Separating Skills and Concepts for Novel Visual Question Answering 论文笔记
Separating Skills and Concepts for Novel Visual Question Answering 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 VQA and Evaluations
- 3.2 Compositionality and VQA
- 3.3 Grounding Visual Concepts
- 四、Skill-Concept Composition in VQA
-
- 4.1 Novel-VQA Evaluation
- 4.2 Comparison to Existing Evaluations
- 4.3 Skill-Concept vs. Elementary Compositions
- 五、方法
-
- 5.0 Preliminaries
- 5.1 Overview
- 5.2 Concept Grounding
-
- 5.2.1 Concept Discovery
- 5.2.2 Concept-Context Contrastive (CCC) References
- 5.2.3 Concept Grounding Loss
- 5.3 Skill Matching
-
- 5.3.1 Skill References
- 5.3.2 Skill Matching Loss
- 5.4 Training Procedure
- 六、实验
-
- 6.1 Data and Settings
- 6.2 Model Comparisons
- 6.3 Novel Skill-Concept Composition VQA
- 6.4 Novel Concept VQA
- 6.5 Loss Ablation
- 6.6 CCC Reference Sets
- 6.7 Existing Benchmarks
- 七、结论
- 八、附录
-
- A、Skill and Concept Details
- B、Approach Details
-
- 1、Concept Grounding
- 2、Reference Sets and Training Procedure
- C、Experimental Details
-
- 1、Dataset Information
- 2、Model Configurations
- 3、Base Model Architecture
- 4、Qualitative Examples
写在前面
这是CVPR2021 VQA Workshop的第三篇论文,大胆预言一下是针对Novel Visual Question Answering数据集的。
论文链接: Separating Skills and Concepts for Novel Visual Question Answering
代码链接: github
切记:勿坐井观天!!!
一、Abstract
首先突出本文重点关注模型的泛化性,然后从技能和概念两方面阐述如何衡量泛化性。
- 技能:skills,指一项能力,例如计数,属性识别等。
- 概念:concepts,指问题中提及的名词?
对于VQA模型来说,需要将技能skills应用到概念concepts上。
接下来本文表明现有的模型在处理新的(技能+概念)组合方面还有很多需要改进的地方。因此,作者顺势提出解决方法:学习真正意义上的概念表示以及将技能的编码从概念中抽出,从而把这两个因素(技能 & 概念) 隐式的蕴藏在模型内部。
此外,作者采用一种新的对比学习的策略(不需要外部标注)来强化这些属性( 概念 & 技能),并且这些属性能够从无标签的 图像-问题对 中习得。
(摘要里面难以推断作者意图,继续往下看~)
二、引言
引言部分有点长,不同于以往的文章写很多前人的研究,本篇文章重点在于讲解新的 概念 & 技能。
同时为了帮助我们从概念 & 技能的角度理解VQA,所以作者一开始讲述了人类是如何回答VQA问题的:首先将问题划分到不同的部分:例如概念、关系、行为、问题类型,然后选择相应的技能并根据一定的信息+基础知识进行回答。
接下来引入主题,对技能的介绍:技能必须是一般的且能够能够应用到多种问题类型中去。举例: 一个人如果具有识别颜色的技能,再加上能够识别出车这一概念,就能回答像 “车是什么颜色?”这样的组合式问题。
这种利用技能来无缝地组合概念的能力以及能从无标签的数据中学习泛化性才是真正理解VQA的体现。于是作者表明需要更多的研究关注于将组合能力应用到模型中去,并开发出数据高效、泛化能力强的模型,而非一味追求在标准数据集上的性能 (๑•̀ㅂ•́)و✧ ;同时指出了当前有一些工作未能解决模型缺乏组合能力的问题,仅仅展示了模型的弱泛化性以及过度依赖于语言先验。
所以作者提出了 一种新的评估方式:测试模型泛化在技能 & 概念上的组合能力,称之为:技能-概念组合,这一评估方式源于能够回答出问题的两个关键之处:视觉概念必须和问题相关;需要从涉及到的概念中提取出信息。
Next 作者提出的模型介绍:利用对比学习的方法在模型内部将技能 & 概念分开,以提高泛化性的同时学习回答问题。所用的方法: 采用标签作为监督来分开概念,以致于模型能够学习区分问题和图像中的概念,而不用关注特定的内容;采用对比相同或不同技能的问题表示,把技能从概念中区分开。
该方法和弱监督类似,通过对比masked词的多模态表示和其他问题中词的多模态表示来恢复masked词(好似MLM?)。
作者所提模型的优势:
- 使用自监督的方式使用VQA数据,不需要外部标注;
- 不依赖于答案标签来学习技能-概念分布,因此能够使用无标签的图像-问题对,同时可以获得新的概念而不需要带有这些概念的标签数据;
- 重点关注于数据有效性,所以并不需要像预训练这种类似的方法来提高性能。
本文的主要贡献:
- 从 新的视角和评估设置 看待VQA的组合能力,命名为概念 & 技能组合;
- 提出一种新的对比学习方法,采用自监督学习的方式联合VQA的监督,实现不需要额外标注下分离概念 & 技能;
- 性能牛皮,在概念-技能组合能力和泛化到无标签的图像-问题对(包含不可视的概念)上很强。
三、相关工作
3.1 VQA and Evaluations
这一小节是对一些VQA数据集和方法的笼统介绍,指出这些模型考虑问题的基础前提与技能类似,但本文测试了技能 & 概念的泛化组合;现有的工作并未探索在一些新的组合方式上的泛化评估,相反作者在未曾见过的技能-概念组合上进行了评估。
3.2 Compositionality and VQA
GQA数据集提供了组合式的问题,但并未关注于新的组合方式,本文将组合能力应用到最牛批的transformer模型上,能够泛化到新问题。
3.3 Grounding Visual Concepts
之前的工作并未研究grounding concepts,本文开始关注grounding concepts,最直接的就是研究关于可解释性视觉注意力的模型,即:不依赖于任何额外的标注,研究问题中的 ground concepts,此举能够促进组合式的VQA model。
四、Skill-Concept Composition in VQA
总起:概念的特点:Objects、visually-grounded words or phrases;技能的特点:每个技能彼此独立。
作者的观察发现:回答一个问题,只需要少量的技能(大部分问题只涉及单个技能)。另外对模型泛化性能的说明:模型应该学习到的是能应用到不同概念中的技能 ,也就是不应该和训练过程中的特定概念绑定在一起。
最后再次强调一下贡献:将技能 & 概念分开。
4.1 Novel-VQA Evaluation
- 回答新的技能-概念组合式的问题;
- 回答模型之前没有见过任何答案的概念问题。
4.2 Comparison to Existing Evaluations
主要对比一下VQA cp v2 & TDIUC数据集,这部分不细讲,需要的自行了解一下这两个数据集就知道作者在讲啥了。
4.3 Skill-Concept vs. Elementary Compositions

介绍一下现有的组合式评估方法:将组合式定义为与问题相关的关系推理链,适用于逐元素操作的过程。但现有方法存在两个问题:
- 概念 & 属性过于简单,并不能代替现实世界中的视觉表示;
- 在合成数据集中的组合式问题极度依赖于现实世界的自然问题。
而本文提出的技能-概念视角更加适合真实世界的VQA,所以效果更好。
五、方法
5.0 Preliminaries
先决条件:数据集的设置,模型基本框架介绍;独特之处:利用了有标签和无标签的数据。
5.1 Overview
采用对比学习,以自监督的方式学习让技能 & 概念分离。
 训练模型:2对评估指标:concept grounding + skill matching, VQA指标。
训练模型:2对评估指标:concept grounding + skill matching, VQA指标。
5.2 Concept Grounding
mask问题中的概念词,然后使用多种模态的上下文信息(在推理数据集中指向样本中所提到的相同概念)来恢复这些词
5.2.1 Concept Discovery
采用 启发法 & 词形还原法,识别出400个频率最高的名词,并过滤掉非实体的词。
- rg+ 数据集:概念在问题和图像中同时存在;
- rg- 数据集:问题中并未提及任何相同概念。
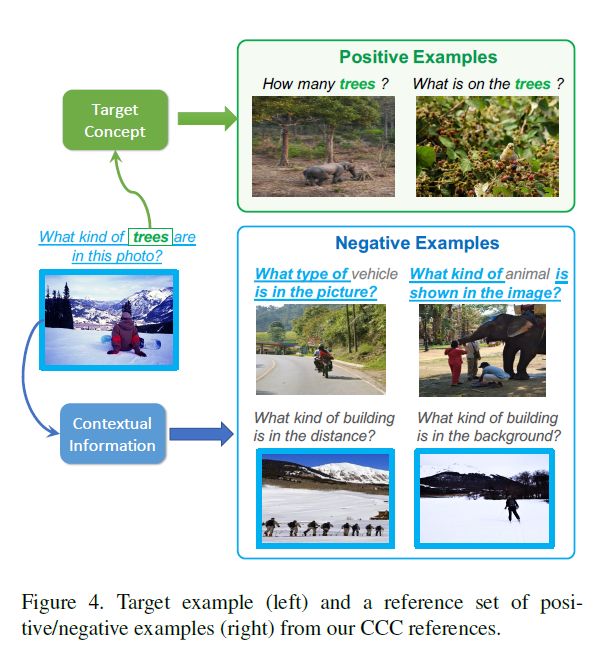
5.2.2 Concept-Context Contrastive (CCC) References
在这一部分,作者并未采用在rg+和rg-中随机采样,而是提出了推理样本过滤策略来促进concept grounding:正负样本应该迫使模型不再依赖于表面的线索而是查看正确的视觉区域。所以作者继续从rg+和rg-中提炼数据:对于每一个采样的样本,确保可以减少同时出现在样本中的相同因素。
以Fig . 4.为例,正样本中图像和问题中同时包含 “trees”,而对于负样本的干扰选项:问题类型相似或者场景相似但却不包含概念,也就是问题中不出现 “trees”。
ξ = β cos ( q , q ′ ) + ( 1 − β ) cos ( v , v ′ ) \xi=\beta \cos \left(q, q^{\prime}\right)+(1-\beta) \cos \left(v, v^{\prime}\right) ξ=βcos(q,q′)+(1−β)cos(v,v′)
本文的第一个公式:通过将masked后的问题和图像(正、负样本)送入现成的特征提取器,输出特征,然后比较样本的相似度,按照相似度排序规则来选择正负样本。
排序规则如下:
- 正样本: b = 0.6 b=0.6 b=0.6,最小化 E E E,选择N+个正样本;
- 负样本:两种设置: b = 0.7 b=0.7 b=0.7,最大化 E E E,强调负样本的文本要和正样本相似; b = 0.7 b=0.7 b=0.7,强调负样本图像要相似,选择N-个负样本。
5.2.3 Concept Grounding Loss
将masked问题和对应的图像输入到模型 f f f中,得到masked concepts的表示,然后将测试数据集中的每个样本单独作为模型的输入来获得每个样本的表示 h k j h_{kj} hkj, 其中 h k ∗ j ∗ h_{k^{*}j^{*}} hk∗j∗为正样本的表示。
损失函数:NCE loss,具体参考知乎:nce loss 与 sampled softmax loss 到底有什么区别?怎么选择?用公式表示为:
L g = − log exp ( sim ( ϕ g ( h i ) , ϕ g ( h ^ k ∗ , j ∗ ) ) ) ∑ k , j exp ( sim ( ϕ g ( h i ) , ϕ g ( h ^ k , j ) ) ) \mathcal{L}_{g}=-\log \frac{\exp \left(\operatorname{sim}\left(\phi_{g}\left(h_{i}\right), \phi_{g}\left(\hat{h}_{k^{*}, j^{*}}\right)\right)\right)}{\sum_{k, j} \exp \left(\operatorname{sim}\left(\phi_{g}\left(h_{i}\right), \phi_{g}\left(\hat{h}_{k, j}\right)\right)\right)} Lg=−log∑k,jexp(sim(ϕg(hi),ϕg(h^k,j)))exp(sim(ϕg(hi),ϕg(h^k∗,j∗)))
其中 ϕ g \phi_{g} ϕg为投影函数, s i n ( . , . ) sin(.,.) sin(.,.)为余弦相似度的计算,
作者点评:提出的CCF数据集增强了正样本中概念词的表示,masked的概念被强制匹配到正确的视觉区域。
5.3 Skill Matching
利用技能回答的问题很大程度上与问题中的概念和图像中的appearances无关。以计数为例:需要统计目标的个数,而与目标的类型无关。
总结:技能共享推理答案的关键步骤,而和概念无关。
5.3.1 Skill References
模型学习技能最直接的方法就是指定需要相同推理步骤的问题,但是这种指定一般出现在合成数据集中(非真实世界)。所以作者提出:计算msak concepts后问题的BERT表示。
- rs+:正样本:采用 BERT计算前200个最高相似度的问题;
- rs-:负样本:从数据集的剩下部分随机抽取。
5.3.2 Skill Matching Loss
将目标样本送入BERT模型中,池化所有问题单词的输出,然后从推理数据集中采样样本,正样本数据共享目标样本中相同的技能 。这一部分具体咋操作建议要看下源码。
L s = − log exp ( sim ( ϕ s ( h ) , ϕ s ( h ^ l ∗ ) ) ) ∑ l exp ( sim ( ϕ s ( h ) , ϕ s ( h ^ l ) ) ) \mathcal{L}_{s}=-\log \frac{\exp \left(\operatorname{sim}\left(\phi_{s}(h), \phi_{s}\left(\hat{h}_{l^{*}}\right)\right)\right)}{\sum_{l} \exp \left(\operatorname{sim}\left(\phi_{s}(h), \phi_{s}\left(\hat{h}_{l}\right)\right)\right)} Ls=−log∑lexp(sim(ϕs(h),ϕs(h^l)))exp(sim(ϕs(h),ϕs(h^l∗)))其中 h ^ l ∗ \hat{h}_{l^{*}} h^l∗为正样本表示, ϕ s \phi_{s} ϕs为另一个投影函数。此损失函使得需要相同技能回答的问题表示类似,而不管问题中所提及的概念词。
5.4 Training Procedure
在训练过程中,第一次从有标签的数据集中采样,然后通过最小化VQA指标来更新模型参数。也就是第一次使用VQA指标更新模型参数,然后应用提出的其他指标最小化 L g , L s L_g,L_s Lg,Ls损失来更新模型参数。
六、实验
6.1 Data and Settings
本文工作旨在测试模型在不同新颖问题上的性能,所以采用VQA v2 val进行测试。
6.2 Model Comparisons
采样的模型:StackNMN、XNM;Lxmer、Uniter。当然最重要的是:无内鬼:预训练+外部数据。基础模型:没有使用技能-概念对比损失的模型。牛皮模型:当然是采用了提出的损失呀。
6.3 Novel Skill-Concept Composition VQA
在VQAv2上选取具有代表性的三个技能: 计数、颜色识别、子类识别。对于每一个 技能,都会采用训练集随机选取的单个种类或多个种类的概念来代替问题中的数据标签,然后测试这些组合式问题。
随机选取的概念的符合标准:
- 每一个concepts-skills组合都包含可信数量的测试数据;
- 组成部分在数据集上的分布不同。
下面是测试结果:

有意思的结论是:组合式的模型(XNM、StackNMN)与transfrormer相比,性能更低。
6.4 Novel Concept VQA
此次测试的是:模型之前从未训练过关于回答概念的问题,但使用了无标签的图像-问题对,在所给概念相同的问题上进行测试。

结论中突出了一点:可能transformer架构能够在大尺度视觉和语言预训练中表现的好,但很难专注于特定的VQA任务。
6.5 Loss Ablation
单个损失使用时:grounding loss> skill loss。
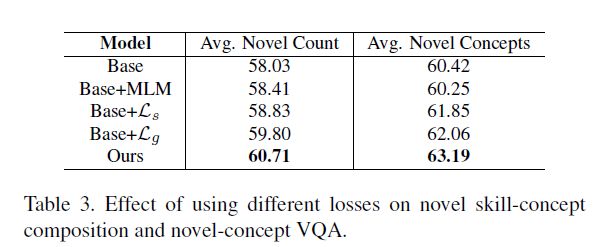
6.6 CCC Reference Sets
唯一不同之处在于推理数据集的构建采用了概念损失。

6.7 Existing Benchmarks

七、结论
作者提出了一个新的泛化性测试来衡量组合概念 & 组合的能力,同时表明现有的方法很难泛化到组合式问题上。本文提出新的方法: 隐式的分开概念 & 组合,同时使用对比学习的策略建模视觉上的概念。提出的方法可以根据无标签的训练数据回答从未见过的概念,并且在概念 & 组合组合问题以及泛化到无标签的数据上很棒~
八、附录
A、Skill and Concept Details
主要突出一下难点问题,具体请查看原论文。下面是一些技能举例:

概念分组 :

技能 & 概念分组的标准:
- 每一个技能组合由400个训练问题和200个测试问题构成;
- 先分到大组,然后小组。
B、Approach Details
这一部分建议查看源码呦~
1、Concept Grounding
ϕ g ( x ) = W g x + b g \phi_{g}(x) =W_{g} x+b_{g} ϕg(x)=Wgx+bg
sim ( x , y ) = x ⊤ y d \operatorname{sim}(x, y) =\frac{x^{\top} y}{\sqrt{d}} sim(x,y)=dx⊤y
ϕ s ( x ) = W s ( 2 ) ψ ( W s ( 1 ) x + b s ( 1 ) ) + b s ( 2 ) \phi_{s}(x) =W_{s}^{(2)} \psi\left(W_{s}^{(1)} x+b_{s}^{(1)}\right)+b_{s}^{(2)} ϕs(x)=Ws(2)ψ(Ws(1)x+bs(1))+bs(2)
sim ( x , y ) = cos ( x , y ) τ s \operatorname{sim}(x, y) =\frac{\cos (x, y)}{\tau_{s}} sim(x,y)=τscos(x,y)
2、Reference Sets and Training Procedure
从参考数据集中选择候选样本来构建CCC候选数据集,需要旋转的正样本数量 N + = 20 , N − = 40 N^+=20,N^-=40 N+=20,N−=40,由于负样本有两种设置方法,所以这里是2倍的关系。
而对于技能匹配候选数据集来说, N + = 200 , N − = 200 N^+=200,N^-=200 N+=200,N−=200。在每一步的训练中, p s e p = 0.1 , N r + = 1 , N r − = 2 p_{sep}=0.1,N_r^+=1,N_r^-=2 psep=0.1,Nr+=1,Nr−=2,这样使得模型能够在单个正样本和两个负样本之间进行对比。而对于concept grounding损失,负样本是从所有两种负样本设置方法中选择其中一个。
C、Experimental Details
1、Dataset Information
对于那些包含技能和概念的问题,利用不同的NLP规则来处理。例如标签技能,采用问题模板来匹配和验证答案是否符合匹配到的模板;而对于标签概念,利用词形还原和负标签来选择频率最高的名词,之后会创建不同的训练分布,例如具有特定的技能-概念组合或者概念被移除而只留技能的分布。
实验在VQA-CP和VQA v2数据集上进行,包含测试开发,测试标准集。在标准集上实验室,利用验证集和VG数据集进行训练。
(工作量确实挺大的,令我等汗颜)
2、Model Configurations
说明一下上述4个模型的配置情况:

3、Base Model Architecture
需要注意的点:标准的transformer模型和本文的基础模型有两点细微区别:本文在输入问题到transformer层之前,经过了一层双向LSTM,(MCAN也这么干过),与位置嵌入相比有轻微的性能提升;每一层中的CLS词和视觉区域能够参与到所有输入中,包括自身token,问题token和CLS词也能参与,因此视觉信息和文本信息就可以利用CLS词进行上下文的交互。
4、Qualitative Examples
数据可视化:

写在后面
这篇文章的笔记终于是写完了,说实话,理解起来确实有点长&难,虽然大部分意思都清楚了,但是感觉还是有那么些晦涩,推荐还是去看源码吧~
2021.11.11 再更新,既然这篇博客还有同学在看,那就把格式改漂亮些~