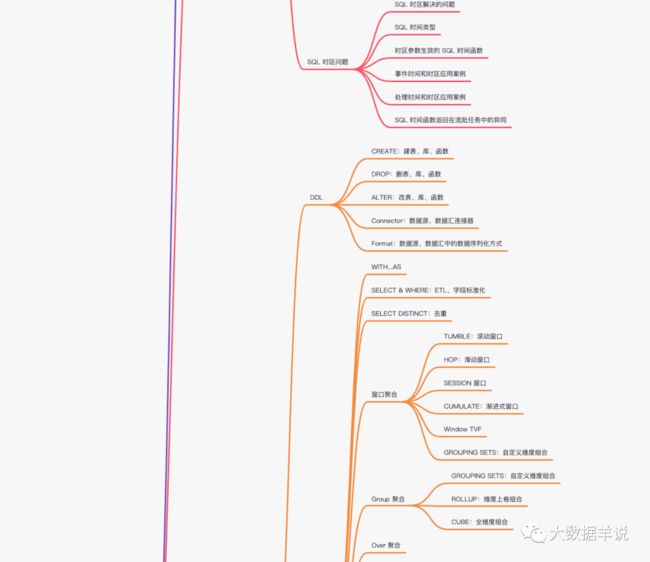
【Flink】Flink SQL之路
文章目录
-
- 1.前言
- 2.基础概念篇
- 2.1.SQL & Table 简介及运行环境
-
- 2.1.1.简介
- 2.1.2.SQL 和 Table API 运行环境依赖
- 2.2.SQL & Table 的基本概念及常用 API
-
- 2.2.1.一个 SQL\\Table API 任务的代码结构
- 2.2.2.SQL 上下文:TableEnvironment
- 2.2.3.SQL 中表的概念
- 2.2.4.SQL 临时表、永久表
- 2.2.5.SQL 外部数据表
- 2.2.6.SQL 视图 VIEW
- 2.2.7.一个 SQL 查询案例
- 2.2.8.SQL 与 DataStream API 的转换
- 2.3.SQL 数据类型
-
- 2.3.1.原子数据类型
- 2.3.2.复合数据类型
- 2.3.3.用户自定义数据类型
- 2.4.SQL 动态表 & 连续查询
-
- 2.4.1.SQL 应用于流处理的思路
- 2.4.2.流批处理的异同点及将 SQL 应用于流处理核心解决的问题
- 2.4.3.SQL 流处理的输入:输入流映射为 SQL 动态输入表
- 2.4.4.SQL 流处理的计算:实时处理底层技术 - SQL 连续查询
- 2.4.5.SQL 流处理实际应用:动态表 & 连续查询技术的两个实战案例
- 2.4.6.SQL 连续查询的两种类型:更新(Update)查询 & 追加(Append)查询
- 2.4.7.SQL 流处理的输出:动态输出表转化为输出数据
- 2.4.8.补充知识:SQL 与关系代数
- 2.5.SQL 的时间属性
-
- 2.5.1.Flink 三种时间属性简介
- 2.5.2.Flink 三种时间属性的应用场景
- 2.5.3.SQL 指定时间属性的两种方式
- 2.5.4.SQL 事件时间案例
- 2.5.5.SQL 处理时间案例
- 2.6.SQL 时区问题
-
- 2.6.1.SQL 时区解决的问题
- 2.6.1.SQL 时间类型
- 2.6.2.时区参数生效的 SQL 时间函数
- 2.6.3.事件时间和时区应用案例
- 2.6.4.处理时间和时区应用案例
- 2.6.5.SQL 时间函数返回在流批任务中的异同
1.前言
看了那么多的技术文,你能明白作者想让你在读完文章后学到什么吗?
-
博主会阐明博主期望本文能给小伙伴们带来什么帮助,让小伙伴萌能直观明白博主的心思
-
博主会以实际的应用场景和案例入手,不只是知识点的简单堆砌
-
博主会把重要的知识点的原理进行剖析,让小伙伴萌做到深入浅出
呕心沥血,Flink SQL 成神之路出品。小伙伴萌可以先体验一下下图大纲。由于微信公众号限制上传图片像素,所以博主分隔成了 5 张图片。。。

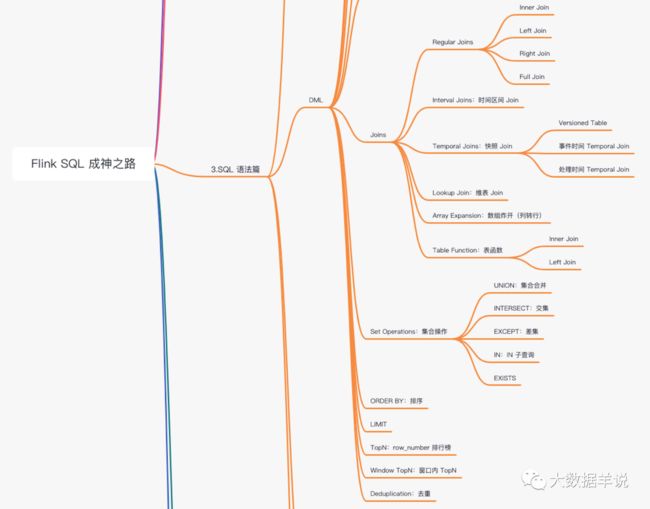


NB
2.基础概念篇
2.1.SQL & Table 简介及运行环境
2.1.1.简介
Apache Flink 提供了两种关系型 API 用于统一流和批处理,Table 和 SQL API。
- ⭐ Table API 是一种集成在 Java、Scala 和 Python 语言中的查询 API,简单理解就是用 Java、Scala、Python 按照 SQL 的查询接口封装了一层 lambda 表达式的查询 API,它允许以强类型接口的方式组合各种关系运算符(如选择、筛选和联接)的查询操作,然后生成一个 Flink 任务运行。如下案例所示:
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.*;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 下面就是 Table API 的案例,其语义等同于
// select a, count(b) as cnt
// from Orders
// group by a
DataSet<Row> result = tEnv
.from("Orders")
.groupBy($("a"))
.select($("a"), $("b").count().as("cnt"))
.toDataSet(counts, Row.class);
result.print();
- ⭐ SQL API 是基于 SQL 标准的 Apache Calcite 框架实现的,我们可以使用纯 SQL 来开发和运行一个 Flink 任务。如下案例所示:
insert into target
select a, count(b) as cnt
from Orders
group by a
注意:无论输入是连续(流处理)还是有界(批处理),在 Table 和 SQL 任一 API 中同一条查询语句是具有相同的语义并且会产出相同的结果的。这就是说为什么 Flink SQL 和 Table API 可以做到在用户接口层面的流批统一。xdm,用一套 SQL 既能跑流任务,也能跑批任务,它不香嘛?
Table API 和 SQL API 也与 DataStream API 做到了无缝集成。可以轻松地在三种 API 之间灵活切换。例如,可以使用 SQL 的 MATCH_RECOGNIZE 子句匹配出异常的数据,然后使用再转为 DataStream API 去灵活的构建针对于异常数据的自定义报警机制。
在 xdm 大体了解了这两个 API 是干啥的之后,我们就可以直接来看看,怎么使用这两个 API 了。
2.1.2.SQL 和 Table API 运行环境依赖
根据小伙伴们使用的编程语言的不同(Java 或 Scala),需要将对应的依赖包添加到项目中。
- ⭐ Java 依赖如下
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.11artifactId>
<version>1.13.5version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.11artifactId>
<version>1.13.5version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>1.13.5version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>1.13.5version>
dependency>
- ⭐ Scala 依赖如下
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-scala-bridge_2.11artifactId>
<version>1.13.5version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_2.11artifactId>
<version>1.13.5version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>1.13.5version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>1.13.5version>
dependency>
引入上述依赖之后,小伙伴萌就可以开始使用 Table\SQL API 了。具体案例如下文所示。
2.2.SQL & Table 的基本概念及常用 API
在小伙伴萌看下文之前,先看一下 2.2 节整体的思路,跟着博主思路走,会更清晰:
-
⭐ 先通过一个 SQL\Table API 任务看一下我们在实际开发时的代码结构应该长啥样,让大家能有直观的感受
-
⭐ 重点介绍 SQL\Table API 中核心 API - TableEnvironment。SQL\Table 所有能用的接口都在 TableEnvironment 中
-
⭐ 通过两个角度(外部表\视图、临时\非临时)认识 Flink SQL 体系中的表的概念
-
⭐ 举几个创建外部表、视图的实际应用案例
2.2.1.一个 SQL\Table API 任务的代码结构
// 创建一个 TableEnvironment,为后续使用 SQL 或者 Table API 提供上线
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 声明为流任务
//.inBatchMode() // 声明为批任务
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 创建一个输入表
tableEnv.executeSql("CREATE TEMPORARY TABLE table1 ... WITH ( 'connector' = ... )");
// 创建一个输出表
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// 1. 使用 Table API 做一个查询并返回 Table
Table table2 = tableEnv.from("table1").select(...);
// 2. 使用 SQl API 做一个查询并返回 Table
Table table3 = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
// 将 table2 的结果使用 Table API 写入 outputTable 中,并返回结果
TableResult tableResult = table2.executeInsert("outputTable");
tableResult...
总结一下上面案例使用到的一些 API,让大家先对 Table\SQL API 的能力有一个大概了解:
-
⭐ TableEnvironment:Table API 和 SQL API 的都集成在一个统一上下文(即 TableEnvironment)中,其地位等同于 DataStream API 中的 StreamExecutionEnvironment 的地位
-
⭐ TableEnvironment::executeSql:用于 SQL API 中,可以执行一段完整 DDL,DML SQL。举例,方法入参可以是
CREATE TABLE xxx,INSERT INTO xxx SELECT xxx FROM xxx。 -
⭐ TableEnvironment::from(xxx):用于 Table API 中,可以以强类型接口的方式运行。方法入参是一个表名称。
-
⭐ TableEnvironment::sqlQuery:用于 SQL API 中,可以执行一段查询 SQL,并把结果以 Table 的形式返回。举例,方法的入参是
SELECT xxx FROM xxx -
⭐ Table::executeInsert:用于将 Table 的结果插入到结果表中。方法入参是写入的目标表。
无论是对于 SQL API 来说还是对于 Table API 来说,都是使用 TableEnvironment 接口承载我们的业务查询逻辑的。只是在用户的使用接口的方式上有区别,以上述的 Java 代码为例,Table API 其实就是模拟 SQL 的查询方式封装了 Java 语言的 lambda 强类型 API,SQL 就是纯 SQL 查询。Table 和 SQL 很多时候都是掺杂在一起的,大家理解的时候就可以直接将 Table 和 SQL API 直接按照 SQL 进行理解,不用强行做特殊的区分。
而且博主推荐的话,直接上 SQL API 就行,其实 Table API 在企业实战中用的不是特别多。你说 Table API 方便吧,它确实比 DataStream API 方便,但是又比 SQL 复杂。一般生产使用不多。
注意:由于 Table 和 SQL API 基本上属于一回事,后续如果没有特别介绍的话,博主就直接按照 SQL API 进行介绍了。
如果 xdm 想直接上手运行一段 Flink SQL 的代码。
2.2.2.SQL 上下文:TableEnvironment
TableEnvironment 是使用 SQL API 永远都离不开的一个接口。其是 SQL API 使用的入口(上下文),就像是你要使用 Java DataStream API 去写一个 Flink 任务需要使用到 StreamExecutionEnvironment 一样。
可以认为 TableEnvironment 在 SQL API 中的地位和 StreamExecutionEnvironment 在 DataStream 中的地位是一样的,都是包含了一个 Flink 任务运行时的所有上下文环境信息。大家这样对比学习会比较好理解。
TableEnvironment 包含的功能如下:
-
⭐ ️Catalog 管理:Catalog 可以理解为 Flink 的 MetaStore,类似 Hive MetaStore 对在 Hive 中的地位,关于 Flink Catalog 的详细内容后续进行介绍
-
⭐ ️表管理:在 Catalog 中注册表
-
⭐️ SQL 查询:(这 TMD 还用说,最基本的功能啊),就像 DataStream 中提供了 addSource、map、flatmap 等接口
-
⭐ UDF 管理:注册用户定义(标量函数:一进一出、表函数:一进多出、聚合函数:多进一出)函数
-
⭐️ UDF 扩展:加载可插拔 Module(Module 可以理解为 Flink 管理 UDF 的模块,是可插拔的,可以让小伙伴萌自定义 Module,去支持奇奇怪怪的 UDF 功能)
-
⭐ DataStream 和 Table(Table\SQL API 的查询结果)之间进行转换:目前 1.13 版本的只有流任务支持,批任务不支持。1.14 支持批任务。
接下来介绍如何创建一个 TableEnvironment。案例为 Java。easy game。
- ⭐ 方法 1:通过 EnvironmentSettings 创建 TableEnvironment
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
// 1. 就是设置一些环境信息
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 声明为流任务
//.inBatchMode() // 声明为批任务
.build();
// 2. 创建 TableEnvironment
TableEnvironment tEnv = TableEnvironment.create(settings);
在 1.13 版本中。
如果你是 inStreamingMode,则最终创建出来的 TableEnvironment 实例为 StreamTableEnvironmentImpl。
如果你是 inBatchMode,则最终创建出来的 TableEnvironment 实例为 TableEnvironmentImpl。
它两虽然都继承了 TableEnvironment 接口,但是 StreamTableEnvironmentImpl 支持的功能更多一些。大家可以直接去看看接口实验一下,这里就不进行详细介绍。
- ⭐ 方法 2:通过已有的 StreamExecutionEnvironment 创建 TableEnvironment
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
2.2.3.SQL 中表的概念
一个表的全名(标识)会由三个部分组成:Catalog 名称.数据库名称.表名称。如果 Catalog 名称或者数据库名称没有指明,就会使用当前默认值 default。
举个例子,下面这个 SQL 创建的 Table 的全名为 default.default.table1。
tableEnv.executeSql("CREATE TEMPORARY TABLE table1 ... WITH ( 'connector' = ... )");
下面这个 SQL 创建的 Table 的全名为 default.mydatabase.table1。
tableEnv.executeSql("CREATE TEMPORARY TABLE mydatabase.table1 ... WITH ( 'connector' = ... )");
表可以是常规的(外部表 TABLE),也可以是虚拟的(视图 VIEW)。
-
⭐ 外部表 TABLE:描述的是外部数据,例如文件(HDFS)、消息队列(Kafka)等。依然拿离线 Hive SQL 举个例子,离线中一个表指的是 Hive 表,也就是所说的外部数据。
-
⭐ 视图 VIEW:从已经存在的表中创建,视图一般是一个 SQL 逻辑的查询结果。对比到离线的 Hive SQL 中,在离线的场景(Hive 表)中 VIEW 也都是从已有的表中去创建的。其实 Flink 也是一样的。
注意:
这里有不同的地方就是,离线 Hive MetaStore 中不会有 Catalog 这个概念,其标识都是
数据库.数据表。
2.2.4.SQL 临时表、永久表
表(视图、外部表)可以是临时的,并与单个 Flink session(可以理解为 Flink 任务运行一次就是一个 session)的生命周期绑定。
表(视图、外部表)也可以是永久的,并且对多个 Flink session 都生效。
- ⭐ 临时表:通常保存于内存中并且仅在创建它们的 Flink session(可以理解为一次 Flink 任务的运行)持续期间存在。这些表对于其它 session(即其他 Flink 任务或非此次运行的 Flink 任务)是不可见的。因为这个表的元数据没有被持久化。如下案例:
-- 临时外部表
CREATE TEMPORARY TABLE source_table (
user_id BIGINT,
`name` STRING
) WITH (
'connector' = 'user_defined',
'format' = 'json',
'class.name' = 'flink.examples.sql._03.source_sink.table.user_defined.UserDefinedSource'
);
-- 临时视图
CREATE TEMPORARY VIEW query_view as
SELECT
*
FROM source_table
;
- ⭐ 永久表:需要外部 Catalog(例如 Hive Metastore)来持久化表的元数据。一旦永久表被创建,它将对任何连接到这个 Catalog 的 Flink session 可见且持续存在,直至从 Catalog 中被明确删除。如下案例:
-- 永久外部表。需要外部 Catalog 持久化!!!
CREATE TABLE source_table (
user_id BIGINT,
`name` STRING
) WITH (
'connector' = 'user_defined',
'format' = 'json',
'class.name' = 'flink.examples.sql._03.source_sink.table.user_defined.UserDefinedSource'
);
-- 永久视图。需要外部 Catalog 持久化!!!
CREATE VIEW query_view as
SELECT
*
FROM source_table
;
- ⭐ 如果临时表和永久表使用了相同的名称(Catalog名.数据库名.表名)。那么在这个 Flink session 中,你的任务访问到这个表时,访问到的永远是临时表(即相同名称的表,临时表会屏蔽永久表)。
2.2.5.SQL 外部数据表
由于目前在实时数据的场景中多以消息队列作为数据表。此处就以 Kafka 为例创建一个外部数据表。
- ⭐ Table API 创建外部数据表
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// kafka 数据源
DataStream<Row> r = env.addSource(new FlinkKafkaConsumer<Row>(xxx));
// 将 DataStream 转为一个 Table API 中的 Table 对象进行使用
Table sourceTable = tEnv.fromDataStream(r
, Schema
.newBuilder()
.column("f0", "string")
.column("f1", "string")
.column("f2", "bigint")
.columnByExpression("proctime", "PROCTIME()")
.build());
tEnv.createTemporaryView("source_table", sourceTable);
String selectWhereSql = "select f0 from source_table where f1 = 'b'";
Table resultTable = tEnv.sqlQuery(selectWhereSql);
tEnv.toRetractStream(resultTable, Row.class).print();
env.execute();
}
上述案例中,Table API 将一个 DataStream 的结果集通过 StreamTableEnvironment::fromDataStream 转为一个 Table 对象来使用。
- ⭐ SQL API 创建外部数据表
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// SQL API 执行 create table 创建表
tEnv.executeSql(
"CREATE TABLE KafkaSourceTable (\n"
+ " `f0` STRING,\n"
+ " `f1` STRING\n"
+ ") WITH (\n"
+ " 'connector' = 'kafka',\n"
+ " 'topic' = 'topic',\n"
+ " 'properties.bootstrap.servers' = 'localhost:9092',\n"
+ " 'properties.group.id' = 'testGroup',\n"
+ " 'format' = 'json'\n"
+ ")"
);
Table t = tEnv.sqlQuery("SELECT * FROM KafkaSourceTable");
具体的创建方式就是使用 Create Table xxx DDL 定义一个 Kafka 数据源(输入)表(也可以是 Kafka 数据汇(输出)表)。

9
xdm,是不是又和 Hive 一样?惊不惊喜意不意外。对比学习 +1。
2.2.6.SQL 视图 VIEW
上文已经说了,一个 VIEW 其实就是一段 SQL 逻辑的查询结果。
视图 VIEW 在 Table API 中的体现就是:一个 Table 的 Java 对象,其封装了一段查询逻辑。如下案例所示:
- ⭐ Table API 创建 VIEW
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 声明为流任务
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// Table API 中的一个 Table 对象
Table projTable = tEnv.from("X").select(...);
// 将 projTable 创建为一个叫做 projectedTable 的 VIEW
tEnv.createTemporaryView("projectedTable", projTable);
Table API 是使用了 TableEnvironment::createTemporaryView 接口将一个 Table 对象创建为一个 VIEW。
- ⭐ SQL API 创建 VIEW
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 声明为流任务
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
String sql = "CREATE TABLE source_table (\n"
+ " user_id BIGINT,\n"
+ " `name` STRING\n"
+ ") WITH (\n"
+ " 'connector' = 'user_defined',\n"
+ " 'format' = 'json',\n"
+ " 'class.name' = 'flink.examples.sql._03.source_sink.table.user_defined.UserDefinedSource'\n"
+ ");\n"
+ "\n"
+ "CREATE TABLE sink_table (\n"
+ " user_id BIGINT,\n"
+ " name STRING\n"
+ ") WITH (\n"
+ " 'connector' = 'print'\n"
+ ");\n"
+ "CREATE VIEW query_view as\n" // 创建 VIEW
+ "SELECT\n"
+ " *\n"
+ "FROM source_table\n"
+ ";\n"
+ "INSERT INTO sink_table\n"
+ "SELECT\n"
+ " *\n"
+ "FROM query_view;";
Arrays.stream(sql.split(";"))
.forEach(tEnv::executeSql);
SQL API 是直接通过一段 CREATE VIEW query_view as select * from source_table 来创建的 VIEW,是纯 SQL 写法。
9
这种创建方式是不是贼熟悉,和离线 Hive 一样 +1~
注意:
在 Table API 中的一个 Table 对象被后续的多个查询使用的场景下:Table 对象不会真的产生一个中间表供下游多个查询去引用,即多个查询不共享这个 Table 的结果,小伙伴萌可以理解为是一种中间表的简化写法,不会先产出一个中间表结果,然后将这个结果在下游多个查询中复用,后续的多个查询会将这个 Table 的逻辑执行多次。类似于 with tmp as (DML) 的语法
2.2.7.一个 SQL 查询案例
首先,如果 xdm 想直接上手运行一段 Flink SQL 的代码。
来看看一个 SQL 查询案例。
-
⭐ 案例场景:计算每一种商品(sku_id 唯一标识)的售出个数、总销售额、平均销售额、最低价、最高价
-
⭐ 数据准备:数据源为商品的销售流水(sku_id:商品,price:销售价格),然后写入到 Kafka 的指定 topic(sku_id:商品,count_result:售出个数、sum_result:总销售额、avg_result:平均销售额、min_result:最低价、max_result:最高价)当中
-
⭐ 任务代码:
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 声明为流任务
//.inBatchMode() // 声明为批任务
.build();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 1. 创建一个数据源(输入)表,这里的数据源是 flink 自带的一个随机 mock 数据的数据源。
String sourceSql = "CREATE TABLE source_table (\n"
+ " sku_id STRING,\n"
+ " price BIGINT\n"
+ ") WITH (\n"
+ " 'connector' = 'datagen',\n"
+ " 'rows-per-second' = '1',\n"
+ " 'fields.sku_id.length' = '1',\n"
+ " 'fields.price.min' = '1',\n"
+ " 'fields.price.max' = '1000000'\n"
+ ")";
// 2. 创建一个数据汇(输出)表,输出到 kafka 中
String sinkSql = "CREATE TABLE sink_table (\n"
+ " sku_id STRING,\n"
+ " count_result BIGINT,\n"
+ " sum_result BIGINT,\n"
+ " avg_result DOUBLE,\n"
+ " min_result BIGINT,\n"
+ " max_result BIGINT,\n"
+ " PRIMARY KEY (`sku_id`) NOT ENFORCED\n"
+ ") WITH (\n"
+ " 'connector' = 'upsert-kafka',\n"
+ " 'topic' = 'tuzisir',\n"
+ " 'properties.bootstrap.servers' = 'localhost:9092',\n"
+ " 'key.format' = 'json',\n"
+ " 'value.format' = 'json'\n"
+ ")";
// 3. 执行一段 group by 的聚合 SQL 查询
String selectWhereSql = "insert into sink_table\n"
+ "select sku_id,\n"
+ " count(*) as count_result,\n"
+ " sum(price) as sum_result,\n"
+ " avg(price) as avg_result,\n"
+ " min(price) as min_result,\n"
+ " max(price) as max_result\n"
+ "from source_table\n"
+ "group by sku_id";
tEnv.executeSql(sourceSql);
tEnv.executeSql(sinkSql);
tEnv.executeSql(selectWhereSql);
2.2.8.SQL 与 DataStream API 的转换
大家会比较好奇,要写 SQL 就纯 SQL 呗,要写 DataStream 就纯 DataStream 呗,为啥还要把这两类接口做集成呢?
博主举一个案例:在 pdd 这种发补贴券的场景下,希望可以在发的补贴券总金额超过 1w 元时,及时报警出来,来帮助控制预算,防止发的太多。
对应的解决方案,我们可以想到使用 SQL 计算补贴券发放的结果,但是 SQL 的问题在于无法做到报警。所以我们可以将 SQL 的查询的结果(即 Table 对象)转为 DataStream,然后就可以在 DataStream 后自定义报警逻辑的算子。
我们直接上 SQL 和 DataStream API 互相转化的案例:
public static void main(String[] args) throws Exception {
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
// 1. pdd 发补贴券流水数据
String createTableSql = "CREATE TABLE source_table (\n"
+ " id BIGINT,\n" -- 补贴券的流水 id
+ " money BIGINT,\n" -- 补贴券的金额
+ " row_time AS cast(CURRENT_TIMESTAMP as timestamp_LTZ(3)),\n"
+ " WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n"
+ ") WITH (\n"
+ " 'connector' = 'datagen',\n"
+ " 'rows-per-second' = '1',\n"
+ " 'fields.id.min' = '1',\n"
+ " 'fields.id.max' = '100000',\n"
+ " 'fields.money.min' = '1',\n"
+ " 'fields.money.max' = '100000'\n"
+ ")\n";
// 2. 计算总计发放补贴券的金额
String querySql = "SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, \n"
+ " window_start, \n"
+ " sum(money) as sum_money,\n" -- 补贴券的发放总金额
+ " count(distinct id) as count_distinct_id\n"
+ "FROM TABLE(CUMULATE(\n"
+ " TABLE source_table\n"
+ " , DESCRIPTOR(row_time)\n"
+ " , INTERVAL '5' SECOND\n"
+ " , INTERVAL '1' DAY))\n"
+ "GROUP BY window_start, \n"
+ " window_end";
flinkEnv.streamTEnv().executeSql(createTableSql);
Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
// 3. 将金额结果转为 DataStream,然后自定义超过 1w 的报警逻辑
flinkEnv.streamTEnv()
.toDataStream(resultTable, Row.class)
.flatMap(new FlatMapFunction<Row, Object>() {
@Override
public void flatMap(Row value, Collector<Object> out) throws Exception {
long l = Long.parseLong(String.valueOf(value.getField("sum_money")));
if (l > 10000L) {
log.info("报警,超过 1w");
}
}
});
flinkEnv.env().execute();
}
注意:
目前在 1.13 版本中,Flink 对于 Table 和 DataStream 的转化是有一些限制的:上面的案例可以看到,Table 和 DataStream 之间的转换目前只有
StreamTableEnvironment::toDataStream、StreamTableEnvironment::fromDataStream接口支持。所以其实小伙伴萌可以理解为只有流任务才支持 Table 和 DataStream 之间的转换,批任务是不支持的(虽然可以使用流执行模式处理有界流 - 批数据,也就是模拟按照批执行,但效率较低,这种骚操作不建议大家搞)。
那什么时候才能支持批任务的 Table 和 DataStream 之间的转换呢?1.14 版本支持。1.14 版本中,流和批的都统一到了 StreamTableEnvironment 中,因此就可以做 Table 和 DataStream 的互相转换了。
2.3.SQL 数据类型
在介绍完一些基本概念之后,我们来认识一下,Flink SQL 中的数据类型。
Flink SQL 内置了很多常见的数据类型,并且也为用户提供了自定义数据类型的能力。
总共包含 3 部分:
-
⭐ 原子数据类型
-
⭐ 复合数据类型
-
⭐ 用户自定义数据类型
2.3.1.原子数据类型
- ⭐ 字符串类型:
-
⭐ CHAR、CHAR(n):定长字符串,就和 Java 中的 Char 一样,n 代表字符的定长,取值范围 [1, 2,147,483,647]。如果不指定 n,则默认为 1。
-
⭐ VARCHAR、VARCHAR(n)、STRING:可变长字符串,就和 Java 中的 String 一样,n 代表字符的最大长度,取值范围 [1, 2,147,483,647]。如果不指定 n,则默认为 1。STRING 等同于 VARCHAR(2147483647)。
- ⭐ 二进制字符串类型:
-
⭐ BINARY、BINARY(n):定长二进制字符串,n 代表定长,取值范围 [1, 2,147,483,647]。如果不指定 n,则默认为 1。
-
⭐ VARBINARY、VARBINARY(n)、BYTES:可变长二进制字符串,n 代表字符的最大长度,取值范围 [1, 2,147,483,647]。如果不指定 n,则默认为 1。BYTES 等同于 VARBINARY(2147483647)。
- ⭐ 精确数值类型:
-
⭐ DECIMAL、DECIMAL§、DECIMAL(p, s)、DEC、DEC§、DEC(p, s)、NUMERIC、NUMERIC§、NUMERIC(p, s):固定长度和精度的数值类型,就和 Java 中的 BigDecimal 一样,p 代表数值位数(长度),取值范围 [1, 38];s 代表小数点后的位数(精度),取值范围 [0, p]。如果不指定,p 默认为 10,s 默认为 0。
-
⭐ TINYINT:-128 到 127 的 1 字节大小的有符号整数,就和 Java 中的 byte 一样。
-
⭐ SMALLINT:-32,768 to 32,767 的 2 字节大小的有符号整数,就和 Java 中的 short 一样。
-
⭐ INT、INTEGER:-2,147,483,648 to 2,147,483,647 的 4 字节大小的有符号整数,就和 Java 中的 int 一样。
-
⭐ BIGINT:-9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 的 8 字节大小的有符号整数,就和 Java 中的 long 一样。
- ⭐ 有损精度数值类型:
-
⭐ FLOAT:4 字节大小的单精度浮点数值,就和 Java 中的 float 一样。
-
⭐ DOUBLE、DOUBLE PRECISION:8 字节大小的双精度浮点数值,就和 Java 中的 double 一样。
-
⭐ 关于 FLOAT 和 DOUBLE 的区别可见 https://www.runoob.com/w3cnote/float-and-double-different.html
-
⭐ 布尔类型:BOOLEAN
-
⭐ NULL 类型:NULL
-
⭐ Raw 类型:RAW(‘class’, ‘snapshot’) 。只会在数据发生网络传输时进行序列化,反序列化操作,可以保留其原始数据。以 Java 举例,
class参数代表具体对应的 Java 类型,snapshot代表类型在发生网络传输时的序列化器 -
⭐ 日期、时间类型:
-
⭐ DATE:由
年-月-日组成的不带时区含义的日期类型,取值范围 [0000-01-01, 9999-12-31] -
⭐ TIME、TIME§:由
小时:分钟:秒[.小数秒]组成的不带时区含义的的时间的数据类型,精度高达纳秒,取值范围 [00:00:00.000000000到23:59:59.9999999]。其中 p 代表小数秒的位数,取值范围 [0, 9],如果不指定 p,默认为 0。 -
⭐ TIMESTAMP、TIMESTAMP§、TIMESTAMP WITHOUT TIME ZONE、TIMESTAMP§ WITHOUT TIME ZONE:由
年-月-日 小时:分钟:秒[.小数秒]组成的不带时区含义的时间类型,取值范围 [0000-01-01 00:00:00.000000000, 9999-12-31 23:59:59.999999999]。其中 p 代表小数秒的位数,取值范围 [0, 9],如果不指定 p,默认为 6。 -
⭐ TIMESTAMP WITH TIME ZONE、TIMESTAMP§ WITH TIME ZONE:由
年-月-日 小时:分钟:秒[.小数秒] 时区组成的带时区含义的时间类型,取值范围 [0000-01-01 00:00:00.000000000 +14:59, 9999-12-31 23:59:59.999999999 -14:59]。其中 p 代表小数秒的位数,取值范围 [0, 9],如果不指定 p,默认为 6。 -
⭐ TIMESTAMP_LTZ、TIMESTAMP_LTZ§:由
年-月-日 小时:分钟:秒[.小数秒] 时区组成的带时区含义的时间类型,取值范围 [0000-01-01 00:00:00.000000000 +14:59, 9999-12-31 23:59:59.999999999 -14:59]。其中 p 代表小数秒的位数,取值范围 [0, 9],如果不指定 p,默认为 6。 -
⭐ TIMESTAMP_LTZ 与 TIMESTAMP WITH TIME ZONE 的区别在于:TIMESTAMP WITH TIME ZONE 的时区信息是携带在数据中的,举例:其输入数据应该是 2022-01-01 00:00:00.000000000 +08:00;TIMESTAMP_LTZ 的时区信息不是携带在数据中的,而是由 Flink SQL 任务的全局配置决定的,我们可以由
table.local-time-zone参数来设置时区。 -
⭐ INTERVAL YEAR TO MONTH、 INTERVAL DAY TO SECOND:interval 的涉及到的种类比较多。INTERVAL 主要是用于给 TIMESTAMP、TIMESTAMP_LTZ 添加偏移量的。举例,比如给 TIMESTAMP 加、减几天、几个月、几年。INTERVAL 子句总共涉及到的语法种类如下 Flink SQL 案例所示。
CREATE TABLE sink_table (
result_interval_year TIMESTAMP(3),
result_interval_year_p TIMESTAMP(3),
result_interval_year_p_to_month TIMESTAMP(3),
result_interval_month TIMESTAMP(3),
result_interval_day TIMESTAMP(3),
result_interval_day_p1 TIMESTAMP(3),
result_interval_day_p1_to_hour TIMESTAMP(3),
result_interval_day_p1_to_minute TIMESTAMP(3),
result_interval_day_p1_to_second_p2 TIMESTAMP(3),
result_interval_hour TIMESTAMP(3),
result_interval_hour_to_minute TIMESTAMP(3),
result_interval_hour_to_second TIMESTAMP(3),
result_interval_minute TIMESTAMP(3),
result_interval_minute_to_second_p2 TIMESTAMP(3),
result_interval_second TIMESTAMP(3),
result_interval_second_p2 TIMESTAMP(3)
) WITH (
'connector' = 'print'
);
INSERT INTO sink_table
SELECT
-- Flink SQL 支持的所有 INTERVAL 子句如下,总体可以分为 `年-月`、`日-小时-秒` 两种
-- 1. 年-月。取值范围为 [-9999-11, +9999-11],其中 p 是指有效位数,取值范围 [1, 4],默认值为 2。比如如果值为 1000,但是 p = 2,则会直接报错。
-- INTERVAL YEAR
f1 + INTERVAL '10' YEAR as result_interval_year
-- INTERVAL YEAR(p)
, f1 + INTERVAL '100' YEAR(3) as result_interval_year_p
-- INTERVAL YEAR(p) TO MONTH
, f1 + INTERVAL '10-03' YEAR(3) TO MONTH as result_interval_year_p_to_month
-- INTERVAL MONTH
, f1 + INTERVAL '13' MONTH as result_interval_month
-- 2. 日-小时-秒。取值范围为 [-999999 23:59:59.999999999, +999999 23:59:59.999999999],其中 p1\p2 都是有效位数,p1 取值范围 [1, 6],默认值为 2;p2 取值范围 [0, 9],默认值为 6
-- INTERVAL DAY
, f1 + INTERVAL '10' DAY as result_interval_day
-- INTERVAL DAY(p1)
, f1 + INTERVAL '100' DAY(3) as result_interval_day_p1
-- INTERVAL DAY(p1) TO HOUR
, f1 + INTERVAL '10 03' DAY(3) TO HOUR as result_interval_day_p1_to_hour
-- INTERVAL DAY(p1) TO MINUTE
, f1 + INTERVAL '10 03:12' DAY(3) TO MINUTE as result_interval_day_p1_to_minute
-- INTERVAL DAY(p1) TO SECOND(p2)
, f1 + INTERVAL '10 00:00:00.004' DAY TO SECOND(3) as result_interval_day_p1_to_second_p2
-- INTERVAL HOUR
, f1 + INTERVAL '10' HOUR as result_interval_hour
-- INTERVAL HOUR TO MINUTE
, f1 + INTERVAL '10:03' HOUR TO MINUTE as result_interval_hour_to_minute
-- INTERVAL HOUR TO SECOND(p2)
, f1 + INTERVAL '00:00:00.004' HOUR TO SECOND(3) as result_interval_hour_to_second
-- INTERVAL MINUTE
, f1 + INTERVAL '10' MINUTE as result_interval_minute
-- INTERVAL MINUTE TO SECOND(p2)
, f1 + INTERVAL '05:05.006' MINUTE TO SECOND(3) as result_interval_minute_to_second_p2
-- INTERVAL SECOND
, f1 + INTERVAL '3' SECOND as result_interval_second
-- INTERVAL SECOND(p2)
, f1 + INTERVAL '300' SECOND(3) as result_interval_second_p2
FROM (SELECT TO_TIMESTAMP_LTZ(1640966476500, 3) as f1)
2.3.2.复合数据类型
-
⭐ 数组类型:ARRAY、t ARRAY。数组最大长度为 2,147,483,647。t 代表数组内的数据类型。举例 ARRAY、ARRAY,其等同于 INT ARRAY、STRING ARRAY
-
⭐ Map 类型:MAP
-
⭐ 集合类型:MULTISET、t MULTISET。就和 Java 中的 List 类型,一样,运行重复的数据。举例 MULTISET,其等同于 INT MULTISET
-
⭐ 对象类型:ROW
、ROW 、ROW(n0 t0, n1 t1, …>、ROW(n0 t0 ‘d0’, n1 t1 ‘d1’, …)。就和 Java 中的自定义对象一样。举例:ROW(myField INT, myOtherField BOOLEAN),其等同于 ROW
2.3.3.用户自定义数据类型
用户自定义类型就是运行用户使用 Java 等语言自定义一个数据类型出来。但是目前数据类型不支持使用 CREATE TABLE 的 DDL 进行定义,只支持作为函数的输入输出参数。如下案例:
- ⭐ 第一步,自定义数据类型
public class User {
// 1. 基础类型,Flink 可以通过反射类型信息自动把数据类型获取到
// 关于 SQL 类型和 Java 类型之间的映射见:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/types/#data-type-extraction
public int age;
public String name;
// 2. 复杂类型,用户可以通过 @DataTypeHint("DECIMAL(10, 2)") 注解标注此字段的数据类型
public @DataTypeHint("DECIMAL(10, 2)") BigDecimal totalBalance;
}
- ⭐ 第二步,在 UDF 中使用此数据类型
public class UserScalarFunction extends ScalarFunction {
// 1. 自定义数据类型作为输出参数
public User eval(long i) {
if (i > 0 && i <= 5) {
User u = new User();
u.age = (int) i;
u.name = "name1";
u.totalBalance = new BigDecimal(1.1d);
return u;
} else {
User u = new User();
u.age = (int) i;
u.name = "name2";
u.totalBalance = new BigDecimal(2.2d);
return u;
}
}
// 2. 自定义数据类型作为输入参数
public String eval(User i) {
if (i.age > 0 && i.age <= 5) {
User u = new User();
u.age = 1;
u.name = "name1";
u.totalBalance = new BigDecimal(1.1d);
return u.name;
} else {
User u = new User();
u.age = 2;
u.name = "name2";
u.totalBalance = new BigDecimal(2.2d);
return u.name;
}
}
}
- ⭐ 第三步,在 Flink SQL 中使用
-- 1. 创建 UDF
CREATE FUNCTION user_scalar_func AS 'flink.examples.sql._12_data_type._02_user_defined.UserScalarFunction';
-- 2. 创建数据源表
CREATE TABLE source_table (
user_id BIGINT NOT NULL COMMENT '用户 id'
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '10'
);
-- 3. 创建数据汇表
CREATE TABLE sink_table (
result_row_1 ROW<age INT, name STRING, totalBalance DECIMAL(10, 2)>,
result_row_2 STRING
) WITH (
'connector' = 'print'
);
-- 4. SQL 查询语句
INSERT INTO sink_table
select
-- 4.a. 用户自定义类型作为输出
user_scalar_func(user_id) as result_row_1,
-- 4.b. 用户自定义类型作为输出及输入
user_scalar_func(user_scalar_func(user_id)) as result_row_2
from source_table;
-- 5. 查询结果
+I[+I[9, name2, 2.20], name2]
+I[+I[1, name1, 1.10], name1]
+I[+I[5, name1, 1.10], name1]
2.4.SQL 动态表 & 连续查询
在小伙伴萌看下文之前,先看一下 2.4 节整体的思路,跟着博主思路走,会更清晰:
-
⭐ 先分析一下将 SQL 应用到流处理的思路
-
⭐ SQL 应用于批处理已经很成熟了,通过对比流批处理在输入、数据处理、输出的异同点来分析出将 SQL 应用于流处理的核心要解决的问题点
-
⭐ 分析如何使用
SQL 动态输入表技术来将输入数据流映射到SQL 中的输入表 -
⭐ 分析如何使用
SQL 连续查询技术来将计算逻辑映射到SQL 中的运算语义 -
⭐ 使用
SQL 动态表 & 连续查询技术两种技术方案来将流式 SQL实际应用到两个常见案例中 -
⭐ 分析
SQL 连续查询的两种类型:更新(Update)查询 & 追加(Append)查询 -
⭐ 分析如何使用
SQL 动态输出表技术来将输出数据流映射到SQL 中的输出表
博主认为读完本节你应该掌握:
-
⭐
SQL 动态输入表、SQL 动态输出表 -
⭐
SQL 连续查询的两种类型分别对应的查询场景及 SQL 语义
2.4.1.SQL 应用于流处理的思路
在流式 SQL 诞生之前,所有的基于 SQL 的数据查询都是基于批数据的,没有将 SQL 应用到流数据处理这一说法。
那么如果我们想将 SQL 应用到流处理中,必然要站在巨人的肩膀(批数据处理的流程)上面进行,那么具体的分析思路如下:
-
⭐ 步骤一:先比较
批处理与流处理的异同之处:如果有相同的部分,那么可以直接复用;不同之处才是我们需要重点克服和关注的。 -
⭐ 步骤二:摘出 1 中说到的不同之处,分析如果要满足这个不同之处,目前有哪些技术是类似的
-
⭐ 步骤三:再从这些类似的技术上进一步发展,以满足将 SQL 应用于流任务中
博主下文就会根据上述三个步骤来一步一步介绍 动态表 诞生的背景以及这个概念是如何诞生的。
2.4.2.流批处理的异同点及将 SQL 应用于流处理核心解决的问题
首先对比一下常见的 批处理 和 流处理 中 数据源(输入表)、处理逻辑、数据汇(结果表) 的异同点。
| - | 输入表 | 处理逻辑 | 结果表 |
|---|---|---|---|
| 批处理 | 静态表:输入数据有限、是有界集合 | 批式计算:每次执行查询能够访问到完整的输入数据,然后计算,输出完整的结果数据 | 静态表:数据有限 |
| 流处理 | 动态表:输入数据无限,数据实时增加,并且源源不断 | 流式计算:执行时不能够访问到完整的输入数据,每次计算的结果都是一个中间结果 | 动态表:数据无限 |
对比上述流批处理之后,我们得到了要将 SQL 应用于流式任务的三个要解决的核心点:
-
⭐ SQL 输入表:分析如何将一个实时的,源源不断的输入流数据表示为 SQL 中的输入表。
-
⭐ SQL 处理计算:分析将 SQL 查询逻辑翻译成什么样的底层处理技术才能够实时的处理流式输入数据,然后产出流式输出数据。
-
⭐ SQL 输出表:分析如何将 SQL 查询输出的源源不断的流数据表示为一个 SQL 中的输出表。
将上面 3 个点总结一下,也就引出了本节的 动态表 和 连续查询 两种技术方案:
-
⭐
动态表:源源不断的输入、输出流数据映射到动态表 -
⭐
连续查询:实时处理输入数据,产出输出数据的实时处理技术
2.4.3.SQL 流处理的输入:输入流映射为 SQL 动态输入表
动态表。这里的动态其实是相比于批处理的静态(有界)来说的。
-
⭐ 静态表:应用于批处理数据中,静态表可以理解为是不随着时间
实时进行变化的。一般都是一天、一小时的粒度新生成一个分区。 -
⭐ 动态表:动态表是随时间实时进行变化的。是将 SQL 体系中表的概念应用到 Flink 上面的的核心点。
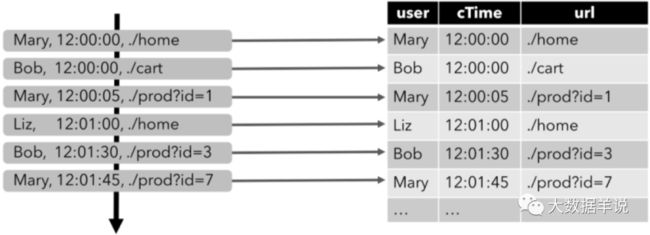
来看一个具体的案例,下图显示了点击事件流(左侧)如何转换为动态表(右侧)。当数据源生成更多的点击事件记录时,映射出来的动态表也会不断增长,这就是动态表的概念:
Dynamic Table
2.4.4.SQL 流处理的计算:实时处理底层技术 - SQL 连续查询
连续查询。
部分高级关系数据库系统提供了一个称为物化视图(Materialized Views) 的特性。
物化视图其实就是一条 SQL 查询,就像常规的虚拟视图 VIEW 一样。但与虚拟视图不同的是,物化视图会缓存查询的结果,因此在请求访问视图时不需要对查询进行重新计算,可以直接获取物化视图的结果,小伙伴萌可以认为物化视图其实就是把结果缓存了下来。
举个例子:批处理中,如果以 Hive 天级别的物化视图来说,其实就是每天等数据源 ready 之后,调度物化视图的 SQL 执行然后产生新的结果提供服务。那么就可以认为一条表示了输入、处理、输出的 SQL 就是一个构建物化视图的过程。
映射到我们的流任务中,输入、处理逻辑、输出这一套流程也是一个物化视图的概念。相比批处理来说,流处理中,我们的数据源表的数据是源源不断的。那么从输入、处理、输出的整个物化视图的维护流程也必须是实时的。
因此我们就需要引入一种实时视图维护(Eager View Maintenance)的技术去做到:一旦更新了物化视图的数据源表就立即更新视图的结果,从而保证输出的结果也是最新的。
这种 实时视图维护(Eager View Maintenance)的技术就叫做 连续查询。
注意:
⭐ 连续查询(Continuous Query) 不断的消费动态输入表的的数据,不断的更新动态结果表的数据。
⭐ 连续查询(Continuous Query) 的产出的结果 = 批处理模式在输入表的上执行的相同查询的结果。相同的 SQL,对应于同一个输入数据,虽然执行方式不同,但是流处理和批处理的结果是永远都会相同的。
2.4.5.SQL 流处理实际应用:动态表 & 连续查询技术的两个实战案例
总结前两节,动态表 & 连续查询 两项技术在一条流 SQL 中的执行流程总共包含了三个步骤,如下图及总结所示:

Query
-
⭐ 第一步:将数据输入流转换为 SQL 中的动态输入表。这里的转化其实就是指将输入流映射(绑定)为一个动态输入表。上图虽然分开画了,但是可以理解为一个东西。
-
⭐ 第二步:在动态输入表上执行一个连续查询,然后生成一个新的动态结果表。
-
⭐ 第三步:生成的动态结果表被转换回数据输出流。
我们实际介绍一个案例来看看其运行方式,以上文介绍到的点击事件流为例,点击事件流数据的字段如下:
[
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问 URL 的时间
url: VARCHAR // 用户访问的 URL
]
- ⭐ 第一步,将输入数据流映射为一个动态输入表。以下图为例,我们将点击事件流(图左)转换为动态表 (图右)。当点击数据源源不断的来到时,动态表的数据也会不断的增加。
Dynamic Table
- ⭐ 第二步,在点击事件流映射的动态输入表上执行一个连续查询(Continuous Query),并生成一个新的动态输出表。
下面介绍两个查询的案例:
第一个查询:一个简单的 GROUP-BY COUNT 聚合查询,写过 SQL 的都不会陌生吧,这种应该都是最基础,最常用的对数据按照类别分组的方法。
如下图所示 group by 聚合的常用案例。

time
那么本案例中呢,是基于 clicks 表中 user 字段对 clicks 表(点击事件流)进行分组,来统计每一个 user 的访问的 URL 的数量。下面的图展示了当 clicks 输入表来了新数据(即表更新时),连续查询(Continuous Query) 的计算逻辑。

group agg
当查询开始,clicks 表(左侧)是空的。
-
⭐ 当第一行数据被插入到 clicks 表时,连续查询(Continuous Query)开始计算结果数据。数据源表第一行数据 [Mary,./home] 输入后,会计算结果 [Mary, 1]
插入(insert)结果表。 -
⭐ 当第二行 [Bob, ./cart] 插入到 clicks 表时,连续查询(Continuous Query)会计算结果 [Bob, 1],并
插入(insert)到结果表。 -
⭐ 第三行 [Mary, ./prod?id=1] 输出时,会计算出[Mary, 2](user 为 Mary 的数据总共来过两条,所以为 2),并
更新(update)结果表,[Mary, 1] 更新成 [Mary, 2]。 -
⭐ 最后,当第四行数据加入 clicks 表时,查询将第三行 [Liz, 1]
插入(insert)结果表中。
注意上述特殊标记出来的字体,可以看到连续查询对于结果的数据输出方式有两种:
-
⭐ 插入(insert)结果表
-
⭐ 更新(update)结果表
大家对于 插入(insert)结果表 这件事都比较好理解,因为离线数据都只有插入这个概念。
但是 更新(update)结果表 就是离线处理中没有概念了。这就是连续查询中中比较重要一个概念。后文会介绍。
接下来介绍第二条查询语句。
第二条查询与第一条类似,但是 group by 中除了 user 字段之外,还 group by 了 tumble,其代表开了个滚动窗口(后面会详细说明滚动窗口的作用),然后计算 url 数量。
group by user,是按照类别(横向)给数据分组,group by tumble 滚动窗口是按时间粒度(纵向)给数据进行分组。如下图所示。

time
图形化一解释就很好理解了,两种都是对数据进行分组,一个是按照 类别 分组,另一种是按照 时间 分组。
与前面一样,左边显示了输入表 clicks。查询每小时持续计算结果并更新结果表。clicks 表有三列,user,cTime,url。其中 cTime 代表数据的时间戳,用于给数据按照时间粒度分组。

tumble window
我们的滚动窗口的步长为 1 小时,即时间粒度上面的分组为 1 小时。其中时间戳在 12:00:00 - 12:59:59 之间有四条数据。13:00:00 - 13:59:59 有三条数据。14:00:00 - 14:59:59 之间有四条数据。
-
⭐ 当 12:00:00 - 12:59:59 数据输入之后,1 小时的窗口,连续查询(Continuous Query)计算的结果如右图所示,将 [Mary, 3],[Bob, 1]
插入(insert)结果表。 -
⭐ 当 13:00:00 - 13:59:59 数据输入之后,1 小时的窗口,连续查询(Continuous Query)计算的结果如右图所示,将 [Bob, 1],[Liz, 2]
插入(insert)结果表。 -
⭐ 当 14:00:00 - 14:59:59 数据输入之后,1 小时的窗口,连续查询(Continuous Query)计算的结果如右图所示,将 [Mary, 1],[Bob, 2],[Liz, 1]
插入(insert)结果表。
而这个查询只有 插入(insert)结果表 这个行为。
2.4.6.SQL 连续查询的两种类型:更新(Update)查询 & 追加(Append)查询
虽然前一节的两个查询看起来非常相似(都计算分组进行计数聚合),但它们在一个重要方面不同:
-
⭐ 第一个查询(group by user),即(Update)查询:会更新先前输出的结果,即结果表流数据中包含 INSERT 和 UPDATE 数据。小伙伴萌可以理解为 group by user 这条语句当中,输入源的数据是一直有的,源源不断的,同一个 user 的数据之后可能还是会有的,因此可以认为此 SQL 的每次的输出结果都是一个中间结果, 当同一个 user 下一条数据到来的时候,就要用新结果把上一次的产出中间结果(旧结果)给 UPDATE 了。所以这就是 UPDATE 查询的由来(其中 INSERT 就是第一条数据到来的时候,没有之前的中间结果,所以是 INSERT)。
-
⭐ 第二个查询(group by user, tumble(xxx)),即(Append)查询:只追加到结果表,即结果表流数据中只包含 INSERT 的数据。小伙伴萌可以理解为虽然 group by user, tumble(xxx) 上游也是一个源源不断的数据,但是这个查询本质上是对时间上的划分,而时间都是越变越大的,当前这个滚动窗口结束之后,后面来的数据的时间都会比这个滚动窗口的结束时间大,都归属于之后的窗口了,当前这个滚动窗口的结果数据就不会再改变了,因此这条查询只有 INSERT 数据,即一个 Append 查询。
上面是 Flink SQL 连续查询处理机制上面的两类查询方式。我们可以发现连续查询的处理机制不一样,产出到结果表中的结果数据也是不一样的。针对上面两种结果表的更新方式,Flink SQL 提出了 changelog 表的概念来进行兼容。
changelog 表这个概念其实就和 MySQL binlog 是一样的。会包含 INSERT、UPDATE、DELETE 三种数据,通过这三种数据的处理来描述实时处理技术对于动态表的变更:
-
⭐ changelog 表:即第一个查询的输出表,输出结果数据不但会追加,还会发生更新
-
⭐ changelog insert-only 表:即第二个查询的输出表,输出结果数据只会追加,不会发生更新
2.4.7.SQL 流处理的输出:动态输出表转化为输出数据
可以看到我们的标题都是随着一个 SQL 的生命周期的。从 输入流映射为 SQL 动态输入表、实时处理底层技术 - SQL 连续查询 到本小节的 SQL 动态输出表转化为输出数据。都是有逻辑关系的。
我们上面介绍到了 连续查询(Continuous Query) 的输出结果表是一个 changelog。其可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。
它可能是一个只有一行、不断更新 changelog 表,也可能是一个 insert-only 的 changelog 表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些不同状态的数据进行编码。Flink 的 Table API 和 SQL API 支持三种方式来编码一个动态表的变化:
-
⭐ Append-only 流:输出的结果只有
INSERT操作的数据。 -
⭐ Retract 流:
-
⭐ Retract 流包含两种类型的 message:add messages 和 retract messages 。其将
INSERT操作编码为 add message、将DELETE操作编码为 retract message、将UPDATE操作编码为更新先前行的 retract message 和更新(新)行的 add message,从而将动态表转换为 retract 流。 -
⭐ Retract 流写入到输出结果表的数据如下图所示,有
-,+两种,分别-代表撤回旧数据,+代表输出最新的数据。这两种数据最终都会写入到输出的数据引擎中。 -
⭐ 如果下游还有任务去消费这条流的话,要注意需要正确处理
-,+两种数据,防止数据计算重复或者错误。

retract
- ⭐ Upsert 流:
-
⭐ Upsert 流包含两种类型的 message:upsert messages 和 delete messages。转换为 upsert 流的动态表需要唯一键(唯一键可以由多个字段组合而成)。其会将
INSERT和UPDATE操作编码为 upsert message,将DELETE操作编码为 delete message。 -
⭐ Upsert 流写入到输出结果表的数据如下图所示,每次输出的结果都是当前每一个 user 的最新结果数据,不会有 Retract 中的
-回撤数据。 -
⭐ 如果下游还有一个任务去消费这条流的话,消费流的算子需要知道唯一键(即 user),以便正确地根据唯一键(user)去拿到每一个 user 当前最新的状态。其与 retract 流的主要区别在于 UPDATE 操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 upsert 流的过程。

upsert
2.4.8.补充知识:SQL 与关系代数
小伙伴萌会问到,关系代数是啥东西?
其实关系代数就是对于数据集(即表)的一系列的 操作(即查询语句)。常见关系代数有:

Relational Algebra
⭐ 那么 SQL 和关系代数是啥关系呢?
SQL 就是能够表示关系代数一种面向用户的接口:即用户能使用 SQL 表达关系代数的处理逻辑,也就是我们可以用 SQL 去在表(数据集)上执行我们的业务逻辑操作(关系代数操作)。
2.5.SQL 的时间属性
在小伙伴萌看下文之前,先看一下 2.5 节整体的思路,跟着博主思路走:
-
⭐ 与离线处理中常见的时间分区字段一样,在实时处理中,时间属性也是一个核心概念。Flink 支持
处理时间、事件时间、摄入时间三种时间语义。 -
⭐ 分别介绍三种时间语义的应用场景及案例。三种时间在生产环境的使用频次
事件时间(SQL 常用)>处理时间(SQL 几乎不用,DataStream 少用)>摄入时间(不用)
2.5.1.Flink 三种时间属性简介

time
-
⭐ 事件时间:指的是数据本身携带的时间,这个时间是在事件产生时的时间,而且在 Flink SQL 触发计算时,也使用数据本身携带的时间。这就叫做
事件时间。目前生产环境中用的最多。 -
⭐ 处理时间:指的是具体算子计算数据执行时的机器时间(例如在算子中 Java 取 System.currentTimeMillis()) ),
在生产环境中用的次多。 -
⭐ 摄入时间:指的是数据从数据源进入 Flink 的时间。
摄入时间用的最少,可以说基本不使用。
小伙伴萌要注意到:
-
⭐ 上述的三种时间概念不是由于有了数据而诞生的,而是有了 Flink 之后根据实际的应用场景而诞生的。以事件时间举个例子,如果只是数据携带了时间,Flink 也消费了这个数据,但是在 Flink 中没有使用数据的这个时间作为计算的触发条件,也不能把这个 Flink 任务叫做事件时间的任务。
-
⭐ 其次,要认识到,一般一个 Flink 任务只会有一个时间属性,所以时间属性通常认为是一个任务粒度的。举例:我们可以说 A 任务是事件时间语义的任务,B 任务是处理时间语义的任务。当然了,一个任务也可以存在多个时间属性。
2.5.2.Flink 三种时间属性的应用场景
讲到这里,xdm 会问,博主上面写的 3 种时间属性到底对我们的任务有啥影响呢?3 种时间属性的应用场景是啥?
先说结论,在 Flink 中时间的作用:
-
⭐
主要体现在包含时间窗口的计算中:用于标识任务的时间进度,来判断是否需要触发窗口的计算。比如常用的滚动窗口、滑动窗口等都需要时间推动触发。这些窗口的应用场景后续会详细介绍。 -
⭐
次要体现在自定义时间语义的计算中:举个例子,比如用户可以自定义每隔 10s 的本地时间,或者消费到的数据的时间戳每增大 10s,就把计算结果输出一次,时间在此类应用中也是一种标识任务进度的作用。
博主以 滚动窗口 的聚合任务为例来介绍一下事件时间和处理时间的对比区别。
- ⭐ 事件时间案例:还是以之前的 clicks 表拿来举例。
tumble window
上面这个案例的窗口大小是 1 小时,需求方需要按照用户点击时间戳 cTime 划分数据(划分滚动窗口),然后计算出 count 聚合结果(这样计算能反映出事件的真实发生时间),那么就需要把 cTime 设置为窗口的划分时间戳,即代码中 tumble(cTime, interval '1' hour)。
上面这种就叫做事件时间。即用数据中自带的时间戳进行窗口的划分(点击操作真实的发生时间)。
后续 Flink SQL 任务在运行的过程中也会实际按照 cTime 的当前时间作为一小时窗口结束触发条件并计算一个小时窗口内的数据。
- ⭐ 处理时间案例:还是以之前的 clicks 表拿来举例。
还是上面那个案例,但是这次需求方不需要按照数据上的时间戳划分数据(划分滚动窗口),只需要数据来了之后, 在 Flink 机器上的时间作为一小时窗口结束的书法条件并计算。
那么这种触发机制就是处理时间。
- ⭐ 摄入时间案例:在 Flink 从外部数据源读取到数据时,给这条数据带上的当前数据源算子的本地时间戳。下游可以用这个时间戳进行窗口聚合,不过这种几乎不使用。
2.5.3.SQL 指定时间属性的两种方式
如果要满足 Flink SQL 时间窗口类的聚合操作,SQL 或 Table API 中的 数据源表 就需要提供时间属性(相当于我们把这个时间属性在 数据源表 上面进行声明),以及支持时间相关的操作。
那么来看看 Flink SQL 为我们提供的两种指定时间戳的方式:
-
⭐
CREATE TABLE DDL创建表的时候指定 -
⭐
可以在 DataStream 中指定,在后续的 DataStream 转的 Table 中使用
一旦时间属性定义好,它就可以像普通列一样使用,也可以在时间相关的操作中使用。
2.5.4.SQL 事件时间案例
来看看 Flink 中如何指定事件时间。
- ⭐
CREATE TABLE DDL指定时间戳的方式。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- 使用下面这句来将 user_action_time 声明为事件时间,并且声明 watermark 的生成规则,即 user_action_time 减 5 秒
-- 事件时间列的字段类型必须是 TIMESTAMP 或者 TIMESTAMP_LTZ 类型
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
-- 然后就可以在窗口算子中使用 user_action_time
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
从上面这条语句可以看到,如果想使用事件时间,那么我们的时间戳类型必须是 TIMESTAMP 或者 TIMESTAMP_LTZ 类型。很多小伙伴会想到,我们的时间戳一般不都是秒或者是毫秒(BIGINT 类型)嘛,那这种情况怎么办?
解决方案必须要有啊。如下。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
-- 1. 这个 ts 就是常见的毫秒级别时间戳
ts BIGINT,
-- 2. 将毫秒时间戳转换成 TIMESTAMP_LTZ 类型
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
-- 3. 使用下面这句来将 user_action_time 声明为事件时间,并且声明 watermark 的生成规则,即 user_action_time 减 5 秒
-- 事件时间列的字段类型必须是 TIMESTAMP 或者 TIMESTAMP_LTZ 类型
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(time_ltz, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(time_ltz, INTERVAL '10' MINUTE);
- ⭐
DataStream中指定事件时间。
之前介绍了 Table 和 DataStream 可以互转,那么 Flink 也提供了一个能力,就是在 Table 转为 DataStream 时,指定时间戳字段。如下案例:
public class DataStreamSourceEventTimeTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// 1. 分配 watermark
DataStream<Row> r = env.addSource(new UserDefinedSource())
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Row>(Time.minutes(0L)) {
@Override
public long extractTimestamp(Row element) {
return (long) element.getField("f2");
}
});
// 2. 使用 f2.rowtime 的方式将 f2 字段指为事件时间时间戳
Table sourceTable = tEnv.fromDataStream(r, "f0, f1, f2.rowtime");
tEnv.createTemporaryView("source_table", sourceTable);
// 3. 在 tumble window 中使用 f2
String tumbleWindowSql =
"SELECT TUMBLE_START(f2, INTERVAL '5' SECOND), COUNT(DISTINCT f0)\n"
+ "FROM source_table\n"
+ "GROUP BY TUMBLE(f2, INTERVAL '5' SECOND)"
;
Table resultTable = tEnv.sqlQuery(tumbleWindowSql);
tEnv.toDataStream(resultTable, Row.class).print();
env.execute();
}
private static class UserDefinedSource implements SourceFunction<Row>, ResultTypeQueryable<Row> {
private volatile boolean isCancel;
@Override
public void run(SourceContext<Row> sourceContext) throws Exception {
int i = 0;
while (!this.isCancel) {
sourceContext.collect(Row.of("a" + i, "b", System.currentTimeMillis()));
Thread.sleep(10L);
i++;
}
}
@Override
public void cancel() {
this.isCancel = true;
}
@Override
public TypeInformation<Row> getProducedType() {
return new RowTypeInfo(TypeInformation.of(String.class), TypeInformation.of(String.class),
TypeInformation.of(Long.class));
}
}
}
2.5.5.SQL 处理时间案例
来看看 Flink SQL 中如何指定处理时间。
- ⭐
CREATE TABLE DDL指定时间戳的方式。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
-- 使用下面这句来将 user_action_time 声明为处理时间
user_action_time AS PROCTIME()
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
-- 然后就可以在窗口算子中使用 user_action_time
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
- ⭐
DataStream中指定处理时间。
public class DataStreamSourceProcessingTimeTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
// 1. 分配 watermark
DataStream<Row> r = env.addSource(new UserDefinedSource());
// 2. 使用 proctime.proctime 的方式将 f2 字段指为处理时间时间戳
Table sourceTable = tEnv.fromDataStream(r, "f0, f1, f2, proctime.proctime");
tEnv.createTemporaryView("source_table", sourceTable);
// 3. 在 tumble window 中使用 f2
String tumbleWindowSql =
"SELECT TUMBLE_START(proctime, INTERVAL '5' SECOND), COUNT(DISTINCT f0)\n"
+ "FROM source_table\n"
+ "GROUP BY TUMBLE(proctime, INTERVAL '5' SECOND)"
;
Table resultTable = tEnv.sqlQuery(tumbleWindowSql);
tEnv.toDataStream(resultTable, Row.class).print();
env.execute();
}
private static class UserDefinedSource implements SourceFunction<Row>, ResultTypeQueryable<Row> {
private volatile boolean isCancel;
@Override
public void run(SourceContext<Row> sourceContext) throws Exception {
int i = 0;
while (!this.isCancel) {
sourceContext.collect(Row.of("a" + i, "b", System.currentTimeMillis()));
Thread.sleep(10L);
i++;
}
}
@Override
public void cancel() {
this.isCancel = true;
}
@Override
public TypeInformation<Row> getProducedType() {
return new RowTypeInfo(TypeInformation.of(String.class), TypeInformation.of(String.class),
TypeInformation.of(Long.class));
}
}
}
2.6.SQL 时区问题
2.6.1.SQL 时区解决的问题
首先说一下这个问题的背景:
大家想一下离线 Hive 环境中,有遇到过时区时区相关的问题吗?
至少博主目前没有碰到过,因为这个问题在底层的数据集成系统都已经给解决了,小伙伴萌拿到手的 ODS 层表都是已经按照所在地区的时区给格式化好的了。
举个例子:小伙伴萌看到日期分区为 2022-01-01 的 Hive 表时,可以默认认为该分区中的数据就对应到你所在地区的时区的 2022-01-01 日的数据。
但是 Flink 中时区问题要特别引起关注,不加小心就会误用。
而本节 SQL 时区旨在帮助大家了解到以下两个场景的问题:
-
⭐ 在 1.13 之前,DDL create table 中使用
PROCTIME()指定处理时间列时,返回值类型为 TIMESTAMP(3) 类型,而 TIMESTAMP(3) 是不带任何时区信息的,默认为 UTC 时间(0 时区)。 -
⭐ 使用
StreamTableEnvironment::createTemporaryView将 DataStream 转为 Table 时,注册处理时间(proctime.proctime)、事件时间列(rowtime.rowtime)时,两列时间类型也为 TIMESTAMP(3) 类型,不带时区信息。
而以上两个场景就会导致:
-
⭐ 在北京时区的用户使用 TIMESTAMP(3) 类型的时间列开最常用的 1 天的窗口时,划分出来的窗口范围是北京时间的 [2022-01-01 08:00:00, 2022-01-02 08:00:00],而不是北京时间的 [2022-01-01 00:00:00, 2022-01-02 00:00:00]。因为 TIMESTAMP(3) 是默认的 UTC 时间,即 0 时区。
-
⭐ 北京时区的用户将 TIMESTAMP(3) 类型时间属性列转为 STRING 类型的数据展示时,也是 UTC 时区的,而不是北京时间的。
因此充分了解本节的知识内容可以很好的帮你避免时区问题错误。
2.6.1.SQL 时间类型
-
⭐ Flink SQL 支持 TIMESTAMP(不带时区信息的时间)、TIMESTAMP_LTZ(带时区信息的时间)
-
⭐ TIMESTAMP(不带时区信息的时间):是通过一个
年, 月, 日, 小时, 分钟, 秒 和 小数秒的字符串来指定。举例:1970-01-01 00:00:04.001。
-
⭐ 为什么要使用字符串来指定呢?因为此种类型不带时区信息,所以直接用一个字符串指定就好了
-
⭐ 那 TIMESTAMP 字符串的时间代表的是什么时区的时间呢?UTC 时区,也就是默认 0 时区,对应中国北京是东八区
- ⭐ TIMESTAMP_LTZ(带时区信息的时间):没有字符串来指定,而是通过 java 标准 epoch 时间 1970-01-01T00:00:00Z 开始计算的毫秒数。举例:1640966400000
-
⭐ 其时区信息是怎么指定的呢?是通过本次任务中的时区配置参数
table.local-time-zone设置的 -
⭐ 时间戳本身也不带有时区信息,为什么要使用时间戳来指定呢?就是因为时间戳不带有时区信息,所以我们通过配置
table.local-time-zone时区参数之后,就能将一个不带有时区信息的时间戳转换为带有时区信息的字符串了。举例:table.local-time-zone为Asia/Shanghai时,4001 时间戳转化为字符串的效果是1970-01-01 08:00:04.001。
2.6.2.时区参数生效的 SQL 时间函数
以下 SQL 中的时间函数都会受到时区参数的影响,从而做到最后显示给用户的时间、窗口的划分都按照用户设置时区之内的时间。
-
⭐ LOCALTIME
-
⭐ LOCALTIMESTAMP
-
⭐ CURRENT_DATE
-
⭐ CURRENT_TIME
-
⭐ CURRENT_TIMESTAMP
-
⭐ CURRENT_ROW_TIMESTAMP()
-
⭐ NOW()
-
⭐ PROCTIME():其中 PROCTIME() 在 1.13 版本及之后版本,返回值类型是 TIMESTAMP_LTZ(3)
在 Flink SQL client 中执行结果如下:
Flink SQL> SET sql-client.execution.result-mode=tableau;
Flink SQL> CREATE VIEW MyView1 AS SELECT LOCALTIME, LOCALTIMESTAMP, CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP, CURRENT_ROW_TIMESTAMP(), NOW(), PROCTIME();
Flink SQL> DESC MyView1;
+------------------------+-----------------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------------------------+-----------------------------+-------+-----+--------+-----------+
| LOCALTIME | TIME(0) | false | | | |
| LOCALTIMESTAMP | TIMESTAMP(3) | false | | | |
| CURRENT_DATE | DATE | false | | | |
| CURRENT_TIME | TIME(0) | false | | | |
| CURRENT_TIMESTAMP | TIMESTAMP_LTZ(3) | false | | | |
|CURRENT_ROW_TIMESTAMP() | TIMESTAMP_LTZ(3) | false | | | |
| NOW() | TIMESTAMP_LTZ(3) | false | | | |
| PROCTIME() | TIMESTAMP_LTZ(3) *PROCTIME* | false | | | |
+------------------------+-----------------------------+-------+-----+--------+-----------+
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT * FROM MyView1;
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
| LOCALTIME | LOCALTIMESTAMP | CURRENT_DATE | CURRENT_TIME | CURRENT_TIMESTAMP | CURRENT_ROW_TIMESTAMP() | NOW() | PROCTIME() |
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
| 15:18:36 | 2021-04-15 15:18:36.384 | 2021-04-15 | 15:18:36 | 2021-04-15 15:18:36.384 | 2021-04-15 15:18:36.384 | 2021-04-15 15:18:36.384 | 2021-04-15 15:18:36.384 |
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT * FROM MyView1;
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
| LOCALTIME | LOCALTIMESTAMP | CURRENT_DATE | CURRENT_TIME | CURRENT_TIMESTAMP | CURRENT_ROW_TIMESTAMP() | NOW() | PROCTIME() |
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
| 23:18:36 | 2021-04-15 23:18:36.384 | 2021-04-15 | 23:18:36 | 2021-04-15 23:18:36.384 | 2021-04-15 23:18:36.384 | 2021-04-15 23:18:36.384 | 2021-04-15 23:18:36.384 |
+-----------+-------------------------+--------------+--------------+-------------------------+-------------------------+-------------------------+-------------------------+
Flink SQL> CREATE VIEW MyView2 AS SELECT TO_TIMESTAMP_LTZ(4001, 3) AS ltz, TIMESTAMP '1970-01-01 00:00:01.001' AS ntz;
Flink SQL> DESC MyView2;
+------+------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------+------------------+-------+-----+--------+-----------+
| ltz | TIMESTAMP_LTZ(3) | true | | | |
| ntz | TIMESTAMP(3) | false | | | |
+------+------------------+-------+-----+--------+-----------+
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT * FROM MyView2;
+-------------------------+-------------------------+
| ltz | ntz |
+-------------------------+-------------------------+
| 1970-01-01 00:00:04.001 | 1970-01-01 00:00:01.001 |
+-------------------------+-------------------------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT * FROM MyView2;
+-------------------------+-------------------------+
| ltz | ntz |
+-------------------------+-------------------------+
| 1970-01-01 08:00:04.001 | 1970-01-01 00:00:01.001 |
+-------------------------+-------------------------+
Flink SQL> CREATE VIEW MyView3 AS SELECT ltz, CAST(ltz AS TIMESTAMP(3)), CAST(ltz AS STRING), ntz, CAST(ntz AS TIMESTAMP_LTZ(3)) FROM MyView2;
Flink SQL> DESC MyView3;
+-------------------------------+------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+-------------------------------+------------------+-------+-----+--------+-----------+
| ltz | TIMESTAMP_LTZ(3) | true | | | |
| CAST(ltz AS TIMESTAMP(3)) | TIMESTAMP(3) | true | | | |
| CAST(ltz AS STRING) | STRING | true | | | |
| ntz | TIMESTAMP(3) | false | | | |
| CAST(ntz AS TIMESTAMP_LTZ(3)) | TIMESTAMP_LTZ(3) | false | | | |
+-------------------------------+------------------+-------+-----+--------+-----------+
Flink SQL> SELECT * FROM MyView3;
+-------------------------+---------------------------+-------------------------+-------------------------+-------------------------------+
| ltz | CAST(ltz AS TIMESTAMP(3)) | CAST(ltz AS STRING) | ntz | CAST(ntz AS TIMESTAMP_LTZ(3)) |
+-------------------------+---------------------------+-------------------------+-------------------------+-------------------------------+
| 1970-01-01 08:00:04.001 | 1970-01-01 08:00:04.001 | 1970-01-01 08:00:04.001 | 1970-01-01 00:00:01.001 | 1970-01-01 00:00:01.001 |
+-------------------------+---------------------------+-------------------------+-------------------------+-------------------------------+
2.6.3.事件时间和时区应用案例
这里分两类,分别是 TIMESTAMP(不带时区信息的时间)、TIMESTAMP_LTZ(带时区信息的时间) 的事件时间 Flink SQL 任务
- ⭐ TIMESTAMP(不带时区信息的时间)
Flink SQL> CREATE TABLE MyTable2 (
item STRING,
price DOUBLE,
ts TIMESTAMP(3), -- TIMESTAMP 类型的时间戳
WATERMARK FOR ts AS ts - INTERVAL '10' SECOND
) WITH (
'connector' = 'socket',
'hostname' = '127.0.0.1',
'port' = '9999',
'format' = 'csv'
);
Flink SQL> CREATE VIEW MyView4 AS
SELECT
TUMBLE_START(ts, INTERVAL '10' MINUTES) AS window_start,
TUMBLE_END(ts, INTERVAL '10' MINUTES) AS window_end,
TUMBLE_ROWTIME(ts, INTERVAL '10' MINUTES) as window_rowtime,
item,
MAX(price) as max_price
FROM MyTable2
GROUP BY TUMBLE(ts, INTERVAL '10' MINUTES), item;
Flink SQL> DESC MyView4;
+----------------+------------------------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+----------------+------------------------+------+-----+--------+-----------+
| window_start | TIMESTAMP(3) | true | | | |
| window_end | TIMESTAMP(3) | true | | | |
| window_rowtime | TIMESTAMP(3) *ROWTIME* | true | | | |
| item | STRING | true | | | |
| max_price | DOUBLE | true | | | |
+----------------+------------------------+------+-----+--------+-----------+
将数据写入到 MyTable2 中:
> nc -lk 9999
A,1.1,2021-04-15 14:01:00
B,1.2,2021-04-15 14:02:00
A,1.8,2021-04-15 14:03:00
B,2.5,2021-04-15 14:04:00
C,3.8,2021-04-15 14:05:00
C,3.8,2021-04-15 14:11:00
最终结果如下:
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT * FROM MyView4;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_rowtime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | A | 1.8 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | B | 2.5 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT * FROM MyView4;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_rowtime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | A | 1.8 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | B | 2.5 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
通过上述结果可见,使用 TIMESTAMP(不带时区信息的时间) 进开窗,在 UTC 时区下的计算结果与在 Asia/Shanghai 时区下计算的窗口开始时间,窗口结束时间和窗口的时间是相同的。
- ⭐ TIMESTAMP_LTZ(带时区信息的时间)
Flink SQL> CREATE TABLE MyTable3 (
item STRING,
price DOUBLE,
ts BIGINT, -- long 类型的时间戳
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3), -- 转为 TIMESTAMP_LTZ 类型的时间戳
WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '10' SECOND
) WITH (
'connector' = 'socket',
'hostname' = '127.0.0.1',
'port' = '9999',
'format' = 'csv'
);
Flink SQL> CREATE VIEW MyView5 AS
SELECT
TUMBLE_START(ts_ltz, INTERVAL '10' MINUTES) AS window_start,
TUMBLE_END(ts_ltz, INTERVAL '10' MINUTES) AS window_end,
TUMBLE_ROWTIME(ts_ltz, INTERVAL '10' MINUTES) as window_rowtime,
item,
MAX(price) as max_price
FROM MyTable3
GROUP BY TUMBLE(ts_ltz, INTERVAL '10' MINUTES), item;
Flink SQL> DESC MyView5;
+----------------+----------------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+----------------+----------------------------+-------+-----+--------+-----------+
| window_start | TIMESTAMP(3) | false | | | |
| window_end | TIMESTAMP(3) | false | | | |
| window_rowtime | TIMESTAMP_LTZ(3) *ROWTIME* | true | | | |
| item | STRING | true | | | |
| max_price | DOUBLE | true | | | |
+----------------+----------------------------+-------+-----+--------+-----------+
将数据写入 MyTable3:
A,1.1,1618495260000 # 对应到 UTC 时区的时间为 2021-04-15 14:01:00
B,1.2,1618495320000 # 对应到 UTC 时区的时间为 2021-04-15 14:02:00
A,1.8,1618495380000 # 对应到 UTC 时区的时间为 2021-04-15 14:03:00
B,2.5,1618495440000 # 对应到 UTC 时区的时间为 2021-04-15 14:04:00
C,3.8,1618495500000 # 对应到 UTC 时区的时间为 2021-04-15 14:05:00
C,3.8,1618495860000 # 对应到 UTC 时区的时间为 2021-04-15 14:11:00
最终结果如下:
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT * FROM MyView5;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_rowtime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | A | 1.8 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | B | 2.5 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:09:59.999 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT * FROM MyView5;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_rowtime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:09:59.999 | A | 1.8 |
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:09:59.999 | B | 2.5 |
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:09:59.999 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
通过上述结果可见,使用 TIMESTAMP_LTZ(带时区信息的时间) 进开窗,在 UTC 时区下的计算结果与在 Asia/Shanghai 时区下计算的窗口开始时间,窗口结束时间和窗口的时间是不同的,都是按照时区进行格式化的。
2.6.4.处理时间和时区应用案例
Flink SQL 定义处理时间属性列是通过 PROCTIME() 函数来指定的,其返回值类型是 TIMESTAMP_LTZ。
注意:
在 Flink 1.13 之前,
PROCTIME()函数返回类型是 TIMESTAMP,返回值是 UTC 时区的时间戳,例如,上海时间显示为 2021-03-01 12:00:00 时,PROCTIME() 返回值显示 2021-03-01 04:00:00,我们进行使用是错误的。Flink 1.13 修复了这个问题,使用 TIMESTAMP_LTZ 作为 PROCTIME() 的返回类型,这样 Flink 就会自动获取当前时区信息,然后进行处理,不需要用户再进行时区的格式化处理了。
如下案例:
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT PROCTIME();
+-------------------------+
| PROCTIME() |
+-------------------------+
| 2021-04-15 14:48:31.387 |
+-------------------------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT PROCTIME();
+-------------------------+
| PROCTIME() |
+-------------------------+
| 2021-04-15 22:48:31.387 |
+-------------------------+
Flink SQL> CREATE TABLE MyTable1 (
item STRING,
price DOUBLE,
proctime as PROCTIME()
) WITH (
'connector' = 'socket',
'hostname' = '127.0.0.1',
'port' = '9999',
'format' = 'csv'
);
Flink SQL> CREATE VIEW MyView3 AS
SELECT
TUMBLE_START(proctime, INTERVAL '10' MINUTES) AS window_start,
TUMBLE_END(proctime, INTERVAL '10' MINUTES) AS window_end,
TUMBLE_PROCTIME(proctime, INTERVAL '10' MINUTES) as window_proctime,
item,
MAX(price) as max_price
FROM MyTable1
GROUP BY TUMBLE(proctime, INTERVAL '10' MINUTES), item;
Flink SQL> DESC MyView3;
+-----------------+-----------------------------+-------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+-----------------+-----------------------------+-------+-----+--------+-----------+
| window_start | TIMESTAMP(3) | false | | | |
| window_end | TIMESTAMP(3) | false | | | |
| window_proctime | TIMESTAMP_LTZ(3) *PROCTIME* | false | | | |
| item | STRING | true | | | |
| max_price | DOUBLE | true | | | |
+-----------------+-----------------------------+-------+-----+--------+-----------+
将数据写入到 MyTable1 中:
> nc -lk 9999
A,1.1
B,1.2
A,1.8
B,2.5
C,3.8
其输出结果如下:
Flink SQL> SET table.local-time-zone=UTC;
Flink SQL> SELECT * FROM MyView3;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_procime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:10:00.005 | A | 1.8 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:10:00.007 | B | 2.5 |
| 2021-04-15 14:00:00.000 | 2021-04-15 14:10:00.000 | 2021-04-15 14:10:00.007 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
Flink SQL> SET table.local-time-zone=Asia/Shanghai;
Flink SQL> SELECT * FROM MyView3;
+-------------------------+-------------------------+-------------------------+------+-----------+
| window_start | window_end | window_procime | item | max_price |
+-------------------------+-------------------------+-------------------------+------+-----------+
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:10:00.005 | A | 1.8 |
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:10:00.007 | B | 2.5 |
| 2021-04-15 22:00:00.000 | 2021-04-15 22:10:00.000 | 2021-04-15 22:10:00.007 | C | 3.8 |
+-------------------------+-------------------------+-------------------------+------+-----------+
通过上述结果可见,使用处理时间进行开窗,在 UTC 时区下的计算结果与在 Asia/Shanghai 时区下计算的窗口开始时间,窗口结束时间和窗口的时间是不同的,都是按照时区进行格式化的。
2.6.5.SQL 时间函数返回在流批任务中的异同
以下函数:
-
⭐ LOCALTIME
-
⭐ LOCALTIMESTAMP
-
⭐ CURRENT_DATE
-
⭐ CURRENT_TIME
-
⭐ CURRENT_TIMESTAMP
-
⭐ NOW()
在 Streaming 模式下这些函数是每条记录都会计算一次,但在 Batch 模式下,只会在 query 开始时计算一次,所有记录都使用相同的时间结果。
以下时间函数无论是在 Streaming 模式还是 Batch 模式下,都会为每条记录计算一次结果:
-
⭐ CURRENT_ROW_TIMESTAMP()
-
⭐ PROCTIME()