【Transformer系列(1)】encoder(编码器)和decoder(解码器)

前言
这个专栏我们开始学习transformer,自推出以来transformer在深度学习中占有重要地位,不仅在NLP领域,在CV领域中也被广泛应用,尤其是2021年,transformer在CV领域可谓大杀四方。
在论文的学习之前,我们先来介绍一些专业术语。本篇就让我们先来认识一下encoder和decoder吧!

目录
一、encoder
1.1 简介
1.2 代码实现
1.3 transformer中的使用
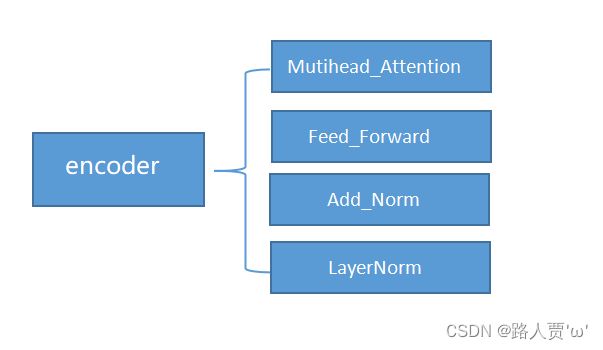
1.3.1 transformer中encoder的组成
1.3.2 每个Block的组成
1.3.3 每个Block 中的具体实现步骤
二、decoder
2.1 简介
2.2 代码实现
2.3 transformer中的使用
2.3.1transformer中decoder的组成
2.3.2 transformer中encoder和decoder的区别
2.3.3 Masked self attention模块
2.3.4 Cross attetion模块
2.3.5 具体实现步骤
三、encoder-decoder
3.1 简介
3.2 代码实现
3.3 注意问题

一、encoder
1.1 简介
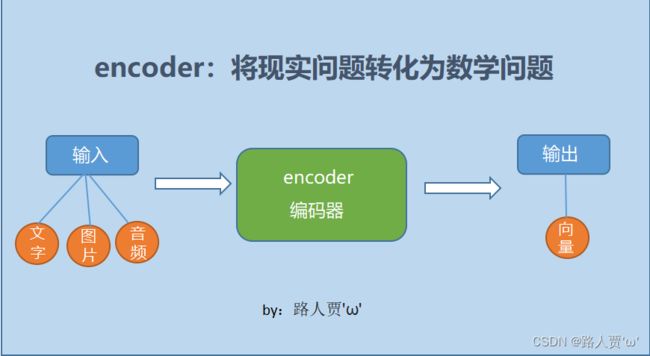
encoder,也就是编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,然后进行编码,或进行特征提取(可以看做更复杂的编码)。
简单来说就是机器读取数据的过程,将现实问题转化成数学问题。如下图所示:
1.2 代码实现
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。 任何继承这个encoder 基类的模型将完成代码实现。
class encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
x += self.positional_encoding(x.shape[1],config.d_model)
# print("After positional_encoding: {}".format(x.size()))
output = self.add_norm(x,self.muti_atten,y=x)
output = self.add_norm(output,self.feed_forward)
return output
Mutihead_Attention():多头注意力机制:
class Mutihead_Attention(nn.Module):
def __init__(self,d_model,dim_k,dim_v,n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model,dim_k)
self.k = nn.Linear(d_model,dim_k)
self.v = nn.Linear(d_model,dim_v)
self.o = nn.Linear(dim_v,d_model)
self.norm_fact = 1 / math.sqrt(d_model)
def generate_mask(self,dim):
# 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
# padding mask 在数据输入模型之前完成。
matirx = np.ones((dim,dim))
mask = torch.Tensor(np.tril(matirx))
return mask==1
def forward(self,x,y,requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# 对 x 进行自注意力
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
# print("Attention V shape : {}".format(V.shape))
attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
if requires_mask:
mask = self.generate_mask(x.shape[1])
attention_score.masked_fill(mask,value=float("-inf")) # 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASKSoftmax之前的结果就好了
output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
# print("Attention output shape : {}".format(output.shape))
output = self.o(output)
return output
Feed_Forward() : 两个Linear中连接Relu即可,目的是为模型增添非线性信息,提高模型的拟合能力。
class Feed_Forward(nn.Module):
def __init__(self,input_dim,hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.L1 = nn.Linear(input_dim,hidden_dim)
self.L2 = nn.Linear(hidden_dim,input_dim)
def forward(self,x):
output = nn.ReLU()(self.L1(x))
output = self.L2(output)
return output
Add_Norm():残差连接以及LayerNorm
class Add_Norm(nn.Module):
def __init__(self):
self.dropout = nn.Dropout(config.p)
super(Add_Norm, self).__init__()
def forward(self,x,sub_layer,**kwargs):
sub_output = sub_layer(x,**kwargs)
# print("{} output : {}".format(sub_layer,sub_output.size()))
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.size()[1:])
out = layer_norm(x)
return out
1.3 transformer中的使用
1.3.1transformer中encoder的组成
transformer 中 encoder 由 6 个相同的层组成,每个层包含 2 个部分:
- Multi-Head Self-Attention
- Position-Wise Feed-Forward Network (全连接层)

1.3.2 每个Block的组成
自注意力机制 + 残差链接 + LayerNorm + FC + 残差链接 + layer Norm此时的输出 = 一个 Block 的输出;
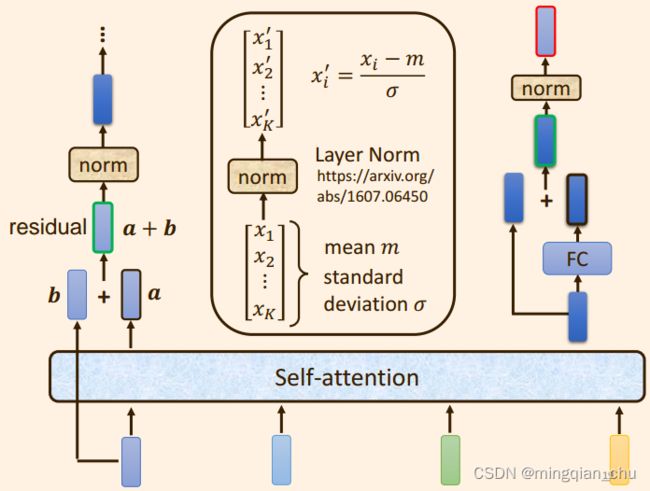
1.3.3 每个Block 中的具体实现步骤
(1)原始的输入向量b 与输出向量a残差相加,得到向量a+b;
【注意】 b是原始的输入向量,下图中输出向量a是考虑整个序列的输入向量得到的结果

(2)将向量 a+b 通过 Layer Normation 得到向量c ;
也就是下图左边部分: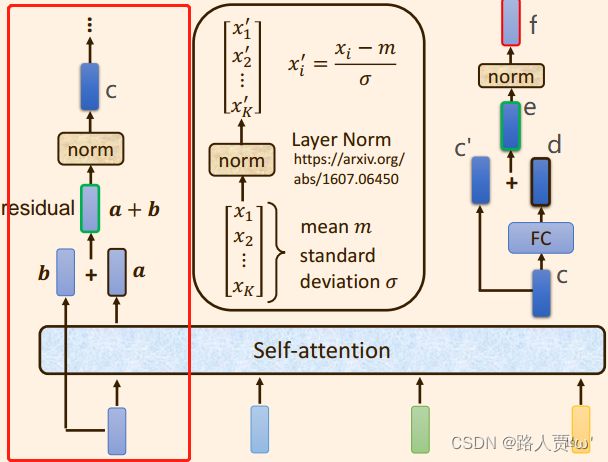
(3)将向量c 通过 FC layer 得到向量d ;
(4)向量c 与向量d 残差相加 ,得到向量e ;
(5)向量e 通过 Layer Norm 输出 向量f;
(6)此时得到的输出向量f 才是 encoder中每个Block中的一个输出向量;
以上步骤就是下图右边部分:
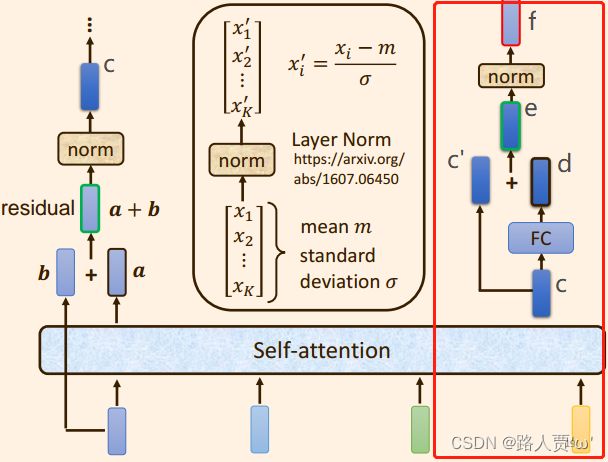
上述步骤,便是原始论文transformer中encoder的设计啦~
二、decoder
2.1 简介
decoder,也就是解码器,负责根据encoder部分输出的语义向量c来做解码工作。以翻译为例,就是生成相应的译文。
简单来说,就是就数学问题,并转换为现实世界的解决方案。
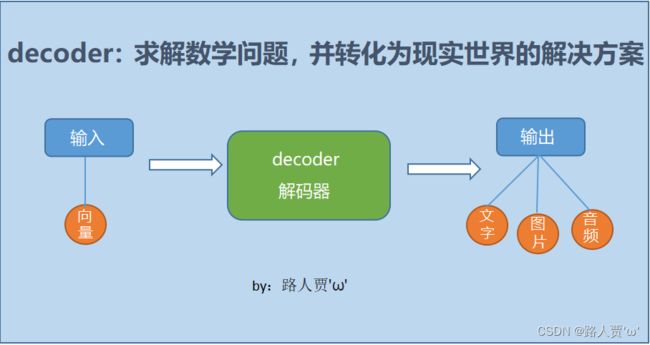
【注意】生成的序列是不定长的。而且上一时刻的输出通常要作为下一时刻的输入。
2.2 代码实现
在上面1.2encoder的代码实现中,我们已经实现了大部分decoder的模块。
但是encoder和decoder实现还是有区别的:
- decoder的Muti_head_Attention引入了Mask机制
- decoder与encoder中模块的拼接方式不同
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
# print(x.size())
x += self.positional_encoding(x.shape[1],config.d_model)
# print(x.size())
# 第一个 sub_layer
output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
# 第二个 sub_layer
output = self.add_norm(output,self.muti_atten,y=encoder_output,requires_mask=True)
# 第三个 sub_layer
output = self.add_norm(output,self.feed_forward)
return output
2.3 transformer中的使用
2.3.1transformer中decoder的组成
在transformer中decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
- Multi-Head Self-Attention
- Multi-Head Context-Attention
- Position-Wise Feed-Forward Network

2.3.2 transformer中encoder和decoder的区别
我们先来看看这个图

(1)第一级中: 将self attention 模块加入了Masked模块,变成了 Masked self-attention, 这样以来就只考虑解码器的当前输入和当前输入的左侧部分, 不考虑右侧部分; ( 注意,第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。)
(2)第二级中:引入了 Cross attention 交叉注意力模块, 在 masked self-attention 和全连接层 之间加入;
(3)Cross attention 交叉注意力模块的输入 Q,K,V 不是来自同一个模块,K,V 来自编码器的输出, Q来自解码器的输出;
【注意】 解码器的输出一个一个产生的
2.3.3 Masked self attention模块

举个栗子吧~以翻译为例:
- 输入:我是路人贾
- 输出: I am Jia
由上一节可知,输入“我是路人贾”这一步是在encoder中进行了编码,那么这里我们具体讨论decoder的操作,也就是加了 Masked self attention模块后如何得到输出(“I am Jia”)的过程。
第1步:
- 初始输入: 起始符 + Positional Encoding(位置编码)
- 中间输入:(我是路人贾)Encoder Embedding
- 最终输出:产生预测“I”
第2步:
- 初始输入:起始符 + “I”+ Positonal Encoding
- 中间输入:(我是路人贾)Encoder Embedding
- 最终输出:产生预测“am”
第3步:
- 初始输入:起始符 + “I”+ “Love”+ Positonal Encoding
- 中间输入:(我是路人贾)Encoder Embedding
- 最终输出:产生预测“Jia”
其实这个原理很简单,主要想表达的就是因为变成了Masked self attention ,所以只考虑输入向量本身, 和输入向量的之前的向量,即左侧向量,而不去考虑后边(右侧)向量。
另外,求相关性的分数时,q,k ,v 同样的也只会考虑当前输入向量的左侧向量部分,而不去考虑输入向量后面的右侧部分。
这里介绍一下论文在Decoder的输入上,对Outputs的Shifted Right操作。
Shifted Right 实质上是给输出添加起始符/结束符,方便预测第1个Token/结束预测过程。
还是看看我们上一个栗子~
正常的输出序列位置关系如下:
- 0-"I"
- 1-"am"
- 2-"Jia"
但在执行的过程中,我们在初始输出中添加了起始符,相当于将输出整体右移1位(Shifted Right),所以输出序列变成如下情况:
- 0-【起始符】
- 1-“I”
- 2-“am”
- 3-“Jia”
这样我们就可以通过起始符预测“I”,也就是通过起始符预测实际的第1个输出啦。

2.3.4 Cross attetion模块
Cross attetion模块称为交叉注意力模块,是因为向量 q , k , v 不是来自同一个模块。
而是将来自解码器的输出向量q 与来自编码器的输出向量 k , v运算。
具体讲来:
向量 q 与向量 k之间相乘求出注意力分数α1 '
注意力分数α1 '再与向量 v 相乘求和,得出向量 b (图中表示为向量 v ) ;
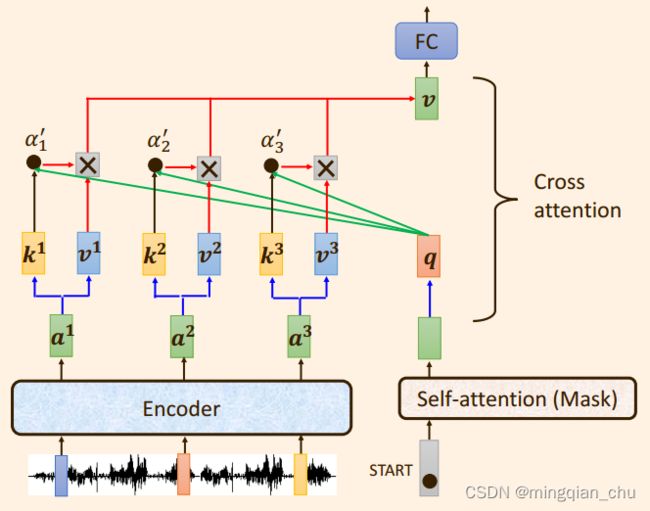
2.3.5 具体实现步骤
(1)经过 Masked self attention:
解码器之前的输出作为当前解码器的输入,并且训练过程中真实标签的也会输入到解码器中,此时这些输入, 通过一个Masked self-attention ,得到输出q向量,注意到这里的q是由解码器产生的;
(2)经过 Cross attention:
将向量q 与来自编码器的输出向量 k , v 运算。具体讲来就是向量 q 与向量 k之间相乘求出注意力分数α1 ',注意力分数α1 '再与向量 v 相乘求和,得出向量 b ;
(3)经过全连接层:
之后向量 b 便被输入到feed−forward 层, 也即全连接层, 得到最终输出;
上述步骤,便是原始论文transformer中decoder的设计啦~
三、encoder-decoder
刚才已经分别了解了encoder和decoder,接下来我们再来看看encoder-decoder这个框架吧。
3.1 简介
encoder-decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。encoder-decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
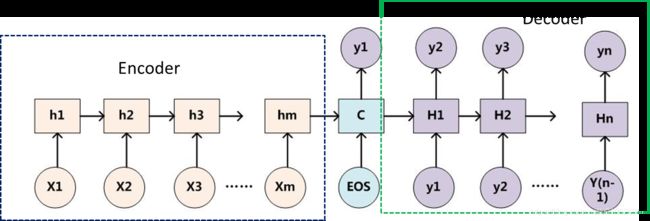
其实整个过程我们可以看做是一个游戏——《你画我猜》。玩家1从系统中抽取拿到题卡,然后通过画画的方式描述该词。玩家2就通过画来猜出题目中的词是什么东东。我们拿目前应用最深入的机器翻译问题举个栗子:
(毕贾索已上线~)

就酱就酱~大家懂就行~
3.2 代码实现
encoder-decoder框架包含了一个编码器和一个解码器,并且还拥有可选的额外的参数。在前向传播中,编码器的输出用于生成编码状态,这个状态又被解码器作为其输入的一部分。
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
3.3 注意问题
- 不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
- encoder-decoder的一个显著特征就是:它是一个end-to-end的学习算法。
- 只要符合这种框架结构的模型都可以统称为encoder-decoder模型。
本文参考:
李宏毅机器学习
