第28步 机器学习分类实战:Catboost建模
文章目录
- 前言
- 一、Python调参
-
- (1)建模前的准备
- (2)Catboost的调参策略
- (3)Catboost调参演示
-
- (A)先默认参数走一波
- (B)开整Model1(SymmetricTree)
- (C)开整Model2(Depthwise)
- (D)开整Model3(Lossguide)
- 二、SPSSPRO调参(自己琢磨了哈)
- 总结
前言
Catboost建模~
一、Python调参
(1)建模前的准备
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
(2)Catboost的调参策略
先复习一下参数,需要调整的参数有:
① depth:树深度,默认6,最大16。
② grow_policy:子树生长策略。可选:SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)。
③ min_data_in_leaf:叶子结点最小样本量。只能与Lossguide和Depthwise增长策略一起使用。
④ max_leaves:最大叶子结点数量,不建议使用大于64的值,因为它会大大减慢训练过程。只能与 Lossguide增长政策一起使用。
⑤ iterations:迭代次数,默认500。
⑥ learning_rate:学习速度,默认0.03。
⑦ l2_leaf_reg:L2正则化。
⑧ random_strength:特征分裂信息增益的扰动项,默认1,用于避免过拟合。
⑨ rsm:列采样比率,默认值1,取值(0,1]。
(3)Catboost调参演示
(A)先默认参数走一波
import catboost as cb
classifier = cb.CatBoostClassifier(eval_metric='AUC')
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
虽然过拟合,但是比之前的xgb和lgb好一点:


验证集的AUC已经来到0.8693,媲美之前的任何模型了,不过训练集的AUC已经接近1.0了(0.9978),所以还是存在过拟合,继续调参看看能否改善。
(B)开整Model1(SymmetricTree)
(a)由于grow_policy选择SymmetricTree,因此min_data_in_leaf和max_leaves调整不了。因此,先调整depth试试:
import catboost as cb
param_grid=[{
'depth': [i for i in range(6,11)],
},
]
boost = cb.CatBoostClassifier(eval_metric='AUC')
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
print(cm_train)
print(cm_test)
最优参数:depth=7
Catboost的最优参数的调取有点不同,之前介绍的两种方法找起来有点困难,因此直接输入代码:
grid_search.best_estimator_._init_params:
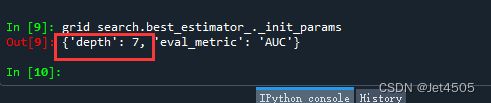
结果就不看了,肯定也是过拟合,毕竟没有调过拟合相关参数。
(b)然后,调整l2_leaf_reg:
param_grid=[{
'l2_leaf_reg': [i for i in range(1,11)],
},
]
boost = cb.CatBoostClassifier(depth = 7, eval_metric='AUC')
最优参数:l2_leaf_reg=6
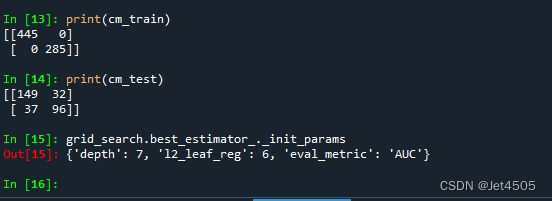
然后就凉凉,越调越过拟合。
(c)继续调整过拟合的参数:random_strength
param_grid=[{
'random_strength': [i for i in range(1,11)],
},
]
boost = cb.CatBoostClassifier(depth = 7, l2_leaf_reg = 6, eval_metric='AUC')
最优参数:random_strength=7

依旧过拟合。
(d)继续调整参数rsm:
param_grid=[{
'rsm': [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0],
},
]
boost = cb.CatBoostClassifier(depth = 7, l2_leaf_reg = 6, random_strength=7, eval_metric='AUC')
最优参数:rsm=0.3

一顿操作,还不如第一版,接下来,缩短一下迭代次数试试:
(e)learning_rate和iterations一起调整试试:
param_grid=[{
'learning_rate': [0.03,0.06,0.08,0.1],
'iterations': [100,200,300,400,500,600,700,800],
},
]
boost = cb.CatBoostClassifier(depth = 7, l2_leaf_reg = 6, random_strength=7, rsm=0.3, eval_metric='AUC')
最优参数:learning_rate=0.06和iterations=300

综上,最优参数为grow_policy=‘SymmetricTree’, depth=8, min_data_in_leaf=115, l2_leaf_reg=6, rsm=0.3, random_strength=7, learning_rate=0.06, iterations=300, eval_metric=‘AUC’。
(f)最后试试Overfitting detection settings的几个参数:
① early_stopping_rounds:早停设置,默认不启用。
classifier = cb.CatBoostClassifier(grow_policy='SymmetricTree', depth=8, min_data_in_leaf=115, l2_leaf_reg=6, rsm=0.3, random_strength=7, learning_rate=0.06, iterations=300, early_stopping_rounds=200, eval_metric='AUC')
classifier.fit(X_train, y_train)
事实证明,没啥用。继续往下测试。
② od_type:过拟合检测类型,默认IncToDec。可选:IncToDec、Iter。
③ od_pval:IncToDec过拟合检测的阈值,当达到指定值时,训练将停止。要求输入验证数据集,建议取值范围[10e-10,10e-2]。默认值0,即不使用过拟合检测。
这一步呢,就是在模型拟合的时候,输入我们划分的验证集,多少有点提前漏题的感觉,这里也演示一下,大家心里有数:
classifier = cb.CatBoostClassifier(grow_policy='SymmetricTree', depth=8, min_data_in_leaf=115, l2_leaf_reg=6, rsm=0.3, random_strength=7, learning_rate=0.06, iterations=300, early_stopping_rounds=200, eval_metric='AUC')
classifier.fit(X_train, y_train, eval_set=(X_test, y_test), plot=True)
看看结果,过拟合有所缓解:

然后,试一试调整od_type和od_pval:
classifier = cb.CatBoostClassifier(grow_policy='SymmetricTree', depth=8, min_data_in_leaf=115, l2_leaf_reg=6, rsm=0.3, random_strength=7, learning_rate=0.06, iterations=300, early_stopping_rounds=200, eval_metric='AUC', od_type='IncToDec',od_pval=0.1 )
classifier.fit(X_train, y_train, eval_set=(X_test, y_test), plot=True)
结果没变化,接着用网格试一试od_pval用哪个取值好一些:
import catboost as cb
param_grid=[{
'od_pval': [0.6,0.2,0.1,0.01,0.001,0.0001,0.00001,0.000001],
},
]
boost = cb.CatBoostClassifier(grow_policy='SymmetricTree', depth=8, min_data_in_leaf=115, l2_leaf_reg=6,
rsm=0.3, random_strength=7, learning_rate=0.06, iterations=300, early_stopping_rounds=200,
eval_metric='AUC')
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train, eval_set=(X_test, y_test))
classifier = grid_search.best_estimator_
事实证明,没有变化,所以就这样吧,看看Model1的最终结果:


(C)开整Model2(Depthwise)
(a)grow_policy选择Depthwise,因此多加了一个min_data_in_leaf可调整。类似地,先调整depth试试:
depth还是等于7,依旧过拟合。
(b)调整min_data_in_leaf
param_grid=[{
'min_data_in_leaf': range(5,200,10),
},
]
boost = cb.CatBoostClassifier(grow_policy='Depthwise', depth=7, eval_metric='AUC')
min_data_in_leaf等于135,过拟合有缓解。


(c)然后,我再调整l2_leaf_reg、random_strength、learning_rate和iterations等参数,性能又回去了,所以到此为止了吧。直接看Model2的结果(我没有用验证集来调参):


(D)开整Model3(Lossguide)
(a)grow_policy选择Lossguide,因此多加了min_data_in_leaf和max_leaves可调整。类似地,先调整depth试试:
depth还是等于8,依旧过拟合。
(b)调整min_data_in_leaf
param_grid=[{
'min_data_in_leaf': range(5,200,10),
},
]
boost = cb.CatBoostClassifier(grow_policy='Lossguide', depth=8, eval_metric='AUC')
最优参数:min_data_in_leaf=115

(c)调整num_leaves
param_grid=[{
'num_leaves': range(5, 100, 5),
},
]
boost = cb.CatBoostClassifier(grow_policy='Lossguide',
depth=8,min_data_in_leaf=115, eval_metric='AUC')
最优参数:num_leaves=5
效果还不错:


(d)l2_leaf_reg、random_strength、learning_rate和iterations等参数,我就不调了,预感调整以后性能又回去了,所以到此为止了吧。直接看看Model3的结果(这里我没有加入验证集进行调参):

二、SPSSPRO调参(自己琢磨了哈)
略~
总结
根据grow_policy(子树生长策略)可以分成三种模型(Model1、Model2和Model3),其中,严格来说使用SymmetricTree(对称树)的才是原汁原味的Catboost,毕竟对称树就是它的特色之一。
从结果来做,Model1存在较大的过拟合,除非运用测试集进行调试(这个我保留意见哈),Model2和Model3引入DT的一些参数,可以较好的纠正过拟合。
多说一句,Catboost我也是刚学不久,感觉还是很多隐藏技能没学到,一家之言,供大家参考,要是有错误,欢迎指正。