bs4使用
标签的属性
Attributes(属性)
一个标签可以有很多个属性。
比如标签
标签的属性可以被添加、删除或修改。再强调一次,标签的属性操作方法与 Python 字典是一样的!
你可以使用 get_attribute_list() 方法以列表形式获取一个属性值:如果它是多值属性,那么列表中存在多个字符串;否则列表中就只有一个字符串。

如果解析的文档是 XML 格式,那么 tag 中不包含多值属性:
获取标签后的文本
字符串对应的是标签内部包含的文本。BeautifulSoup 使用 NavigableString 类来包装这些文本:
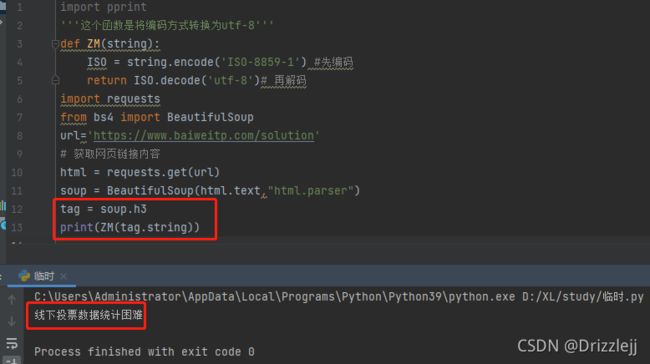
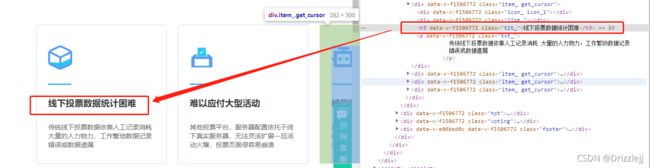
打印的是第一个h3标签包含的文本
如果想在 BeautifulSoup 之外使用 NavigableString 对象,需要调用 str() 方法,将该对象转换成普通的 Unicode 字符串。否则,就算 BeautifulSoup 已经执行结束,该对象也会带有整个 BeautifulSoup 解析树的引用地址,这样会造成内存的巨大浪费。
标签可能包含字符串或其它标签,这些都是这个标签的子节点。BeautifulSoup 提供了许多不同的属性,用于遍历和迭代一个标签的子节点。
注意:BeautifulSoup 中的字符串节点是不支持这些属性的,因为字符串本身没有子节点。
6.1.1 使用标签名进行遍历
获取标签内容
>>> soup.head
获取标签内容</h3>
<p>>>> soup.title<br> <title>睡鼠的故事
你可以重复多次使用这个小技巧来深入解析树的某一个部分。下面代码获取 标签中的第一个
标签:

使用标签名作为属性的方法只能获得当前名字后的第一个标签:
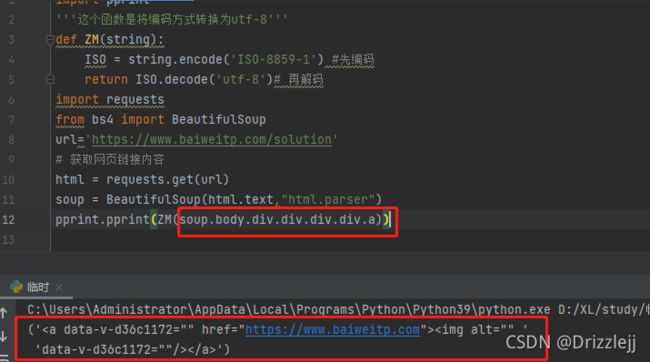 ('
('')
获取所有的 标签
如果想要获取所有的 标签,或者获取一些更复杂的东西时,就要用到在 查找文档树 章节中讲解的一个方法 —— find_all():
soup.find_all('a')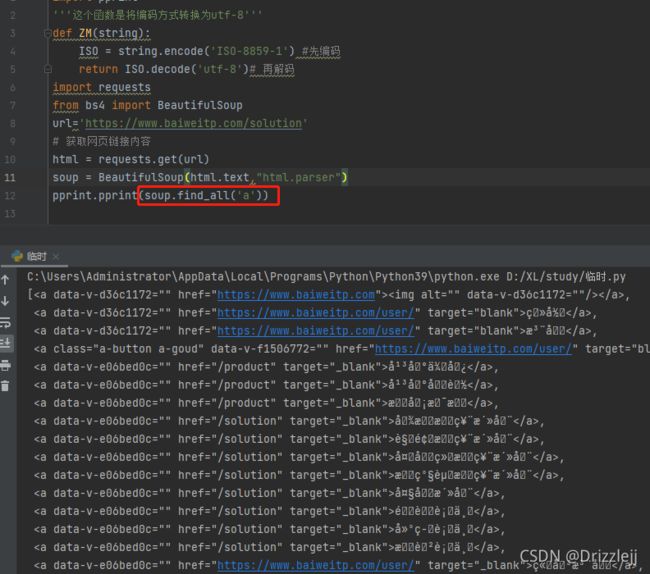
6.1.2 .contents 和 .children
一个标签的子节点可以从一个叫 .contents 的列表中获得:
获取标签子节点
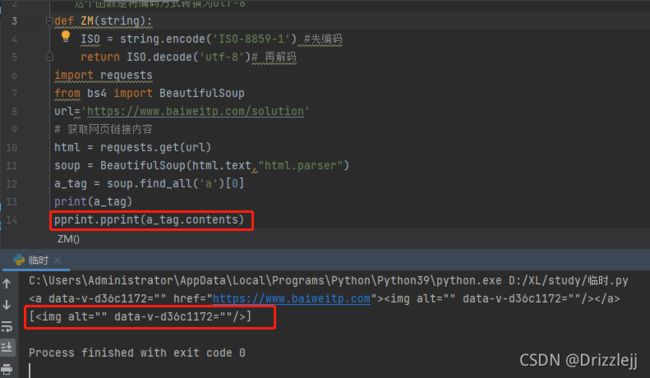
BeautifulSoup 对象本身拥有子节点,也就是说 标签也是 BeautifulSoup 对象的子节点:
>>> len(soup.contents)
1
>>> soup.contents[0].name
'html'
字符串没有 .contents 属性,因此字符串没有子节点:
如果你不想通过 .contents 获取一个列表,还可以通过标签的 .children 属性得到一个生成器:
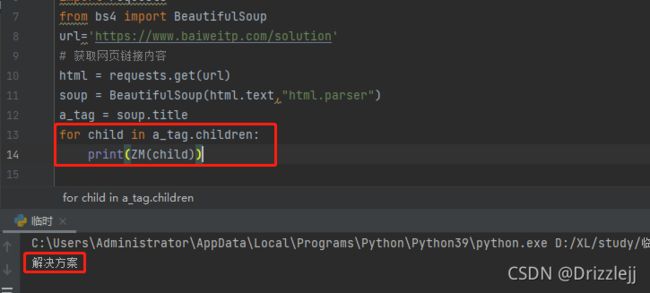
6.1.3 .descendants
.contents 和 .children 属性仅包含标签的直接子节点。如果要对多层子孙节点进行递归迭代,可以使用 .descendants 属性完成任务:
上面的例子中,
>>>
>>> soup.find_all("p", "title")
[
睡鼠的故事
]>>>
>>> soup.find_all("a")
[埃尔西, 莱斯, 蒂尔莉]
>>>
>>> soup.find_all(id="link2")
[莱斯]
>>>
>>> import re
>>> soup.find(string=re.compile("小姐姐"))
'从前有三位小姐姐,她们的名字是:\n'
>>>
上面的 string 和 id 关键字参数代表什么呢?为什么 find_all("p", "title") 返回的是 Class 为 ”title” 的
标签呢?请看下面的参数讲解。
通过 name 参数,你可以根据指定名字来查找标签。
简单的用法如下:
>>> soup.find_all("title")
[
上一节提到的几种过滤器均可以作为 name 参数的值:字符串,正则表达式,列表,函数,或者直接一个布尔类型值 True。
7.2.2 keyword 参数
如果一个指定名字的参数不是搜索内置的(name, attrs, recursive, string, limit)参数名,搜索时会把该参数当作指定 tag 的属性来搜索。
比如你传递一个名为 id 的参数,BeautifulSoup 将会搜索每个 tag 的 ”id” 属性:
>>> soup.find_all(id="link2")
[莱斯]
如果你传递一个名为 href 的参数,BeautifulSoup 将会搜索每个 tag 的 ”href” 属性:
>>> soup.find_all(href=re.compile("elsie"))
[埃尔西]
搜索指定名字的属性时可以使用的参数值包括:字符串、正则表达式、列表、函数和 True 值。
下面的例子在文档树中查找所有包含 id 属性的 tag,无论 id 的值是什么都将匹配:
>>> soup.find_all(id=True)
[埃尔西, 莱斯, 蒂尔莉]
你还可以同时过滤多个属性:
>>> soup.find_all(href=re.compile("elsie"), id="link1")
[埃尔西]
注意:有些 tag 属性在搜索不能使用,比如 HTML5 中的 data-* 属性:
>>> data_soup = BeautifulSoup('
>>> data_soup.find_all(data-foo="value")
SyntaxError: keyword can't be an expression
但是可以通过将这些属性放进一个字典里,然后将其传给 attrs 关键字参数来实现 “曲线救国”:
>>> data_soup.find_all(attrs={"data-foo": "value"})
[
你不能使用关键字参数来搜索 HTML 的 "name" 元素,因为 BeautifulSoup 使用 name 参数来表示标签自身的名字。
取而代之,你可以将 "name" 添加到 attrs 参数的值中:
>>> name_soup = BeautifulSoup('')
>>> name_soup.find_all(name="email")
[]
>>> name_soup.find_all(attrs={"name": "email"})
[]
7.2.3 根据 CSS 进行搜索
按照 CSS 类名搜索标签的功能非常实用,但由于表示 CSS 类名的关键字 “class” 在 Python 中是保留字,所以使用 class 做参数会导致语法错误。从 BeautifulSoup 的 4.1.1 版本开始,可以通过 class_ 参数搜索有指定 CSS 类名的标签:
>>> soup.find_all("a", class_="sister")
[埃尔西, 莱斯, 蒂尔莉]
跟关键字参数一样,class_ 参数也支持不同类型的过滤器:字符串、正则表达式、函数或 True:
>>> soup.find_all(class_=re.compile("itl"))
[
睡鼠的故事
]>>>
>>> def has_six_characters(css_class):
return css_class is not None and len(css_class) == 6
>>> soup.find_all(class_=has_six_characters)
[埃尔西, 莱斯, 蒂尔莉]
注意,标签的 “class” 属性支持同时拥有多个值,按照 CSS 类名搜索标签时,可以分别搜索标签中的每个 CSS 类名:
>>> css_soup = BeautifulSoup('
', "html.parser")>>> css_soup.find_all("p", class_="strikeout")
[]
>>>
>>> css_soup.find_all("p", class_="body")
[]
搜索 class 属性时也可以指定完全匹配的 CSS 值:
>>> css_soup.find_all("p", class_="body strikeout")
[
但如果 CSS 值的顺序与文档不一致,将导致结果搜索不到(尽管其字符串是一样的):
>>> css_soup.find_all("p", class_="strikeout body")
[]
如果你希望搜索结果同时匹配两个以上的 CSS 类名,你应该使用 CSS 选择器:
>>> css_soup.select("p.strikeout.body")
[
在那些没有 class_ 关键字的 BeautifulSoup 版本中,你可以使用 attrs 技巧(上面咱举过一个例子):
>>> soup.find_all("a", attrs={"class": "sister"})
[埃尔西, 莱斯, 蒂尔莉]
7.2.4 string 参数
通过 string 参数可以搜索标签中的文本内容。与 name 参数一样,string 参数接受字符串,正则表达式,列表,函数,或者直接一个布尔类型值 True。
请看下面例子:
>>> soup.find_all(string="埃尔西")
['埃尔西']
>>>
>>> soup.find_all(string=["蒂尔莉", "埃尔西", "莱斯"])
['埃尔西', '莱斯', '蒂尔莉']
>>>
>>> soup.find_all(string=re.compile("睡鼠"))
['睡鼠的故事', '睡鼠的故事']
>>>
>>> def is_the_only_string_within_a_tag(s):
"""如果字符串是其父标签的唯一子节点,则返回 True。"""
return (s == s.parent.string)
>>> soup.find_all(string=is_the_only_string_within_a_tag)
['睡鼠的故事', '睡鼠的故事', '埃尔西', '莱斯', '蒂尔莉', '...']
尽管 string 参数是用于搜索字符串的,但你可以与其它参数混合起来使用:下面代码中,BeautifulSoup 会找到所有与 string 参数值相匹配的 标签:
>>> soup.find_all("a", string="埃尔西")
[埃尔西]
string 参数是 BeautifulSoup 4.4.0 新增加的特性,在早期的版本中,它叫 text 参数:
>>> soup.find_all("a", text="埃尔西")
[埃尔西]
7.2.5 limit 参数
find_all() 方法返回匹配过滤器的所有标签和文本。如果文档树很大,那么搜索就会变得很慢。如果你不需要全部的结果,可以使用 limit 参数限制返回结果的数量。效果与 SQL 中的 LIMIT 关键字类似 —— 当搜索到的结果数量达到 limit 的限制时,就停止搜索并返回结果。
文档树中有 3 个标签符合搜索条件,但结果只返回了 2 个,因为我们限制了返回数量:
>>> soup.find_all("a", limit=2)
[埃尔西, 莱斯]
7.2.6 recursive 参数
如果你调用 mytag.find_all() 方法,BeautifulSoup 将会获取 mytag 的所有子孙节点。如果只想搜索 mytag 的直接子节点,可以使用参数 recursive=False。
对比一下:
>>> soup.html.find_all("title")
[
>>>
>>> soup.html.find_all("title", recursive=False)
[]
文档的原型是这样的:
...
>>> soup.find('title')
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果。find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None 。
>>> print(soup.find("nosuchtag"))
None
>>> print(soup.find_all("nosuchtag"))
[]
soup.head.title 是 6.1 子节点(向下遍历)-使用标签名进行遍历 方法的简写。这个简写的原理就是多次调用当前tag的 find() 方法:
>>> soup.head.title
>>> soup.find("head").find("title")
7.5 find_parents() 和 find_parent()
find_parents(name, attrs, string, limit, **kwargs)
find_parent(name, attrs, string, **kwargs)
我们已经用了很大篇幅来介绍 find_all() 和 find() 方法,Beautiful Soup中还有10个用于搜索的API。它们中的五个用的是与 find_all() 相同的搜索参数。另外5个与 find() 方法的搜索参数类似。区别仅是它们搜索文档的不同部分。
记住:find_all() 和 find() 只搜索当前节点的所有子节点,孙子节点等。 find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,搜索方法与普通tag的搜索方法相同,搜索文档包含的内容。我们从一个文档中的一个叶子节点开始:
>>> a_string = soup.find(text="莱斯")
>>> a_string
'莱斯'
>>> a_string.find_parents("a")
[莱斯]
>>> a_string.find_parents("p")
[
从前有三位小姐姐,她们的名字是:
埃尔西,
莱斯和
蒂尔莉;
她们住在一个井底下面。
>>> a_string.find_parents("p", class_="sister")
[]
文档中的一个标签是是当前叶子节点的直接父节点,所以可以被找到.还有一个
标签,是目标叶子节点的间接父辈节点,所以也可以被找到。包含class值为”title”的
标签不是不是目标叶子节点的父辈节点,所以通过 find_parents() 方法搜索不到。
find_parent() 和 find_parents() 方法会让人联想到 6.2 父节点(向上遍历)中 .parent 和 .parents 属性。它们之间的联系非常紧密。搜索父辈节点的方法实际上就是对 .parents 属性的迭代搜索.
7.6 find_next_siblings() 和 find_next_sibling()
find_next_siblings(name, attrs, string, limit, **kwargs)
find_next_sibling(name, attrs, string, **kwargs)
这2个方法通过 6.3 兄弟节点(左右遍历)中 .next_siblings 属性对当tag的所有后面解析的兄弟tag节点进行迭代,find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点。
>>> first_link = soup.a
>>> first_link
埃尔西
>>> first_link.find_next_siblings("a")
[莱斯, 蒂尔莉]
>>> first_story_paragraph = soup.find("p", "story")
>>> first_story_paragraph.find_next_sibling("p")
...
7.7 find_previous_siblings() 和 find_previous_sibling()
find_previous_siblings() (name, attrs, string, limit, **kwargs)
find_previous_sibling()(name, attrs, string, **kwargs)
这2个方法通过 6.3 兄弟节点(左右遍历)中 .previous_siblings 属性对当前tag的前面解析的兄弟tag节点进行迭代, find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点:
>>> last_link = soup.find("a", id="link3")
>>> last_link
蒂尔莉
>>> last_link.find_previous_siblings("a")
[莱斯, 埃尔西]
>>> first_story_paragraph = soup.find("p", "story")
>>> first_story_paragraph.find_previous_sibling("p")
睡鼠的故事
7.8 find_all_next() 和 find_next()
find_all_next(name, attrs, string, limit, **kwargs)
find_next(name, attrs, string, **kwargs)
这2个方法通过 6.4 回退和前进 中 .next_elements 属性对当前tag的之后的 tag和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点:
>>> first_link = soup.a
>>> first_link
埃尔西
>>> first_link.find_all_next(string=True)
['埃尔西', ',\n', '莱斯', '和\n', '蒂尔莉', ';\n她们住在一个井底下面。', '\n', '...', '\n']
>>> first_link.find_next("p")
...
第一个例子中,字符串 “埃尔西”也被显示出来,尽管它被包含在我们开始查找的标签的里面。第二个例子中,最后一个
标签也被显示出来,尽管它与我们开始查找位置的标签不属于同一部分。例子中,搜索的重点是要匹配过滤器的条件,并且在文档中出现的顺序而不是开始查找的元素的位置。
7.9 find_all_previous() 和 find_previous()
find_all_previous(name, attrs, string, limit, **kwargs)
find_previous(name, attrs, string, **kwargs)
这2个方法通过 6.4 回退和前进 中 .previous_elements 属性对当前节点前面 的tag和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous() 方法返回第一个符合条件的节点。
>>> first_link = soup.a
>>> first_link
埃尔西
>>> first_link.find_all_previous("p")
[
从前有三位小姐姐,她们的名字是:
埃尔西,
莱斯和
蒂尔莉;
她们住在一个井底下面。
睡鼠的故事
]>>> first_link.find_previous("title")
find_all_previous("p") 返回了文档中的第一段(class=”title”的那段),但还返回了第二段,
标签包含了我们开始查找的标签。不要惊讶,这段代码的功能是查找所有出现在指定标签之前的 标签,因为这个 标签包含了开始的标签,所以 标签一定是在之前出现的。 7.10 CSS选择器 BeautifulSoup有一个.select()方法,该方法使用SoupSieve对解析的文档运行CSS选择器并返回所有匹配的元素。 Tag有一个类似的方法,它针对单个标记的内容运行CSS选择器。 (早期版本的Beautiful Soup也有.select()方法,但只支持最常用的CSS选择器。) SoupSieve文档 列出了所有当前支持的CSS选择器,但以下是一些基础知识: 可以使用CSS选择器的语法找到tag: >>> soup.select("title") ... >>> soup.select("body a")
从版本4.7.0开始,Beautiful Soup通过 SoupSieve 项目支持大多数CSS4选择器。 如果您通过pip安装了Beautiful Soup,则同时安装了SoupSieve,因此您无需执行任何额外操作。
[
>>> soup.select("p:nth-of-type(3)")
[
通过tag标签逐层查找:
[埃尔西, 莱斯, 蒂尔莉]
>>> soup.select("html head title")
[
找到某个tag标签下的直接子标签:
>>> soup.select("head > title")
[
>>> soup.select("p > a")
[埃尔西, 莱斯, 蒂尔莉]
>>> soup.select("p > a:nth-of-type(2)")
[莱斯]
>>> soup.select("p > #link1")
[埃尔西]
>>> soup.select("body > a")
[]
找到兄弟节点标签:
>>> soup.select("#link1 ~ .sister")
[莱斯, 蒂尔莉]
>>> soup.select("#link1 + .sister")
[莱斯]
通过CSS的类名查找:
>>> soup.select(".sister")
[埃尔西, 莱斯, 蒂尔莉]
>>> soup.select("[class~=sister]")
[埃尔西, 莱斯, 蒂尔莉]
通过tag的ID查找:
>>> soup.select("#link1")
[埃尔西]
>>> soup.select("a#link2")
[莱斯]
查找与选择器列表中的任何选择器匹配的tag:
>>> soup.select("#link1,#link2")
[埃尔西, 莱斯]
通过是否存在某个属性来查找:
>>> soup.select('a[href]')
[埃尔西, 莱斯, 蒂尔莉]
通过属性的值来查找:
>>> soup.select('a[href="http://example.com/elsie"]')
[埃尔西]
>>> soup.select('a[href^="http://example.com/"]')
[埃尔西, 莱斯, 蒂尔莉]
>>> soup.select('a[href$="tillie"]')
[蒂尔莉]
>>> soup.select('a[href*=".com/el"]')
[埃尔西]
还有一个名为 select_one()的方法,它只查找与选择器匹配的第一个标记:
>>> soup.select_one(".sister")
埃尔西
如果您已经解析了定义名称空间的XML,则可以在CSS选择器中使用它们:
>>>from bs4 import BeautifulSoup
>>>xml = """
>>>soup = BeautifulSoup(xml, "xml")
>>>soup.select("child")
[
>>>soup.select("ns1|child", namespaces=namespaces)
[
注意:这里需要安装 xml 解析库,如果出现以下报错:
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: xml. Do you need to install a parser library?
需要 通过 pip install lxml 安装 lxml:
处理使用命名空间的CSS选择器时,Beautiful Soup使用在解析文档时找到的命名空间缩写。 您可以通过传入自己的缩写词典来覆盖它:
>>>namespaces = dict(first="http://namespace1/", second="http://namespace2/")
>>>soup.select("second|child", namespaces=namespaces)
[
所有这些CSS选择器的东西对于已经知道CSS选择器语法的人来说都很方便。 您可以使用Beautiful Soup API完成所有这些工作。 如果你只需要CSS选择器,你应该使用lxml解析文档:它的速度要快得多。 但是这可以让你将CSS选择器与Beautiful Soup API结合起来。
8 修改文档树
Beautiful Soup的主要优势在于搜索解析树,但您也可以修改树并将更改写为新的HTML或XML文档。
8.1 修改tag的名称和属性
在 5.1 Tag(标签)- Attributes(属性) 章节中已经介绍过这个功能,但是再看一遍也无妨. 重命名一个tag,改变属性的值,添加或删除属性:
>>> soup = BeautifulSoup('Extremely bold')
>>> tag = soup.b
>>> tag.name = "blockquote"
>>> tag['class'] = 'verybold'
>>> tag['id'] = 1
>>> tag
Extremely bold
>>> del tag['class']
>>> del tag['id']
>>> tag
Extremely bold
8.2 修改 .string
给tag的 .string 属性赋值,就相当于用当前的内容替代了原来的内容:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag.string = "New link text."
>>> tag
New link text.
注意:如果当前的tag包含了其它tag,那么给它的 .string 属性赋值会覆盖掉原有的所有内容包括子tag。
8.3 append()
Tag.append() 方法想tag中添加内容,就好像Python的列表的 .append() 方法:
>>> soup = BeautifulSoup("Foo")
>>> soup.a.append("Bar")
>>> soup
FooBar
>>> soup.a.contents
['Foo', 'Bar']
8.4 extend()
从Beautiful Soup 4.7.0开始,Tag还支持一个名为.extend()的方法,它就像在Python列表上调用.extend()一样:
>>> soup = BeautifulSoup("Soup")
>>> soup.a.extend(["'s", " ", "on"])
>>> soup
Soup's on
>>> soup.a.contents
['Soup', "'s", ' ', 'on']
8.5 NevigableString() 和 .new_tag()
如果想添加一段文本内容到文档中也没问题,可以调用Python的 append() 方法或调用 NavigableString() 构造函数: :
>>> soup = BeautifulSoup("")
>>> tag = soup.b
>>> tag.append("Hello")
>>> new_string = NavigableString(" there")
>>> tag.append(new_string)
>>> tag
Hello there.
>>> tag.contents
['Hello', ' there']
如果要创建注释或NavigableString的其他子类,只需调用构造函数:
>>> from bs4 import Comment
>>> new_comment = Comment("Nice to see you.")
>>> tag.append(new_comment)
>>> tag
Hello there
>>> tag.contents
['Hello', ' there', 'Nice to see you.']
(这是Beautiful Soup 4.4.0的新功能。)
创建一个tag最好的方法是调用工厂方法 BeautifulSoup.new_tag() :
>>> soup = BeautifulSoup("")
>>> original_tag = soup.b
>>> new_tag = soup.new_tag("a", href="http://www.example.com")
>>> original_tag.append(new_tag)
>>> original_tag
>>> new_tag.string = "Link text."
>>> original_tag
Link text.
第一个参数作为tag的name,是必填,其它参数选填。
8.6 insert()
Tag.insert() 方法与 Tag.append() 方法类似,区别是不会把新元素添加到父节点 .contents 属性的最后,而是把元素插入到指定的位置。与Python列表总的 .insert() 方法的用法相同:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag.insert(1, "but did not endorse ")
>>> tag
I linked to but did not endorse example.com
>>> tag.contents
['I linked to ', 'but did not endorse ', example.com]
8.7 insert_before() 和 insert_after()
insert_before() 方法在当前tag或文本节点前插入tag 或者 字符串:
>>> soup = BeautifulSoup("stop")
>>> tag = soup.new_tag("i")
>>> tag.string = "Don't"
>>> soup.b.string.insert_before(tag)
>>> soup.b
Don'tstop
insert_after() 方法在当前tag或文本节点前插入tag 或者 字符串:
>>> div = soup.new_tag('div')
>>> div.string = 'ever'
>>> soup.b.i.insert_after(" you ", div)
>>> soup.b
Don't you
>>> soup.b.contents
[Don't, ' you ',
8.8 clear()
Tag.clear() 方法移除当前tag的内容:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag.clear()
>>> tag
8.9 extract()
PageElement.extract() 方法将当前tag移除文档树,并作为方法结果返回:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> i_tag = soup.i.extract()
>>> a_tag
I linked to
>>> i_tag
example.com
>>> print(i_tag.parent)
None
这个方法实际上产生了2个文档树: 一个是用来解析原始文档的 BeautifulSoup 对象,另一个是被移除并且返回的tag。被移除并返回的tag可以继续调用 extract 方法:
>>> my_string = i_tag.string.extract()
>>> my_string
'example.com'
>>> print(my_string.parent)
None
>>> i_tag
8.10 decompose()
Tag.decompose() 方法将当前节点移除文档树并完全销毁:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> soup.i.decompose()
>>> a_tag
I linked to
8.11 replace_with()
PageElement.replace_with() 方法移除文档树中的某段内容,并用新tag或文本节点替代它:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> new_tag = soup.new_tag("b")
>>> new_tag.string = "example.net"
>>> a_tag.i.replace_with(new_tag)
>>> a_tag
I linked to example.net
replace_with() 方法返回被替代的tag或文本节点,可以用来浏览或添加到文档树其它地方
8.12 wrap()
PageElement.wrap() 方法可以对指定的tag元素进行包装,并返回包装后的结果:
>>> soup = BeautifulSoup("
I wish I was bold.
")>>> soup.p.string.wrap(soup.new_tag("b"))
I wish I was bold.
>>> soup.p.wrap(soup.new_tag("div")
I wish I was bold.
该方法在 Beautiful Soup 4.0.5 中添加
8.13 unwrap()
Tag.unwrap() 方法与 wrap() 方法相反。将移除tag内的所有tag标签,该方法常被用来进行标记的解包:
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> a_tag.i.unwrap()
>>> a_tag
I linked to example.com
与 replace_with() 方法相同, unwrap() 方法返回被移除的tag。
九、输出
9.1 格式化输出
prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行
>>> markup = 'I linked to example.com'
>>> soup = BeautifulSoup(markup)
>>> soup.prettify()
'\n