Item2Vec算法及代码实战
1.背景
在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。 在推荐系统中,用户Embedding向量更多通过行为历史中的物品Embedding平均或者聚类得到。对于物品Embedding的计算,2016年微软提出了Item2vec的方法。
2.Item2vec的基本原理
相比于Word2vec利用“词序列”生成词Embedding。Item2vec利用的“物品序列”是由特定用户的浏览、购买等行为产生的历史行为记录序列。
如果Item存在于一个序列中,Item2vec的方法与word2vec没有任何区别。而如果摒弃序列中Item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是Item set中两两之间的条件概率。
1 K ∑ i = 1 K ∑ j ≠ i K l o g p ( w j ∣ w i ) \frac{1}{K}\sum\limits^K_{i=1}\sum\limits^K_{j\neq i}logp(w_j|w_i) K1i=1∑Kj=i∑Klogp(wj∣wi)
Item2vec摒弃了时间窗口的概念,认为序列中任意两个物品都相关,因此在Item2vec的目标函数中可以看到两两物品对数概率的和,而不是时间窗口内物品的对数概率之和。
3.“广义”上的Item2vec
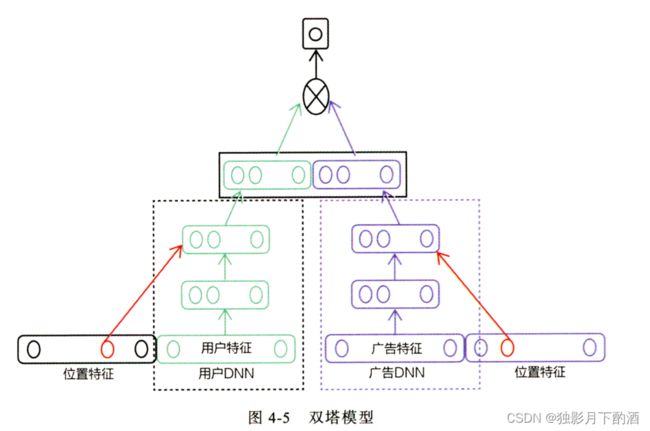
在广告场景下的双塔模型中,广告侧的模型结构实现的就是对物品进行Embedding的过程。该模型成为“双塔模型”。
- 广告侧:“item塔”,接受物品相关的特征向量。
经过“item塔”内的多层神经网络,最终生成一个多维稠密向量。Embedding模型从Word2vec变成了复杂灵活的“item塔”模型,输入特征有用户行为序列生成的one-hot特征向量变成了可包含更多信息的物品特征向量。
4.Item2vec实践
类似于Word2vec,item2vec有两种方式:CBOW和skip-gram模型。
CBOW使用的是词袋模型,模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这个词的词向量。Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
主流程:
- 从log中抽取用户行为序列
- 将行为序列当成预料训练word2Vec得到item embedding
- 得到item sim关系用于推荐
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。 算法需要注意的参数有:
- sentences: 要分析的语料,可以是一个列表,或者从文件中遍历读出。
- vector_size: 词向量的维度,默认值是100。这个维度的取值一般与语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
- window:即词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
- sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
- hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,如果是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
- negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在算法原理篇中标记为neg。
- cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的 x w x_w xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。默认值也是1,不推荐修改默认值。
- min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
- epochs: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
- alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
- min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
代码如下
import pandas as pd
from gensim.models import Word2Vec
import multiprocessing
import os
class CBOW:
def __init__(self, input_file):
self.model = self.get_train_data(input_file)
def get_train_data(self, input_file, L=100):
if not os.path.exists(input_file):
return
score_thr = 4.0
ratingsDF = pd.read_csv(input_file, index_col=None, sep='::', header=None,
names=['user_id', 'movie_id', 'rating', 'timestamp'])
ratingsDF = ratingsDF[ratingsDF['rating'] > score_thr]
ratingsDF['movie_id'] = ratingsDF['movie_id'].apply(str)
movie_list = ratingsDF.groupby('user_id')['movie_id'].apply(list).values
print('training...')
model = Word2Vec(movie_list, vector_size=L, window=5, sg=0, hs=0, min_count=1, workers=multiprocessing.cpu_count(), epochs=10)
return model
def recommend(self, movieID, K):
"""
Args:
movieID:the movieID to find similar
K:recom item num
Returns:
a dic,key:itemid ,value:sim score
"""
movieID = str(movieID)
rank = self.model.wv.most_similar(movieID, topn=K)
return rank
if __name__ == '__main__':
moviesPath = './ml-1m/movies.dat'
ratingsPath = './ml-1m/ratings.dat'
usersPath = './ml-1m/users.dat'
rank = CBOW(ratingsPath).recommend(movieID=1, K=30)
print('CBOW result', rank)
5.Item2vec的特点和局限性
特点:万物皆可embedding
局限性:只能利用序列型数据,在处理互联网背景下大量的网络化数据时不够用
本文仅仅作为个人学习记录所用,不作为商业用途,谢谢理解。
参考:
1.https://www.cnblogs.com/hellojamest/p/11766401.html
2.https://www.zhihu.com/tardis/zm/art/53194407?source_id=1003