【性能优化】cocoscreator 共享节点-动效复用方案
前言

迷雾散尽,露出了古朴庄严的森林。古老的铁杉,在头顶编成绿色穹顶。 阳光在树叶间破碎成金色顶棚。从树干间远眺,远处的森林渐渐隐去。
用几句话就能描述一片巨大的森林,但是在实时游戏中做这件事就完全是另外一件事了。 当屏幕上需要显示一整个森林时,图形程序员看到的是每秒需要送到GPU六十次的百万多边形。
我们讨论的是成千上万的树,每棵都由上千的多边形组成。 就算有足够的内存描述森林,渲染的过程中,CPU到GPU的部分也太过繁忙了。
–Bob Nystrom《游戏设计模式》
以上是《游戏设计模式》这本书中“享元模式”章节提到的内容。文中还提到,当我们需要渲染一整片使用给相同纹理的树木时,可以只进行一次树木模型的数据传输,随后发送每棵树不同的位置、大小等数据,来实现森林的效果。
初次读到这个章节的时候,我觉得这真是一个了不起的优化,去除所有重复的工作,用最少的渲染数据,实现大量复用元素的渲染。
当时的我一想,这不就是渲染合批在做的事情吗?提交一次纹理数据,再多次提交顶点数据,就可以实现渲染大量相同的元素。
年轻的我以为故事到这里就结束了… 但是!前段时间看了上海站Cocos Star Meeting,乐府互娱大佬夏凯强分享的“共享节点”,发现这个故事其实还有得聊!
引擎已经帮我们实现了渲染合批的功能,当我们需要渲染大量元素(比如同一张图集下的图片)时,即使不做任何优化,性能效果也是非常优秀的。
能不能更进一步呢?如果我们需要的是一样的结果(比如渲染100个草丛),必须要这么多节点、这么多计算吗?
胆子大一点,把这些节点、组件全部省掉!相同元素只创建一份,杜绝重复劳动——这就是共享节点。
1. 开发环境
浏览器:Chrome
开发语言:JavaScript
引擎版本:CocosCreator 2.4.3
注意:
乐府互娱基于原生环境实现了共享节点,但本文是基于H5的实现。
2. 研究过程
贴一下大佬的PPT(可在Cocos公众号后台发送“上海”获得,其他内容也很棒):

在他们的项目中,共享节点技术主要用来解决动效复用的问题。
在我看来,动效渲染时,会伴随大量的计算,如果有多个相同动效,会产生大量没必要的CPU消耗。虽然引擎提供了SHARED_CACHE等优化方式,但是似乎和我们的期望还是有一点点差距。
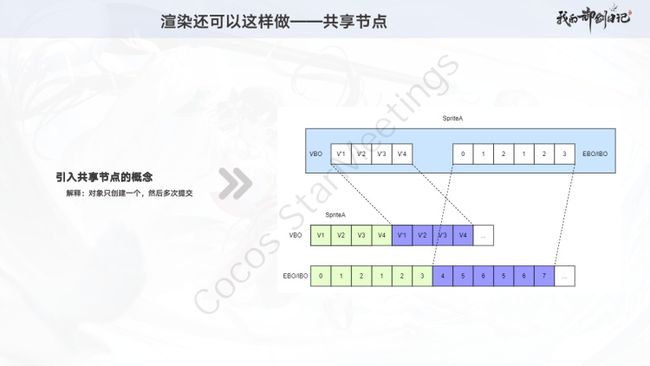
image750×422 57.8 KB
从这张PPT中,可以看出共享节点的主要实现逻辑:
- 相同的对象只创建1个
- 将该对象的渲染数据进行多次提交
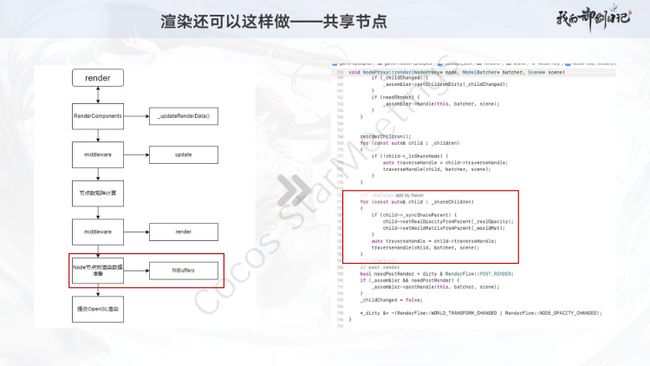
image750×422 72.4 KB
最后的PPT涉及的是渲染流程的修改,在渲染子节点之后,对节点下的共享节点(特殊的子节点)进行渲染。
由于我是在线上观看的分享,加上运气不好,进去的时候这一段刚好完美错过了
。
看完PPT之后,也只是模糊地有了一个思路,本着不要脸的精神,我联系上了大佬(#狗头)!
得知他们的方案大概是:修改了节点的相关逻辑,使得共享节点可以有多个父节点,这样就实现了共享节点可以在多个位置进行渲染。感谢大佬!
3. 实现思路
3.1 思路梳理
综上,可以大概得出共享节点实现的逻辑(以多次渲染同一图片为例):
- 创建一个实际的节点,带有Sprite组件(称为共享节点)。
- 不再创建节点,而是将共享节点多次添加到父节点中。
- 修改渲染流程,在渲染完子节点后,渲染共享节点(可能有多个)。
- 将共享节点自己的渲染数据再次进行提交。
3.2 思路简化
虽然大致的实现思路已经清晰了,但是为了方便实现… 我换了个方案(…
- 创建一个实际的节点,带有Sprite组件(称为共享节点)。
- 不再创建节点,而是创建一个复制节点(js对象),其中保存了位置、共享节点等信息。
- 将复制节点记录到父节点的_copyChidrens中。
- 修改渲染流程,在渲染完子节点后,渲染_copyChidrens(可能有多个)。
- 复制节点在渲染时,拷贝共享节点的渲染数据。
- 对渲染数据进行一点小加工,比如修改位置。
- 提交渲染数据!
注意,这里引入了“复制节点”这个概念。意义为:复制节点是共享节点的一个复制品~
4. 代码实现
为了实现共享节点,我们需要修改引擎相关代码。
本文是基于H5的实现,如果你需要像乐府一样支持原生端,则需要修改对应的C++代码。
4.1 拓展cc.Node
我们需要拓展内置节点功能,支持添加复制节点,并修改渲染流程,支持复制节点的渲染。
4.1.1 增加共享节点标记
// CCNode.js(cocos2d\core\CCNode.js)
properties: {
_isShareNode: false,
isShareNode: {
get () {
return this._isShareNode;
},
set (value) {
this._isShareNode = value;
}
},
}
4.1.2 支持记录复制节点
// CCNode.js(cocos2d\core\CCNode.js)
let NodeDefines = {
/**
* 添加一个复制节点作为子节点
* @param {CopyNode} node 复制节点
*/
addCopyChildren (node) {
let nodes = (this._copyChidrens || (this._copyChidrens = []));
nodes.push(node);
node.setParent(this);
}
}
4.1.3 渲染复制节点
// render-flow.js(cocos2d\core\renderer\render-flow.js)
_proto._children = function (node) {
let children = node._children;
for (let i = 0, l = children.length; i < l; i++) {
// ... 渲染子节点
}
// 修改开始-共享节点-渲染复制子节点
if (node._copyChidrens) {
for (let children of node._copyChidrens) {
children.fillBuffers(batcher);
}
}
// 修改结束-共享节点-渲染复制子节点
this._next._func(node);
};
我们在子节点渲染的逻辑之后,渲染复制节点。
我们遍历节点的所有复制子节点(_copyChidrens),并调用fillBuffers函数进行渲染数据的填充。
注意:
在cocos渲染相关的流程中,若节点没有子节点,则不会进入_children渲染流,因此,作为复制节点的父节点,至少要有一个节点,即使是空节点也可以**。**
节点的修改比较简单,接着我们实现复制节点的逻辑。
4.2 实现复制节点(CopyNode)
不同渲染组件的实现逻辑会有不同,因此我们实现一个父类CopyNode,来负责通用的逻辑。
// CopyNode.js
const _nodeWorldPos = new cc.Vec2();
const _targetWorldPos = new cc.Vec2();
module.exports = class CopyNode {
constructor(shareNode, x, y) {
this.shareNode = shareNode;
this._disX = 0;
this._disY = 0;
this.position = new cc.Vec2();
}
get x() { return this.position._x }
get y() { return this.position._y }
setParent(parent) {
this._parent = parent;
}
setPosition(x, y) {
if (!this._parent) {
CC_DEBUG && cc.warn("复制节点:请在设置父节点后,再修改位置");
return;
}
x === undefined && (x = this.position.x);
y === undefined && (y = this.position.y);
this.position.x = x;
this.position.y = y;
this._parent.convertToWorldSpaceAR(this.position, _nodeWorldPos);
this.shareNode.parent.convertToWorldSpaceAR(this.shareNode.position, _targetWorldPos);
let disX = _nodeWorldPos.x - _targetWorldPos.x;
let disY = _nodeWorldPos.y - _targetWorldPos.y;
this.calDis(disX, disY);
}
/**
* 计算和共享节点的距离
* 有特殊需求可重写本函数
* @param {number} x x距离
* @param {number} y y距离
*/
calDis(x, y) {
this._disX = x;
this._disY = y;
}
}
目前的需求只涉及修改位置,因此这里只实现了位置相关的设置和读取功能。
特殊的是,这里还额外计算了_disX和_disY。这是由于,复制节点的渲染数据来源于共享节点,修改位置时,如果知道复制节点和共享节点之间的距离,就可以直接进行相加得出结果,无需重新计算。
4.3 支持复制Sprite
乐府没有提到复用Sprite相关的内容,但是我有一些其他的想法,因此顺便研究了一下
。
Sprite实现起来比Spine简单,我们先从Sprite开始~
// CopySprite.js
module.exports = class CopySprite extends CopyNode {
fillBuffers(renderer) {
let renderComp = this.shareNode._renderComponent;
renderComp._checkBacth(renderer, this.shareNode._cullingMask);
// 获得共享节点的渲染数据
let assembler = renderComp._assembler;
let renderData = assembler._renderData;
let vData = renderData.vDatas[0];
let iData = renderData.iDatas[0];
// 申请渲染数据空间、计算数据位移
let buffer = assembler.getBuffer(renderer);
let { verticesCount, floatsPerVert, indicesCount } = assembler;
let positionOffset = assembler.getVfmt().element("a_position").offset;
let offsetInfo = buffer.request(verticesCount, indicesCount);
let vertexOffset = offsetInfo.byteOffset >> 2, vbuf = buffer._vData;
// 复制vertices
let vbufLen = vbuf.length;
if (vData.length + vertexOffset > vbufLen) {
vbuf.set(vData.subarray(0, vbufLen - vertexOffset), vertexOffset);
} else {
vbuf.set(vData, vertexOffset);
}
// 修改位置
for (let i = 0; i < verticesCount; i++) {
let positionIndex = vertexOffset + i * floatsPerVert + positionOffset;
if (positionIndex > vbufLen) {
break;
}
vbuf[positionIndex] += this._disX;
vbuf[positionIndex + 1] += this._disY;
}
// 填充indices
let ibuf = buffer._iData, indiceOffset = offsetInfo.indiceOffset, vertexId = offsetInfo.vertexOffset;
for (let i = 0, l = iData.length; i < l; i++) {
ibuf[indiceOffset++] = vertexId + iData[i];
}
}
}
对于Sprite,我们可以仿照Assembler中的fillBuffers函数进行修改。
由于渲染数据都会存储在Assembler中,我们这里取出对应的数据,再重新填充一遍就好了。
复制完渲染数据后,我们可以对顶点数据进行修改,这里只修改了位置。如果你需要修改其他属性(比如颜色),也可以在这里进行处理。
从看到共享节点的第一眼,我就想把它用到TiledMap中!这满屏幕的物件,要是能少创建几个,肯定也有不错的提升!
最后我也确实把它塞到TiledMap中了,优化效果大概是25%(地图不同会导致数据不同)。实现起来不难,大家感兴趣可以试试。
在大部分的应用场景中,很少出现同一张图片渲染多次的情况,复制节点的优势很难凸显,加上复制节点的功能完全打不过真实的节点。估计很难用到其他地方。
4.4 支持复制Spine
与Sprite不同,Spine的渲染数据并不会被缓存,这不就不能CV了吗?这可不行!
根据渲染流程,所有最终的渲染数据都会被填充到buffer中,那我们胆子大一点,直接从buffer中取!
我们在共享节点渲染时,记录Spine渲染数据在buffer中的起始和结束位置,这样就可以在复制节点中通过buffer获得共享节点的渲染数据了!
4.4.1 记录渲染数据位置
// spine-assembler.js(extensions\spine\spine-assembler.js)
fillBuffers (comp, renderer) {
// ...省略部分代码
// 修改开始-共享节点-记录渲染数据开始位置
if (node.isShareNode) {
this._bufferOffsetInfo = {
startVertexOffset: _buffer.vertexOffset,
startIndiceOffset: _buffer.indiceOffset,
}
}
// 修改结束-共享节点-记录渲染数据开始位置
if (comp.isAnimationCached()) {
// Traverse input assembler.
this.cacheTraverse(worldMat);
} else {
if (_vertexEffect) _vertexEffect.begin(comp._skeleton);
this.realTimeTraverse(worldMat);
if (_vertexEffect) _vertexEffect.end();
}
// 修改开始-共享节点-记录渲染数据结束位置
if (node.isShareNode) {
this._bufferOffsetInfo.endVertexOffset = _buffer.vertexOffset;
this._bufferOffsetInfo.endIndiceOffset = _buffer.indiceOffset;
}
// 修改结束-共享节点-记录渲染数据结束位置
// ...省略部分代码
}
4.4.2 实现复制逻辑
// CopySpine.js
const VFOneColor = cc.gfx.VertexFormat.XY_UV_Color;
const VFTwoColor = cc.gfx.VertexFormat.XY_UV_Two_Color;
const _mt4 = new cc.Mat4();
module.exports = class CopySpine extends CopyNode{
fillBuffers(renderer) {
let renderComp = this.shareNode._renderComponent;
renderComp._checkBacth(renderer, this.shareNode._cullingMask);
// 计算渲染数据数量
let assembler = renderComp._assembler;
let { startVertexOffset, startIndiceOffset, endVertexOffset, endIndiceOffset } = assembler._bufferOffsetInfo;
let vertexCount = endVertexOffset - startVertexOffset;
let indiceCount = endIndiceOffset - startIndiceOffset;
// 准备填充复制节点的渲染数据
let _useTint = renderComp.useTint || renderComp.isAnimationCached();
let _vertexFormat = _useTint ? VFTwoColor : VFOneColor;
let floatsPerVert = _vertexFormat._bytes >> 2;
// 相关变量计算结束
// 申请渲染数据空间、计算数据位移
let _buffer = renderer.getBuffer('spine', _vertexFormat);
let offsetInfo = _buffer.request(vertexCount, indiceCount);
let { indiceOffset, vertexOffset } = offsetInfo;
let vertexFloatOffset = offsetInfo.byteOffset >> 2;
// 复制vertices
let vbuf = _buffer._vData;
let startVbufIndex = startVertexOffset * floatsPerVert;
for (let i = 0, len = vertexCount * floatsPerVert; i < len; i++) {
vbuf[vertexFloatOffset + i] = vbuf[startVbufIndex + i];
}
// 修改位置
let positionOffset = _vertexFormat.element("a_position").offset;
let positionIndex = vertexFloatOffset + positionOffset;
while (positionIndex < vertexFloatOffset + vertexCount * floatsPerVert) {
vbuf[positionIndex] += this._disX;
vbuf[positionIndex + 1] += this._disY;
positionIndex += floatsPerVert;
}
// 填充indices
let ibuf = _buffer._iData;
for (let i = 0; i < indiceCount; i++) {
ibuf[indiceOffset + i] = ibuf[startIndiceOffset + i] - startVertexOffset + vertexOffset;
}
_buffer.adjust(vertexCount, indiceCount);
}
/**
* 计算和共享节点的距离
* 未开启合批时,会计算矩阵变换,需要将距离根据缩放进行逆换算。否则坐标错误。
* @param {number} x x距离
* @param {number} y y距离
*/
calDis(x, y) {
let shareNode = this.shareNode;
if (!shareNode._renderComponent.enableBatch) {
shareNode.getWorldMatrix(_mt4);
x /= _mt4.m[0];
y /= _mt4.m[5];
}
this._disX = x;
this._disY = y;
}
}
整体逻辑和Sprite类似,但我们从_buffer中复制渲染数据~
4.5 效果展示
到这里就实现了基本的复制节点效果了,我们已经可以用一个渲染节点来复制出无数个拷贝。是不是很简单!甚至有一点小激动。
你可以像这样使用复制节点:
this.nodeSprite.isShareNode = true;
let copyNode = new CopySprite(this.nodeSprite);
this.nodeContainer.addCopyChildren(copyNode);
copyNode.setPosition(-200, 0);

image960×641 27.3 KB
也可以多复制几个,做个基本的for循环就行(中间那个不合群的是共享节点):

但是!事情往往没有这么简单!
4.6 测试
4.6.1 翻车
当我把哥布林放到测试用例中…
这个框起来的小人本来应该出现在最右侧,突然… 变成了左侧…

对应的节点树:

当哥布林位于两个小人中间时,复制节点的位置错误。
当哥布林位于两个小人后面时,复制节点的位置正确。
4.6.2 翻车原因
乍一看以为是哥布林的原因,直接方向错误…
根本原因是:合批判定逻辑有缺陷,导致复制节点可以和最后一个渲染节点合批,但该节点又不是共享节点。
当哥布林位于小人后面时,显然无法进行合批,因此位置正确。
为什么合批判定出错,会导致位置错误呢?
渲染数据提交时,每个渲染批次会对应一个渲染模型(model),每个渲染模型会绑定一个节点。
节点的位置会变换为cc_matWorld属性(模型空间转世界空间矩阵),传递给effect的顶点处理器。
// base-renderer.js(cocos2d\renderer\core\base-renderer.js)
_draw (item) {
// 省略了部分代码
node.getWorldMatrix(_m4_tmp);
device.setUniform('cc_matWorld', Mat4.toArray(_float16_pool.add(), _m4_tmp));
}
在effect中,cc_matWorld会和cc_matViewProj进行计算,得出顶点位置的换算矩阵。
// builtin-2d-spine.effect(resources\static\default-assets\resources\effects\builtin-2d-spine.effect)
// 省略了部分代码
CCProgram vs %{
void main () {
#if CC_USE_MODEL
mvp = cc_matViewProj * cc_matWorld;
#else
mvp = cc_matViewProj;
#endif
gl_Position = mvp * vec4(a_position, 1);
}
}%
因此,当我们判定复制节点可以和最后的小人合批时,我们将渲染数据附在了最后的小人上,一起提交给了渲染引擎。
基于错误的换算矩阵计算出来的位置自然也是错误的。
这里有个新的疑问,为什么Sprite中没有出现类似的问题?
答案就在effect的代码中:CC_USE_MODEL的值。
Sprite的CC_USE_MODEL值为false,而Spine的CC_USE_MODEL值为true!
也就是说,Sprite渲染时,并不会进行转换。自然也不会因为节点的位置导致错误~
CC_USE_MODEL值取决于是否启用合批(enableBatch属性),在复用Spine的情况下,不一定能够合批,因此不进一步讨论。
5. 修正合批检测
5.1 实现合批检测
在原本的方案中,我们调用共享节点的renderComponent来实现合批检测,现在我们需要拓展合批检测逻辑,来实现一个类似的~
// CopyNode.js
class CopyNode {
/**
* 检测是否可以合批
*/
checkBacth(renderer) {
if (!this.checkCanBacth(renderer)) {
this.flush(renderer);
return;
}
// cocos内置检测逻辑
let node = this.shareNode;
let cullingMask = node._cullingMask;
let material = node._renderComponent._materials[0];
if (renderer.cullingMask !== cullingMask ||
(material && material.getHash() !== renderer.material.getHash())
) {
this.flush(renderer);
}
}
/**
* 检测是否可以合批(子类可以继承拓展)
*/
checkCanBacth(renderer) {
return true;
}
/**
* 刷写渲染数据
*/
flush(renderer) {
renderer._flush();
let node = this.shareNode;
let material = node._renderComponent._materials[0];
renderer.node = material.getDefine('CC_USE_MODEL') ? node : renderer._dummyNode;
renderer.material = material;
renderer.cullingMask = node._cullingMask;
}
}
与内置的合批检测相比,我们在检测之前增加了一个可拓展的函数checkCanBatch,来针对某些特殊子类。
修改原有的checkBatch函数调用(CopySpine和CopySprite都需要修改)
fillBuffers(renderer) {
this.checkBacth(renderer);
let renderComp = this.shareNode._renderComponent;
// 省略后续代码
}
5.2 实现Spine合批检测
// CopySpine.js
class CopySpine extends CopyNode {
checkCanBacth(renderer) {
return this.shareNode === renderer.node;
}
}
就这么简单,当节点不一样的时候,我们就认定为无法合批。

很好,位置正确了!哥布林和小人们快乐地… (不是
6. 性能对比
测试数据由于环境的影响,常常波动不定,因此我们将小人复制五百份,来增大对比性。
两组对照为:
优化前:使用cc.instantiate
优化后:使用复制节点
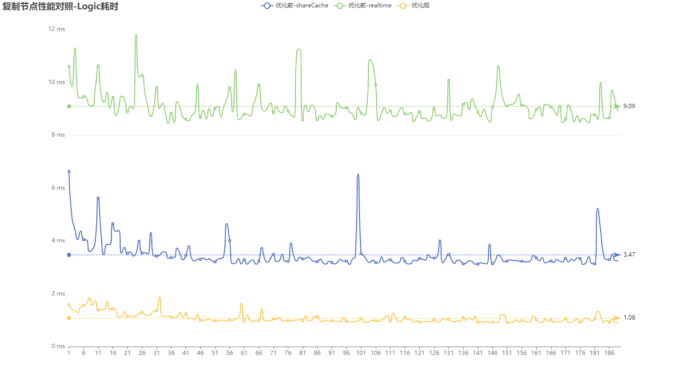
image1405×775 59.3 KB
emmm… 可以明显地看出它们的差距… 大到甚至不想多次实验取平均值…
使用复制节点对比优化前(ShareCache),大约只消耗了32%的性能。
7. 总结
共享节点可以减少节点、组件的创建,避免了大量组件的各类刷新函数调用,同时还可以减少对于渲染数据的计算。
对于复用Spine有奇效,Spine往往需要使用CPU进行位移、变换等运算,使用共享节点后,可以省掉这些计算量,当然SharedCache也可以,但需要额外的内存空间。
本文的方案在某些场景下,已经实现了最初目的——复用Spine,但还是存在一些限制。比如对节点移动、变换等效果的支持不足。也有一些地方还可以优化,比如必须先设置父节点才能修改位置。
受限于本人的技术(以及懒),若干问题不赘述,但技术是个好技术,希望给大家一点启发~
乐府的方案是对原生平台的优化,本人学艺不精,只能做个H5版本玩玩。