DQN算法详解
DQN算法详解
一.概述
强化学习算法可以分为三大类:value based, policy based 和 actor critic。常见的是以DQN为代表的value based算法,这种算法中只有一个值函数网络,没有policy网络,以及以DDPG,TRPO为代表的actor-critic算法,这种算法中既有值函数网络,又有policy网络。
说到DQN中有值函数网络,这里简单介绍一下强化学习中的一个概念,叫值函数近似。一个state action pair 对应一个值函数。理论上对于任意的state action pair 我们都可以由公式求出它的值函数,即用一个查询表来表示值函数。但是当state或action的个数过多时,分别去求每一个值函数会很慢。因此我们用函数近似的方式去估计值函数。
论文:Human-level control through deep reinforcement learning | Nature
代码:https://github.com/indigoLovee/DQN
二.DL与RL结合的问题
- DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
- DL的样本独立;RL前后state状态相关;
- DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
- 过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
三.DQN解决问题方法
- 通过Q-Learning使用reward来构造标签(对应问题1)
- 通过experience replay(经验池)的方法来解决相关性及非静态分布问题(对应问题2、3)
- 使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值(对应问题4)
1、构造标签
前面提到DQN中的CNN作用是对在高维且连续状态下的Q-Table做函数拟合,而对于函数优化问题,监督学习的一般方法是先确定Loss Function,然后求梯度,使用随机梯度下降等方法更新参数。DQN则基于Q-Learning来确定Loss Function。
Q-Learning的更新公式:
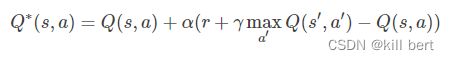
DQN的Loss Function为:
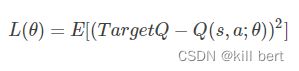
其中 θ是网络参数,目标为:
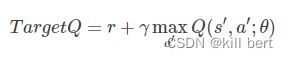
显然Loss Function是基于Q-Learning更新公式的第二项确定的,两个公式意义相同,都是使当前的Q值逼近Target Q值。
2、经验池(experience replay)
经验池的功能主要是解决相关性及非静态分布问题。具体做法是把每个时间步agent与环境交互得到的转移样本储存到回放记忆单元,要训练时就随机拿出一些(minibatch)来训练。(其实就是将游戏的过程打成碎片存储,训练时随机抽取就避免了相关性问题)
3、目标网络
在Nature 2015版本的DQN中提出了这个改进,使用另一个网络(这里称为TargetNet)产生Target Q值。具体地,Q(s,a;θi)表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;Q(s,a;θ−i)表示TargetNet的输出,代入上面求 TargetQ值的公式中得到目标Q值。根据上面的Loss Function更新MainNet的参数,每经过N轮迭代,将MainNet的参数复制给TargetNet。
引入TargetNet后,再一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。
4.模型构建

DQN算法流程:
- 初始化经验池,随机初始化Q网络,初始化target Q网络,其参数与Q网络参数相同;
- repeat
- 重置环境,获得第一个状态;
- repeat
- 用 ϵ \epsilon ϵ-greedy策略生成一个action:其中有 ϵ \epsilon ϵ的概率会随机选择一个action,即为探索模式;其他情况下, a t = m a x a Q ( s t , a ; θ ) a_{t} = max_{a}Q(s_{t}, a;\theta) at=maxaQ(st,a;θ), 选择在 s t s_t st状态下使得Q最大的action,即为经验模式;
- 根据动作与环境的交互,获得反馈的reward r t r_{t} rt、下一个状态 s t + 1 s_{t+1} st+1和是否触发终止条件done;
- 将经验 s t , a t , r t , s t + 1 , d o n e s_{t}, a_{t}, r_{t}, s_{t+1}, done st,at,rt,st+1,done 存入经验池;
- 从经验池中随机获取一个minibatch的经验;
- Q t a r g e t t = { r t , i f d o n e r t + γ m a x a ′ Q t a r g e t ( s t + 1 , a ′ ; θ ) , i f n o t d o n e Qtarget_{t} = \left\{\begin{matrix} r_{t},{\,}if{\,} done \\r_{t} + \gamma max_{a^{'}}Qtarget(s_{t+1}, a^{'}; \theta),if{\,}not{\,}done \end{matrix}\right. Qtargett={rt,ifdonert+γmaxa′Qtarget(st+1,a′;θ),ifnotdone
- 根据 Q p r e d t Qpred_{t} Qpredt 和 Q t a r g e t t Qtarget_{t} Qtargett 求loss,梯度下降法更新Q网络;
- until done=True
- 每隔固定个training step,更新target Q网络,使其参数与Q网络相同;
- until Q ( s , a ) Q(s,a) Q(s,a) 收敛
四、 代码详解
代码链接:
链接:https://pan.baidu.com/s/1ugaruRWcEzlhRDdVoQT1vw?pwd=q9ns
提取码:q9ns
argparse基本用法
1. 实验内容
MountainCar问题是强化学习中的一个经典控制问题。该问题场景如图1所示,小车每次都被初始化在一个山谷的谷底,它的目标是以最少的移动次数到达右侧山顶黄色小旗的位置。但是小车的发动机不足以支持它一直向右爬坡驶向山顶,唯一的成功方式就是让小车通过左右移动积蓄足够的动量冲过山顶。
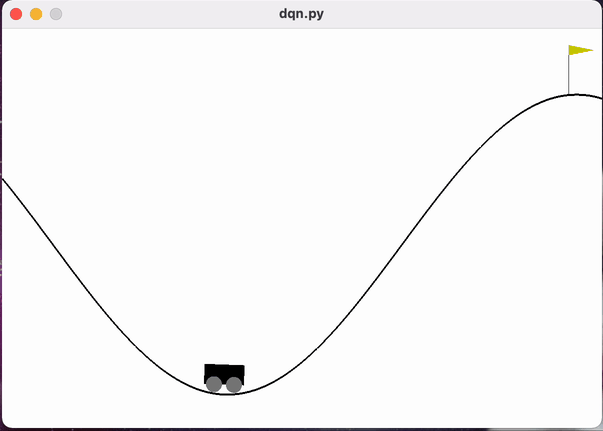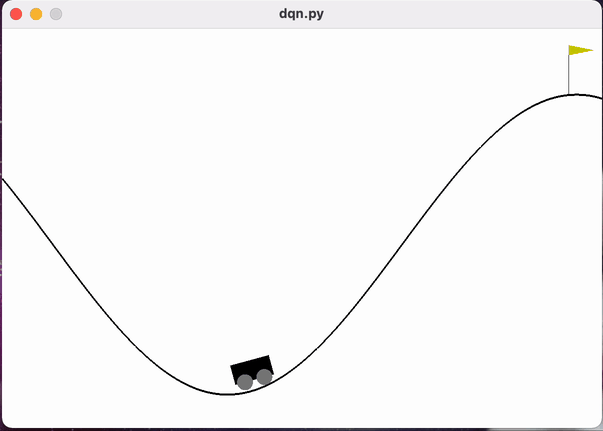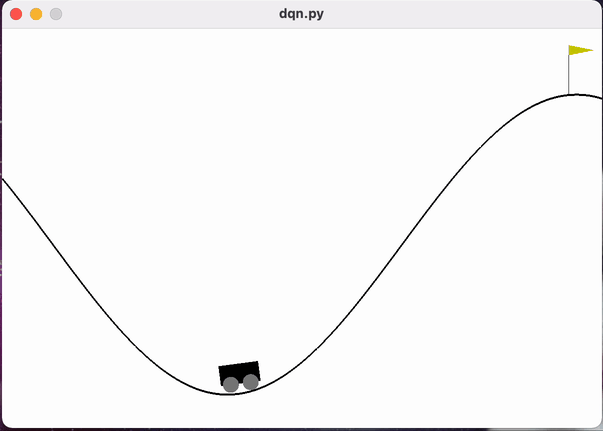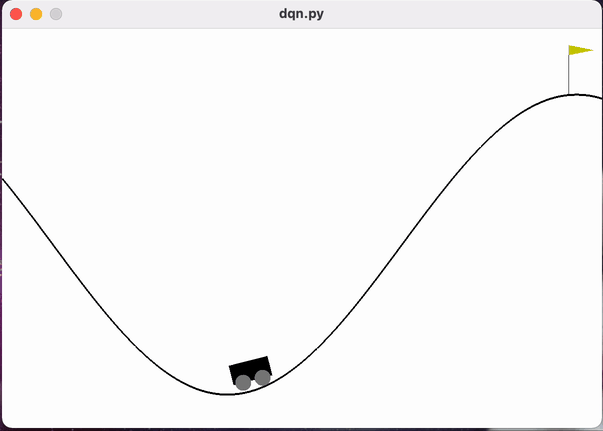
图 MountainCar问题
在本实验中,小车即为智能体,小车所处的运动空间可称为环境,小车与环境交互后,会获得当前的状态,状态包含以下两个状态变量:
| 状态变量 | 定义 | Min | Max |
|---|---|---|---|
| Cart Position | 小车在x轴方向上的位置 | -1.2 | 0.6 |
| Cart Velocity | 小车的运动速度 | -0.07 | 0.07 |
小车根据当前的状态,依据现有的策略,执行相应的动作,在MountainCar问题中,可执行的动作为以下三种:
| 动作 | |
|---|---|
| 0 | 向左加速 |
| 1 | 不加速 |
| 2 | 向右加速 |
该实验中,若触发以下两种情况中任意一种,则一轮实验终止(我们称一个episode为一轮实验):
- 小车达到右侧小旗的位置
- 小车的移动次数超过200次
2.代码
2.1Agent的设计
构建一个可以解决复杂问题的智能体,可采取Model → \rightarrow → Algorithm → \rightarrow → Agent的构建结构。如图6所示,我们分别对model,dqn algorithm和agent进行构建,agent负责与环境的交互,在交互过程中把生成的数据提供给algorithm来更新model。
class MountainCarModel(parl.Model):
""" 继承parl.Model定义DQN网络结构
Args:
obs_dim (int): 观察值(状态)的维度
act_dim (int): 行动的维度
"""
def __init__(self, obs_dim, act_dim):
super(MountainCarModel, self).__init__()
# 设定两个隐藏层的神经元数量都为128
hid1_size = 128
hid2_size = 128
# 定义第一层全连接层,输入单元数目为观察值的维度,在本实验中obs_dim为2,输出单元数目为隐藏层神经元数目hid1_size
self.fc1 = nn.Linear(obs_dim, hid1_size)
# 定义第二层全连接层
self.fc2 = nn.Linear(hid1_size, hid2_size)
# 定义第三层全连接层,输入单元数目为隐藏层神经元数目hid2_size,输出单元数目为action的维度
self.fc3 = nn.Linear(hid2_size, act_dim)
def forward(self, obs):
# 前向计算
h1 = F.relu(self.fc1(obs))
h2 = F.relu(self.fc2(h1))
# 网络输出为在当前状态下,所有action对应的Q值,Q(s, a1), Q(s, a2), Q(s, a3)
Q = self.fc3(h2)
return Q
class DQN(parl.Algorithm):
""" DQN算法
Args:
model (parl.Model): 定义Q函数的前向网络结构
gamma (float): reward的衰减因子
lr (float): 学习率
"""
def __init__(self, model, gamma=None, lr=None):
self.model = model
self.target_model = copy.deepcopy(model) # 复制一个相同的模型作为target model
self.gamma = gamma
self.lr = lr
self.mse_loss = paddle.nn.MSELoss(reduction='mean') # 定义损失函数为均方差损失函数,计算预测值和目标值的均方差误差
self.optimizer = paddle.optimizer.Adam(
learning_rate=lr, parameters=self.model.parameters()) # 定义Adam优化器,学习率设置为0.001
def predict(self, obs):
# 调用model.forward, 根据输入的状态变量,获取所有action对应的Q值
return self.model.forward(obs)
def learn(self, obs, action, reward, next_obs, terminal):
# 使用DQN算法更新model的forward网络
pred_values = self.model.forward(obs) # 获得Q(s, a1), Q(s, a2), Q(s, a3)
action_dim = pred_values.shape[-1]
action = paddle.squeeze(action, axis=-1)
action_onehot = paddle.nn.functional.one_hot(action, num_classes=action_dim)
pred_value = paddle.multiply(pred_values, action_onehot)
pred_value = paddle.sum(pred_value, axis=1, keepdim=True) # 计算Q预测值
with paddle.no_grad(): # 禁用动态图梯度计算
max_v = self.target_model.forward(next_obs).max(1, keepdim=True) # 使用target model预测Q值,并选取maxQ(next_s, a),用于计算target Q
target = reward + (1 - terminal) * self.gamma * max_v # 计算Q目标值
loss = self.mse_loss(pred_value, target) # 计算Q(s, a)与target_Q的均方差,得到loss
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
return loss
def sync_target(self):
# 把self.model的模型参数值同步到self.target_model
self.model.sync_weights_to(self.target_model)
class MountainCarAgent(parl.Agent):
""" 继承parl.Agent定义的智能体
Args:
algorithm (parl.Algorithm): DQN算法
act_dim (int): 行动的维度
e_greed (float): e-greedy策略中的e概率
e_greed_decrement (float): e概率的衰减,随着训练逐步收敛,探索的概率逐渐减小
"""
def __init__(self, algorithm, act_dim, e_greed=0.1, e_greed_decrement=0):
super(MountainCarAgent, self).__init__(algorithm)
assert isinstance(act_dim, int)
self.act_dim = act_dim
self.global_step = 0
self.update_target_steps = 200 # 每隔200个training steps将model的参数复制给target model
self.e_greed = e_greed # 有一定的概率会随机选取动作,即让智能体去探索
self.e_greed_decrement = e_greed_decrement # 随着训练逐步收敛,逐渐降低探索的程度
def sample(self, obs):
sample = np.random.random() # 产生[0, 1)区间内的随机浮点数
if sample < self.e_greed: # 如果随机值小于e_greed,则进入探索模式,随机选择一个动作
act = np.random.randint(self.act_dim)
else:
act = self.predict(obs) # 经验模式:根据Q值选择最优动作
self.e_greed = max(0.01, self.e_greed - self.e_greed_decrement) # 随着训练逐步收敛,逐渐降低探索的程度
return act
def predict(self, obs):
obs = paddle.to_tensor(obs, dtype='float32')
pred_q = self.alg.predict(obs)
act = pred_q.argmax().numpy()[0] # 选择Q值最大的action
return act
def learn(self, obs, act, reward, next_obs, terminal):
# 每隔200个training steps同步一次model和target model的参数
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
act = np.expand_dims(act, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(terminal, axis=-1)
obs = paddle.to_tensor(obs, dtype='float32')
act = paddle.to_tensor(act, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_obs = paddle.to_tensor(next_obs, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
loss = self.alg.learn(obs, act, reward, next_obs, terminal) # 训练网络并得到loss
return loss.numpy()[0]
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size) # 随机抽取batch_size条经验
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience # 每条经验包含state,action,reward,next_state, done
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'), \
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
2.2 训练配置
训练配置的具体流程为:
- 设置超参数;
- 通过gym创建MountainCar-v0环境;
- 实例化MountainCarAgent。
# 设置超参数
LEARN_FREQ = 5 # 训练频率,不需要每有一条经验都训练一次,攒一些新增经验后再learn,提高效率
MEMORY_SIZE = 20000 # 经验池的大小,越大越占用内存
MEMORY_WARMUP_SIZE = 200 # 在replay_memory中预存一些经验数据,再开启训练
BATCH_SIZE = 32 # 每次从replay memory中随机出一批大小为Batch_Size的数据,供agent学习
LEARNING_RATE = 0.001 # 学习率
GAMMA = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
# 使Gym创建MountainCar环境
env = gym.make('MountainCar-v0')
obs_dim = env.observation_space.shape[0] # 获得环境状态维度
act_dim = env.action_space.n # 获得动作维度
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim))
# 对智能体进行实例化
rpm = ReplayMemory(MEMORY_SIZE)
model = MountainCarModel(obs_dim=obs_dim, act_dim=act_dim)
alg = DQN(model, gamma=GAMMA, lr=LEARNING_RATE)
agent = MountainCarAgent(alg, act_dim=act_dim, e_greed=0.1, e_greed_decrement=1e-6)
2.3 模型训练
本实验中,我们使用Gym创建了MountainCar环境。Gym是强化学习中的经典环境库,用于研究和开发强化学习相关算法的仿真平台。其具体的API如 图7 所示。
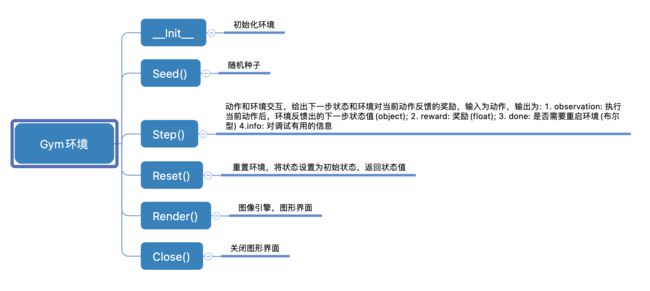
图 gym环境
模型训练的具体步骤如下:
-
初始化环境;
-
在未触发终止条件的情况下:
1)根据当前状态,采用随机选取或根据最大Q值选取的方式,获得一个动作;
2)动作和环境交互,给出交互后新的环境状态,针对当前action的reward和是否触发终止条件done;
3)将
state, action, reward, next_state, done作为一条经验,存入经验池中;4)如果经验池中存储的经验数量超过MEMORY_WARMUP_SIZE且该step为训练step,则:从经验池中随机选取一个BATCH_SIZE的经验,作为数据输入训练agent;
-
触发终止条件,一个episode结束,获得整个episode的total_reward。
run_train_episode: 训练agent;根据上述模型训练步骤,执行一个episode的训练。
def run_train_episode(agent, env, rpm):
# 训练一个episode
total_reward = 0
obs = env.reset()
step = 0
while True:
step += 1
action = agent.sample(obs) # 随机选取动作(探索模式)或按最大Q值选取动作(经验模式)
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done) = rpm.sample(BATCH_SIZE)
train_loss = agent.learn(batch_obs, batch_action, batch_reward, batch_next_obs, batch_done)
total_reward += reward
obs = next_obs
if done:
break
return total_reward
2.4 模型评估
模型评估的具体步骤为:
-
初始化环境
-
在未触发终止条件的情况下:
1)根据当前状态,选择Q值最大的action,作为预测的动作;
2)动作和环境交互,给出交互后新的环境状态,针对当前action的reward和是否触发终止条件done;
3)触发终止条件,一个episode结束,获得整个episode的total_reward.
-
五个episode结束,获得total_reward的平均值。
run_evaluate_episodes: 评估agent;运行五个episode,求total_reward的平均值。
def run_evaluate_episodes(agent, env, eval_episodes=5, render=False):
# 评估agent
eval_reward = []
for i in range(eval_episodes):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs) # 根据最大Q值预测动作
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
while len(rpm) < MEMORY_WARMUP_SIZE:
run_train_episode(agent, env, rpm)
max_episode = 5000
episode = 0
while episode < max_episode:
for i in range(50):
total_reward = run_train_episode(agent, env, rpm) # 训练agent
episode += 1
eval_reward = run_evaluate_episodes(agent, env, render=False) # 每训练50个episode评估一次模型
logger.info('episode:{} e_greed:{} Test reward:{}'.format(episode, agent.e_greed, eval_reward))
2.5 模型保存
# 保存模型参数到指定路径
save_path = './model_dir'
agent.save(save_path)
# 若想读取该模型参数恢复到指定agent上,可使用如下代码:
if os.path.exists('./model_dir'):
agent.restore('./model_dir')
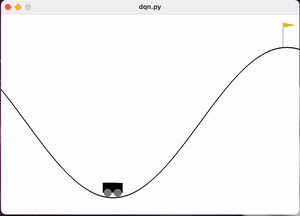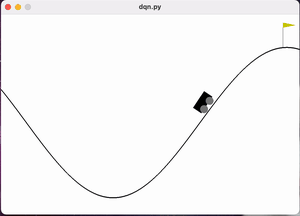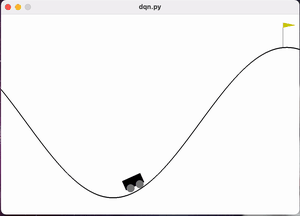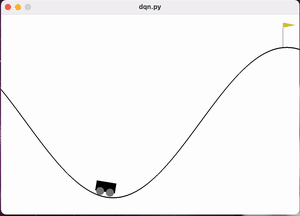
图 训练过程前中期
图 训练过程后期