线程池的核心线程数该怎么设置
线程池的核心线程数该怎么设置
- 前言
- 线程池原理及使用
-
- 代码示例
- 线程池执行步骤
- 参数说明
- 核心线程数、最大线程数、队列大小
- 拒绝策略
前言
为什么要用线程池?线程池中的线程可以重复利用,避免了重复创建线程造成的资源开销。在线程的执行时间比较短,任务比较多的时候非常适合用线程池。
线程池原理及使用
代码示例
// threadPoolExecutor 最好定义一个全局的,不用每次重建线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(5));
public testThreadPool() {
// 方式1 不需要返回值
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
// 处理相关业务
}
});
// 方式2 有返回值
Future<String> submit = threadPoolExecutor.submit(new businessWorker("param"));
}
class businessWorker implements Callable<String> {
public businessWorker(String param) {
}
@Override
public String call() throws Exception {
return null;
}
}
线程池执行步骤
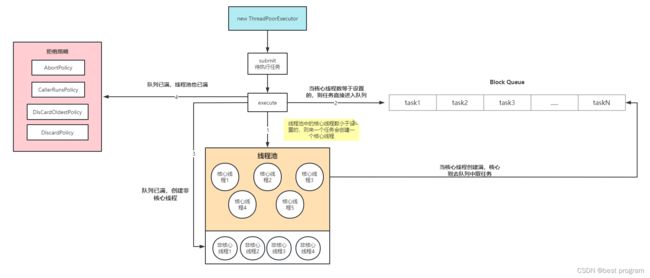
- 如果运行的线程少于核心线程,会尝试去开启一个新的核心线程(addWorker),如果有空间的核心线程,也不会去使用,而是去创建一个新的核心线程,直到核心线程创建满。核心线程创建满了,线程去队列中取任务。
- 如果运行的线程数等于核心线程数,任务则进入队列等待核心线程调用。
- 如果队列已满,则去创建非核心线程。
- 如果非核心线程也饱和了,则进入拒绝策略
参数说明
corePoorSize:核心线程数
maximumPoorSize:最大线程数–核心线程数+非核心线程数
keepAliveTime:非核心线程允许空闲时间,超过则非核心线程销毁
unit:keepAliveTime单位
workQueue:保存任务的阻塞队列
threadFactory:创建线程的工厂
hander:线程池饱和的处理方式(拒绝策略)
接下来根据这几个参数做进一步研究
核心线程数、最大线程数、队列大小
核心线程数、最大线程数、队列大小应该设置成多少合适,设置是否合理直接关系到线程池的处理能力。参考网上的说法要根据业务判断是CPU密集型还是IO密集型
CPU密集型:就会JVM自己内部处理的一些逻辑,额外的IO操作很少
IO密集型:可以理解为经常要和数据库交互,产生的IO操作比较多
CPU密集型核心线程数:CPU核数(逻辑核) + 1
IO密集型核心线程数:2 * CPU核数(逻辑核)
我们大部分JAVA WEB项目是IO密集型
上面其实就是一个理想状态的理论值,在实际应用中还会受其它影响,比如一台服务器不可能只有这一个应用,这一个应用中也会有其它线程。所以这个核心线程数的设置并不会十分准确,还要在线上使用时来调试这些参数。
首先要通过压测来设置出一个较为合理的参数。然后简单做一个线程池的数据监控,根据这些监控数据及线上的运行情况,可以在对线程数做一下适当的调整。线程池中提供了一些数据,可供我们调用
public HashMap<String, Object> getPoolInfo() {
poolInfo.put("activeCount", threadPoolExecutor.getActiveCount());
poolInfo.put("completedTask", threadPoolExecutor.getCompletedTaskCount());
poolInfo.put("poolSize", threadPoolExecutor.getPoolSize());
poolInfo.put("queueSize", threadPoolExecutor.getQueue().size());
poolInfo.put("taskCount", threadPoolExecutor.getTaskCount());
return poolInfo;
}
class AbortPolicyCustom implements RejectedExecutionHandler
{
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
log.info("线程处理异常");
Integer unCompletedTask = Integer.parseInt(String.valueOf(poolInfo.get("unCompletedTask") == null ? 0 : poolInfo.get("unCompletedTask")));
poolInfo.put("unCompletedTask", unCompletedTask + 1);
}
}
{
"activeCount":0,
"taskCount":1000,
"queueSize":0,
"poolSize":100,
"completedTask":1000,
"unCompletedTask": 0
}
taskCount: 请求过来的总任务数
poolSize:当前线程池的线程数
completeTaskCount:已完成的任务数
activeCount:当前正在运行的线程数
getQueue().size():可以获取当前队列中的任务数
unCompletedTask: 未完成任务数(需要通过拒绝策略自定义实现)
经验总结:
-
如果业务经常用
要求响应时间越快越好,可以适当将核心线程数和最大线程数调大一点,队列不用设置太大。这样既能提高响应,也不会浪费线程资源。
不要求响应时间,队列可以设置大一点。 -
如果业务不常使用
核心线程数可以设置小一点,最大线程数可以调成2倍核心线程数,这样如果核心线程不够用的话,可以创建非核心线程,待任务执行完后,到达空闲等待时间后销毁非核心线程,只保留了少数核心线程数,这样也不会浪费线程资源。 -
如果批量处理大量任务
不宜将核心线程数设置的太大,设置的太大可能会引起线程的上下文切换带来的问题,也降低了处理速度,可以适当将队列设置大一点,不要求响应时间,慢慢处理就好了,注意做好拒绝策略处理,避免任务丢失。
拒绝策略
总共有4种拒绝策略
- AbortPolicy:抛出异常(默认)
- CallerRunsPolicy:提交任务的线程自己执行
- DisCardOldestPolicy:把老的任务丢掉
- DiscardPolicy:什么都没干,直接丢掉任务
经验来说,大多数情况使用默认的抛出异常即可,这样保证即使任务丢失后,也能做好后续处理。
public void testThreadPool() {
long l = System.currentTimeMillis();
try {
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
handleMsg(l);
}
});
} catch (Exception e) {
log.info("任务处理异常:{}", e);
Integer unCompletedTask = Integer.parseInt(String.valueOf(poolInfo.get("unCompletedTask") == null ? 0 : poolInfo.get("unCompletedTask")));
poolInfo.put("unCompletedTask", unCompletedTask + 1);
}
}
如果第二个策略,让主线程自己执行,任务可以不丢失,但是如果出现大量任务被拒绝的话,主线程性能会直线下降。