Linux性能测试工具之CPU(一)
CPUs
1.1 uptime

Load averages 的三个值分别代表最近 1/5/15 分钟的平均系统负载。在多核系统中,这些值有可能经常大于1,比如四核系统的 100% 负载为 4,八核系统的 100% 负载为 8。
Loadavg 有它固有的一些缺陷:
- uninterruptible的进程,无法区分它是在等待 CPU 还是 IO。无法精确评估单个资源的竞争程度;
- 最短的时间粒度是 1 分钟,以 5 秒间隔采样。很难精细化管理资源竞争毛刺和短期过度使用;
- 结果以进程数量呈现,还要结合 cpu 数量运算,很难直观判断当前系统资源是否紧张,是否影响任务吞吐量
PSI - Pressure Stall Information
每类资源的压力信息都通过 proc 文件系统的独立文件来提供,路径为 /proc/pressure/ – cpu, memory, and io.
其中 CPU 压力信息格式如下:
some avg10=2.98 avg60=2.81 avg300=1.41 total=268109926
memory 和 io 格式如下:
some avg10=0.30 avg60=0.12 avg300=0.02 total=4170757
full avg10=0.12 avg60=0.05 avg300=0.01 total=1856503
avg10、avg60、avg300 分别代表 10s、60s、300s 的时间周期内的阻塞时间百分比。total 是总累计时间,以毫秒为单位。
some 这一行,代表至少有一个任务在某个资源上阻塞的时间占比,full 这一行,代表所有的非idle任务同时被阻塞的时间占比,这期间 cpu 被完全浪费,会带来严重的性能问题。我们以 IO 的 some 和 full 来举例说明,假设在 60 秒的时间段内,系统有两个 task,在 60 秒的周期内的运行情况如下图所示:

红色阴影部分表示任务由于等待 IO 资源而进入阻塞状态。Task A 和 Task B 同时阻塞的部分为 full,占比 16.66%;至少有一个任务阻塞(仅 Task B 阻塞的部分也计算入内)的部分为 some,占比 50%。
some 和 full 都是在某一时间段内阻塞时间占比的总和,阻塞时间不一定连续,如下图所示:

IO 和 memory 都有 some 和 full 两个维度,那是因为的确有可能系统中的所有任务都阻塞在 IO 或者 memory 资源,同时 CPU 进入 idle 状态。
但是 CPU 资源不可能出现这个情况:不可能全部的 runnable 的任务都等待 CPU 资源,至少有一个 runnable 任务会被调度器选中占有 CPU 资源,因此 CPU 资源没有 full 维度的 PSI 信息呈现。
通过这些阻塞占比数据,我们可以看到短期以及中长期一段时间内各种资源的压力情况,可以较精确的确定时延抖动原因,并制定对应的负载管理策略。
1.2 vmstat
显示虚拟内存使用情况的工具
用法:
Usage:
vmstat [options] [delay [count]]
Options:
-a, --active active/inactive memory
-f, --forks number of forks since boot
-m, --slabs slabinfo
-n, --one-header do not redisplay header
-s, --stats event counter statistics
-d, --disk disk statistics
-D, --disk-sum summarize disk statistics
-p, --partition <dev> partition specific statistics
-S, --unit <char> define display unit #设置显示数值的单位(k,K,m,M)
-w, --wide wide output
-t, --timestamp show timestamp
-h, --help display this help and exit
-V, --version output version information and exit
For more details see vmstat(8).
[root@localhost /]# vmstat -Sm 1 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 2269 71344 341 56880 0 0 77 48 1 1 4 2 93 1 0
3 0 2269 71343 341 56880 0 0 0 24 29804 37752 4 2 94 0 0
默认是KiB为单位,可以通过参数-SM来指定以MB为单位显示。
| r | The number of runnable processes (running or waiting for run time). | procs |
| b | The number of processes in uninterruptible sleep. | |
| swpd | the amount of virtual memory used. | memory |
| free | the amount of idle memory. | |
| buff | the amount of memory used as buffers. | |
| cache | the amount of memory used as cache. | |
| active | the amount of active memory. (-a option) | |
| inactive | the amount of inactive memory. (-a option) | |
| si | Amount of memory swapped in from disk (/s). | swap |
| so | Amount of memory swapped to disk (/s). | |
| bi | Blocks received from a block device (blocks/s). | io |
| bo | Blocks sent to a block device (blocks/s). | |
| in | The number of interrupts per second, including the clock. | system |
| cs | The number of context switches per second. | |
| us | Time spent running non-kernel code. (user time, including nice time) | cpu (以下都是占cpu time的百分比值) |
| sy | Time spent running kernel code. (system time) | |
| id | Time spent idle. | |
| wa | Time spent waiting for IO. | |
| st | Time stolen from a virtual machine. | |
1.3 mpstat
查看处理器的活动状态,依赖/proc/stat文件
CPU: Processor number. The keyword all indicates that statistics are calculated as averages among all processors.
%usr: Show the percentage of CPU utilization that occurred while executing at the user level (application).
%nice: Show the percentage of CPU utilization that occurred while executing at the user level with nice priority.
%sys: Show the percentage of CPU utilization that occurred while executing at the system level (kernel). Note that this does not include time spent servicing hardware and software interrupts.
%iowait: Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
%irq: Show the percentage of time spent by the CPU or CPUs to service hardware interrupts.
%soft: Show the percentage of time spent by the CPU or CPUs to service software interrupts.
%steal: Show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
%guest: Show the percentage of time spent by the CPU or CPUs to run a virtual processor.
%gnice: Show the percentage of time spent by the CPU or CPUs to run a niced guest.
%idle: Show the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
1.4 pidstat
pidstat用来显示系统的活动的进程信息。
# 比如每隔2秒、总共3次的显示page fault和内存使用情况
root@ubuntu:~# pidstat -r 2 3
Linux 5.4.0-58-generic (ubuntu) 2021年01月05日 _x86_64_ (2 CPU)
11时38分43秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
11时38分45秒 0 21733 799.00 0.00 20864 8360 0.42 pidstat
11时38分45秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
11时38分47秒 1000 1777 0.50 0.00 3918948 178616 8.90 gnome-shell
11时38分47秒 1000 2064 8.50 0.00 2608 1524 0.08 bd-qimpanel.wat
11时38分47秒 1000 2135 185.00 0.00 412584 32120 1.60 sogouImeService
11时38分47秒 0 21733 52.50 0.00 20864 8888 0.44 pidstat
11时38分47秒 1000 21741 42.50 0.00 11152 516 0.03 sleep
11时38分47秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
11时38分49秒 0 355 0.50 0.00 62488 20988 1.05 systemd-journal
11时38分49秒 1000 2064 8.50 0.00 2608 1524 0.08 bd-qimpanel.wat
11时38分49秒 1000 2135 188.50 0.00 412584 32120 1.60 sogouImeService
11时38分49秒 0 21733 1.50 0.00 20864 8888 0.44 pidstat
11时38分49秒 1000 21749 42.50 0.00 11152 580 0.03 sleep
Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command
Average: 0 355 0.17 0.00 62488 20988 1.05 systemd-journal
Average: 1000 1777 0.17 0.00 3918948 178616 8.90 gnome-shell
Average: 1000 2064 5.66 0.00 2608 1524 0.08 bd-qimpanel.wat
Average: 1000 2135 124.29 0.00 412584 32120 1.60 sogouImeService
Average: 0 21733 285.19 0.00 20864 8712 0.43 pidstat
Average: 1000 21749 14.14 0.00 11152 580 0.03 sleep
1.5 turbostat
turbostat - Report processor frequency and idle statistics.
reports processor topology, frequency, idle power-state statistics, temperature and power on X86 processors. There are two ways to invoke turbostat. The first method is to supply a command, which is forked and statistics are printed in one-shot upon its completion. The second method is to omit the command, and turbostat displays statistics every 5 seconds interval. The 5-second interval can be changed using the --interval option.
- Core
處理器核心編號. - CPU
CPU邏輯處理器號碼,0,1 代表 CPU 的邏輯處理器號碼, – 代表所有處理器的總合. . - Package
processor package number?? - Avg_MHz
CPU 平均工作頻率. - Busy%
CPU 在 C0 (Operating State) 狀態的平均時間百分比,關於 CPU C State 請參考 http://benjr.tw/99146 . - Bzy_MHz
CPU 在 C0 (Operating State) 狀態的平均工作頻率 P stat. - TSC_MHz
處理器最高的運行速度(不包含 Turbo Mode). - IRQ
在測量間隔期間由該 CPU 提供服務的中斷 Interrupt Request (IRQ) 數量. - SMI
在測量間隔期間由 CPU 提供服務的系統管理中斷 system management interrupt (SMI) 數量. - C1 , C3 , C6 , C7
在測量間隔期間請求 C1 (Halt), C3 (Sleep) , C6 (Deep Power Down) , C7 (C6 + LLC may be flushed ) 等狀態的次數,. - C1% , C3% , C6%, C7%
在測量間隔期間請求 C1 (Halt), C3 (Sleep) , C6 (Deep Power Down) , C7 (C6 + LLC may be flushed ) 等狀態的百分比. - CPU%c1, CPU%c3, CPU%c6, CPU%c7
在測量間隔期間請求 C1 (Halt), C3 (Sleep) , C6 (Deep Power Down) , C7 (C6 + LLC may be flushed ) 等狀態的百分比. - CoreTmp
CPU 核心 Core 溫度感測器回傳的溫度值. - PkgTtmp
CPU Package 溫度感測器回傳的溫度值. - GFX%rc6
在測量間隔期間 GPU 處於 render C6 (rc6) 狀態的時間百分比. - GFXMHz
測量間隔 GPU 工作頻率. - Pkg%pc2, Pkg%pc3, Pkg%pc6, Pkg%pc7?
- PkgWatt
CPU package 消耗的瓦特數. - CorWatt
CPU Core 消耗的瓦特數. - GFXWatt
GPU 消耗的瓦特數. - RAMWatt
DRAM DIMM 消耗的瓦特數. - PKG_%
CPU Package 處於 Running Average Power Limit (RAPL) 活動狀態的時間百分比. - RAM_%
DRAM 處於 Running Average Power Limit (RAPL) 活動狀態的時間百分比.

1.6 perf
perf分析CPU的常用命令:
采样:
perf record -F 99 [command] # 运行执行命令command并以99Hz的频率对on-CPU函数进行采样
perf record -F 99 -a -g -- sleep 10 # 全局的CPU栈函数跟踪,采样保持10秒
perf record -F 99 -p PID --call-graph dwarf -- sleep 10 # 对指定pid进程进行函数栈追踪,以dwarf模式记录10秒,采样频率99Hz
perf record -e sched:sched_process_exec -a # 使用exec产生的新进程事件记录
perf record -e sched:sched_switch -a -g -- sleep 10 # 记录上下文切换事件10秒,全局范围内all cpu, -g模式使用 fp mode
选项--call-graph表示调用图/调用链的集合,即样本的函数堆栈。
默认的fp使用框架指针。这非常有效,但可能不可靠,尤其是对于优化的代码。通过显式使用-fno-omit-frame-pointer,可以确保该代码可用于您的代码。但是,库的结果可能会有所不同。
使用dwarf,perf实际上收集并存储堆栈内存本身的一部分,并通过后处理对其进行展开。这可能非常消耗资源,并且堆栈深度可能有限。默认堆栈内存块为8 kiB,但可以配置。
lbr代表最后一个分支记录。这是Intel CPU支持的硬件机制。这可能会以可移植性为代价提供最佳性能。 lbr也仅限于用户空间功能。
perf record -e migrations -a -- sleep 10 # 采样cpu迁移事件10秒
perf record -e migrations -a -c 1 -- sleep 10 # 每隔1秒进行cpu迁移事件采样,共10秒
读取:
perf report -n --stdio # 读取perf.data并显示百分比等
perf script --header # 显示perf.data的所有事件的数据头
#### 显示5秒之内全局范围内的PMC统计数据
# perf stat -a -- sleep 5
Performance counter stats for 'system wide':
10,003.37 msec cpu-clock # 2.000 CPUs utilized
1,368 context-switches # 0.137 K/sec
71 cpu-migrations # 0.007 K/sec
1,630 page-faults # 0.163 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
5.001731126 seconds time elapsed
### 报告执行指定command时,CPU的最后一级缓存统计数据
# perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches ls > /dev/null
Performance counter stats for 'ls':
14,161 LLC-loads (39.48%)
4,918 LLC-load-misses # 34.73% of all LL-cache hits
1,283 LLC-stores (60.52%)
<not supported> LLC-prefetches
0.001654001 seconds time elapsed
0.000000000 seconds user
0.001696000 seconds sys
perf stat -e sched:sched_switch -a -I 1000 # 每1秒显示上下文切换的数量
perf stat -e sched:sched_switch --filter 'prev_state == 0' -a -I 1000 # 显示被迫上下文切换的数量/s
perf stat -e cpu_clk_unhalted.ring0_trans,cs -a -I 1000 # 每秒的用户态切换到内核态、上下文切换
root@ubuntu:test# perf stat -e cpu_clk_unhalted.ring0_trans,cs -a -I 1000
# time counts unit events
1.000184371 98,833,364 cpu_clk_unhalted.ring0_trans
1.000184371 347 cs
2.001406221 70,411,999 cpu_clk_unhalted.ring0_trans
2.001406221 347 cs
3.002688296 135,797,048 cpu_clk_unhalted.ring0_trans
3.002688296 658 cs
[...]
perf sched record -- sleep 10 # 采样10秒有关调度器的数据样本分析文件
perf sched latency # 分析上面记录文件中的每个处理器的调度延时
perf sched timehist # 分析上面记录文件中的每个事件调度延时

CPU火焰图
root@ubuntu:test# perf record -F 99 -a --call-graph dwarf ./t1
^C[ perf record: Woken up 12 times to write data ]
[ perf record: Captured and wrote 7.490 MB perf.data (735 samples) ]
root@ubuntu:test# perf script --header -i perf.data > out.stacks
root@ubuntu:test# stackcollapse-perf.pl < out.stacks | flamegraph.pl --color=java --hash --title="CPU Flame Graph, $(hostname), $(date -I)" > out.svg
其中,stackcoolapse-perf.pl等工具源码路劲:https://github.com/brendangregg/FlameGraph
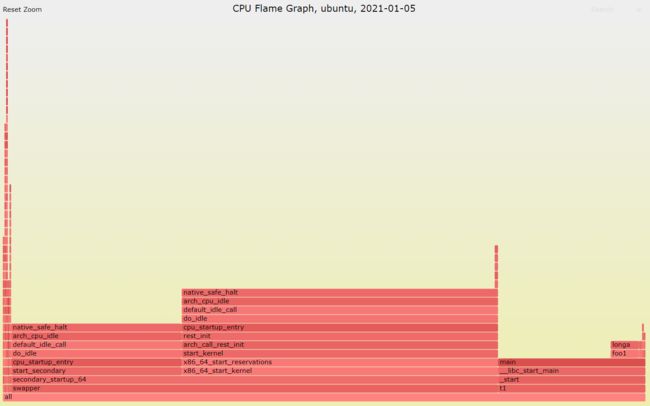
上图中条的宽度表示占用CPU时间的多少,main()函数中调用foo1(),foo2()后是个while(1)死循环。
1.7 profile-bpfcc
profile(8) is a BCC tool that samples stack traces at timed intervals and reports a frequency count.
profile(8) has lower overhead than perf(1) as only the stack trace summary is passed to user space.
profile-bpfcc的开销比perf要小很多。
root@ubuntu:test# profile-bpfcc -h
usage: profile-bpfcc [-h] [-p PID | -L TID] [-U | -K] [-F FREQUENCY | -c COUNT] [-d] [-a] [-I] [-f] [--stack-storage-size STACK_STORAGE_SIZE] [-C CPU] [duration]
Profile CPU stack traces at a timed interval
positional arguments:
duration duration of trace, in seconds
optional arguments:
-h, --help show this help message and exit
-p PID, --pid PID profile process with this PID only
-L TID, --tid TID profile thread with this TID only
-U, --user-stacks-only
show stacks from user space only (no kernel space stacks)
-K, --kernel-stacks-only
show stacks from kernel space only (no user space stacks)
-F FREQUENCY, --frequency FREQUENCY
sample frequency, Hertz
-c COUNT, --count COUNT
sample period, number of events
-d, --delimited insert delimiter between kernel/user stacks
-a, --annotations add _[k] annotations to kernel frames
-I, --include-idle include CPU idle stacks
-f, --folded output folded format, one line per stack (for flame graphs)
--stack-storage-size STACK_STORAGE_SIZE
the number of unique stack traces that can be stored and displayed (default 16384)
-C CPU, --cpu CPU cpu number to run profile on
examples:
./profile # profile stack traces at 49 Hertz until Ctrl-C
./profile -F 99 # profile stack traces at 99 Hertz
./profile -c 1000000 # profile stack traces every 1 in a million events
./profile 5 # profile at 49 Hertz for 5 seconds only
./profile -f 5 # output in folded format for flame graphs
./profile -p 185 # only profile process with PID 185
./profile -L 185 # only profile thread with TID 185
./profile -U # only show user space stacks (no kernel)
./profile -K # only show kernel space stacks (no user)
用profile-bpfcc工具产生火焰图:
root@ubuntu:test# profile-bpfcc -af 10 > profile.stacks
root@ubuntu:test# flamegraph.pl --color=java --hash --title="CPU Flame Graph, profile-bpfcc, $(date -I)" < profile.stacks > profile.svg

profile-bpfcc显示CPU函数堆栈调用关系:
# 另开一个窗口,跑示例程序 ./t1
root@ubuntu:test# profile-bpfcc
Sampling at 49 Hertz of all threads by user + kernel stack... Hit Ctrl-C to end.
^C
b'exit_to_usermode_loop'
b'exit_to_usermode_loop'
b'prepare_exit_to_usermode'
b'swapgs_restore_regs_and_return_to_usermode'
main
__libc_start_main
- t1 (73307)
1
b'__lock_text_start'
b'__lock_text_start'
b'__wake_up_common_lock'
b'__wake_up_sync_key'
b'sock_def_readable'
b'unix_stream_sendmsg'
b'sock_sendmsg'
b'sock_write_iter'
b'do_iter_readv_writev'
b'do_iter_write'
b'vfs_writev'
b'do_writev'
b'__x64_sys_writev'
b'do_syscall_64'
b'entry_SYSCALL_64_after_hwframe'
writev
- Xorg (1615)
1
b'clear_page_orig'
b'clear_page_orig'
b'get_page_from_freelist'
b'__alloc_pages_nodemask'
b'alloc_pages_current'
b'__get_free_pages'
b'pgd_alloc'
b'mm_init'
b'mm_alloc'
b'__do_execve_file.isra.0'
b'__x64_sys_execve'
b'do_syscall_64'
b'entry_SYSCALL_64_after_hwframe'
[unknown]
[unknown]
[unknown]
- bd-qimpanel.wat (73422)
1
b'vmw_cmdbuf_header_submit'
b'vmw_cmdbuf_header_submit'
b'vmw_cmdbuf_ctx_submit.isra.0'
b'vmw_cmdbuf_ctx_process'
b'vmw_cmdbuf_man_process'
b'__vmw_cmdbuf_cur_flush'
b'vmw_cmdbuf_commit'
b'vmw_fifo_commit_flush'
b'vmw_fifo_send_fence'
b'vmw_execbuf_fence_commands'
b'vmw_execbuf_process'
b'vmw_execbuf_ioctl'
b'drm_ioctl_kernel'
b'drm_ioctl'
b'vmw_generic_ioctl'
b'vmw_unlocked_ioctl'
b'do_vfs_ioctl'
b'ksys_ioctl'
b'__x64_sys_ioctl'
b'do_syscall_64'
b'entry_SYSCALL_64_after_hwframe'
ioctl
- Xorg (1615)
1
main
__libc_start_main
- t1 (73307)
71
1.8 cpudist-bpfcc
cpudist(8)12 is a BCC tool for showing the distribution of on-CPU time for each thread wakeup. This can be used to help characterize CPU workloads, providing details for later tuning and design decisions.
比如:
用cpudist观察进程76200的1秒时间
该图中的表示,./t1进程占用CPU的时间是1次512-1023微秒、1次1024-2047微妙等,大部分是栈8192至524287微秒。

1.9 runqlat-bpfcc
runqlat(8)工具用于测试CPU的run queue latency(虽然现在不使用run queue)。
用法:
root@ubuntu:test# runqlat-bpfcc -h
usage: runqlat-bpfcc [-h] [-T] [-m] [-P] [--pidnss] [-L] [-p PID] [interval] [count]
Summarize run queue (scheduler) latency as a histogram
positional arguments:
interval output interval, in seconds
count number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-m, --milliseconds millisecond histogram
-P, --pids print a histogram per process ID
--pidnss print a histogram per PID namespace
-L, --tids print a histogram per thread ID
-p PID, --pid PID trace this PID only
examples:
./runqlat # summarize run queue latency as a histogram
./runqlat 1 10 # print 1 second summaries, 10 times
./runqlat -mT 1 # 1s summaries, milliseconds, and timestamps
./runqlat -P # show each PID separately
./runqlat -p 185 # trace PID 185 only
root@ubuntu:test# runqlat-bpfcc 1 1
Tracing run queue latency... Hit Ctrl-C to end.
usecs : count distribution
0 -> 1 : 3 |* |
2 -> 3 : 9 |***** |
4 -> 7 : 20 |*********** |
8 -> 15 : 62 |********************************** |
16 -> 31 : 20 |*********** |
32 -> 63 : 72 |****************************************|
64 -> 127 : 8 |**** |
128 -> 255 : 2 |* |
256 -> 511 : 11 |****** |
512 -> 1023 : 4 |** |
runqlat(8) works by instrumenting scheduler wakeup and context switch events to determine the time from wakeup to running. These events can be very frequent on busy production systems, exceeding one million events per second. Even though BPF is optimized, at these rates even adding one microsecond per event can cause noticeable overhead. Use with caution, and consider using runqlen(8) instead.
1.10 runqlen-bpfcc
用于测试CPU的run queue队列长度数据,多个CPU汇总的histogram(直方图)。
root@ubuntu:test# runqlen-bpfcc -h
usage: runqlen-bpfcc [-h] [-T] [-O] [-C] [interval] [count]
Summarize scheduler run queue length as a histogram
positional arguments:
interval output interval, in seconds
count number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-O, --runqocc report run queue occupancy
-C, --cpus print output for each CPU separately
examples:
./runqlen # summarize run queue length as a histogram
./runqlen 1 10 # print 1 second summaries, 10 times
./runqlen -T 1 # 1s summaries and timestamps
./runqlen -O # report run queue occupancy
./runqlen -C # show each CPU separately
示例:
### 用了两个终端,每个终端里个运行了一个./t1死循环进程,系统是2个CPU总共
root@ubuntu:test# runqlen-bpfcc 1 1
Sampling run queue length... Hit Ctrl-C to end.
runqlen : count distribution
0 : 194 |****************************************|
### 上表的意思是run queue长度一直为0
root@ubuntu:test# runqlen-bpfcc 1 1
Sampling run queue length... Hit Ctrl-C to end.
runqlen : count distribution
0 : 191 |****************************************|
1 : 0 | |
2 : 2 | |
### 意思是:绝大部分时间run queue为0,大约1%的时间run queue队列长度为2
1.11 softirq-bpfcc
softirqs(8)15 is a BCC tool that shows the time spent servicing soft IRQs (soft interrupts). The system-wide time in soft interrupts is readily available from different tools. For example, mpstat(1) shows it as %soft. There is also /proc/softirqs to show counts of soft IRQ events. The BCC softirqs(8) tool differs in that it can show time per soft IRQ rather than an event count.
root@ubuntu:pc# softirqs-bpfcc -h
usage: softirqs-bpfcc [-h] [-T] [-N] [-d] [interval] [count]
Summarize soft irq event time as histograms.
positional arguments:
interval output interval, in seconds
count number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-N, --nanoseconds output in nanoseconds
-d, --dist show distributions as histograms
examples:
./softirqs # sum soft irq event time
./softirqs -d # show soft irq event time as histograms
./softirqs 1 10 # print 1 second summaries, 10 times
./softirqs -NT 1 # 1s summaries, nanoseconds, and timestamps
root@ubuntu:pc# softirqs-bpfcc 10 1
Tracing soft irq event time... Hit Ctrl-C to end.
SOFTIRQ TOTAL_usecs
net_tx 1
tasklet 126
block 560
rcu 4056
net_rx 4325
sched 7397
timer 8293 ### 花在timer定时器的软中断时间是8.293ms
#####################################################################
root@ubuntu:pc# softirqs-bpfcc -d
Tracing soft irq event time... Hit Ctrl-C to end.
^C
softirq = timer
usecs : count distribution
0 -> 1 : 28 |**************************** |
2 -> 3 : 39 |****************************************|
4 -> 7 : 18 |****************** |
8 -> 15 : 13 |************* |
16 -> 31 : 5 |***** |
32 -> 63 : 2 |** |
64 -> 127 : 2 |** |
softirq = rcu
usecs : count distribution
0 -> 1 : 47 |****************************************|
2 -> 3 : 14 |*********** |
4 -> 7 : 10 |******** |
8 -> 15 : 6 |***** |
16 -> 31 : 5 |**** |
32 -> 63 : 0 | |
64 -> 127 : 1 | |
softirq = tasklet
usecs : count distribution
0 -> 1 : 8 |***************************** |
2 -> 3 : 11 |****************************************|
4 -> 7 : 4 |************** |
softirq = sched
usecs : count distribution
0 -> 1 : 8 |********* |
2 -> 3 : 23 |*************************** |
4 -> 7 : 22 |************************* |
8 -> 15 : 34 |****************************************|
16 -> 31 : 18 |********************* |
softirq = net_rx
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 5 |****************************************|
16 -> 31 : 4 |******************************** |
32 -> 63 : 2 |**************** |
1.12 hardirq-bpfcc
显示花在硬中断上的时间
root@ubuntu:pc# hardirqs-bpfcc -h
usage: hardirqs-bpfcc [-h] [-T] [-N] [-C] [-d] [interval] [outputs]
Summarize hard irq event time as histograms
positional arguments:
interval output interval, in seconds
outputs number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-N, --nanoseconds output in nanoseconds
-C, --count show event counts instead of timing
-d, --dist show distributions as histograms
examples:
./hardirqs # sum hard irq event time
./hardirqs -d # show hard irq event time as histograms
./hardirqs 1 10 # print 1 second summaries, 10 times
./hardirqs -NT 1 # 1s summaries, nanoseconds, and timestamps
root@ubuntu:pc# hardirqs-bpfcc 2 1
Tracing hard irq event time... Hit Ctrl-C to end.
HARDIRQ TOTAL_usecs
vmw_vmci 5
ahci[0000:02:05.0] 12
vmwgfx 259
ens33 414 ### 花费在ens33网卡上的硬中断时间是414us
1.13 bpftrace
bpftrace is a BPF-based tracer that provides a high-level programming language, allowing the creation of powerful one-liners and short scripts. It is well suited for custom application analysis based on clues from other tools. There are bpftrace versions of the earlier tools runqlat(8) and runqlen(8) in the bpftrace repository [Iovisor 20a].
### bpftrace分析 t1 进程,采样频率49Hz,且只显示前3层调用栈
root@ubuntu:test# bpftrace -e 'profile:hz:49 /comm == "t1"/ { @[ustack(3)] = count(); }'
Attaching 1 probe...
^C
@[
longa+20
foo1+31
main+36
]: 1
@[
longa+27
foo2+31
main+46
]: 2
@[
longa+23
foo1+31
main+36
]: 3
@[
longa+34
foo2+31
main+46
]: 3
@[
longa+17
foo1+31
main+36
]: 8
@[
longa+27
foo1+31
main+36
]: 13
@[
longa+34
foo1+31
main+36
]: 27
[root@localhost test]# bpftrace -l 'tracepoint:sched:*'
tracepoint:sched:sched_kthread_stop
tracepoint:sched:sched_kthread_stop_ret
tracepoint:sched:sched_waking
tracepoint:sched:sched_wakeup
tracepoint:sched:sched_wakeup_new
tracepoint:sched:sched_switch
tracepoint:sched:sched_migrate_task
tracepoint:sched:sched_process_free
tracepoint:sched:sched_process_exit
tracepoint:sched:sched_wait_task
tracepoint:sched:sched_process_wait
tracepoint:sched:sched_process_fork
tracepoint:sched:sched_process_exec
tracepoint:sched:sched_stat_wait
tracepoint:sched:sched_stat_sleep
tracepoint:sched:sched_stat_iowait
tracepoint:sched:sched_stat_blocked
tracepoint:sched:sched_stat_runtime
tracepoint:sched:sched_pi_setprio
tracepoint:sched:sched_process_hang
tracepoint:sched:sched_move_numa
tracepoint:sched:sched_stick_numa
tracepoint:sched:sched_swap_numa
tracepoint:sched:sched_wake_idle_without_ipi
[root@localhost test]# bpftrace -lv "kprobe:sched*"
kprobe:sched_itmt_update_handler
kprobe:sched_set_itmt_support
kprobe:sched_clear_itmt_support
kprobe:sched_set_itmt_core_prio
kprobe:schedule_on_each_cpu
kprobe:sched_copy_attr
kprobe:sched_free_group
kprobe:sched_free_group_rcu
kprobe:sched_read_attr
kprobe:sched_show_task
kprobe:sched_change_group
kprobe:sched_rr_get_interval
kprobe:sched_setscheduler
kprobe:sched_setscheduler_nocheck
kprobe:sched_setattr
kprobe:sched_tick_remote
kprobe:sched_can_stop_tick
kprobe:sched_set_stop_task
kprobe:sched_ttwu_pending
kprobe:scheduler_ipi
kprobe:sched_fork
kprobe:schedule_tail
kprobe:sched_exec
kprobe:scheduler_tick
kprobe:sched_setattr_nocheck
kprobe:sched_setaffinity
kprobe:sched_getaffinity
kprobe:sched_setnuma
kprobe:sched_cpu_activate
kprobe:sched_cpu_deactivate
kprobe:sched_cpu_starting
kprobe:sched_cpu_dying
kprobe:sched_create_group
kprobe:sched_online_group
kprobe:sched_destroy_group
kprobe:sched_offline_group
kprobe:sched_move_task
kprobe:sched_show_task.part.60
kprobe:sched_idle_set_state
kprobe:sched_slice.isra.61
kprobe:sched_init_granularity
kprobe:sched_proc_update_handler
kprobe:sched_cfs_slack_timer
kprobe:sched_cfs_period_timer
kprobe:sched_group_set_shares
kprobe:sched_rt_rq_enqueue
kprobe:sched_rt_period_timer
kprobe:sched_rt_bandwidth_account
kprobe:sched_group_set_rt_runtime
kprobe:sched_group_rt_runtime
kprobe:sched_group_set_rt_period
kprobe:sched_group_rt_period
kprobe:sched_rt_can_attach
kprobe:sched_rt_handler
kprobe:sched_rr_handler
kprobe:sched_dl_global_validate
kprobe:sched_dl_do_global
kprobe:sched_dl_overflow
kprobe:sched_get_rd
kprobe:sched_put_rd
kprobe:sched_init_numa
kprobe:sched_domains_numa_masks_set
kprobe:sched_domains_numa_masks_clear
kprobe:sched_domains_numa_masks_clear
kprobe:sched_init_domains
kprobe:sched_numa_warn.part.8
kprobe:sched_autogroup_create_attach
kprobe:sched_autogroup_detach
kprobe:sched_autogroup_exit_task
kprobe:sched_autogroup_fork
kprobe:sched_autogroup_exit
kprobe:schedstat_stop
kprobe:schedstat_start
kprobe:schedstat_next
kprobe:sched_debug_stop
kprobe:sched_feat_open
kprobe:sched_feat_show
kprobe:sched_feat_write
kprobe:sched_debug_header
kprobe:sched_debug_start
kprobe:sched_debug_next
kprobe:sched_debug_show
kprobe:sched_partition_show
kprobe:sched_partition_write
kprobe:sched_autogroup_open
kprobe:sched_open
kprobe:sched_write
kprobe:sched_autogroup_show
kprobe:sched_show
kprobe:sched_autogroup_write
kprobe:schedule_console_callback
kprobe:sched_send_work
kprobe:schedule
kprobe:schedule_idle
kprobe:schedule_user
kprobe:schedule_preempt_disabled
kprobe:schedule_timeout
kprobe:schedule_timeout_interruptible
kprobe:schedule_timeout_killable
kprobe:schedule_timeout_uninterruptible
kprobe:schedule_timeout_idle
kprobe:schedule_hrtimeout_range_clock
kprobe:schedule_hrtimeout_range
kprobe:schedule_hrtimeout