MySQL数据库基础知识(一)
数据库基础知识
- 1. 数据库概述
-
- 1.1 入门
- 1.2 DQL(数据查询语言)
-
- 1.2.1 简单查询
- 1.2.2 条件查询
- 1.2.3 排序
- 1.2.4 数据处理函数(单行处理函数)
- 1.2.5 分组函数(多行处理函数)
- 1.2.5.1 分组查询(重要*****)
- 1.2.6 去除重复记录
- 1.2.7 连接查询
-
- 1.2.7.1 内连接之等值连接
- 1.2.7.2 内连接之非等值连接
- 1.2.7.3 内连接之自连接
- 1.2.7.4 外连接
- 1.2.7.5 多表之间的连接
- 1.2.8 子查询
-
- 1.2.8.1 where子句中的子查询
- 1.2.8.2 from子句中的子查询
- 1.2.8.3 select子句中的子查询(了解即可)
- 1.2.9 union可以合并集合
- 1.2.9 limit可以将查询结果的一部分取出来
- 1.2.10 分页
1. 数据库概述
1.1 入门
-
SQL概述:SQL全称是Structured Query Language,SQL用来和数据库打交道,完成和数据库的通信,SQL是一套标准,但是每一个数据库都有自己的特性,当使用这个数据库特性相关的功能,这是SQL语句可能就不是标准了(90%以上的SQL都是通用的)
-
什么是数据库?
数据库(Database,简称DB)通常是一个或一组文件,保存了一些复合特定规格的数据; 数据库软件称为数据库管理系统(DBMS, Database Management System),如MySQL,Oracle, SQL Server, DB2等 -
MySQL概述
是一个关系型数据库管理系统,不仅是最流行的开源数据库,而且是业内成长最快的数据库。2009年,Oracle收购了sun公司,使MySQL并入Oracle的数据库产品线。 -
什么是数据库?什么是数据库管理系统?什么是SQL?他们之间的关系是什么?
数据库(Database,简称DB)通常是一个或一组文件,保存了一些复合特定规格的数据;
数据库管理系统,简称DBMS,是专门用来管理数据库中数据的,DBMS可以对数据库中的数据进行增删改查;
SQL是结构化查询语言,程序员需要学习SQL语句,通过编写SQL语句,执行SQL语句,最终来完成数据库中数据的增删改查;
关系:DBMS通过执行SQL语句来对DB进行管理。 -
安装MySQL数据库,先安装“经典版”,一路下一步就行了。
注意:①MySQL默认端口号为3306。端口号是任何一个应用/软件都会有的,端口号是应用的唯一代表,通常和IP地址搭配使用,IP地址用来定位计算机,端口号Port用来定位计算机上某个服务;②MySQL的字符编码方式为UTF-8;③MySQL超级管理员用户名为root,不能修改。 -
卸载MySQL:第一步双击安装包进行卸载,第二步删除C:\ProgramData下面MySQL目录,并且删除C:\Program File(x86)下的MySQL目录。
-
MySQL服务的启动与停止
计算机–>右键–>管理–>服务和应用程序–>服务–>找到MySQL服务。默认是自启动状态,可以再服务上点击右键进行启动、重启服务、停止服务等操作。
使用命令来启动和关闭服务: net stop 服务名称; net start 服务名称 -
数据库中用表来存储数据:表比较直观。任何一张表都有行和列:行(row):被称为数据/记录 。列(column):被称为字段,每一个字段都有字段名,数据类型,约束等属性。
-
SQL语句的分类:
数据查询语言(DQL-Data Query Lanauage):代表关键字select
数据操纵语言(DML-Data Manipulation Language):insert,delete,update
数据定义语言(DDL- Data Definition Language):create,drop,alter
事务控制语言(TCL-Transactional Control Language):commit,rollback
数据控制语言(DCL-Data Control Lanauage ):grand,revoke
MySQL常用命令
- 登录:mysql.exe -h主机地址 -P端口 -u用户名 -p密码
1、通常端口都可以默认:mysql的监听端口通常都是3306
2、mysql 或者mysql.exe
3、密码的输入可以先输入-p,直接换行,然后再以密文方式输入密码(安全)
4、-h 主机名,可以使用该参数指定主机名或Ip,如果不指定,默认是localhost - 退出:exit
- 查看数据库版本: select version();
- 查看都有哪些数据库:show databases;
- 创建数据库:create ***;
- 使用某个数据库:use ***;
- 查看某个数据库下有哪些表: show tables;
- 查询某个表的所有数据: select * from 表名;
- 查看表结构:desc 表名;
- 中止某条命令的输入:\c
1.2 DQL(数据查询语言)
1.2.1 简单查询
| 需求 | 命令 |
|---|---|
| 查询一个字段 | select 字段名 from 表名; |
| 查询多个字段 | select 字段1,字段2 from 表名;(用逗号隔开) |
| 查询所有字段 | select * from 表名;(或用逗号隔开所有字段) |
| 给某个字段起别名 | select 旧名 as 新名 from 表名; |
| select 旧名 新名 from 表名; | |
| select 旧名 ‘new name’ from 表名;(名字里有空格) | |
| 列参与数学运算 | select 字段名*12 from 表名; |
Note:
1.使用as关键字起别名的时候,只是将显示的查询结果列明显示为“新名”,数据库中的原表列名还是“旧名”,因为select语句只负责查询,不会对表格进行修改操作。
2.as关键字是可以省略的:select 旧名 新名 from 表名;假设起的别名里有空格,用单引号(或双引号,但是双引号在oracle数据库中用不了,数据库中的字符串标准都是使用单引号括起来,双引号不是标准的)把别名括起来
3. 如果别名是中文的,也需要使用单引号括起来
4. 字段是可以参加加减乘除运算的
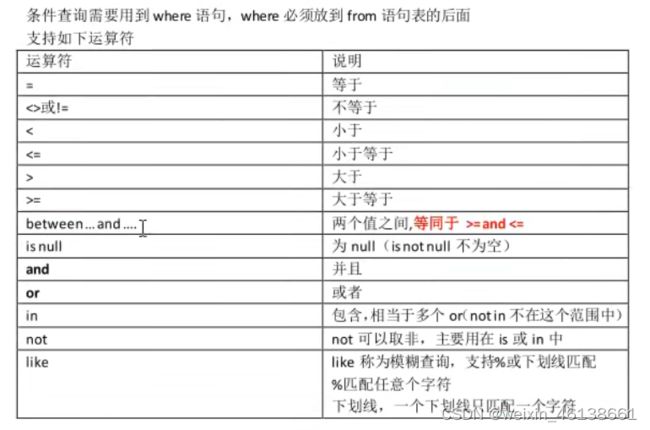
1.2.2 条件查询
select 字段1,字段2,..., from 表名 where 条件;
条件:
注意:
- 在数据库中null不能使用等号进行衡量。需要使用 is null,因为数据库中的null代表什么也没有,它不是一个值,所以不能使用“=”衡量。
- where后面如果and,or的条件, 则or自动会把左右的查询条件分开,即先执行and,再执行or。原因就是:and的优先级最高。
- in
select name,sal from emp where sal = 800 or sal = 5000;
相当于
select name,sal from emp where sal in(800,5000);
//这不是表示800-5000的都找出来,而是表示只找800和5000的
- like 称为模糊查询,支持%或下划线匹配
%匹配任意多个字符,下划线匹配任意一个字符
select name fro emp where name like %o% //查出名字中带有o的员工名字
select name fro emp where name like %\_% //找出名字中带有下划线的名字,“\”为转义字符
1.2.3 排序
//查询所有员工薪资,排序,默认是升序
select name,sal from emp order by sal;
//查询所有员工薪资,降序,descend
select name,sal from emp order by sal desc;
//查询所有员工薪资,升序,ascend
select name,sal from emp order by sal asc;
//查询所有员工薪资,薪资一样时,才会考虑按照名字升序排
select name,sal from emp order by sal asc, name asc;
//了解:按照查询结果进行排序(根据字段的位置进行排序,开发中不建议这样写,不健壮)
select name,sal from emp order by 2;
//关键顺序不能变:
select
...
from
...
where
...
order by
...
以上语句的执行顺序必须掌握:
第一步: from
第二步: where
第三步: select
第四步: order by (排序总是在最后执行!)
1.2.4 数据处理函数(单行处理函数)
数据处理函数又称为单行处理函数
单行处理函数:一个输入对应一个输出
多行处理函数: 多个输入,对应一个输出
常见的单行处理函数:
| 函数 | 作用 |
|---|---|
| lower | 转换小写 |
| upper | 转换大写 |
| substr | 取子串(substr(被截取的字符串,起始下标,截取的长度)) |
| length | 取长度 |
| trim | 去空格 |
| str_to_date | 将字符串转换成日期,格式: str_to_date(‘字符串日期’,‘日期格式’) |
| data_format | 格式化日期(把日期转换成具有特定格式的字符串) |
| format | 设置千分位 |
| round | 四舍五入 |
| rand() | 生成随机数 |
| ifnull | 可以将null转换成一个具体值 |
| case…when…then…when…then…else…end |
SELECT LOWER(NAME) FROM CITY;
SELECT UPPER(NAME) FROM CITY;
SELECT UPPER(NAME) AS NAME1 FROM CITY;
SELECT SUBSTR(NAME, 1, 1) FROM CITY-- SUBSTR的起始下标从1开始,没有0
SELECT NAME FROM CITY WHERE SUBSTR(NAME, 1, 1) = 'A'-- 查询首字母是A的城市名
SELECT CONCAT(UPPER(SUBSTR(NAME,1,1)),SUBSTR(NAME,2,LENGTH(NAME)-1)) AS RESULT FROM CITY;-- 将name列的首字母大写
SELECT LENGTH(NAME) FROM CITY;
SELECT * FROM CITY WHERE NAME =' HERAT';-- 查不到数据
SELECT * FROM CITY WHERE NAME =TRIM(' HERAT ');
SELECT 'ABC' FROM CITY;-- SELECT后面直接跟“字面量/字面值”,会生成和该表的记录一样个数的ABC;
SELECT 'ABC' FROM CITY;-- 会生成和该表的记录一样个数的1000(因为1000是字面值);
mysql的日期格式: %Y 年, %m 月,%d 日, %h 时, %i 分, %s 秒
insert into t_user(id, name, birth) values(1,zhangsan, str_to _date('01-10-1990','%d-%m-%Y'));
-- str_to_date函数可以把字符串varchar转换成日期类型的数据。通常使用在插入insert语句中,因为插入的时候需要一个日期类型的数据,需要通过该函数将字符串转换成date。
insert into t_user(id, name, birth) values(1,zhangsan, '1990-10-11');
-- 注意:如果提供的日期字符串的格式为%Y-%m-%d,namestr_to_date函数就不需要了。
select id,name,birth from t_user;
-- 以上的SQL语句实际上是进行了默认的日期格式化,自动将date类型转换成varchar类型,并且采用mysql的默认日期格式:'%Y-%m-%d'
select id,name,date_format(birth,'%Y/%m/%d') as birth from t_user;
-- 该句是将日期格式化为想要的格式
SELECT ROUND(1234.567, 0) FROM CITY;-- 会生成和该表的记录一样个数的1235,括号里的0表示保留到整数位
SELECT ROUND(1234.567, -1) FROM CITY;-- 会生成和该表的记录一样个数的1230,括号里的-1表示保留到十位
SELECT ROUND(RAND()*100,0) FROM CITY;-- 生成和该表的记录一样个数的100以内的随机数
-- Note:SELECT后面可以跟某个表的字段名(可以理解为java中的变量名),也可以跟字面量/字面值(数据)
SELECT IFNULL(Population,0) FROM CITY;-- 如果人口为NULL,就把它当0
-- 注意,NULL只要参与运算,最终结果一定是NULL.为了避免这个现象,需要使用ifnull函数。ifnull函数用法:ifnull(数据,被当做哪个值),如果“数据”为NULL的时候,把这个当做哪个值 。
CASE...WHEN...THEN...WHEN...THEN...ELSE...END
SELECT NAME,JOB,SAL AS OLDSAL, (CASE JOB WHEN 'MANAGER' THEN SAL*1.1 WHEN 'SALESMAN' THEN SAL*) ELSE SAL END) AS NEWSAL FROM EMP;
-- 当员工的工作岗位是MANAGER的时候,工资上调%,当工作岗位是SALESMAN的时候,工资上调%,其他正常。(注意:不修改数据库,只是将查询结果显示为工资上调)
1.2.5 分组函数(多行处理函数)
多行处理函数: 输入多行,最终输出一行
注意:
- 分组函数在使用时必须先分组,然后才能用,如果没有对数据进行分组,整张表默认为一组
- 分组函数会自动忽略NULL,不需要提前对NULL进行处理
- 分组函数中COUNT(*)和COUNT(具体字段)的区别:
COUNT(*):统计表当中的记录的总行(只要有一行数据COUNT就++,而且表中不存在一行数据所有列都为空)
COUNT(具体字段):统计该字段下所有不为NULL的记录的总数
- 分组函数不能直接使用在where子句中
因为分组函数在使用的时候必须先分组再使用,WHERE在执行的时候还没有进行分组(SQL执行顺序:FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY),所以WHERE后面不能出现分组函数 - 所有分组函数可以组合起来一起使用
SELECT MAX(Population),Min(Population),AVG(Population),SUM(Population),COUNT(NAME) FROM CITY;
| 函数名 | 作用 |
|---|---|
| COUNT | 计数 |
| SUM | 求和 |
| AVG | 求平均值 |
| MAX | 最大值 |
| MIN | 最小值 |
SELECT MAX(Population) FROM CITY;-- 求人口的最大值
SELECT Min(Population) FROM CITY;-- 求人口的最小值
SELECT AVG(Population) FROM CITY; -- 求人口的平均值
SELECT SUM(Population) FROM CITY;-- 求人口的总和
SELECT COUNT(NAME) FROM CITY;-- 求城市的个数
1.2.5.1 分组查询(重要*****)
在实际应用中,可能有这样的需求,需要先进行分组,然后对每一组的数据进行操作,这个时候就需要使用分组查询
SELECT
...
FROM
...
WHERE
...
GROUP BY
...
ORDER BY
...
执行顺序: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
从某张表中查询数据
先经过WHERE条件筛选出有价值的数据。
对这些有价值的数据进行分组
分组之后可以使用HAVING继续筛选
Note:
- 在一条select语句中,如果有group by语句的话,select后面只能跟:参加分组的字段,分组函数。其他的一律不能跟(mysql中不会报错,但没有意义,别的语言如oracle中则会报错)
SELECT MAX(SAL),DEPT,JOB FROM EMP ORDER BY DEPT ,JOB;
找出每个部门不同工作岗位的最高薪资
- WHERE和HAVING,优先选择WHERE,WHERE实在完成不了,在选择having,因为where比having执行效率高。
SELECT DEPT,MAX(SAL) FROM EMP WHERE SAL > 3000 GROUP BY DEPT;-- 找出每个部门最大薪资,要求只显示最大薪资大于3000的
或
SELECT DEPT,MAX(SAL) FROM EMP GROUP BY DEPT HAVING MAX(SAL) > 3000;
SELECT DEPT,AVG(SAL) FROM EMP GROUP BY DEPT HAVING AVG(SAL) > 2500;-- 要求找出每个部门平均薪资大于2500的(此时无法使用WHERE)
1.2.6 去除重复记录
DISTINCT: 去除重复记录
SELECT DISTINCT NAME FROM CITY;
SELECT DISTINCT NAME, POPULATION FROM CITY;-- DISTINCT只能出现在所有字段的最前方
//DISTINCT在NAME, POPULATION 前面,表示两者联合去重
SELECT COUNT(DISTINCT NAME) FROM CITY;-- 统计城市的数量
1.2.7 连接查询
1.连接查询的分类
1.1 根据语法的年代分类:
SQL92: 1992年的时候出现的语法
SQL99: 1999年出现的语法
1.2 根据连接的方式分类:
-
内连接:
等值连接
非等值连接
自连接 -
外连接:
左外连接(左连接) 右外连接(右连接) -
全连接(基本不用)
- 当两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数是两张表条数的乘积,这种现象被称为:笛卡尔积现象。要避免笛卡尔积现象,就需要加条件。
SELECT
E.ENAME,D.DNAME
FROM
EMP E,DEPT D -- 表起别名很重要 效率问题
WHERE
E.DEPTNO = D.DEPTNO
//SQL92语法
-- 最终查询的结果虽然减少,但是匹配的过程中,匹配的次数并没有减少。
注意:通过笛卡尔积现象可以得出,表的连接次数越多,效率越低,我们应该尽量避免表的连接次数
1.2.7.1 内连接之等值连接
例:查询每个员工所在部门名称,显示员工名和部门名
SQL92语法:
SELECT
E.ENAME,D.DNAME
FROM
EMP E,DEPT D
WHERE
E.DEPTNO = D.DEPTNO
SQL92的缺点:表结构不清晰,表的连接条件和后期进一步筛选的条件都放在WHERE后面。
SQL99语法:
SELECT
E.ENAME,D.DNAME
FROM
EMP E
INNER JOIN -- INNER可以省略,带着INNER可读性更好,更容易看出来是内连接
DEPT D -- 表起别名很重要 效率问题
ON
E.DEPTNO = D.DEPTNO -- 条件是等量关系,所以被称为等值连接
SQL99优点:表连接的条件是独立的,连接后如果还需要进一步筛选,再往后继续添加where子句。
SQL99语法:
SELECT
...
FROM
A
JOIN
B
ON
A和B的连接条件
WHERE
筛选条件
1.2.7.2 内连接之非等值连接
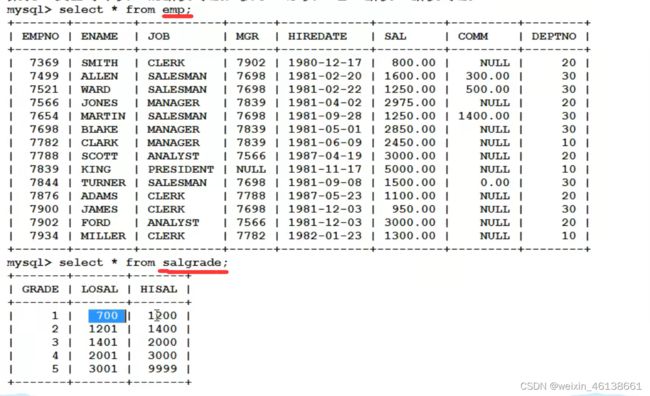
例:找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级
SELECT
E.ENAME, E.SAL , S.GRADE
FROM
EMP E
JOIN
SALGRADE S
ON
E.SAL BETWEEN S.LOSAL AND S.HISAL; -- 条件不是等量关系,称为非等值连接
1.2.7.3 内连接之自连接
自连接:自己连接自己
技巧:将一张表看成两张表
案例:查询员工的上级领导,要求显示员工名和对应的领导名。
查询结果为13条数据,因为KING的领导为NULL
SELECT
A.ENAME AS '员工名', B.ENAME AS '领导名'
FROM
EMP A
JOIN
EMP B
ON
A. MGR = B.EMPNO;
1.2.7.4 外连接
- right:表示将join关键字右边的这张表看成主表,主要是为了将这张表中的数据全部查出来,捎带这关联查询左边的表。 在外连接中,两张表连接,产生了主次关系。
- 带有right的是右外连接,又叫右连接;带有left的是左外连接,又叫左连接。
- 任何一个右连接都有对应的左连接的写法,任何一个左连接也有对应的右连接的写法。
- 外连接的查询结果条数一定 >= 内连接的查询结果条数
SELECT
E.ENAME , D.DNAME
FROM
EMP E
RIGHT OUTER JOIN -- OUTER是可以省略的,带着可读性更强
DEPT D
ON
E.DEPTNO = D.DEPTNO;
上面等价于:
SELECT
E.ENAME , D.DNAME
FROM
DEPT D
LEFT OUTER JOIN -- OUTER是可以省略的,带着可读性更强
EMP E
ON
E.DEPTNO = D.DEPTNO;
案例:查询每个员工的上级领导,要求显示所有员工的名字和领导名
SELECT
A.ENAME AS '员工名', B.ENAME AS '领导名'
FROM
EMP A
LEFT OUTER JOIN
EMP B
ON
A. MGR = B.EMPNO;
1.2.7.5 多表之间的连接
案例:找出每个员工的部门名称以及 工资等级,要求显示员工名、部门名、薪资、薪资等级

SELECT
E.ENAME AS '员工名', D.DNAME AS '部门名', E.SAL AS '薪资' , S.GRADE AS '薪资等级'
FROM
EMP E
JOIN
DEPT D
ON
E.DEPTNO = D.DEPTNO
JOIN
SALGRADE S
ON
E.SAL BETWEEN S.LOSAL AND S.HISAL;
1.2.8 子查询
子查询:select语句中嵌套select语句,被嵌套的select语句称为子查询。
子查询可以出现的位置:
SELECT
..SELECT.
FROM
..SELECT.
WHERE
..SELECT.
1.2.8.1 where子句中的子查询
案例:找出比最低工资高的员工姓名和工资
SELECT
ENAME,SAL
FROM
EMP
WHERE
SAL > (SELECT MIN(SAL) FROM EMP);
1.2.8.2 from子句中的子查询
注意:from后面的子查询,可以将子查询的查询结果当成一张临时表
案例:找出每个工作岗位的平均工资的薪资等级
SELECT A.JOB,S.GRADE
FROM
(SELECT JOB , AVG(SAL) FROM EMP E GROUP BY JOB) A
JOIN
SALGRADE S
ON
A.AVG(SAL) BETWEEN S.LOSAL AND HISAL;
执行失败:> 1630 - FUNCTION a.AVG does not exist. Check the 'Function Name Parsing and Resolution' section in the Reference Manual
//上面的执行失败是因为avg是关键字,没有起别名
正确的如下:
SELECT A.JOB,S.GRADE
FROM
(SELECT JOB , AVG(SAL) AS AVGSAL FROM EMP E GROUP BY JOB) A
JOIN
SALGRADE S
ON
A.AVGSAL BETWEEN S.LOSAL AND HISAL;
1.2.8.3 select子句中的子查询(了解即可)
案例:找出每个员工的部门名称,要求显示员工名、部门名
注意:对于select后面的子查询来说,这个子查询只能一次返回1条记录,多于一条,就报错了
SELECT
E.ENAME,E.DEPTNO,(SELECT D.DNAME FROM DEPT D WHERE E.DEPTNO = D.DEPTNO) AS DNAME
FROM
EMP E;
错误示例:
SELECT
E.ENAME,E.DEPTNO,(SELECT DNAME FROM DEPT ) AS DNAME
FROM
EMP E;
报错:
> Subquery returns more than 1 row
1.2.9 union可以合并集合
案例:查询工作岗位是MANAGER和SALEMAN的员工
注意:
- UNION在mysql中使用的时候要求两个结果的列数相同;在oracle中语法严格,要求不仅要列数相同,还需要列的数据类型也一样。
法一:
SELECT ENAME, JOB FROM EMP WHERE JOB IN('SALESMAN','MANAGER');
法二:
SELECT ENAME, JOB FROM EMP WHERE JOB = 'SALESMAN' OR JOB = 'MANAGER';
法三:
SELECT ENAME, JOB FROM EMP WHERE JOB = 'SALESMAN'
UNION
SELECT ENAME, JOB FROM EMP WHERE JOB = 'MANAGER';

1.2.9 limit可以将查询结果的一部分取出来
limit可以将查询结果的一部分取出来,通常使用在分页查询中(例如百度查询,默认一页显示10条记录)。分页的作用是为了提高用户体验,因为一次将全部数据查出来,用户体验差。
案例:查询工资最高的前五名
LIMIT完整用法: limit StartIndex, length (StartIndex是起始下标,从0开始, length是长度)
limit在order by之后执行
SELECT
ENAME, SAL
FROM
EMP
ORDER BY
SAL DESC
LIMIT 5; -- 起始下标省略的话,默认取前五,相当于LIMIT 0,5
1.2.10 分页
公式:
每页显示PageSize条记录
第PageNo页:limit (PageNo-1) * PageSize,PageSize