网络数据库挖掘程序的设计
现在很多网页都是由数据库自动生成的,数据分散在html代码之中:有的位于URL链接中,有的位于<td></td>之中,有的位于javascript代码之中.如何挖掘这些数据为我所用?小的不才,最近写了一个网络数据库挖掘程序,挖掘了几千万条数据.源代码不能公开,这里简单述说一下设计思路和基本结构吧.
本来是用.net写的,写了几天,因为找不到好的c#的html解析器,最后还是改成了java.在这里,我尽量从语言中性的角度来解释设计思路和关键点所在,就算是小项目分析吧,供大家参考.
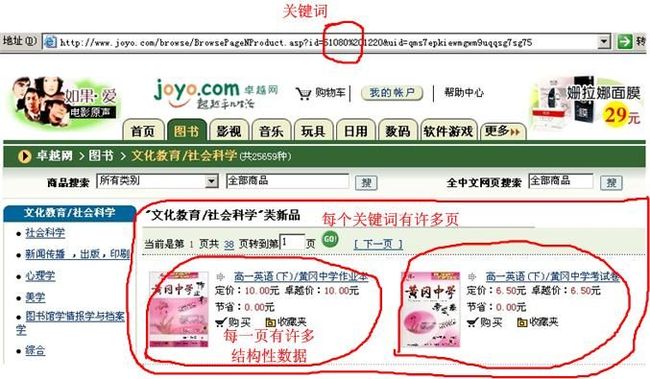
设计目的:解析类如 http://xxx.xxx.xxx.xxx/xxx.xxxx?xxxxx={keyword}&xxxx=xxxx&xxxxxx={page}&xxxxxxx之类的网页.
1,根据id或keyword由数据库动态生成
2,每id或keyword针对1页或多页页面,可以通过翻页来浏览.翻页逻辑体现在url或内部html代码中.
3,每一页面有1条或多条数据,每条数据可根据一定的字符串模式匹配.
差不多大部分网络数据库都有这些特点,下面是一个例子:
软件结构如下图:
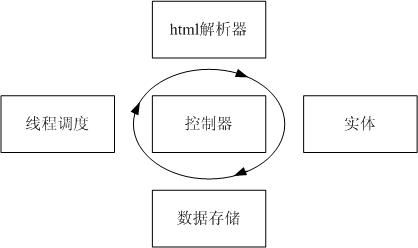
各部分角色如下:
(1) 控制器:调度线程,轮询线程,调度html解析器,抽取数据生成实体,调度数据接入逻辑,控制关键词生成逻辑,控制翻页逻辑
(2) 线程调度:生成线程,中止线程.
(3) html解析器:指定URL地址,负责获取页面,把页面解析成相应的NodeList.
(4) 实体:实体类,体现了实体逻辑.
(5) 数据存储:将已经获得的实体数据存储入数据库
下面逐一介绍,控制器逻辑最复杂,放在最后.
(1) html解析器
html解析器我找的是开源实现.找到几个.net的html parser,老感觉不好用.接着又找java的,先找到了JSpider,看了几天,觉得不能满足我的需求,最后找到htmlParser,决定用这个.
用到的htmlParser功能很简单:给出一个URL地址,生成一个parser,parser访问页面,根据过滤器类型,解析成一个个的NodeList,如,包含<td>节点的NodeList,包含link的NodeList........使用很简单.
2
3
htmlParser可以设置cookies.
因为htmlParser是调用block IO,所以需要在虚拟机上设置ConnectTimeout和ReadTimeout,不设置的话,一旦网络慢下来,总会有几个线程在傻等.我觉得都设置为30秒比较合适.
(2) 实体
因为我要用OR-Mapping,所以就单独提取一个实体层出来.根据要挖掘的数据类型可构造出实体类. 这个就不详说了.
(3) 数据存储
采用OR-Mapping. 对于网络数据库,所设计的数据表的个数不多,于是偶将数据库访问逻辑再封装在类DatabaseHelper中.DatabaseHelper作为数据层的Facade,所有上层数据访问必须通过DatabaseHelper进行.
DatabaseHelper有一个静态变量 private static boolean DEBUG = false; (c#格式: private static bool DEBUG = false)另外有一个方法:
2
3
4
调用DatabaseHelper.Debug()方法可以将DatabaseHelper设置为调试状态,所有读取数据库操作照常,只是不进行实质性的写入数据库操作.开发过程中因为要经常调试,为了不污染数据库,特意设计这个东东.
(4) 线程调度
采用Worker Thread模式.见偶的blog <调度模式·Worker-Channel-Request>. 控制器不断的向channel中放入Request, 工作线程获取并执行Request.
(5) 控制器
控制器由6个重要接口IDispatcher, IDispatcheHelper, ISpider, ISpiderHelper, IHandler, IDigger组成.每一个接口有对应的抽象类骨架,分别为: Dispatcher, DispatcheHelper, Spider, SpiderHelper, Handler, Digger. 带helper的都是可能调用DatabaseHelper的类.
下面详细介绍这些接口和基础类的功能:
- IDispatcher 与Dispatcher:
IDispatcher主要有dispatch(),dispatch(Object key), registAfterCrawled(ISpider spider)三个方法. 运行dispatch(),则默认扫表网络数据库的所有的keywords, dispatch(Object key)只扫描数据库的指定的keyword.
针对每个keyword, Dispatcher将产生相应的ISpider,ISpider扫描完毕后通过registAfterCrawled(ISpider spider)通知Dispatcher.
具体的指派逻辑在Dispatcher中实现.主要逻辑如下:
(a) 通过IDispatcheHelper获得需要指派给Spider的keywords(存入ElementsSet)和以往已指派抓取完毕的keywords(存入DispatchedSet).
(b) 通知Channel,开启全部工作线程.Dispatcher的构造函数Dispatcher(int threadCount),可指定开启的工作线程数.
(c) 再产生一个轮询线程,逐一轮询工作线程,查看线程执行状态.
(d) 遍历ElementsSet,对于其中的keyword,如果不在DispatchedSet之中,则指派keyword进行扫描
(e) 对于指派的keyword,产生一个Spider,包装成Request,放入Channel中,供工作线程执行.
(e) 如果没有需要调度Request,则通知Channel,没Request了,工作线程执行完Channel上的Requests后自动中止.
- IDispatchHelper与DispatchHelper
IDispatchHelper的主要方法是getDispatchedSet()和getElementsSet(),获得需要指派给Spider的keywords(存入ElementsSet)和以往已指派的keywords(存入DispatchedSet). IDispatchHelper还有两个方法: isDispatched(Object key)和commit(Object key), 前一个用来查询某个keyword是否已指派抓取完成,后一个主要是供Dispatcher调用,在指派完一个Spider,Spider完成后通过调用registAfterCrawled,向ElementsSet中注册,表明已指派完该keyword.
getDispatchedSet()和getElementsSet(),可以从数据库中生成, 也可以从文件中读取,也可以是根据某些逻辑条件生成.
- ISpider, Spider , ISpiderHelper与SpiderHelper
ISpider与Spider的角色是根据指定的keyword,获取该keyword的所有查询页面的数据,生成实体,并存储入数据库. Spider包装在Request中,一个线程一次只能调用一个Request,也就是一个线程一次只能执行一个Spider.
ISpider的主要方法是crawl(),负责所有的爬行逻辑和后续操作,具体逻辑封装在. Spider之中.
1个Spider拥有1个SpiderHelper和1个Handler. SpiderHelper主要作用是(1)从数据库中获取该keyword已经抓取的纪录CrawledSet(因为可能由于网络原因,有的Spider抓了一半,就停止了,但数据库中已经抓了不少纪录);(2) 通过dump(digger)将digger抓取的数据存储入数据库.Hander的作用是(1)判断是否还有下一页,(2)构建当前页的URL,根据URL产生Parser,由Parser产生Digger.
crawl()的代码骨干如下:
2
3
4
5
this.helper.saveRecord() 作用更新数据库中数据 , 表明该 keyword 对应数据已经抓取完毕 . 这样 , 当再次运行程序 , IDispatchHelper. getElementsSet() 就不会包含该 Spider 所对应的 keyword 了 .
- IHandler, Handler
IHandler 的主要方法是IDigger.next(),获得下一页所对应的IDigger.不存在则返回null.
Hander有几个主要的抽象方法: 根据页数构造URL--buildUrlString(int pageage), 根据所构造的URL构造Parser--buildParser(), 根据Parser构造Digger--buildDigger().
IHandler .next()根据Parser所返回来的NodeList判断是否存在下一个页面(具体的判断逻辑由具体类实现),如果有则根据下一页的页数,重新一次调用buildUrlString(int pageage), buildParser(),buildDigger(),返回IDigger.
- IDigger 与 Digger
IDigger 与 Digger主要作用是分析Parser所抓获解析所得的页面NodeList,解析成实体对象.
IDigger的主要方法是获取实体--ArrayList dig()和获取当前页面的URL--String getUrlString().Digger提供了protected NodeList getTdList(),protected NodeList getLinkList(),...........等方法,供具体类调用. 具体的解析逻辑就在Digger的具体类中的实现了.
进一步的做法是从中提出一般性框架出来,然后还需要一套规则体系.就看有没时间了.:P
网络数据挖掘分类
网络数据挖掘形式多样。根据不同的网络数据挖掘对象,人们将网络数据挖掘分为网络内容挖掘(Webcontentmining)、网络结构挖掘(Webstructuremining)以及网络用法挖掘(Webusagemining)。
(1)网络信息内容是由文本、图像、音频、视频、元数据等形式的数据组成的。网络内容挖掘就是一个从网络信息内容中发现有用信息的过程。由于网络信息内容有很多是多媒体数据,因此网络内容挖掘也将是一种多媒体数据挖掘形式。
(2)网络结构挖掘就是挖掘Web潜在的链接结构模式。通过分析一个网页链接和被链接数量以及对象来建立Web自身的链接结构模式。这种模式可以用于网页归类,并且由此可以获得有关不同网页间相似度及关联度的信息。网络结构挖掘有助于用户找到相关主题的权威站点。
(3)网络用法挖掘、网络内容挖掘和网络结构挖掘的挖掘对象是网上的原始数据,而网络用法挖掘面对的则是在用户和网络交互的过程中抽取出来的第二手数据,包括网络服务器访问记录、代理服务器日志记录、浏览器日志记录、用户简介、注册信息、用户对话或交易信息、用户提问方式等。通过网络用法挖掘,可以了解用户的网络行为数据所具有的意义。