pandas由内置函数做这件事情,叫做groupby,用法如下:
```python
titanic.groupby('Sex')['Age'].mean()
上述代码的意思是按照Sex列进行分组,然后计算每个组的年龄平均值。计算结果如下:
Sex
0 30.505824
1 28.216730