DreamBooth 梦幻亭——用于主题驱动的文生图微调扩散模型
© 2022 Ruiz, Li, Jampani, Pritch, Rubinstein, Aberman (Google Research)
© 2023 Conmajia
简介
本文是 DreamBooth 官网首页的中文翻译。
本文已获得 Nataniel Ruiz 本人授权。
DreamBooth 主要内容基于 CVPR 论文 DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation(2208.12242)。
‘ ‘ `` ‘‘ 这就像一部照相亭,但只要捕捉到主题,就能把它合成到你梦里能去的任何地方。 " " "
摘要 大型文本生成图像模型在 AI 的发展中取得了显著的飞跃,可以从给定的文本提示中合成高质量和多样化的图像。然而,这些模型缺乏模仿给定参考集中主题外观并在不同环境中合成新的演绎的能力。在这项工作中,我们提出了一种新的方法来“个性化”文本生成图像扩散模型(使其适应用户的需求)。只需要输入主题的几张图片,我们就可以微调预训练的文本生成图像模型(Imagen,虽然我们的方法不限于特定模型),使其学会将唯一标识符与该特定主题绑定。这种方法可以使模型更好地满足用户的需求,同时也增强了模型对主题的识别和生成能力。
一旦主题被嵌入模型的输出域中,唯一标识符就可以用于在不同场景中合成完全新颖的逼真主题图像。通过利用模型中嵌入的语义先验和新的自生类特定先验保留损失,我们的技术能够合成出现在参考图像中不存在的多样化场景、姿态、视角和照明条件中的主题。我们的技术不仅可以实现主题重新定位、文本引导的视图合成和外观修改,还可以在保留主题关键特征的同时实现艺术渲染。这项研究为文本生成图像领域的进一步发展提供了有益的探索。
背景
对于特定的主题,比如一部时钟(在左侧的真实图像中显示),使用最先进的文本生成图像模型在不同的上下文中生成该主题,同时保持其关键视觉特征的高保真度是非常具有挑战性的。以 Saharia 等在 2022 年提出的 Imagen 模型为例,即使包含的文本详细描述了时钟外观(丛林里有一个白色表盘的复古风格黄色闹钟,表盘右侧有一个黄色数字“3”),经过几十次迭代后,模型仍无法重建其关键视觉特征。此外,即使是文本嵌入在共享的语言-视觉空间中,可以创建图像的语义变化的模型,如 DALL-E2,也无法重建给定主题的外观或修改上下文(Ramesh et al, 2022)。相比之下,我们的方法(最右)可以高保真度地合成时钟,并在新的上下文中进行合成(在丛林中的一个[V]时钟)。
方法
我们的方法以几张特定主题(例如一只小狗)图像作为输入,通常 3-5 张图片就足够了,加上相应的类别名称(例如“狗”),然后返回一个经过微调和“个性化”的文本生成图像模型。该模型拥有一个唯一的标识符,用于引用该主题(小狗)。在生成结果过程中(这个过程被称为“推断”),我们可以在不同的句子中嵌入这个唯一的标识符,以在不同的上下文中合成主题。
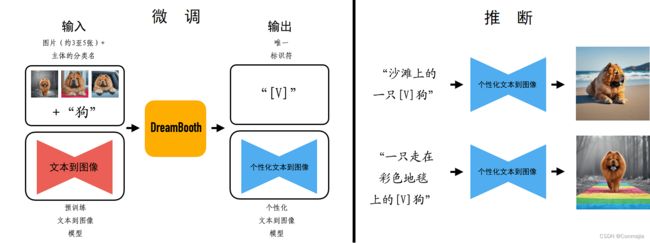
我们利用给定主题的约 3-5 张图像,通过两个步骤微调文本生成图像模型:
(a) 用包含唯一标识符和主题所属类别名称的提示词(例如一张[V]狗的照片),与输入的图像一起微调低分辨率的文本生成图像模型。同时,我们应用了类别特定的先验保留损失,利用模型对该类别的语义先验,通过将类别名称插入提示词中(例如一张狗的照片)鼓励其生成属于该主题类别的多样实例。
(b) 使用从我们的输入图像集当中获取的低分辨率和高分辨率图像对各部分进行超分辨率微调,这使我们能够保持对主题的小细节的高保真度。

结果
下面的例子里展示了使用我们的方法对墨镜、背包、花瓶、茶壶和小狗等主题进行重新语境化的结果。通过对模型进行微调,我们能够在不同环境中生成主题的不同图像,同时保留主题细节并实现与场景的逼真互动。我们在每个图像下方标出了相应的提示词。
艺术演绎
下面是以不同艺术家风格对主题小狗进行的原创艺术演绎。许多生成的姿势在训练样本集中都没有出现过(如对梵高和沃霍尔作品的演绎)。我们还注意到,一些作品在忠实地模仿画家风格基础上,似乎具有其原创的新颖构图:这暗示了我们的项目具备某种程度的创新能力(根据先前的知识进行推断)。
文本引导型视角合成
我们的技术可以为主题小猫合成指定视角的图像,从左到右分别是:上方、下方、侧方和后方视角。可以看出,生成的姿态不同于输入的姿态,并且在姿态变化的情况下背景会以真实的方式变化。我们还特别保留了主题小猫额头上复杂的毛皮图案。

属性修改
下图第一行展示了利用“一台[颜色][V]汽车”这样的提示词生成的图像效果。第二行展示了某个特定品种的小狗和不同动物“混合”之后的效果,用到的提示词为“[V]小狗和[目标物种]合成”。需要强调的是,我们设计的方法既保留了主体本身的独特视觉属性,同时成功执行了所需的对其某一属性的修改。

配饰
这里展示的是给小狗配上服饰。在这里,我们的模特(这只小狗)的身份被保留下来,而许多不同的服饰则“穿”到了小狗身上。选用的提示词为“一只[V]小狗穿着警察/厨师/女巫的服装”。我们观察了模特小狗和服装或配饰之间的现实互动,以及各种可能的选择。

社会影响
我们的项目旨在为用户提供一种用于在不同语境下合成个性化的主题(动物或其他物体)的高效工具。通常文本到图像模型可能会在由文本合成图像时偏向于特定的属性,而我们提出的方法使用户能够更好地重建他们想要的主题。相反之下,一些恶意团体可能试图使用这些图像来误导观众。这个问题相当常见,也存在于其他生成模型方法或者内容操作技术中。在未来对生成建模研究,特别是个性化生成先验的研究中,必须继续研究和重新验证这些问题。
BibTex 引用代码
@article{ruiz2022dreambooth,
title={DreamBooth: Fine Tuning Text-to-image Diffusion Models for Subject-Driven Generation},
author={Ruiz, Nataniel and Li, Yuanzhen and Jampani, Varun and Pritch, Yael and Rubinstein, Michael and Aberman, Kfir},
booktitle={arXiv preprint arxiv:2208.12242},
year={2022}
}
致谢
我们感谢 Rinon Gal、Adi Zicher、Ron Mokady、Bill Freeman、Dilip Krishnan、Huiwen Chang 和 Daniel cohen,感谢他们宝贵的投入帮助改进了这项工作。我们还感谢 Mohammad Norouzi、Chitwan Saharia 和 William Chan 为我们提供了支持和 Imagen 的预训练模型。最后,特别感谢 David Salesin 的反馈、建议和对项目的支持。