
一、背景
本次赛题思路源自于真实工作场景的一个线上项目,该项目在经过一系列优化后已稳定上线,在该项目开发的过程中数据平台组和技术负责人提供了许多资源和指导意见,而项目的结果也让我意识到了流计算在实际生产中优化的作用,进而加深了我对大数据应用的理解。
1.1 成员简介
陆冠兴:数据开发工程师,目前在互联网券商大数据部门工作,主要负责业务数据开发、数据平台建设、数据资产建设等相关工作,对流计算应用开发有一定经验。
1.2 内容概述
本次赛题的主要内容,是通过引入流计算引擎 Flink+消息队列 Kafka,使用 ETL 模式取代原有架构的 ELT 模式计算出用户的实时资产,解决原有架构下计算和读取压力大的问题,实现存算分离;并以计算结果进一步做为数据源构建实时资产走势等数据应用,体现了更多的数据价值。
1.3 一些概念
在股票交易系统中,用户需要先进行开户得到一个账户,该账户包含账户现金和账户持仓两部分,之后就可以通过该账户进行流水操作,同时也可进交易操作。
流水
- 出入金流水 = 往账户现金中存入/取出现金
- 出入货流水 = 往账户持仓中存入/取出股票
交易
- 买入股票 = 现金减少,股票持仓增加
- 卖出股票 = 现金增加,股票持仓减少
总资产的计算
- 用户总资产=账户现金+账户持仓股票市值
- 账户持仓股票市值 = 所持仓股票数量 * 对应的最新报价(实时变化)

1.4 传统架构的实现&痛点

当使用传统业务架构处理一个总资产的查询接口时,大致需要经过的步骤如下:
- 用户从客户端发起资产请求到后端
- 后端进程去业务 DB 里查询所有用户现金表、用户持仓股票表以及最新股票报价表数据
- 后端进程根据查询到的数据计算出用户持仓的市值,加上用户现金得到出用户最新总资产
- 将算出的总资产结果返回客户端展示
但随着请求量的增加,在该架构下数据库和计算性能都会很快达到瓶颈,主要原因是上面的第 2 步和第 3 步的计算流程较长并且未得到复用:
- 每次客户端的请求到来时,后端进程都需要向业务的 DB 发起多个查询请求去查询表,这个对于数据库是有一定压力
- 查询得到的数据库数据还需要计算才能得到结果,并且每来一个请求触发计算一次,这样的话 CPU 开销很大
二、技术方案
2.1 ETL 的架构&流计算

这里一个更合理的架构方案是使用 ETL 的架构对此做优化。
对于 ELT 架构,主要体现在 T(转换)的这个环节的顺序上,ELT 是最后再做转换,而 ETL 是先做转换它的优点是因为先做了转换,能够方便下游直接复用计算的结果。
那么回到总资产计算的这个例子,因为它的基本计算逻辑确定,而下游又有大量的查询需求,因此这个场景下适合把 T 前置,也就是采用 ETL 的架构。

在使用 ETL 架构的同时,这里选择了 Flink 作为流计算引擎,因为 Flink 能带来如下好处:
- 仅在对应上游数据源有变更时触发算出对应的计算,避免了像批计算每个批次都需要去拉取全量数据源的开销
- 由于是事件触发计算最新的结果,所以实时性会比批计算会好很多

那么新的架构实现可以大致如图,首先这里图中右边部分,通过引入 Flink 可先把计算的结果写到中间的数据仓库中;再把这个已算好数据提供给图中左边接口进行一个查询,并且因为数据仓库里面已经是算好的结果,所以接口几乎可以直接读取里面的数据无需再处理。
2.2 架构实现

实现这里主要分为三部分:数据接入、数据 ETL、提供数据。
2.2.1 数据接入
出于性能和 SQL 化的能力以及对 Flink 的兼容性考虑,这里主要使用的接入方案是 Flink CDC,整个 SQL 部分只需要确定数据源实例和库表的一些信息,以及要接入到的目标数据仓库信息,我们可在代码中 create 对应的 SQL,然后执行 insert 便可以完成整个接入。
一个从业务 MySQL 数据库接入数仓 Kafka 消息队列的 demo 代码如下:

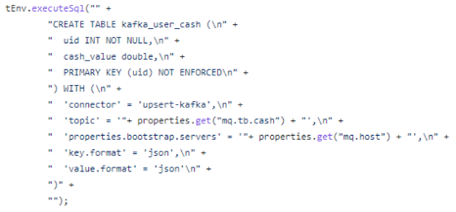

2.2.2 数据 ETL
在数据完成接入后,我们就可以开始业务逻辑,也就是用户总资产的计算了。
根据前面提到的计算公式,需要先对“账户持仓数据”和“股票报价数据”做一个关联,然后进行一次账户维度的聚合算出用户持仓市值,再和“账户现金数据”关联算出总资产,对应的 SQL 代码如下:


然而,在实际的运行中我们发现,数据的输出结果似乎很不稳定,变动频繁,输出的数据量很大,这里通过之前社区一些 Flink 的分享[1] 发现,这类实时流数据的 regular join 可能会有数据量放大和不准确的问题,原因是因为 Flink 有时会把上游的一条数据拆成两条数据(一条回撤,一条新值),然后再发给下游。
那在到我们总资产计算的这个场景中,可以看到在我们的 SQL,确实在关联之前和关联之后都会往下游输出数据;另外,再做聚合 SUM 的时候,上游的一个变化也可能触发两个不同的 SUM 结果;这些计算中间结果,都在不断地往下游输出,导致下游的数据量和数据的稳定性出现了一定的问题,因此这里要对这些回撤进行一个定的优化。

根据之前一些社区的分享经验来看,这里对应的一个解决方案是开启 mini-batch;原理上使用 mini-batch 是为了实现一个攒批,在同一个批次中把相同 KEY 的回撤数据做一个抵消,从而减少对下游的影响;所以这边里可以按照官方的文档做了对应的一个配置,那么数据量和稳定性的问题也就得到了初步的一个缓解。

2.2.3 提供数据
这部分的主要目的是将 ETL 计算好的结果进行保存,便于下游接口直接查询或者再做进一步的流计算使用,因此一般可以选择存储到数据库和消息队列中;

2.3 扩展数据应用
在完成基本数据模块的计算后,我们可以从数据的价值角度出发并探索更多可能,例如对已经接入的数据,可以再做一个二次的数据开发或挖掘,这样就可得到其它视角的数据,并进一步实现数据中台独特的价值。
以用户总资产为例,在我们在计算出用户总资产这个数据之后,我们可以再以此作为数据源,从而实现用户的实时总资产走势。

使用 Flink 自带的状态管理和算子的定时功能,我们可以大致按如下步骤进行实现:
- 接收上游不断更新的全量用户资产数据,并在 Flink 内部不断维护最新的用户资产截面
- 配置定时器,定期地扫描最新的用户资产截面,配上系统设定的时间戳,得到当前截面的资产快照数据
- 将当前截面的资产快照数据输出到下游的数据库或消息队列中

2.4 数据稳定性的挑战
在项目实际上线过程中,我们还遇到了一些引入流计算后带来的挑战,有时这些问题会对数据的准确性和稳定性造成一定影响,其中首当其冲的是 DB 事务给 CDC 带来的困扰,尤其是业务 DB 的一个大事务,会在短时间内对表的数据带来比较大的冲击。

如图,假如业务 DB 出现了一个交易的大事务,会同时修改现金表和持仓表的数据,但下游处理过程是分开并且解耦的,而且各自处理的过程也不一致,就有可能出现钱货数据变动不同步的情况,那么在此期间算出的总资产就是不准确的。
那么这里针对这种情况,我们也有一些应对方案:首先一个方案和前面处理回撤流的思路类似,是通过窗口进行攒批次的一个处理,尤其是 session 窗口比较适合这个场景。
例如下图中的代码,在计算出用户资产之后不是立刻输出结果,而是先做一个 session 窗口,把流之间最大可能延迟的变动包含进去,即把 session 窗口里面最新的结果作为一个比较稳定的结果作为输出;当然这里的 gap 不能太长,太长的话窗口可能会一直无法截断输出,需要根据实际情况选择合适的 gap 大小。

另一个方案的话可以是对此类大事务做一个识别,当上游触发一个很大的变动时,可以给 ETL 程序做一个提醒或预警感知,这样的话 ETL 程序就可以对输出数据做一个暂时的屏蔽,等到数据稳定之后再恢复输出。
再有的话就可以是提升性能和算力,假设处理数据的机器性能越强,那在同样时间数据被处理就越会更快,各流之间的延迟就越小。
三、总结

在这个场景中,我们通过引入 ETL 模式和 Flink 流计算引擎,实现了计算和存储的分离,将计算的负担从后端程序转移到了 Flink 流计算引擎上,方便的实现算力的动态扩缩容,还减少了对业务数据库读取的压力。除此之外,流计算出的实时结果还可以进一步给下游(用户实时走势)使用,实现了更多的数据应用价值。
参考:
[1] FFA2021 核心技术的分享 《Flink Join 算子优化》
扫码进入赛事官网了解更多信息:

更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算Flink版现开启活动:
99 元试用 实时计算Flink版(包年包月、10CU)即有机会获得 Flink 独家定制卫衣;另包 3 个月及以上还有 85 折优惠!
了解活动详情:https://www.aliyun.com/product/bigdata/sc
