大数据项目---电商数仓(二)
一.Azkaban_工作流程安排
二.Azkaban_部署_executor
三.Azkaban_部署_web
四.Azkaban_部署_启停脚本
五.Sqoop_导出事项
六.Sqoop_Mysql建表注意事项
七.Sqoop_导出脚本说明
八.Azkaban_全流程调度_数据准备
九.Azkaban_全流程调度_flow文件的编写上传(一)
十.Azkaban_全流程调度_flow文件的编写上传(二)
十一.Azkaban_问题总结
十二.Hive问题的查找
十三.Flume_HDFS_Event
十四.可视化展示_Superset_概述
十六.可视化展示_Miniconda常用的使用
十七.可视化展示_创建Python环境
十八.可视化展示_部署
十九.可视化展示_启动Supterset
二十.可视化展示_停止superset
二十一.可视化展示_安装数据库依赖
二十二.可视化展示_对接数据源
二十三.可视化展示_配置图表
二十四.可视化展示_配置仪表盘
二十五.可视化展示_地图
二十六.可视化展示_饼状图
一.Azkaban_工作流程安排

目前已经完成的工作流程:

数据仓库并不是我们想要的最后的东西,我们需要ads层的数据导入到mysql之中,为什么不是导入到hive之中,因为hive的延迟实在是太低了.
二.Azkaban_部署_executor
首先是Azkaban的安装,首先是将Azkaban进行解压,然后是进行相应的创建出来.
①然后是将上面的东西使用mysql进行创建;
mysql -uroot -p123456
create database azkaban
use database azkaban
source create-all-sql-3.84.4.sql
为了防止Azkaban发生阻塞,需要修改一个参数,将相应的参数进行修改得到
进入mysql的配置文件:sudo vim /etc/my.cnf
max_allowed_packet=1024M
重新启动mysql:sudo systemctl restart mysqld
②部署executor
Azkaban的部署分类:单机版只能是布置一个executor,多机版配置多个executor.
进入配置文件之中:/opt/module/azkaban/azkaban-exec/conf
vim azkaban.properties
进入编辑者模式:set nu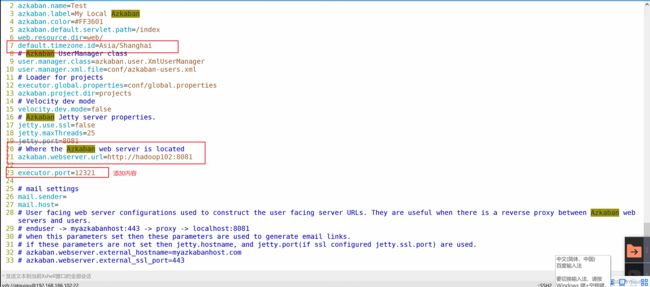
 分发部署:rsync.sh /opt/module/azkaban/azkaban-exec/
分发部署:rsync.sh /opt/module/azkaban/azkaban-exec/
③进入到相应的路径之下进行启动部署
bin/start-exec.sh
同理,在相应的hadoop103,hadoop104之中也是需要进入到相应的路径之中进行启动,
如何查看是否启动成功,在相应的路径之中查看是否存在.port文件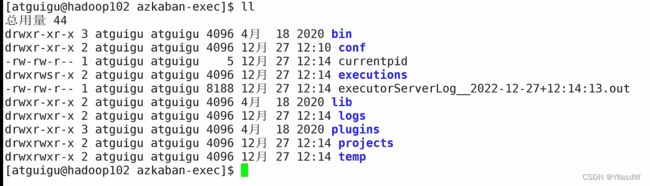
可以看到我的就是启动失败了,需要查找相应的错误.
$ tail -500 executorServerLog__2022-12-27+12\:14\:13.out
重新进入到相应的配置文件之中,看一看我的是不是配置错误了.
果然是我的这个地方写错了,然后进行相应的修改,改正之后发现还是有错.
我就将里面的密码进行了修正,之后将进行使用kill进行杀死.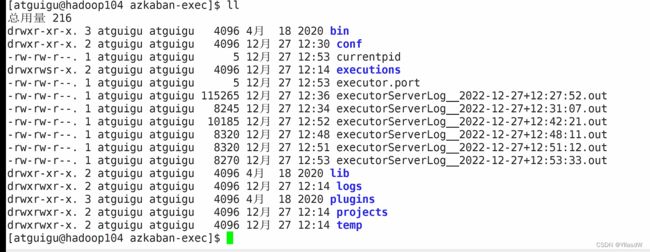
出现.port文件说明正常运行了.
另外一种进行验证的方式是用sql进行连接.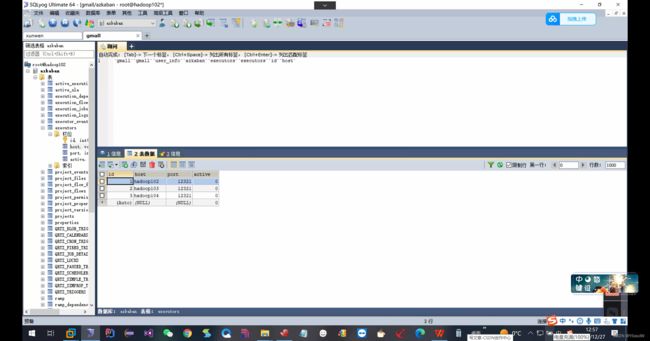
可以见到是正常运行的,只有在执行相应的激活命令之后,active才能变成为1.
[hadoop102 azkaban-exec]curl -G "hadoop102:12321/executor?action=activate" && echo
[hadoop103 azkaban-exec]curl -G "hadoop103:12321/executor?action=activate" && echo
[hadoop104 azkaban-exec]curl -G "hadoop104:12321/executor?action=activate" && echo 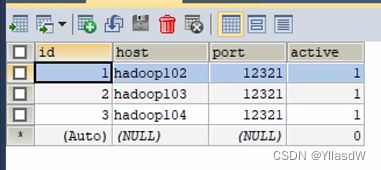
激活成功.
三.Azkaban_部署_web
上述的executor在三台机器上都是存在的,但是web server只是存在于hadoop102上面.
这个地方是对于azkaban-web的修改过程,首先是进入到相应的azkaban.properties之中,然后是将相应的属性进行修改.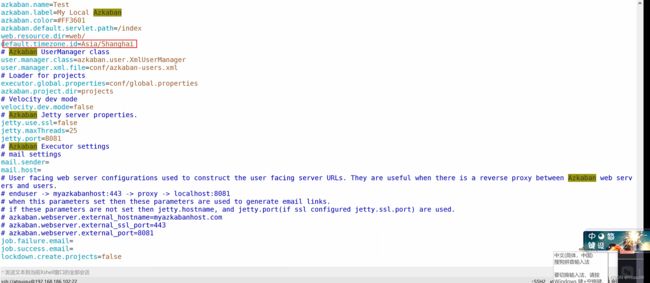
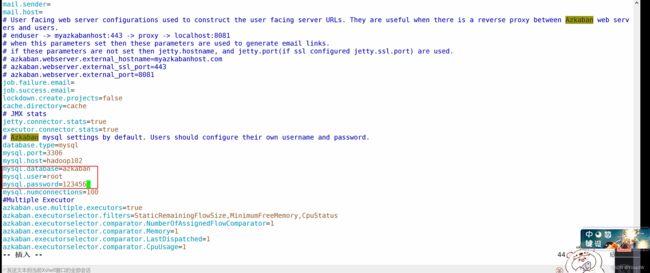
首先是交给executor进行相应的调度,之后是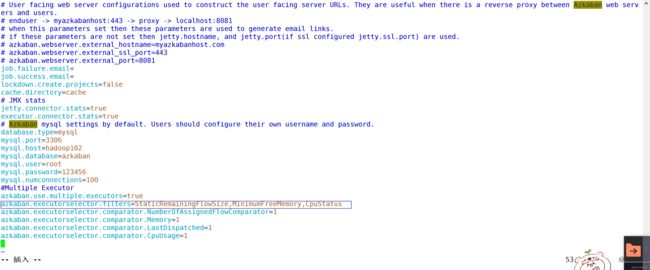
首先是选择最空闲的,然后是进行选择相应的最小的内存的,最后是选择最小的内存.这里我们将最小的内存限制去除掉.
vim azkaban-users.xml
文档之中一些名词的解释:role是权限的集合,perssion权限 
上面是对于一些权限的修改过程,创建一个新的用户.
需要进入到相应的/opt/module/azkaban/azkaban-web路径之中进行相应的查询启动.
bin/start-web.sh
进入相应的端口号查看配置:hadoop102:8081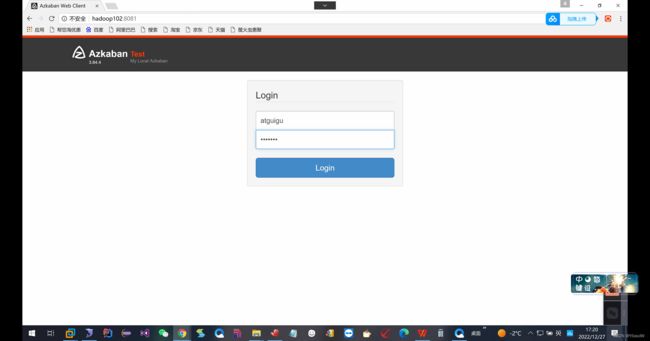
就是上面的这个界面.
四.Azkaban_部署_启停脚本
azkaban群起群停脚本,这个脚本是我在网上查到的,应该是可以用的,代码是如下所示:
azkaban.sh
#!/bin/bash
start-web(){
for i in hadoop102;
do
ssh $i "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"
done
}
stop-web(){
for i in hadoop102;
do
ssh $i "cd /opt/module/azkaban/azkaban-web;bin/shutdown-web.sh"
done
}
start-exec(){
for i in hadoop102 hadoop103 hadoop104;
do
ssh $i "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh"
done
}
activate-exec(){
for i in hadoop102 hadoop103 hadoop104;
do
ssh $i "curl -G "$i:12321/executor?action=activate" && echo"
done
}
stop-exec(){
for i in hadoop102 hadoop103 hadoop104;
do
ssh $i "/opt/module/azkaban/azkaban-exec/bin/shutdown-exec.sh"
done
}
case $1 in
start-exec)
start-exec;;
activate-exec)
activate-exec;;
stop-exec)
stop-exec;;
start-web)
start-web;;
stop-web)
stop-web;;
esac
进行相应的测试,如下所示:没有问题
五.Sqoop_导出事项

这个过程是使用的sqoop的双向传输我们将数据从别的地方导入hadoop之中,这个过程我们称为导入(import).,反之是导出(export).导入的过程是可以到hdfs,hbase,hive,导出仅仅支持在hdfs之中的一个路径下的文件导出到mysql的一张表之中.
使用sqoop的时候,需要注意到相应的字段应当是一致的.
六.Sqoop_Mysql建表注意事项
首先是在相应的mysql之中创建一个新的数据表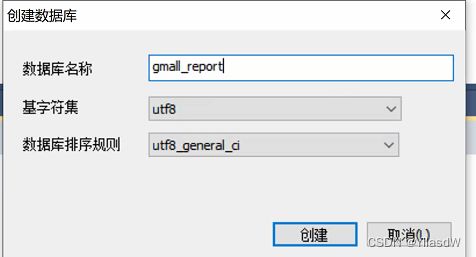
然后就是在相应的里面创建新的表,直接在gui工具之中创建.
在hadoop102之中进入到相应的mysql之中,进行创建的过程
DROP TABLE IF EXISTS `ads_user_topic`;
CREATE TABLE `ads_user_topic` (
`dt` date NOT NULL,
`day_users` bigint(255) NULL DEFAULT NULL,
`day_new_users` bigint(255) NULL DEFAULT NULL,
`day_new_payment_users` bigint(255) NULL DEFAULT NULL,
`payment_users` bigint(255) NULL DEFAULT NULL,
`users` bigint(255) NULL DEFAULT NULL,
`day_users2users` double(255, 2) NULL DEFAULT NULL,
`payment_users2users` double(255, 2) NULL DEFAULT NULL,
`day_new_users2users` double(255, 2) NULL DEFAULT NULL,
PRIMARY KEY (`dt`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;DROP TABLE IF EXISTS `ads_area_topic`;
CREATE TABLE `ads_area_topic` (
`dt` date NOT NULL,
`id` int(11) NULL DEFAULT NULL,
`province_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`area_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`iso_code` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`region_id` int(11) NULL DEFAULT NULL,
`region_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`login_day_count` bigint(255) NULL DEFAULT NULL,
`order_day_count` bigint(255) NULL DEFAULT NULL,
`order_day_amount` double(255, 2) NULL DEFAULT NULL,
`payment_day_count` bigint(255) NULL DEFAULT NULL,
`payment_day_amount` double(255, 2) NULL DEFAULT NULL,
PRIMARY KEY (`dt`, `iso_code`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
可以见到创建成功了.
七.Sqoop_导出脚本说明
1)编写Sqoop导出脚本
在/home/atguigu/bin目录下创建脚本hdfs_to_mysql.sh
脚本之中添加的代码如下所示:
#!/bin/bash
hive_db_name=gmall
mysql_db_name=gmall_report
export_data() {
/opt/module/sqoop-1.4.6/bin/sqoop export \
-Dmapreduce.job.queuename=hive \
--connect "jdbc:mysql://hadoop102:3306/${mysql_db_name}?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$hive_db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-mode allowinsert \
--update-key $2 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_uv_count")
export_data "ads_uv_count" "dt"
;;
"ads_user_action_convert_day")
export_data "ads_user_action_convert_day" "dt"
;;
"ads_user_topic")
export_data "ads_user_topic" "dt"
;;
"ads_area_topic")
export_data "ads_area_topic" "dt,iso_code"
;;
"all")
export_data "ads_user_topic" "dt"
export_data "ads_area_topic" "dt,iso_code"
#其余表省略未写
;;
esac关于导出update还是insert的问题
- --update-mode:
updateonly 只更新,无法插入新数据
allowinsert 允许新增
- --update-key:允许更新的情况下,指定哪些字段匹配视为同一条数据,进行更新而不增加。多个字段用逗号分隔。
- --input-null-string和--input-null-non-string:
分别表示,将字符串列和非字符串列的空串和“null”转义。
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
八.Azkaban_全流程调度_数据准备
造出数据,跑一下每一天的流程过程.
这个地方由于我前面看的课程和这个是不一样的,这个地方我用的有一个dt.sh的使用,就是将相应的时间进行一个生成,我在网上查到一个博客是这样写的,不过这里我的数据是生成的2020-6-16.大数据项目重温——电商数据仓库(三)数据采集模块(中)_Moody丶的博客-CSDN博客9、数据采集模块(三).日志生成(1).日志启动1)代码参数说明// 参数一:控制发送每条的延时时间,默认是0 Long delay = args.length > 0 ?Long.parseLong(args[0]) : 0L;// 参数二:循环遍历次数 int loop_len = args.length > 1 ?Integer.parseInt(args[1])...https://blog.csdn.net/yw1441776254/article/details/97150155
首先是生成一下相应的日志数据
就是很正常的操作,f1.sh start f2.sh start 进入到applog之中修改一下数据日期,log.sh生成数据.
f2.sh stop,f1.sh stop,kafka.sh stop需要注意这里的kafka关闭之后需要调用xcall.sh jps,看一看是不是彻底关掉了相应的kafka,因为关闭kafka是需要一定的时间的.之后,zk.sh stop.
生成一下相应的业务数据.
首先是进入到相应的数据源库之中修改相应的日期,cd /opt/module/db_log/,修改好里面的日期数据之后,直接执行相应的java -jar gmall2020-mock-db-2021-01-22.jar.
这时候在mysql之中查看是否在相应的表之中出现16号的订单.
可以见到是存在相应的16号的数据的,因此,这里的操作是正确的.
九.Azkaban_全流程调度_flow文件的编写上传(一)
创建文件
此刻我们需要上传一个工作流程的文件,类似如下所示:
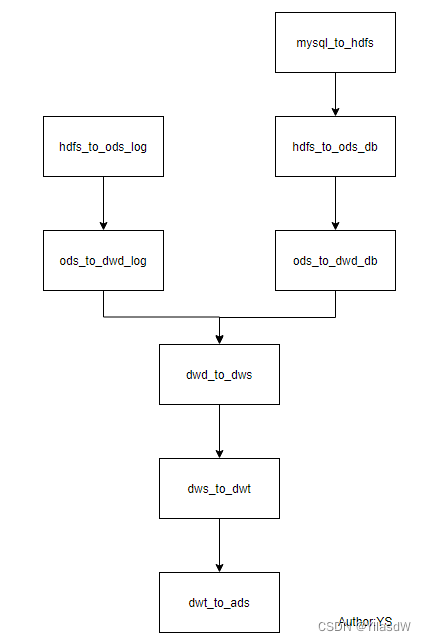
1)编写azkaban.project文件,内容如下
azkaban-flow-version: 2.0上面我们使用的zakaban的版本是3.84版本,但是我们描述工作流程的版本是使用的2.0版本进行的工作流程的描述.
2)编写gmall.flow文件,内容如下
nodes:
- name: mysql_to_hdfs
type: command
config:
command: /home/atguigu/bin/mysql_to_hdfs.sh all ${dt}
- name: hdfs_to_ods_log
type: command
config:
command: /home/atguigu/bin/hdfs_to_ods_log.sh ${dt}
- name: hdfs_to_ods_db
type: command
dependsOn:
- mysql_to_hdfs
config:
command: /home/atguigu/bin/hdfs_to_ods_db.sh all ${dt}
- name: ods_to_dwd_log
type: command
dependsOn:
- hdfs_to_ods_log
config:
command: /home/atguigu/bin/ods_to_dwd_log.sh ${dt}
- name: ods_to_dwd_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dwd_db.sh all ${dt}
- name: dwd_to_dws
type: command
dependsOn:
- ods_to_dwd_log
- ods_to_dwd_db
config:
command: /home/atguigu/bin/dwd_to_dws.sh ${dt}
- name: dws_to_dwt
type: command
dependsOn:
- dwd_to_dws
config:
command: /home/atguigu/bin/dws_to_dwt.sh ${dt}
- name: dwt_to_ads
type: command
dependsOn:
- dws_to_dwt
config:
command: /home/atguigu/bin/dwt_to_ads.sh ${dt}
- name: hdfs_to_mysql
type: command
dependsOn:
- dwt_to_ads
config:
command: /home/atguigu/bin/hdfs_to_mysql.sh all脚本注意事项,这里是yml文件,它是区分大小写的,根据缩进表示递进关系,只能使用空格描述,不能够使用相应的tab快捷键描述相应的递进关系.将上述的两个文件变成一个压缩包.
上传.
十.Azkaban_全流程调度_flow文件的编写上传(二)
点击相应的executorflow,发现会出现自己做好的那个流程图.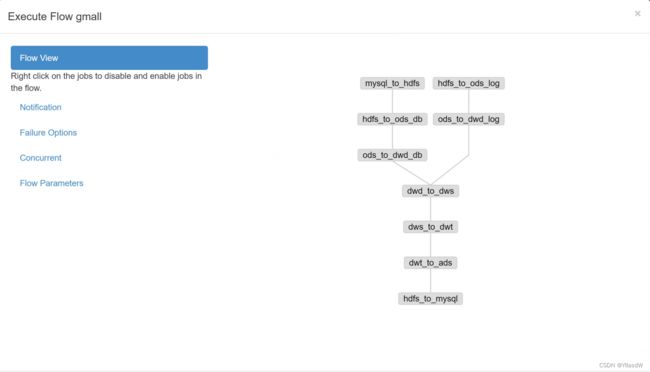
选择schedule,设定相应的跑定时间.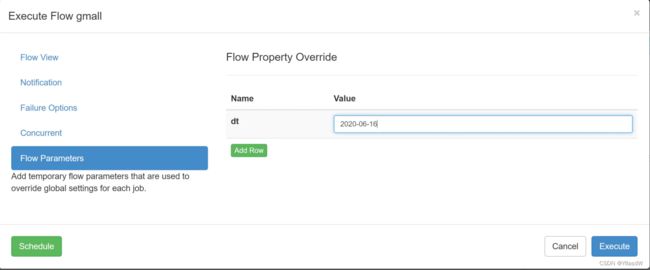
上面的描述过程是进行定时调度的过程,如果要是想要使用自己调度的过程,那么这里的value就是空着就是可以的,然后点击schedule进行设定相应的时间.
可以见到hadoop102之中的地方是4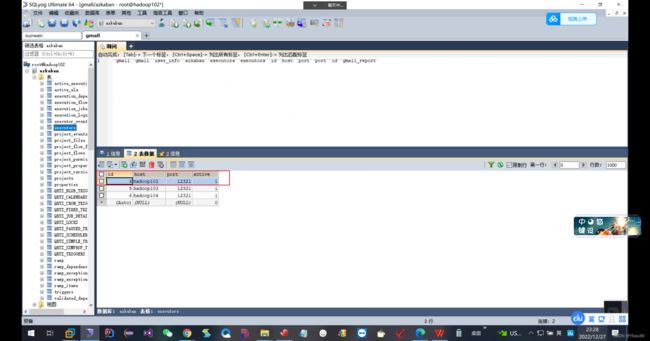

上面的日期改成2020-6-16,多加了一个0出现了问题. 正常执行之中.
正常执行之中.
十一.Azkaban_问题总结
sqlyog显示的时候将限制行关掉.
十二.Hive问题的查找
在相应的客户端出现了相应的问题,我们是在这个路径下面进行查找相应的问题的。
这个路径下方是存在一个相应的hive.log的。
查找相应的错误的方式是使用tail -500 hive.log
如果这个地方还是没有相应的明显的错误,这个时候我们只能够在相应的yarn上进行相应的查看。
hadoop103:8088,在开启相应的历史服务器之后进行相应的错误的寻找,history之中进行相应的寻找.
注意在hive on Spark和Spark是一样的.
十三.Flume_HDFS_Event
hadoop104之中的flume的HDFS的配置是用来配置写到HDFS之中的.
数据上传到相应的HDFS之中,后面会进行相应的一个时间的转换,%Y-%m-%d会转换成为相应的具体的年月日,转换成为什么样子的值,是由相应的header确定的.
默认的情况下,载相应的Flume的Event之中是不存在timestamp的,因此使用这个转义序列必须要记性使用header的,但是相应的Kafka Source会自动为其添加一个header的,value是当前的系统时间戳.所以,如果不认为加拦截器去修改timestamp,那么%Y-%m-%d最终就会和系统时间保持一致.
如果要是添加如下的拦截器,获取日志之中的时间戳,作为该header的值,就能够保证其与%Y-%m-%d和在application.properties配置的mock.date保持一致,就不用修改系统时间了.
如果要是不进行添加相应的拦截器,可能会出现,第一天生成的数据出现在第二天之中.
十四.可视化展示_Superset_概述
1.Apache Superset是一个开源的、现代的(基本是包含了所有的大数据的分析工具)、轻量级(使用python进行开发的)BI分析工具,能够对接多种数据源、拥有丰富的图标展示形式、支持自定义仪表盘(这里的仪表盘就是相应的大屏,上面存在各种各样的图标,我们将上面的图表看作为是相应的表盘,主要进行利用的是这个),且拥有友好的用户界面,十分易用。
这里的BI工具就是相应的进行分析的一个工具,可以将上面的东西转换成为更多的数据图表.
2.使用场景:由于Superset能够对接常用的大数据分析工具,如Hive、Kylin、Druid等,且支持自定义仪表盘,故可作为数仓的可视化工具。
十五.可视化展示_Minconda安装
1.官网地址:http://superset.apache.org/
2.环境:Superset是由Python语言编写的Web应用,要求Python3.6的环境.
电脑系统自带的环境是python2.7.5,是不符合要求的,因此我们这个地方是需要进行相应的搞定环境操作.第一种方式是卸载原来的python,安转新的python,但是这种方式是存在问题的,因为原来的系统可能是依赖与这个环境.
这里就是要提到一个Anaconda,可以创建自己想要的环境.Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。这个地方我们是不需要那么多的东西,因此,使用MiniConda就是可以的.
3.下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
将其上传到相应的/opt/software/superset之中,直接进行相应的执行就是可以的.相应代码是如下所示:bash Miniconda3-latest-Linux-x86_64.sh
注意这个过程之中可能是存在删除的东西,发现是删除不了的,这个时候就是需要按住ctrl+删除键才能够删除掉的.
上面是相应的安装路径.

安装完毕.
4.执行下面的代码过程会发现出现.bashrc,这个文件的含义一会儿再进行解释.
source之后,出现一个新的环境(base)

环境变成了3.7.4版本.
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
[atguigu@hadoop102 lib]$ conda config --set auto_activate_base false
十六.可视化展示_Miniconda常用的使用
1)配置conda国内镜像
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(base) [atguigu@hadoop102 ~]$ conda config --set show_channel_urls yes
2)创建Python3.7环境
(base) [atguigu@hadoop102 ~]$ conda create --name superset python=3.6
这个时候我们是需要进行等待一小会儿的,等待相应的配置配置成功
说明:conda环境管理常用命令
创建环境:conda create -n env_name
查看所有环境:conda info --envs
删除一个环境:conda remove -n env_name --all
3)激活superset环境
(base) [atguigu@hadoop102 ~]$ conda activate superset

十七.可视化展示_创建Python环境
注意上面进行相应的创建环境的时候是比较慢的,我们这里可以使用镜像进行相应的操作.
这里是配置的清华大学的一个镜像的过程.
十八.可视化展示_部署
1.安装依赖
(superset) [atguigu@hadoop102 ~]$ sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
这个地方一共要安装38个包,是比较慢的.我的这个地方的东西看这个地方可以见到是安装好的.
2.安装superset
1)安装(更新)setuptools和pip
(superset) [atguigu@hadoop102 ~]$ pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/
说明:pip是python的包管理工具,可以和centos中的yum类比
2)安装Supetset
(superset) [atguigu@hadoop102 ~]$ pip install apache-superset -i https://pypi.douban.com/simple/
说明:-i的作用是指定镜像,这里选择国内镜像,这里指的是pip的镜像
这个地方应当进行注意,有的时候会出现想一个的超时的现象,我们就是需要重新进行安装。
3)初始化Supetset数据库
(superset) [atguigu@hadoop102 ~]$ superset db upgrade
在进行相应的初始化的时候,我这里遇到了一个问题,就是引入库的情况。问题是如下所示: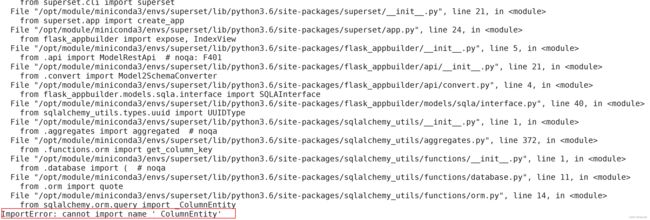
在看了一些别的博客之后,找错误,我发现是这个地方的错误。
4)创建管理员用户
(superset) [atguigu@hadoop102 ~]$ export FLASK_APP=superset
(superset) [atguigu@hadoop102 ~]$ flask fab create-admin
说明:flask是一个python web框架,Superset使用的就是flask
5)Superset初始化
(superset) [atguigu@hadoop102 ~]$ superset init
十九.可视化展示_启动Supterset
1)安装gunicorn
(superset) [atguigu@hadoop102 ~]$ pip install gunicorn -i https://pypi.douban.com/simple/
说明:gunicorn是一个Python Web Server,可以和java中的TomCat类比
2)启动Superset
第一步:确保当前conda环境为superset,及下图所示
(superset) [atguigu@hadoop102 ~]$
第二步:启动
(superset) [atguigu@hadoop102 ~]$ gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 "superset.app:create_app()" --daemon
说明:
- workers:指定进程个数
- timeout:worker进程超时时间,超时会自动重启
- bind:绑定本机地址,即为Superset访问地址
- daemon:后台运行
二十.可视化展示_停止superset
(1)停掉gunicorn进程
(superset) [atguigu@hadoop102 ~]$ ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
(2)退出superset环境
(superset) [atguigu@hadoop102 ~]$ conda deactivate
superset启停脚本
创建superset.sh文件
[atguigu@hadoop102 bin]$ vim superset.sh
#!/bin/bash
superset_status(){
result=`ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | wc -l`
if [[ $result -eq 0 ]]; then
return 0
else
return 1
fi
}
superset_start(){
# 该段内容取自~/.bashrc,所用是进行conda初始化
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/opt/module/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/opt/module/miniconda3/etc/profile.d/conda.sh" ]; then
. "/opt/module/miniconda3/etc/profile.d/conda.sh"
else
export PATH="/opt/module/miniconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
conda activate superset ; gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 --daemon 'superset.app:create_app()'
else
echo "superset正在运行"
fi
}
superset_stop(){
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
fi
}
case $1 in
start )
echo "启动Superset"
superset_start
;;
stop )
echo "停止Superset"
superset_stop
;;
restart )
echo "重启Superset"
superset_stop
superset_start
;;
status )
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
echo "superset正在运行"
fi
esac加执行权限
[atguigu@hadoop102 bin]$ chmod +x superset.sh
测试
启动superset
[atguigu@hadoop102 bin]$ superset.sh start
停止superset
[atguigu@hadoop102 bin]$ superset.sh stop
登录网址:hadoop102:8787
二十一.可视化展示_安装数据库依赖
1)安装连接MySQL数据源的依赖
(superset) [atguigu@hadoop102 ~]$ conda install mysqlclient
Proceed ([y]/n)? y
说明:对接不同的数据源,需安装不同的依赖,以下地址为官网说明
http://superset.apache.org/installation.html#database-dependencies
2)重启Superset
(superset) [atguigu@hadoop102 ~]$ superset.sh restart
二十二.可视化展示_对接数据源
1)Database配置
(1)点击Sources/Databases
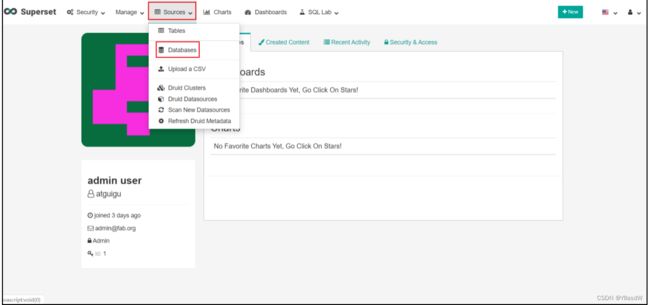
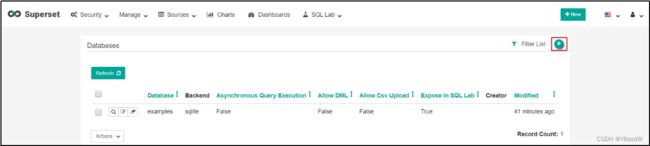
(2)点击+
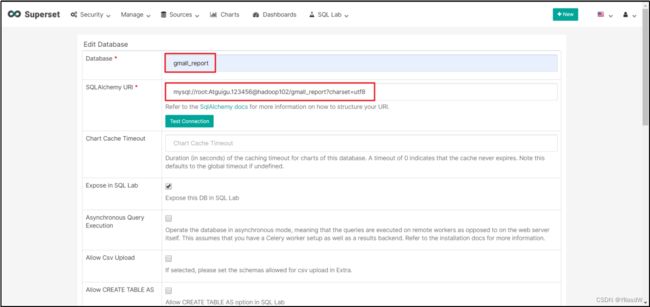
 (3)点击填写Database及SQL Alchemy URI
(3)点击填写Database及SQL Alchemy URI
Database: gmall_report
SQLAIchemy URI: mysql://root:000000@hadoop102/gmall_report?charset=utf8
注:SQL Alchemy URI编写规范:mysql://账号:密码@IP/数据库名称
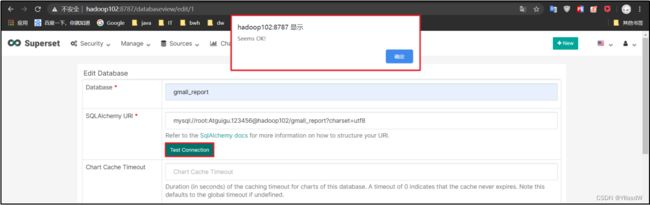
(4)点击Test Connection,出现“Seems Ok!”提示即表示连接成功
(5)保存配置
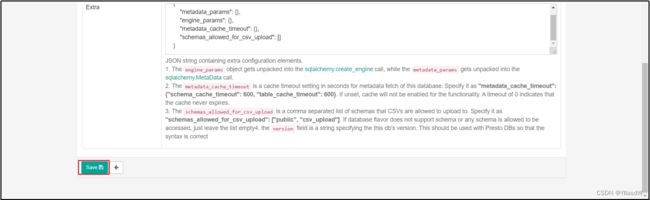 2)Table配置
2)Table配置
(1)点击Sources/Tables
(2)点击Sources/Tables
(3)配置Table

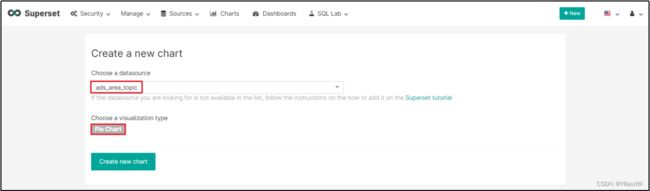
二十三.可视化展示_配置图表
1)点击Dashboards/+
2)选则数据源及图表类型

3)选择何使的图表类型

4)创建图表
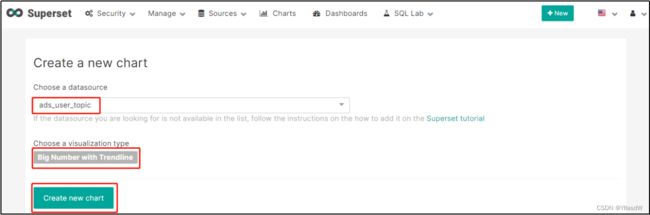
5)可修改语言为中文,方便配置

6)按照说明配置图表
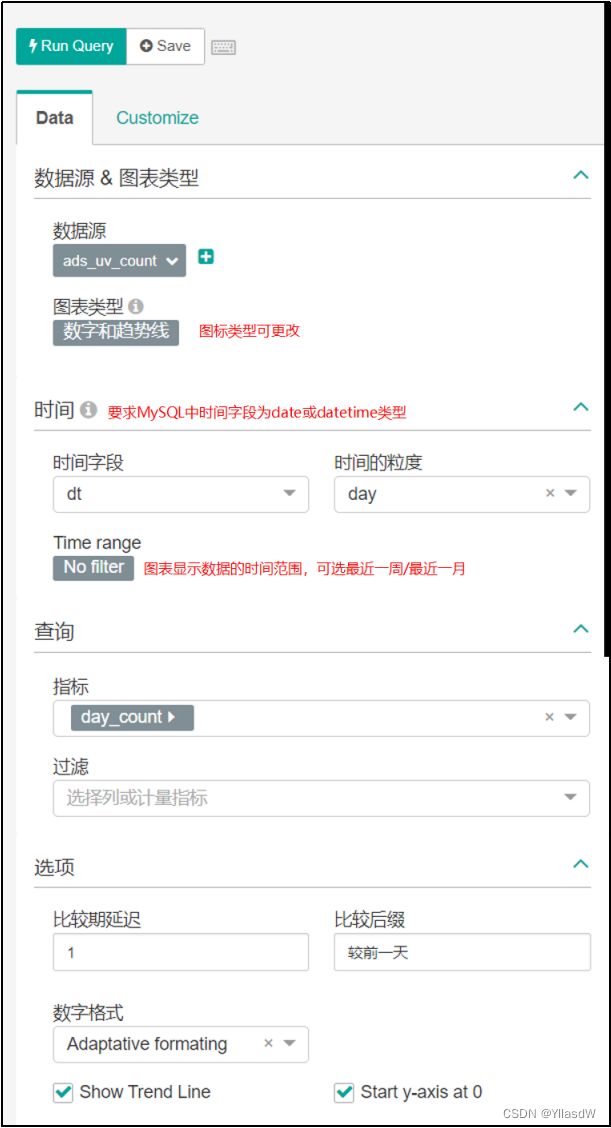
7)点击“Run Query”

二十四.可视化展示_配置仪表盘
1)点击“Edit dashboard”

2)调整图表大小以及图表盘布局

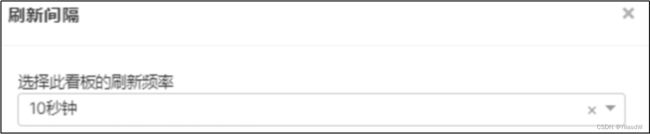
3)点击下图中箭头,可调整仪表盘自动刷新时间

二十五.可视化展示_地图
1)配置Table
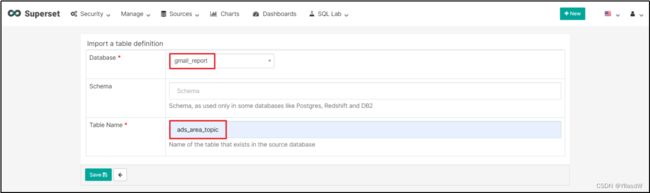
2)配置Chart

二十六.可视化展示_饼状图
1)配置Table
此处使用地区主题表——ads_user_topic
2)配置Chart