文章目录
-
- 前言
- 弱内存顺序模型
- 屏障指令的封装
-
-
- rmb/wmb/mb
- armv7
- ARMv8
- RV32&RV64
- mb/rmb/wmb 的应用
-
-
- 执行流分析
- 情景1 单用户流
- 情景2 用户流与异常流
前言
UP : (Uni-Processor)
编译器乱序 对应的 编译器 内存屏障 问题 已经在 https:
中提及, 并 做了实验
接着 我们 讨论一下 单核需要处理的CPU乱序问题
这个和架构相关
我们主要考察 arm32/arm64/rv32/rv64
他们都是弱内存顺序模型 , 我们先就 弱内存顺序模型考察一番
弱内存顺序模型
对 load & store 的执行顺序没有要求, 只要不将依赖相关的指令乱序,则可以任意乱序
例如 如下,只要没有依赖,都可以乱序(但不一定100%乱序)
load-load
store-store
load-store
store-load
屏障指令的封装
rmb/wmb/mb
读内存屏障
本线程所有后续的读操作均在本条指令以后执行
写内存屏障
本线程所有之前的写操作均在本条指令以前执行
读写内存屏障
本线程所有之前的读写操作均在本条指令以前执行
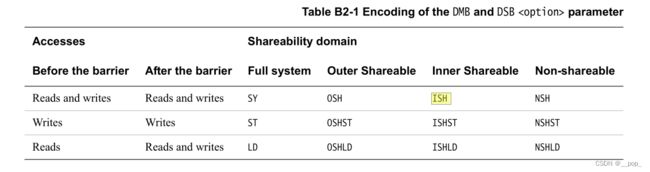
armv7

注意 : ARMv7 没有 LD 选项 . ARMv8 有
以Inner Shareable(ISH)为例
使用"SY"
可防止 所有的 的reorder (read&write memory barrier)
load-load
store-store
load-store
store-load
使用"ST"
防止以下的乱序 (write memory barrier)
store-store
#define dsb(opt) __asm__ __volatile__ ("dsb " #opt : : : "memory")
#define mb() dsb()
#define rmb() dsb()
#define wmb() dsb(st)
ARMv8
write-read 即 store-load 没必要 屏障吗?
没有必要
如果有依赖,自然不会乱序
如果没有依赖,store什么时候发生以及完成都无所谓
#define dsb(opt) __asm__ __volatile__ ("dsb " #opt : : : "memory")
#define mb() dsb(sy)
#define rmb() dsb(ld)
#define wmb() dsb(st)
RV32&RV64

#define RISCV_FENCE(p, s) \
__asm__ __volatile__ ("fence " #p "," #s : : : "memory")
#define mb() RISCV_FENCE(iorw,iorw)
#define rmb() RISCV_FENCE(ir,ir)
#define wmb() RISCV_FENCE(ow,ow)
mb/rmb/wmb 的应用
执行流分析
如果只有一个执行流,应该没啥问题, 因为 有依赖关系的指令 不会乱序
如果我改了下一条指令呢?是不是要 刷新一下流水线
目前 我的代码里面有两个 执行流
一个是正常的用户执行流
一个是异常执行流
那么就考虑 mb/rmb/wmb 在 两个执行流中会导致的问题
情景1 单用户流
不加屏障的情况
command1
command2
command3
加了屏障的情况
command1
command2
command3
结果 :
不加屏障 : command3 已经被加载到 pipeline , 还是执行 原来的 command3
加屏障 : command3 已经被加载到 pipeline , 然后flush pipeline , 执行 svc/ecall
实验代码:
https:
情景2 用户流与异常流
User:
while (flag == 0);
printf("%d\n",data);
Execption:
data = 0x200;
flag = 1;
会有两个问题:
Q1 :User flow 里面 U2 先于 U1 执行 ?
Q2 :Execption flow 里面 E2 先于 E1 执行, E1 还未执行,此时 Execption 切出,然后 U1 U2 执行,打印 了 0
Q1 可以测试
Q2 不可测试(因为Execption 不会在那时切出)
UserA:
while (flag == 0);
printf("%d\n",data);
UserB:
data = 0x200;
flag = 1;
UserB flow 里面 UB2 先于 UB1 执行, UB1 还未执行,此时 UserB 切出,然后 UA1 UA2 执行,打印 了 0
Q1 实际情况
U1 反汇编 为 U1.1 U1.2 U1.3
U2 反汇编 为 U2.1 U2.2 U2.3 U2.4
40005e44: b9402be0 ldr w0, [sp, #40]
40005e48: 7100001f cmp w0, #0x0
40005e4c: 54ffffc0 b.eq 40005e44 <new_fun+0x74>
40005e50: b94027e1 ldr w1, [sp, #36]
40005e54: f0000000 adrp x0, 40008000 <__func__.0+0x2a8>
40005e58: 91272000 add x0, x0, #0x9c8
40005e5c: 97fff414 bl 40002eac <printf>