(新手向)在matlab中运用SMOTE和前馈神经网络对wilt(枯萎)数据集进行机器学习
目录
- 一.概述
- 二.数据集描述
- 三.方法
-
- 数据预处理
- SMOTE算法
- Feed-forward网络
- 四.结果
-
- 后记(2021年5月)
一.概述
近日,有位同学因为搞不懂matlab中的神经网络来问我怎么做,我说你把数据集发来给我看看,我稍微一看好像没啥毛病,他跟我说是UCI上面找的一个wilt数据集,而且已经划分好了训练集和测试集,我粗粗一看没啥毛病就把它直接放进了matlab的神经网络工具箱中进行训练,没想到训练出来的网络在测试集上表现如此糟糕,全都分类成了正常,此时再回去看数据集发现原来这涉及到了机器学习中的类不平衡问题,于是采用了SMOTE(过采样)方法先对少数类进行扩充,扩充成了原来的4倍,再进行训练,此时的表现已经好了很多,在测试集上达到了88%的准确率。要知道提供该数据集的论文运用了SMOTE+SVM,可惜在测试集上的准确率才70%多,可见科技发展是迅速的。
此处matlab版本为 R2018a。
二.数据集描述
数据集来源:https://archive.ics.uci.edu/ml/datasets/Wilt
这个数据集通俗的说是遥感领域对树进行拍照,然后把照片中的像素多少和生病的树这二者结合做成了这个数据集,通过5项属性来预测树是否枯萎(生病)。实际上就是个2分类问题。下载该数据集后得到了一个training.csv和testing.csv文件,让我们先来看看里面具体长啥样。首先是training.csv文件。
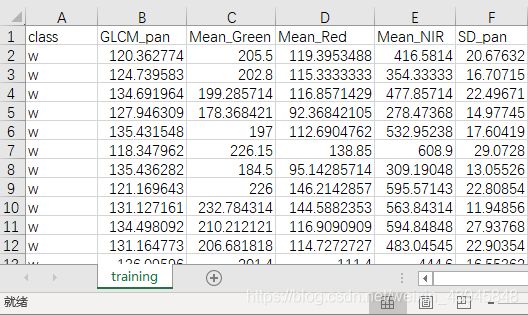
左边第一列是分类,类有2类,w类(枯萎)和n(正常)类,作为我们的输出变量,右边5列5个属性,也就是我们需要的输入变量。
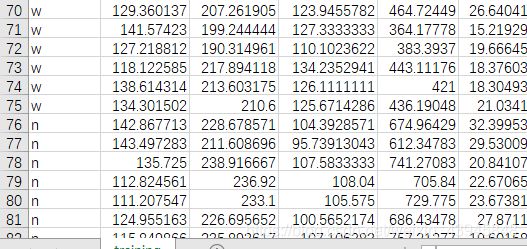
这里我们可以很明显的看到只有74个样本属于w类,剩下还有4264个样本均属于n类,这里出现了类别不平衡问题,w类的样本太少,提供的信息也太少,模型得不到足够的信息就会把少数类给忽视,这显然不是我们想看到的。
对于测试集的信息此处省略。总共500个样本,其中313个属于n类,187个属于w类。与训练集不同的地方在于它的排序是乱的,需要自己处理,不像训练集给你按class排好了。
三.方法
数据预处理
拿到数据集第一步,不是急急忙忙去套模型,是先分析数据特征,不然就会犯和我一样的错,前文中也提到了,这个数据集最特殊的就是类别不平衡问题,这个用SMOTE解决,在接下来的部分中详细阐述。这里对数据并不进行归一化,原文献提供的数据集已经经过了一定的处理,且归一化后实际效果要比归一前差很多。
SMOTE算法
http://freesourcecode.net/matlabprojects/64007/smote-(synthetic-minority-over-sampling-technique)-in-matlab#.XLfieKR5uUl
这个链接提供了简单易行的smote算法,把它下载下来后得到两个主要函数SMOTE.m和nearestneighbour.m。把它放进你的工程目录。smote算法简单来说就是对少数样本进行插值生成,而这其中涉及到一个k值(近邻大小),该k值在SMOTE.m中通过函数nearestneighbour.m自动选择,默认将样本放大4倍。
我们在这里先打开training.csv,为了方便matlab处理,我们先在excel中多加一个label列,1表示生病,0表示正常。
接下来让我们把前74个样本提取出另保存至一个excel表格。在matlab中选择上方的“导入数据”按钮,可得到以下界面:
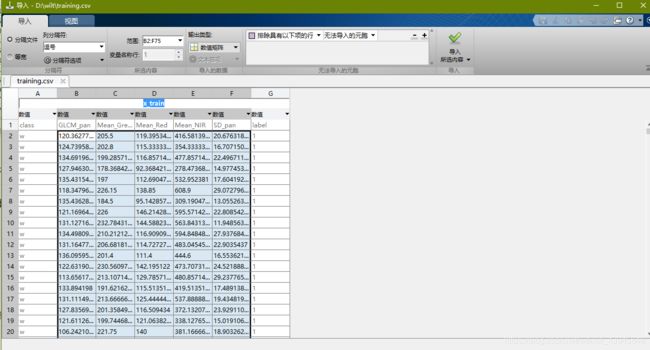
选中数值矩阵,选中5列属性,变量名称命名x_train,点击导入。
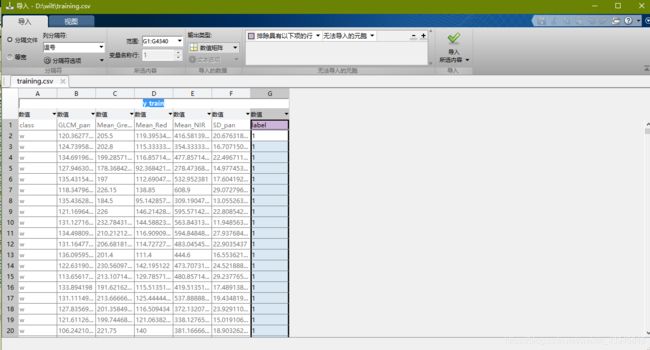 同理选择数值矩阵输出,导入label列,命名为y_train。
同理选择数值矩阵输出,导入label列,命名为y_train。
把matlab的工作空间切换到你的工程目录下(放有smote函数的地方)
接下来只要在命令行窗口中输入以下代码
// SMOTE算法扩展样本
[feature,label]= SMOTE (x_train,y_train);
原来的74个样本就变成了296个样本!
把这些新样本复制进训练集的excel中,总共得到4581个训练样本。同理再进行导入,得到以下初始化的工作区:
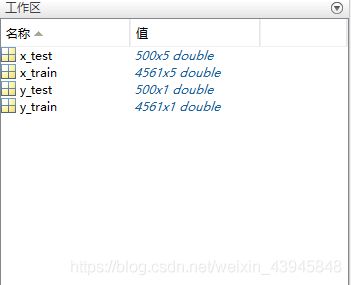
干干净净,有没有,保存工作区为wilt.mat文件,到此我们的数据处理就结束了,接下来就可以建立模型了。
Feed-forward网络
这是我建立该网络并测试用的wilt.m,代码如下:
clear;
clc;
load wilt.mat; %装入事先处理好的wilt数据集
inputnum = 5; %第一层输入神经元为5
hiddennum = 8; %第二层隐含神经元为8
outputnum = 1; %第三层输出神经元为1
x_train = x_train'; %输入为500x5 转置为5x500 以下类似
x_test = x_test';
y_train = y_train';
y_test = y_test';
net = newff(minmax(x_train),[inputnum,hiddennum,outputnum],...
{'tansig','logsig','purelin'},'trainlm'); %创建feed-forward神经网络
view(net) %输出网络图
net.trainParam.epochs = 5000; %设定最大迭代次数
net.trainParam.goal = 0.0000000001; %设定学习目标(最小误差)
[net,tr]=train(net,x_train,y_train);%拟合训练集
outputs = net(x_test); %输出测试集结果
perf = perform(net,outputs,y_test); %比较预测和测试集表现
final = round(outputs); %对测试集结果取整
final = final'; %转置
y_test = y_test'; %转置
k = 0; %k为预测(final)和测试集(y_test)相同样本个数
for i = 1:500 %循环 相同则k加一
if final(i,1) == y_test(i,1)
k = k+1;
end
end
fprintf('算法准确率为: %2.2f%%\n', mean(double(k/500)) * 100) %打印算法准确率
这其中要说明的是此处建立了三层神经网络,结果可以在下面看,隐含层神经元选取了8个,网上有不少公式计算选取神经元,但还是自己试试比较好,调参还是要看实际情况的,跑出来结果好,这个参数就好。传递函数的选取也是一样的道理。至于为什么要转置,是因为matlab的神经网络默认是按列选取,当然也可以按行,此处习惯按列了。
还有一个比较重要的点是,一定要用训练集去拟合模型,测试集去测试,不能再用训练集去测试,这反映不出模型对新数据的预测能力,同时还有可能反映不出对原有训练集过度拟合的现象。
四.结果
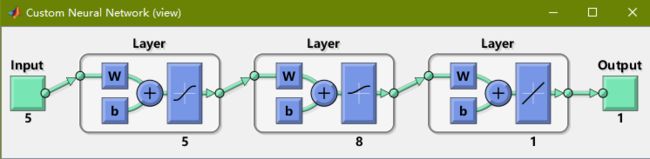
这个图就是神经网络的预设图,三层,输入层5个神经元,隐含层8个神经元,输出层1个神经元。
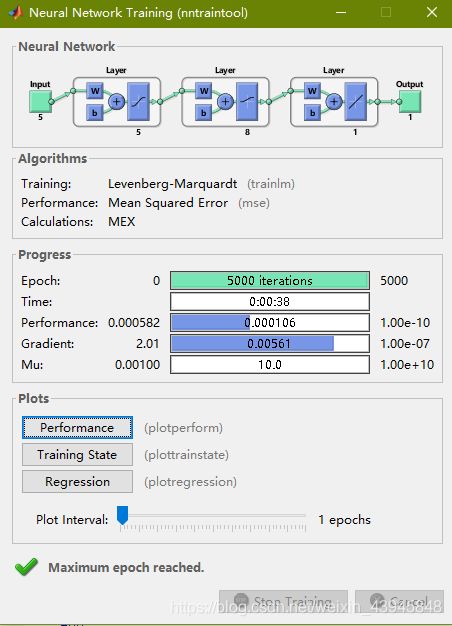
运行时会跳出神经网络工具箱,Epoch为迭代次数,PERFORMANCE为误差表现。
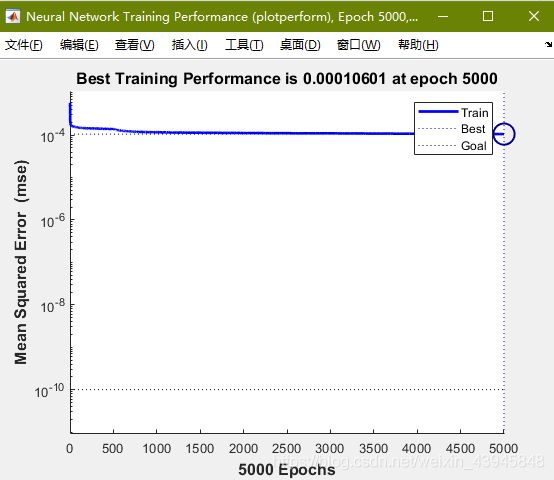
差不多在1000次迭代之后误差就很难继续缩小了,拟合已经完毕,这个时候已经可以按stop停止训练了。
![]()
这是最后得到的准确率,500个测试样本中测试成功的样本有441个,对于这个数据集来说效果还是可以的。
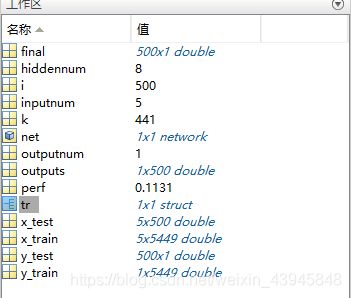
这是我最后输出的工作区,其中5449个训练样本是我再一次运用SMOTE算法之后得到的训练总样本数,此时已经有1000多个w类样本,可惜如同我预测的一样,再进行新样本的生成已经不能使模型获得更新的信息,模型拟合已然到达极限。
后记(2021年5月)
现在回过头来看这个提供的SMOTE算法,其实最大的问题就是没有提供修改抽样比例的接口,我也不建议大家在源代码上修改,如果还要解决这种不平衡问题请使用python的imblearn库里预设的各类SMOTE算法,支持直接修改抽样比例,适用性也更加广泛。
另外,虽然这种方法能使你的测试集上的表现提高,但并不意味着你在新的数据集上的表现良好!!!!!!
这种方法很容易产生过拟合问题,泛化能力不行,写论文展现一下技巧可以,投入实际解决问题还请慎重。