IDDPM的UNetModel的ResBlock和AttentionBlock详解
IDDPM的UNetModel的ResBlock和AttentionBlock详解
- ResBlock
- AttentionBlock
class UNetModel(nn.Module):
"""
The full UNet model with attention and timestep embedding.
:param in_channels: channels in the input Tensor.
:param model_channels: base channel count for the model.
:param out_channels: channels in the output Tensor.
:param num_res_blocks: number of residual blocks per downsample.
:param attention_resolutions: a collection of downsample rates at which
attention will take place. May be a set, list, or tuple.
For example, if this contains 4, then at 4x downsampling, attention
will be used.
:param dropout: the dropout probability.
:param channel_mult: channel multiplier for each level of the UNet.
:param conv_resample: if True, use learned convolutions for upsampling and
downsampling.
:param dims: determines if the signal is 1D, 2D, or 3D.
:param num_classes: if specified (as an int), then this model will be
class-conditional with `num_classes` classes.
:param use_checkpoint: use gradient checkpointing to reduce memory usage.
:param num_heads: the number of attention heads in each attention layer.
"""
def __init__(
self,
in_channels,
model_channels,
out_channels,
num_res_blocks,
attention_resolutions,
dropout=0,
channel_mult=(1, 2, 4, 8),
conv_resample=True,
dims=2,
num_classes=None,
use_checkpoint=False,
num_heads=1,
num_heads_upsample=-1,
use_scale_shift_norm=False,
):# init模块,对超参数进行设置
super().__init__()
if num_heads_upsample == -1:
num_heads_upsample = num_heads
self.in_channels = in_channels
self.model_channels = model_channels
self.out_channels = out_channels
self.num_res_blocks = num_res_blocks
self.attention_resolutions = attention_resolutions
self.dropout = dropout
self.channel_mult = channel_mult
self.conv_resample = conv_resample
self.num_classes = num_classes
self.use_checkpoint = use_checkpoint
self.num_heads = num_heads
self.num_heads_upsample = num_heads_upsample
time_embed_dim = model_channels * 4
# 对扩散过程的timestep进行变换
self.time_embed = nn.Sequential(
linear(model_channels, time_embed_dim),
SiLU(),
linear(time_embed_dim, time_embed_dim),
)
if self.num_classes is not None: # 如果是条件生成的话,还会有label_emb
self.label_emb = nn.Embedding(num_classes, time_embed_dim)
self.input_blocks = nn.ModuleList(
[
TimestepEmbedSequential(
conv_nd(dims, in_channels, model_channels, 3, padding=1)
)
]
)
input_block_chans = [model_channels]
ch = model_channels
ds = 1 # ds为下采样的比例
# 对unet的左边进行搭建:先做ResBlock, AttentionBlock 再做DownSample
for level, mult in enumerate(channel_mult): # channel_mult=(1,2,4,8)
# 第一个for循环,就确定ResBlock和AttentionBlock的块数,也即横向操作
for _ in range(num_res_blocks):
# ResBlock把时间信息加进来
layers = [
ResBlock(
ch,
time_embed_dim,
dropout,
out_channels=mult * model_channels,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
)
]
ch = mult * model_channels
# AttentionBlock只有当downsample到一定程度才会执行哦!
# AttentionBlock 16*16ViT的思想,更好地捕捉像素之间的关系
if ds in attention_resolutions: # ds:下采样的比例
layers.append(
AttentionBlock(
ch, use_checkpoint=use_checkpoint, num_heads=num_heads
)
)
self.input_blocks.append(TimestepEmbedSequential(*layers))
input_block_chans.append(ch)
# Downsample,竖向操作,降采样
if level != len(channel_mult) - 1:
self.input_blocks.append(
TimestepEmbedSequential(Downsample(ch, conv_resample, dims=dims))
)
input_block_chans.append(ch)
ds *= 2
#unet中间的部分,feature map大小和channel都不变
self.middle_block = TimestepEmbedSequential(
ResBlock(
ch,
time_embed_dim,
dropout,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
),
AttentionBlock(ch, use_checkpoint=use_checkpoint, num_heads=num_heads),
ResBlock(
ch,
time_embed_dim,
dropout,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
),
)
# unet最右边的那一块
self.output_blocks = nn.ModuleList([])
for level, mult in list(enumerate(channel_mult))[::-1]:
for i in range(num_res_blocks + 1):
# 注意ResBlock的input 是channles(当前的通道数目) + input_block_chans.pop()(左边的通道数目)
layers = [
ResBlock(
ch + input_block_chans.pop(),
time_embed_dim,
dropout,
out_channels=model_channels * mult,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
)
]
ch = model_channels * mult
if ds in attention_resolutions:
layers.append(
AttentionBlock(
ch,
use_checkpoint=use_checkpoint,
num_heads=num_heads_upsample,
)
)
if level and i == num_res_blocks:
layers.append(Upsample(ch, conv_resample, dims=dims))
ds //= 2 # upsample, 通道数目在不断减小
self.output_blocks.append(TimestepEmbedSequential(*layers))
self.out = nn.Sequential(
normalization(ch),
SiLU(),
zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
)
def convert_to_fp16(self):
"""
Convert the torso of the model to float16.
"""
self.input_blocks.apply(convert_module_to_f16)
self.middle_block.apply(convert_module_to_f16)
self.output_blocks.apply(convert_module_to_f16)
def convert_to_fp32(self):
"""
Convert the torso of the model to float32.
"""
self.input_blocks.apply(convert_module_to_f32)
self.middle_block.apply(convert_module_to_f32)
self.output_blocks.apply(convert_module_to_f32)
@property
def inner_dtype(self):
"""
Get the dtype used by the torso of the model.
"""
return next(self.input_blocks.parameters()).dtype
def forward(self, x, timesteps, y=None):
"""
Apply the model to an input batch.
:param x: an [N x C x ...] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:param y: an [N] Tensor of labels, if class-conditional.
:return: an [N x C x ...] Tensor of outputs.
"""
assert (y is not None) == (
self.num_classes is not None
), "must specify y if and only if the model is class-conditional"
hs = []
# 这里的timestep是一个正余弦的表示,这里和DDPM里面的不一样哦
# 这里的t是缩放到了0~1000之间的
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
if self.num_classes is not None: # 如果有num_classes的话,需要把label_emb也加进来
# 条件也是变为一个embedding, 然后和time_emb结合起来
assert y.shape == (x.shape[0],)
emb = emb + self.label_emb(y)
h = x.type(self.inner_dtype)
# 对input_blocks进行遍历保存起来到hs,因为UpSample的时候每个模块都需要传入左侧对应模块的输出
for module in self.input_blocks:
h = module(h, emb)
hs.append(h)
h = self.middle_block(h, emb)
for module in self.output_blocks:
cat_in = th.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
h = h.type(x.dtype)
return self.out(h)
def get_feature_vectors(self, x, timesteps, y=None):
"""
Apply the model and return all of the intermediate tensors.
:param x: an [N x C x ...] Tensor of inputs.
:param timesteps: a 1-D batch of timesteps.
:param y: an [N] Tensor of labels, if class-conditional.
:return: a dict with the following keys:
- 'down': a list of hidden state tensors from downsampling.
- 'middle': the tensor of the output of the lowest-resolution
block in the model.
- 'up': a list of hidden state tensors from upsampling.
"""
hs = []
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
if self.num_classes is not None:
assert y.shape == (x.shape[0],)
emb = emb + self.label_emb(y)
result = dict(down=[], up=[])
h = x.type(self.inner_dtype)
for module in self.input_blocks:
h = module(h, emb)
hs.append(h)
result["down"].append(h.type(x.dtype))
h = self.middle_block(h, emb)
result["middle"] = h.type(x.dtype)
for module in self.output_blocks:
cat_in = th.cat([h, hs.pop()], dim=1)
h = module(cat_in, emb)
result["up"].append(h.type(x.dtype))
return result
forward函数中:
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
timestep_embedding先把timesteps经过sin, cos变化,输出(N, model_channels)的二维张量
再经过time_embed的linear, silu, linear处理,输出(N, time_embed_dim)的二维张量
emb = emb + self.label_emb(y)如果还有标签y的话,就通过embedding将y编码为(N, time_embed_dim),然后和时间的编码直接相加。
将x 和emb一起传入到input_blocks中处理,也即Unet的左侧,先进行横向(Res or Res+Atten)处理,再downsample
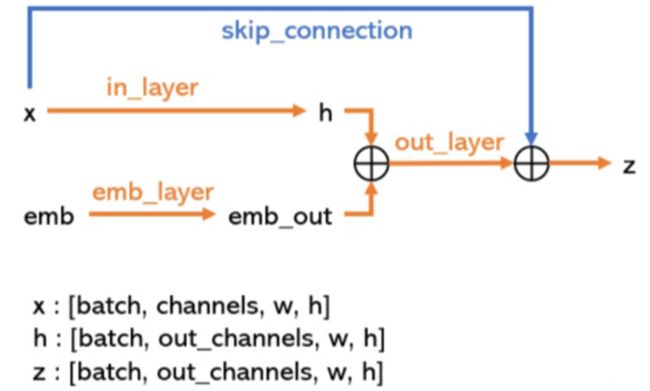
ResBlock
resblock中的emb是包含time和label信息的混合emb, resblock就是为了把时间信息和标签信息处理后融合到图片x中去。
AttentionBlock
由于最开始的ds=1,而attention_resolution=“16,8”,所以只有当降采样到一定level的时候,比如降采样到第3层,第4层的时候才会用到AttentionBlock.
# AttentionBlock只有当downsample到一定程度才会执行哦!
# AttentionBlock 16*16ViT的思想,更好地捕捉像素之间的关系
if ds in attention_resolutions: # ds:下采样的比例
layers.append(
AttentionBlock(
ch, use_checkpoint=use_checkpoint, num_heads=num_heads
)
)
# MHSA:multi-head-self-attention
# SA:更好地捕捉像素之间的关系
# Multi-head: 因为QKV是根据Q和K之间的相似性来计算权重的,它是没有可学习参数的,
# 为了引入可学习参数,先将QKV通过linear投影到低维,再进行Attention(多组),然后concat结果,在project回来
class AttentionBlock(nn.Module): # 其实就是做一个Multi-Head-attention的计算
"""
An attention block that allows spatial positions to attend to each other.
Originally ported from here, but adapted to the N-d case.
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
"""
def __init__(self, channels, num_heads=1, use_checkpoint=False):
super().__init__()
self.channels = channels
self.num_heads = num_heads
self.use_checkpoint = use_checkpoint
self.norm = normalization(channels) # GroupNorm
self.qkv = conv_nd(1, channels, channels * 3, 1) # 进行1维卷积,kernel=1,不改变featuremap形状,但改变channel数目
self.attention = QKVAttention()
self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
def forward(self, x):
return checkpoint(self._forward, (x,), self.parameters(), self.use_checkpoint)
def _forward(self, x):
b, c, *spatial = x.shape
# 首先把x变成三维的,batchsize * channel * 空间维(拉成一维的)
x = x.reshape(b, c, -1)
qkv = self.qkv(self.norm(x)) # GN, 然后channel数翻3倍
# num_head提前,中间的-1是序列长度,
qkv = qkv.reshape(b * self.num_heads, -1, qkv.shape[2])
h = self.attention(qkv)
h = h.reshape(b, -1, h.shape[-1]) # 再恢复为原来的形状
h = self.proj_out(h) # 再经过一个proj
return (x + h).reshape(b, c, *spatial) # 残差连接
class QKVAttention(nn.Module):
"""
A module which performs QKV attention.
"""
def forward(self, qkv):
"""
Apply QKV attention.
:param qkv: an [N x (C * 3) x T] tensor of Qs, Ks, and Vs.
:return: an [N x C x T] tensor after attention.
"""
ch = qkv.shape[1] // 3
q, k, v = th.split(qkv, ch, dim=1)
scale = 1 / math.sqrt(math.sqrt(ch))
weight = th.einsum(
"bct,bcs->bts", q * scale, k * scale
) # More stable with f16 than dividing afterwards
weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
return th.einsum("bts,bcs->bct", weight, v)
@staticmethod
def count_flops(model, _x, y):
"""
A counter for the `thop` package to count the operations in an
attention operation.
Meant to be used like:
macs, params = thop.profile(
model,
inputs=(inputs, timestamps),
custom_ops={QKVAttention: QKVAttention.count_flops},
)
"""
b, c, *spatial = y[0].shape
num_spatial = int(np.prod(spatial))
# We perform two matmuls with the same number of ops.
# The first computes the weight matrix, the second computes
# the combination of the value vectors.
matmul_ops = 2 * b * (num_spatial ** 2) * c
model.total_ops += th.DoubleTensor([matmul_ops])
AttentionBlock做的事情:
输入的x=(batch, channel, h, w)
先将图片拉平为(batch, channel, h × w h\times w h×w),然后GN, 并通过conv1d将channel翻3倍,变为(batch, 3channel, h × w h\times w h×w).
然后是multi-head的处理:
比如这里设置multi-head=3,将batch和通道重新分组,变为qkv=(batch*multi-head, channel, h × w h\times w h×w).
QKVAttention(qkv)是对通道进行划分,基本上等分为3份,即q.shape=k.shape=v.shape=(3batch, c h a n n e l 3 \frac{channel}{3} 3channel, h × w h\times w h×w)
通过Q,K计算权重Weight,将权重Weight和V相乘得到最后的值,output.shape(3batch, c h a n n e l 3 \frac{channel}{3} 3channel, h × w h\times w h×w)
h = h.reshape(b, -1, h.shape[-1])再恢复为原来的形状( b a t c h , c h a n n e l , h × w batch, channel, h\times w batch,channel,h×w), 再经过一个proj_out(其实就是一个conv1d),形状不变,仍为( b a t c h , c h a n n e l , h × w batch, channel, h\times w batch,channel,h×w),然后和 x 进行残差连接,再reshape为( b a t c h , c h a n n e l , h , w batch, channel, h, w batch,channel,h,w).
unetmodel
进去的是x.shape(b, c, h, w),出来的还是(b, c, h, w)
如果x是单通道则c=1, 如果x是三通道则c=3,也就是说unetmodel预测的噪声是3通道里的每个像素点位置上的噪声!!!
einsum函数详解,写的超好!