Python多线程慎用shutil.make_archive打包
Python多线程慎用shutil.make_archive打包
记一下在工作中遇到一个错误,先说一下结论shutil.make_archive是线程不安全的,要慎重使用!!!
参考:https://stackoverflow.com/questions/41625702/is-shutil-make-archive-thread-safe
本篇文章会分别从多线程下使用shutil.make_archive打包会导致什么问题、原因是什么、如何解决三个方面进行讲解。
1 导致的问题
这里写个测试程序,按照规则创建一个文件夹,然后将这个文件夹打包成zip
def make_archive_use_shutil(f_number):
p = f'test_archives/{f_number}'
os.makedirs(p)
print(f'archive: {f_number}.zip\n')
shutil.make_archive(base_name=p, format='zip', root_dir=p)
单线程调用:
if __name__ == '__main__':
shutil.rmtree('test_archives',ignore_errors=True)
total = 1
with ThreadPoolExecutor(max_workers=10) as executor:
fs = [executor.submit(make_archive_use_shutil, i) for i in range(total)]
for future in fs:
future.result()
执行结果如下,是没有问题的

但当我们把total改为10的时候再执行程序
if __name__ == '__main__':
shutil.rmtree('test_archives',ignore_errors=True)
total = 10
with ThreadPoolExecutor(max_workers=10) as executor:
fs = [executor.submit(make_archive_use_shutil, i) for i in range(total)]
for future in fs:
future.result()
问题出现了,报错:[Errno 2] No such file or directory: ‘test_archives/0’
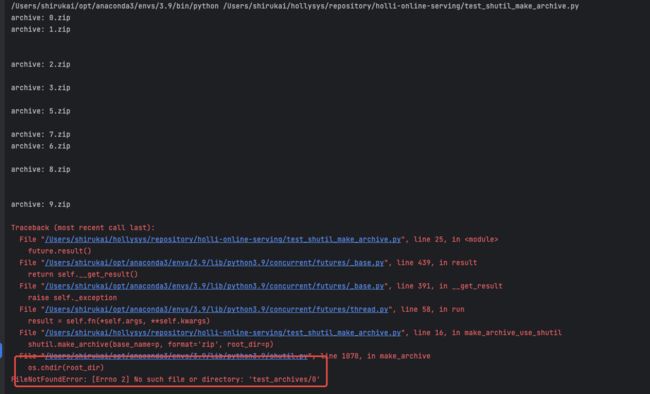
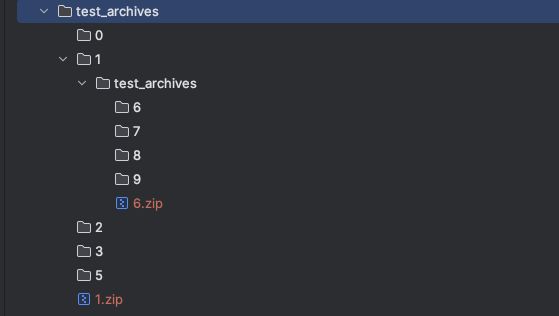
再看看压缩的文件夹,发现都乱套了。
2 问题的原因
上面通过代码复现了多线程使用shutil.make_archive打包会导致的问题,接下来我们将从源码来分析一下导致问题的原因。
以下为Python3.9版本的make_archive方法实现
def make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0,
dry_run=0, owner=None, group=None, logger=None):
"""Create an archive file (eg. zip or tar).
'base_name' is the name of the file to create, minus any format-specific
extension; 'format' is the archive format: one of "zip", "tar", "gztar",
"bztar", or "xztar". Or any other registered format.
'root_dir' is a directory that will be the root directory of the
archive; ie. we typically chdir into 'root_dir' before creating the
archive. 'base_dir' is the directory where we start archiving from;
ie. 'base_dir' will be the common prefix of all files and
directories in the archive. 'root_dir' and 'base_dir' both default
to the current directory. Returns the name of the archive file.
'owner' and 'group' are used when creating a tar archive. By default,
uses the current owner and group.
"""
sys.audit("shutil.make_archive", base_name, format, root_dir, base_dir)
// 获取当前路径,并保存为临时变量
save_cwd = os.getcwd()
if root_dir is not None:
if logger is not None:
logger.debug("changing into '%s'", root_dir)
base_name = os.path.abspath(base_name)
if not dry_run:
// 切换路径
os.chdir(root_dir)
if base_dir is None:
base_dir = os.curdir
kwargs = {'dry_run': dry_run, 'logger': logger}
try:
format_info = _ARCHIVE_FORMATS[format]
except KeyError:
raise ValueError("unknown archive format '%s'" % format) from None
func = format_info[0]
for arg, val in format_info[1]:
kwargs[arg] = val
if format != 'zip':
kwargs['owner'] = owner
kwargs['group'] = group
try:
filename = func(base_name, base_dir, **kwargs)
finally:
if root_dir is not None:
if logger is not None:
logger.debug("changing back to '%s'", save_cwd)
// 切换回原来保存的路径
os.chdir(save_cwd)
return filename
代码的大体思路是:
- 打包之前获取当前目录并保存变量save_cwd
- 切换目录到root_dir
- 执行打包逻辑
- 打包完成该切换回打包之前的save_cwd目录
单看逻辑是没有问题的,关键点在于,目录切换是进程级别的,也就是说,当一个进程中的一个线程切换目录之后,对另一个线程是可见的,另一个线程获取的当前目录也会随之改变,这就是问题的本质所在。
另外通过上面的报错,可以看出来最后打包的路径出现了嵌套的现象,是因为在打包过程中使用了相对路径,当多个线程进行目录切换的时候,相对路径也发生了变化。
3 解决方案
经过上面的分析,解决这个问题,就要避免线程之间不安全的目录切换,并且最好使用绝对路径代替原来的相对路径。
首先使用如下方法代替打包方法:
def make_archive_threadsafe(zip_name: str, path: str):
with zipfile.ZipFile(zip_name, 'w', zipfile.ZIP_DEFLATED) as zf:
for root, dirs, files in os.walk(path):
for file in files:
zf.write(os.path.join(root, file), os.path.relpath(os.path.join(root, file), path))
将程序改造为使用绝对路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
def make_archive_use_custom(f_number):
p = f'{BASE_DIR}/test_archives/{f_number}'
os.makedirs(p)
print(f'archive: {f_number}.zip\n')
make_archive_threadsafe(f'{p}.zip', p)
if __name__ == '__main__':
shutil.rmtree(f'{BASE_DIR}/test_archives',ignore_errors=True)
total = 100
with ThreadPoolExecutor(max_workers=20) as executor:
fs = [executor.submit(make_archive_use_custom, i) for i in range(total)]
for future in fs:
future.result()
执行main方法测试之后打包是没有问题的。