论文翻译:Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
论文翻译
- 摘要
- 1.简介
- 2.监督视觉语言模型
-
- 2.1 Vokens:可视化的标记
- 2.2 Voken分类任务
- 2.3 示列
- 创建Vokens的两个挑战
- Vokenization
-
- 3.1 Vokenization过程
- 3.2 上下文Token-Image匹配模型
-
- 训练
- 推理
摘要
人类学习语言的方式包括听、说、写、读,以及通过与多模态现实世界的互动。现有的语言预训练框架展示了基于文本的自监督学习的有效性,而本文探索了一种以视觉为监督信号的语言模型的思路。我们发现,阻碍这种探索的主要原因是基于视觉的语言数据集与纯语言语料库之间规模和分布上的巨大差异。因此,我们开发了一种称为“vokenization”的技术,通过将语言标记在上下文中映射到相关图像(我们称之为“vokens”)来将多模态对齐扩展到仅语言数据。 “vokenizer”在相对较小的图像字幕数据集上进行训练,然后将其应用于生成大型语言语料库的vokens。使用这些上下文生成的vokens训练的视觉监督语言模型在多个纯语言任务(例如GLUE,SQuAD和SWAG)上显示出了一致的改进。
1.简介
大多数人在学习语言理解时,使用的是多种模态,而不仅仅是文本和音频,尤其是利用视觉模态。正如 Bloom(2002)所声称的那样,视觉指向是大多数儿童学习单词含义的重要步骤。然而,现有的语言预训练框架是由上下文学习驱动的,仅将语言上下文作为自我监督。例如,word2vec(Mikolov等人,2013)使用周围的词袋;ELMo(Peters等人,2018)和GPT(Radford等人,2018)使用后续上下文;BERT(Devlin等人,2019)使用随机屏蔽的标记。虽然这些自我监督框架在理解人类语言方面取得了强大的进展,但它们并没有从外部视觉世界借鉴基础信息(请参见Bender和Koller(2020)以及Bisk等人(2020)的最近相关工作的动机)。
在这篇论文中,我们介绍了一种以视觉指向(Bloom,2002)模拟人类语言学习的视觉监督语言模型。
正如下图所示,该模型以语言标记作为输入,并使用与标记相关的图像作为视觉监督。我们将这些图像称为vokens(即可视化标记),因为它们充当相应标记的可视化。假设存在一个大型对齐的标记-voken数据集,该模型可以通过从这些voken中学习voken预测任务。
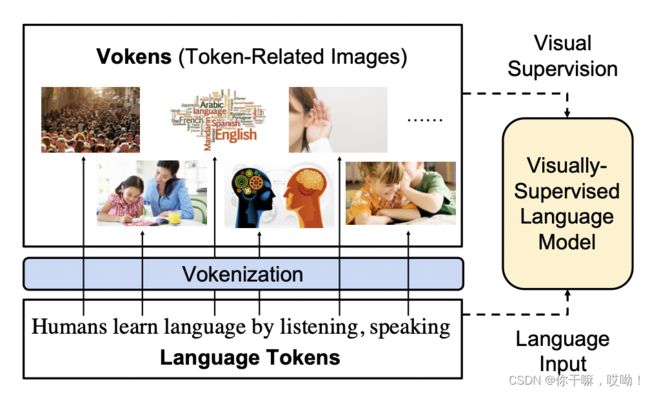
不幸的是,目前还没有这样的对齐标记-voken数据集,因此视觉与语言一一对应的数据集创建,存着主要挑战。
2.监督视觉语言模型
上下文语言表示学习是通过自监督驱动的,没有考虑与外部世界的明确联系(基础)。在本节中,我们介绍了一种受视觉监督的语言模型的思想,并讨论了创建其视觉监督的挑战。
2.1 Vokens:可视化的标记
为了为语言模型提供视觉监督,我们假设存在一个文本语料库,其中每个标记都与相关图像对齐(尽管这些voken注释目前不存在,我们将在第3节中通过voken化过程尝试生成vokens)。因此,这些图像可以被视为标记的可视化,并将它们命名为“vokens”。基于这些vokens,我们提出了一项新的语言预训练任务:voken分类。
2.2 Voken分类任务
大多数语言骨干模型(例如 ELMo(Peters 等人,2018),GPT(Radford 等人,2018),BERT(Devlin 等人,2019))为句子 s = w i s = {w_i} s=wi 中的每个 token 输出一个局部特征表示 h i {h_i} hi。而且无需修改模型架构。
假设 vokens 来自有限集合 X X X,我们使用线性层和 softmax 层将隐藏输出 h i h_i hi转换为概率分布 p i p_i pi,然后voken分类损失是所有对应 vokens 的负对数概率:
h 1 , h 2 , . . . , h l = l m ( w 1 , w 2 , . . . , w l ) h_1,h_2,...,h_l=lm(w_1,w_2,...,w_l) h1,h2,...,hl=lm(w1,w2,...,wl)
p i ( v ∣ s ) = s o f t m a x v { W h i + b } p_i(v|s)=softmax_v \lbrace Wh_i+b\rbrace pi(v∣s)=softmaxv{Whi+b}
L V O K E N − C L S ( s ) = − ∑ i = 1 l l o g p i ( v ( w i ; s ) ∣ s ) \mathcal{L}_{VOKEN-CLS}(s)=-\sum_{i=1}^llog p_i(v(w_i;s)|s) LVOKEN−CLS(s)=−i=1∑llogpi(v(wi;s)∣s)
2.3 示列
该任务可以轻松地集成到当前的语言预训练框架中,下面是语言预训练模型的算法流程:

上图为可视化监督BERT展示了voken分类任务的一个实现示例,为BERT(Devlin等,2019)提供可视化监督。原始BERT预训练任务主要依靠遮盖语言模型:语音主体部分被随机遮盖mask,模型需要从语言上下文中预测这些缺失的部分。
为简单起见,我们分别使用 s s s和 s ^ \hat s s^表示token集和mask token集。未mask的部分 s s s和 s ^ \hat s s^差集记为: s \ s ^ s \backslash \hat s s\s^
假设 q i q_i qi是第 i i i个标记的条件概率分布,则Masked Language Model(MLM)损失为mask token的负对数似然:
L M L M ( s , s ^ ) = − ∑ w i ∈ s ^ l o g q i ( w i ∣ s \ s ^ ) \mathcal{L}_{MLM}(s,\hat s)=-\sum_{w_i \in \hat s}log q_i(w_i|s \backslash \hat s) LMLM(s,s^)=−wi∈s^∑logqi(wi∣s\s^)
在不改变模型和模型输入的情况下,我们计算所有token的voken分类损失(如图2右侧所示):
L V O K E N − C L S ( s , s ^ ) = − ∑ w i ∈ s l o g p i ( v ( w i ; s ) ∣ s \ s ^ ) \mathcal{L}_{VOKEN-CLS}(s,\hat s)=-\sum_{w_i \in s}log p_i(v(w_i;s)|s \backslash \hat s) LVOKEN−CLS(s,s^)=−wi∈s∑logpi(v(wi;s)∣s\s^)
可视化监督的mask语言模型将这两个损失的比率求和,得到最终的损失函数
L V L M ( s , s ^ ) = L V O K E N − C L S ( s , s ^ ) + λ L M L M ( s , s ^ ) \mathcal{L}_{VLM}(s,\hat s)=\mathcal{L}_{VOKEN-CLS}(s,\hat s)+\lambda \mathcal{L}_{MLM}(s,\hat s) LVLM(s,s^)=LVOKEN−CLS(s,s^)+λLMLM(s,s^)
其中λ是一个超参数,控制voken分类任务和遮盖语言模型任务之间的平衡。这种方法可以提高语言模型的性能和泛化能力。
创建Vokens的两个挑战
前面的章节中介绍了利用存在的Vokens来进行外部监督的潜力。然而,我们目前缺乏从token到图像的密集注释。与Vokens最相似的概念是短语定位(例如在Flickr30K实体中(Young等人,2014;Plummer等人,2017))。由于收集短语定位的过程成本高昂,因此覆盖率和注释量不能满足我们的要求。除了短语定位之外,最有前途的数据来源是具有句子到图像映射(或从多模态文档中发现,如Hessel等人(2019))的图像字幕数据集。图像字幕属于一种特定类型的语言,称为基于实体语言(Roy和Pentland,2002;Hermann等人,2017),它具有对外部存在或物理行为的明确基础。但是,基于实体语言与其他类型的自然语言(例如新闻、维基百科和教科书)存在很大的差异。为了说明这一点,我们在表1中列出了三个图像字幕数据集(即MS COCO(Lin等人,2014)、Visual Genome(Krishna等人,2017)和Conceptual Captions(Sharma等人,2018))和其他语言类型的三个语言语料库(即Wiki103(Merity等人,2017)、英文维基百科和CNN/Daily Mail(See等人,2017))的关键统计数据。
Vokenization
在本节中,我们开发了一个可以生成 vokens 的框架。其基本思想是从图像文本数据集中学习一个“vokenizer”,并将其用于注释大型语言语料库(即英文维基百科),从而弥合基础语言和其他类型自然语言之间的差距。我们首先说明vokenization过程,然后描述如何实现它。
3.1 Vokenization过程
如上图所示,vokenization是将句子 s = ( w 1 , w 2 , . . . , w l ) s =(w_1,w_2,...,w_l) s=(w1,w2,...,wl)中的每个标记 w i w_i wi分配一个相关图像 v ( w i ; s ) v(w_i; s) v(wi;s)的过程。我们将这个图像 v ( w i ; s ) v(w_i; s) v(wi;s)称为“voken”(可视化token)。
我们不是使用生成模型创建这个图像,而是从图像集 X = x 1 , x 2 , . . . , x n X = {x_1,x_2,...,x_n} X=x1,x2,...,xn中检索与标记-图像相关性评分函数 r θ ( w i , x ; s ) r_θ(w_i,x; s) rθ(wi,x;s)相关的图像。这个由 θ θ θ参数化的评分函数 r θ ( w i , x ; s ) r_θ(w_i,x; s) rθ(wi,x;s),测量句子s中标记 w i w_i wi和图像 x x x之间的相关性。
我们假设这个函数的最优参数是 θ ∗ θ* θ∗,
与句子s相关的voken v ( w i ; s ) v(w_i; s) v(wi;s)实现为最大化它们的相关得分 r θ r_θ rθ的图像 x ∈ X x \in X x∈X:
v ( w i ; s ) = a r g m a x x ∈ V r θ ∗ ( w i , x ; s ) v(w_i;s)= argmax_{x \in V}r_θ * (w_i,x;s) v(wi;s)=argmaxx∈Vrθ∗(wi,x;s)
由于图像集 X X X实际上为vokens构建了有限的词汇表,因此我们可以利用voken分类任务来视觉监督语言模型的训练。接下来,我们将讨论此vokenization过程的详细实现。
3.2 上下文Token-Image匹配模型
vokenization 过程的核心是一个上下文Token-Image匹配模型。
该模型以一句话 s s s和一张图像 x x x作为输入,而句子 s s s由一系列token { w 1 , w 2 , . . . , w l } , \lbrace w_1,w_2,...,w_l \rbrace, {w1,w2,...,wl}, 组成。
输出 r θ ( w i , x ; s ) r_θ(w_i,x;s) rθ(wi,x;s)是token w i ∈ s w_i \in s wi∈s 和图像 x 之间的相关度分数,同时考虑整个句子 s s s作为上下文。
建模为了建立相关度分数函数 r θ ( w i , x ; s ) r_θ(w_i,x;s) rθ(wi,x;s) 的模型,
我们将其分解为语言特征表示 f θ ( w i ; s ) f_θ(w_i;s) fθ(wi;s) 和视觉特征表示 g θ ( x ) g_θ(x) gθ(x) 的内积:
r θ ( w i , x ; s ) = f θ ( w i ; s ) T g θ ( x ) r_θ(w_i,x;s) = f_θ(w_i;s)^Tg_θ(x) rθ(wi,x;s)=fθ(wi;s)Tgθ(x)
这两个特征表示分别由语言和视觉编码器生成。语言编码器首先使用预训练的 BERTBASE(Devlin et al.,2019)模型将离散token { w i } \lbrace w_i\rbrace {wi} 上下文嵌入到隐藏输出向量 { h i } \lbrace hi \rbrace {hi} 中:
h 1 , h 2 , . . . , h l = b e r t ( w 1 , w 2 , . . . , w l ) h_1,h_2,...,h_l = bert(w_1,w_2,...,w_l) h1,h2,...,hl=bert(w1,w2,...,wl)
然后我们应用一个多层感知器 (MLP) w m l p θ w{mlpθ} wmlpθ对隐藏输出 h i h_i hi 进行降维。为了简化第 3.1 节中的检索过程,最终的语言特征被规范化为范数为 1 的向量,通过将其欧几里得范数除以其自身值:
f θ ( w i ; s ) = w m l p θ ( h i ) ∣ ∣ w m l p θ ( h i ) ∣ ∣ f_θ(w_i;s) = \frac{w_{mlpθ}(h_i)}{||w_{mlpθ}(h_i)||} fθ(wi;s)=∣∣wmlpθ(hi)∣∣wmlpθ(hi)
另一方面,视觉编码器首先从预训练的 ResNeXt(Xie et al.,2017)中提取视觉嵌入embedding。与语言编码器类似,随后应用 MLP 层 x m l p θ x_{mlpθ} xmlpθ 和 L2 规范化层:
e = R e s N e X t ( x ) e=ResNeXt(x) e=ResNeXt(x)
g θ ( x ) = x m l p θ ( e ) ∣ ∣ x m l p θ ( e ) ∣ ∣ g_θ(x)=\frac{x_{mlpθ}(e)}{||x_{mlpθ}(e)||} gθ(x)=∣∣xmlpθ(e)∣∣xmlpθ(e)
训练
由于从标记到图像的密集注释缺乏且难以生成,因此我们选择从图像字幕数据集(例如MS COCO(Lin等,2014))的弱监督中训练标记-图像匹配模型。这些数据集由句子 - 图像对 ( s k , x k ) (s_k,x_k) (sk,xk)组成,其中句子 s k s_k sk描述了图像 x k x_k xk中的视觉内容。
为了建立标记和图像之间的对应关系,我们将句子 s k s_k sk中的所有标记与图像 x k x_k xk配对。然后通过最大化这些对齐的标记 - 图像对与未对齐的对之间的相关性得分来优化模型,不失一般性。
假设 ( s , x ) (s,x) (s,x)是图像文本数据点,我们随机选择另一个图像 x ′ x′ x′,满足条件 x ′ ≠ x x′≠x x′=x。然后我们使用hinge loss来优化权重 θ θ θ,使得正标记 - 图像对 r θ ( w i , x ; s ) r_θ(w_i,x;s) rθ(wi,x;s)的得分至少比负对 r θ ( w i , x ′ ; s ) r_θ(w_i,x′;s) rθ(wi,x′;s)高一个边界M。
L θ ( s , x , x ′ ) = ∑ i = 1 l m a x { 0 , M − r θ ( w i , x ; s ) + r θ ( w i , x ′ ; s ) } \mathcal{L}_θ(s,x,x′)=\sum_{i=1}^l max \lbrace0,M−r_θ(w_i,x;s)+ r_θ(w_i,x′;s)\rbrace Lθ(s,x,x′)=i=1∑lmax{0,M−rθ(wi,x;s)+rθ(wi,x′;s)}
直观地说,当得分差小于边缘M时,最小化此hinge loss m a x { 0 , M − p o s + n e g } max \lbrace 0,M−pos + neg\rbrace max{0,M−pos+neg}将尝试增加正对的得分并降低负对的得分。否则(如果差异≥边界M),两个得分保持不变。
推理
鉴于相关性得分被分解为特征表示 f θ ( w i ; s ) f_θ(w_i;s) fθ(wi;s)和 g θ ( v ) g_θ(v) gθ(v)的内积,因此第3.1节中的检索问题可以被制定为最大内积搜索(Mussmann和Ermon,2016)。此外,由于向量是norm-1的,具有最大内积的向量与欧几里得空间中最接近的向量相同(即最近邻(Knuth,1973))。