java集合框架及其背后的数据类型 - 包装类
介绍
java集合框架 java Collection Framewrok , 又称为容器 container,是定义在 java.util包下的一组接口 interfaces 和其实现的类 classes 。都是工具包。
其主要表现的是将多个元素 element 置于一个单元中,用于对这些元素的快速,便携的储存 store,检索 retrieve , 管理 manipulate , 即我们平时使俗称的 增删查改 CRUD。
在java中,把很多的数据结构都封装起来了,封装成一个一个现成的类。我们只需要拿过来使用就行了。
如下图所示,是java中的数据结构接口的预览:

我们发现我们之前用C来写的数据结构,都在java当中得到了封装。
那么上图也进行了说明:
要理解上面那张图的话,首先我们要理解这其中的关系:
关系
接口和接口的关系:extends;如上图所示,
List Queue Set 都extends 实现了 Collection 的功能。
类和接口的关系:implements ; 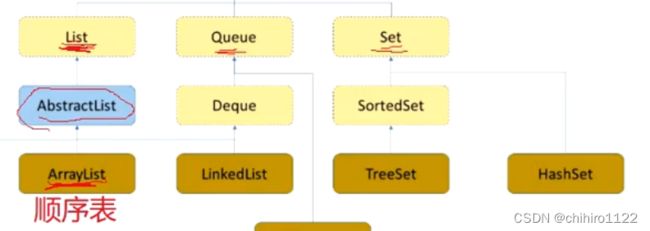
上图 ArrayList 顺序表 实现了 List 接口,那么他同样也间接实现了 Collection 接口。
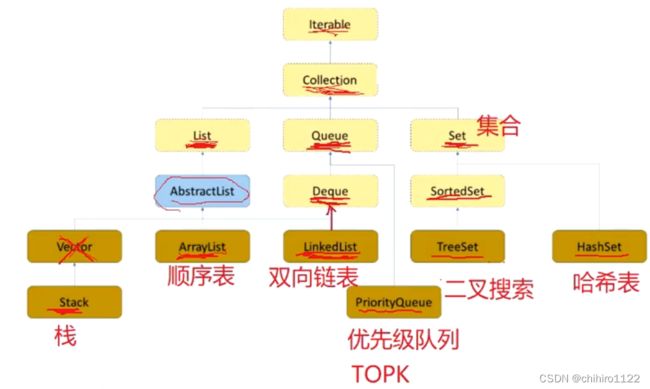
上图中的 Set 集合 中存储的每一个元素不能是重复的。
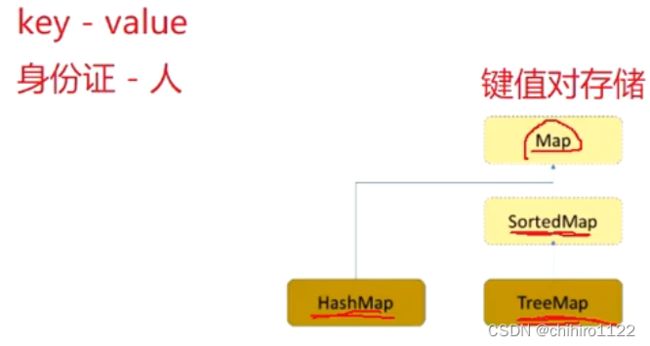
Map 接口中的数据,用的是键值对存储,也就说,一个元素,对应一个键和一个值。
TreeMap 底层是一个二叉搜索树,它实现了 SortedMap 接口,那么说明这个 TreeMap是支持排序的。

- 使用成熟的集合框架,有助于我们便捷快速的写出高效的,稳定的代码。
- 学习数据结构背后实现的知识,有助于我们理解各个集合的优缺点及其使用场景。
接口 interfaces


![]()
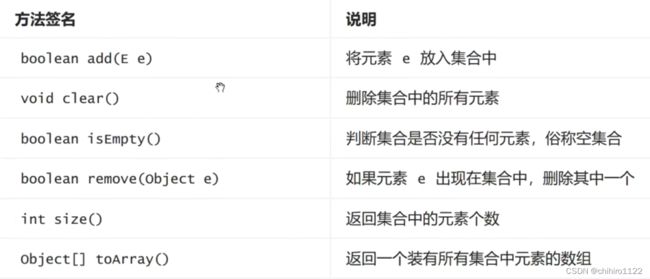
Collection 接口常用方法说明
在Collection中常用的方法有以下几种:
要是用这个接口,就要先导入这个接口的包:
import java.util.Collection;因为Collection是一个接口,所以不能直接new这个Collection的对象,能new一个对象的只能是类,因为Collection被很多的类所实现,所以我们可以new一个实现了Collection接口的类,来使用其中的方法,比如我们使用顺序表这个类来实现Collection接口中方法:
public static void main(String[] args) {
Collection collection = new ArrayList();
}1) add()方法,我们发现add()方法当中的参数是 一个 E 类型,我们查看 Collection 接口的源代码:![]()
这里的 E 是一种泛型,我们先来简单了解一下泛型:

上述代码表示 collection1 引用的是一个 顺序表对象,这个顺序表对象当中只能存储 String类型的数据:

那么此时的String传过去给了 Collection 源代码中的 E 泛型了:

所以此时的 E 类型就代表的是 你传入的类型,官方文档中这样定义:
那么Add()方法就是 往这个集合中插入元素:
Collection collection = new ArrayList();
collection.add("hello");
collection.add("world");
System.out.println(collection);//[hello, world] Collection collection1 = new ArrayList<>();
collection1.add(2);
collection1.add(3);
System.out.println(collection1);//[2, 3] 我们发现 Add()方法返回的是一个 boolear 类型的数据,此方法返回一个表示操作成功的布尔值。如果添加了元素,则返回true,否则返回false。
System.out.println(collection.add("world"));//trueAdd()源代码:

2) clear()方法就是把这个集合当中的元素都删除掉:
Collection collection = new ArrayList();
collection.add("hello");
collection.add("world");
System.out.println(collection);
collection.clear();
System.out.println(collection);//[] clear()方法的源代码:

3) isEmpty()方法判断这个集合里是不是空的,不是空返回 false ,是空 返回true:
Collection collection = new ArrayList();
collection.add("hello");
System.out.println(collection.isEmpty());//false
collection.clear();
System.out.println(collection.isEmpty());//true 4)remove()方法,删除集合中的某个元素;
Collection collection = new ArrayList();
collection.add("hello");
collection.add("world");
collection.remove("hello");
System.out.println(collection);//[world] 5)计算并返回这个集合中的元素个数;
Collection collection1 = new ArrayList<>();
collection1.add(2);
collection1.add(3);
collection1.add(3);
collection1.add(3);
collection1.add(3);
System.out.println(collection1.size());//5 6) toArray()方法,把这个集合变成一个对于类型的数组,然后把这个数组通过返回值返回,返回的是一个 Object 类型的数组,那么我们就要用一个Object类型的数组去接收它:
Collection collection1 = new ArrayList<>();
collection1.add(2);
collection1.add(3);
Object[] array = collection1.toArray();
System.out.println(Arrays.toString(array));//[2, 3] 因为其中的类都实现了 Iterable这个接口,所以我们上述除了可以使用 System.out.println()来直接答应,还可以使用 foreach来打印:
如上述例子;
for(int tmp:collection1)
{
System.out.println(tmp);
}
//2
//3
//3
//3
//3Map接口常用方法

同样,因为Map()是一个接口,所以只能使用实现这个接口的类来创建对象,而且Map是键值对的形式,所以我们要用两个泛型来表示,键和值两个数据的类型:
![]()
0)我们这里可以用put()方法对在 其中插入一些值:
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("好好学习","成功");
map.put("不好好学习","失败");
System.out.println(map);//{好好学习=成功, 不好好学习=失败}
} 这里看见我们是直接使用 map 这个引用类型直接进行打印的,我们知道此时的 map 存入的是HashMap()对象的地址,那么此处为什么能打印其中的元素,而不是哈希处理过的地址呢?
一般这种情况都是在其中重写了类型 toString()方法的,我们查看HashMap类的源代码:
1)get()方法是传入键,然后返回这个键对应的值,它是传入的是一个Object类型的参数,我们发现它命名为 K ,而在Map中 K 就代表键,他还有一个返回值,返回值是一个 V ,V就代表的是 值,这个值的类型就是我们在创建这个类的时候定义的泛型:
泛型:

get的返回值,和参数:

例子:
Map map = new HashMap<>();
map.put("好好学习","成功");
map.put("不好好学习","失败");
System.out.println(map);//{好好学习=成功, 不好好学习=失败}
String str1 = map.get("好好学习");
String str2 = map.get("及时雨");
System.out.println(str1);//成功
System.out.println(str2);//null 当其中有这个键值对的时候,就返回这个键对应的值,没有这个键值对,就返回null。
2)这个时候,我们可以使用另一个方法- getOrDefault(),他支持给值赋一个默认值,这个方法有两个参数,第一个是键,第二个是值,这个值就是默认值,那么这个方法的意思就是,我先在map中找有没有这个键值对,有就返回原本的值,没有就返回 传入的默认值:
Map map = new HashMap<>();
map.put("好好学习","成功");
map.put("不好好学习","失败");
System.out.println(map);//{好好学习=成功, 不好好学习=失败}
String str3 = map.getOrDefault("及时雨","宋江");
String str4 = map.getOrDefault("好好学习","不成功");
System.out.println(str3);//宋江
System.out.println(str4);//成功
System.out.println(map);//{好好学习=成功, 不好好学习=失败} 我们发现,没有对应键的地方就返回默认值,有这个键就就返回这个键本来的值,不会返回默认值,而且我们发现,如果map中没有这个键,那么我们在返回默认值之后,是不会在原来的map 中添加这个键值对的,如上述输出的最后一个map,并没有 (及时雨 = 宋江)。
需要注意的是:如果键值重复,也就说一个键,对应了两个值,那么在返回值的时候,会优先返回最新的那一个值:
String str5 = map.get("好好学习");
String str6 = map.getOrDefault("好好学习","hello");
System.out.println(str5);//成功2
System.out.println(str6);//成功2我们发现无论是 get()方法还是 getOrDefaul()方法都是选择了新的那个值。
3)containsKey()方法,判断是否有 传入参数对应的 键,有就返回 true,没有就返回 false:
Map map = new HashMap<>();
map.put("好好学习","成功");
map.put("好好学习","成功2");
map.put("不好好学习","失败");
System.out.println(map.containsKey("好好学习"));//true
System.out.println(map.containsKey("这是一个测试例子"));//false 4)containsValue()方法,判断是否有传入参数对应的 值,有就返回 true,没有就返回 false:
Map map = new HashMap<>();
map.put("好好学习","成功");
// map.put("好好学习","成功2");
map.put("不好好学习","失败");
System.out.println(map.containsValue("成功"));//true
System.out.println(map.containsValue("这是一个测试例子"));//false 上述containsKey()方法在有一个键(好好学习)对应两个值的时候返回了true,说明他能找到,但是对于containsValue()方法,如果是有一个键(好好学习)对应两个值的时候,我们如果查找的不是最新的那值,那么结果就返回false:
Map map = new HashMap<>();
map.put("好好学习","成功");
map.put("好好学习","成功2");
map.put("不好好学习","失败");
System.out.println(map.containsValue("成功"));//false
System.out.println(map.containsValue("成功2"));//true
System.out.println(map.containsValue("这是一个测试例子"));//false 我们发现containsValue()方法在有一个键(好好学习)对应两个值的时候,只能寻找到最新的那值,前面键对应的值不能找到。
5) entrySet()方法,这个方法可以返回这个集合中的所有的键值对,我们发现这个函数的放回类型是这样的:
这个其实包装好的键值对的类型,这个类型就把其中的 key 和 value 包装成一个类型,其中对应 K ,V 就是我们在创建这个对象的时候,写入的这个泛型:

那么我们就可以这样来使用 这个 entrySet()方法:
Set< Map.Entry > set = map.entrySet(); 此时我们就把 map 当中的 所有的键值对 都取出来 储存到 Map.Entry
for(Map.Entry s:set)
{
System.out.println(s);
}
//好好学习=成功
//不好好学习=失败 上述是直接打印,我们也可以单独拿出键和值:
for(Map.Entry s:set)
{
System.out.println(s.getKey());
}
//好好学习
//不好好学习
for(Map.Entry s:set)
{
System.out.println(s.getValue());
}
//成功
//失败 包装类
Object引用可以指向任意类型的对象,但是有例外,8中基本数据类型不是对象,那泛型机制不就失效了?
确实失效了,但是java中有一些特殊的类,这8中类型的包装类就是一些特殊的类,假设是int,那么会把这个int这样的值,包装到一个对象中去使用。
基本数据类型和包装类直接的关系

包装类的使用,手动装箱(boxing)和手动拆箱(unboxing)
- 装箱/装包: 将简单类型包装为 包装类 类型
- 拆包/拆包:把包装类类型 转变为 简单类型
public static void main(String[] args) {
int i = 10;
double d = 10.0;
// 装箱操作,新建一个 Integer 类型的对象,将 i 的值放入这个对象 的 某个属性中
Integer ii = Integer.valueOf(i); // valueOf() 这个方法,会把 i 这个简单类型 包装为 其对应的包装类型
Integer ij = new Integer(i); // 创建一个对象,利用这个对象里面构造犯法也可以 把这个简单类型 包装其 对应的包装类型
Double dd = new Double(d);
// 拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = ii.intValue();
double ddd = dd.doubleValue();
}自动装箱 拆箱
像下述这样写,就可以实现自动的装箱和拆箱:
public static void main(String[] args) {
//自动装箱
Integer a = 10;
//自动拆箱
int b = a;
}那么上述这样写,它的底层原理还是和我们手动拆箱 装箱是一样的,我们查看上述代码的反汇编代码,发现还是和之前一样,调用 valueOf()方法装包,调用 intValue()方法拆包:

问题
请问下述代码,输出什么:
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
System.out.println(a == b);
Integer c = 200;
Integer d = 200;
System.out.println(c == d);
}答案是:
true
false这是为什么呢?
因为上述都是自动装包,调用的是valueOf()方法,那么我们来查看这个方法的源代码:
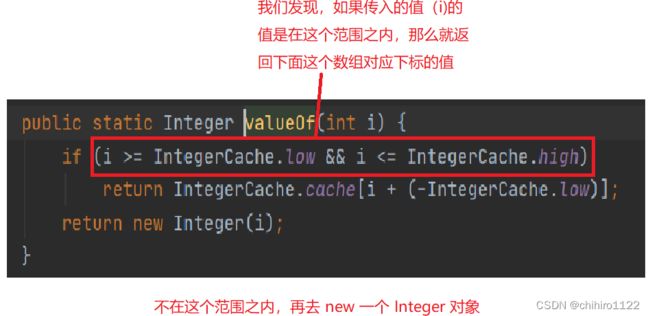
我们再来查看 low 和 high 的值:
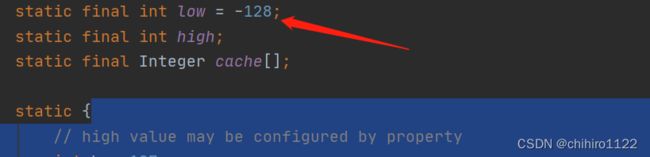
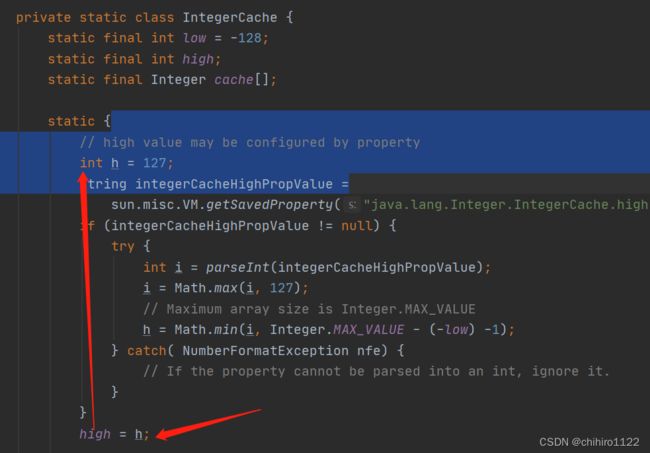
那么这个范围就是在 -128 < i < 127 这个范围,如果在这个范围之内,那么例如上述例子,会在内存中开辟一个数组,先在这个数组中存入一个 127 的值,然后

然后,当我第二次的数,也就是 b ,b也是在范围之内的,那么就会在这个数组中找到这个,127的下标(之前存储的下标),然后返回这个数组中为这个下标的元素。
那么实质上,上述例子的 a 和 b 所存储的都是一个数组中的同一个 100,因为第一个100 已经存储到 缓存好的 数组中去了,那么第二次如果还是100 ,那么就会在这个 数组中取出这个100继续使用。
相反,如果给的数一旦超出这个范围,那么就会直接去 new 一个对象,那么同样是上述例子,c和d都是200,超出范围,那么都是创建了一个对象,那么 c 和 d 保存的都是各自对象的引用。