第十周.02.LightGCN
文章目录
- NGCF回顾
-
- First-order Propagation
- high-order connectivity
- NGCF vs GNN
- LightGCN
-
- 摘要
- 3.1 LightGCN
- 3.2 Model Analysis
- 实验
本文内容整理自深度之眼《GNN核心能力培养计划》
公式输入请参考: 在线Latex公式
本周主要是讲解GNN简化模型,这个研究方向不是在模型的精度上进行提高,而是把精力放在模型的简化,使得模型精度在不大幅下降的前提下,计算更加简单,模型能处理更加大的数据集。
涉及到的模型有三个:SGCN、 FastGCN、 LightGCN
这节讲Light GCN
https://github.com/gusye1234/LightGCN-PyTorch
NGCF回顾
模型思想:
Organize historical interactions as a user-item bipartite graph. 将用户-商品关系表达为二部图。

Capture CF signal via high-order connectivity. 通过high-order connectivity获取协同过滤特征
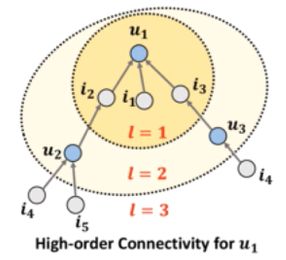
high-order connectivity定义:the paths that reach u 1 u_1 u1 from any node with the path length l l l larger than 1.
模型主要贡献:explicitly modeling high-order connectivity in representation space via GNN.
First-order Propagation
Message Construction:
由于是二部图,因此First-order Propagation肯定是从item传递到user的:
m u ← i = 1 ∣ N u ∣ ∣ N i ∣ ( W 1 e i + W 2 ( e i ⊙ e u ) ) m_{u\leftarrow i}=\cfrac{1}{\sqrt{|\mathcal{N}_u||\mathcal{N}_i|}}\left(W_1e_i+W_2(e_i\odot e_u)\right) mu←i=∣Nu∣∣Ni∣1(W1ei+W2(ei⊙eu))
这里的分数项相当于GNN里面度矩阵的0.5次方,括号里面的第一项要注意下标是 i i i不是 u u u,这里是代表一阶邻居 i i i,后面那项是邻居与当前节点的相似度,以此来决定消息传递的重要性(Pass more information to similar nodes)。
Message Aggregation:
update ego node’s(当前节点) representation by aggregating message from all neighbors.
e u ( 1 ) = LeakyReLU ( m u ← u + ∑ i ∈ N u m u ← i ) e_u^{(1)}=\text{LeakyReLU}\left(m_{u\leftarrow u}+\sum_{i\in \mathcal{N}_u }m_{u\leftarrow i}\right) eu(1)=LeakyReLU(mu←u+i∈Nu∑mu←i)
上面括号第一项是self loop,第二项是邻居消息
high-order connectivity
上面的第一层的消息传递和汇聚过程,如果考虑 l l l层:
e u ( l ) = LeakyReLU ( m u ← u ( l ) + ∑ i ∈ N u m u ← i ( l ) ) e_u^{(l)}=\text{LeakyReLU}\left(m_{u\leftarrow u}^{(l)}+\sum_{i\in \mathcal{N}_u }m_{u\leftarrow i}^{(l)}\right) eu(l)=LeakyReLU(mu←u(l)+i∈Nu∑mu←i(l))
这里需要注意,上面得到的是节点u在第 l l l层的表征,最终的节点表征是要将所有 l l l层的embedding进行concat得到结果。
NGCF vs GNN
Designs of NGCF are rather heavy and burdensome
·Many operations are directly inherited from GCN without justification.
| NGCF | GNN | |
|---|---|---|
| Original task | Collaborative filtering | Node classification |
| Input data(重点关注) | Only node ID ·One-hot encoding |
Rich node features ·Attributes,text,image data |
| Feature transformation | Generate ID embeddings | Distill useful information |
| Neighborhood aggregation | Pass messages from neighbors to the egos | Pass messages from neighbors to the egos |
| Nonlinear activation | Negatively increases the difficulty for model training | Enhance representation ability |
这个表对理解本节模型很有用,copy一段原文解释:
In semi-supervised
node classification, each node has rich semantic features as input, such as the title and abstract words of a paper. Thus performing multiple layers of nonlinear transformation is beneficial to feature learning. Nevertheless, in collaborative filtering, each node of user-item interaction graph only has an ID as input which has no concrete semantics. In this case, performing multiple nonlinear transformations will not contribute to learn better features; even worse, it may add the difficulties to train well. In the next subsection, we provide empirical evidence on this argument.
SGCN的回顾就不写了,大家自己看上节笔记
LightGCN
回顾NGCF是因为这个文章的模型就是在NGCF上进行实验观测,然后找出规律,然后弄出来的一个模型,对NGCF的实验本来有四个图,看一个就好:
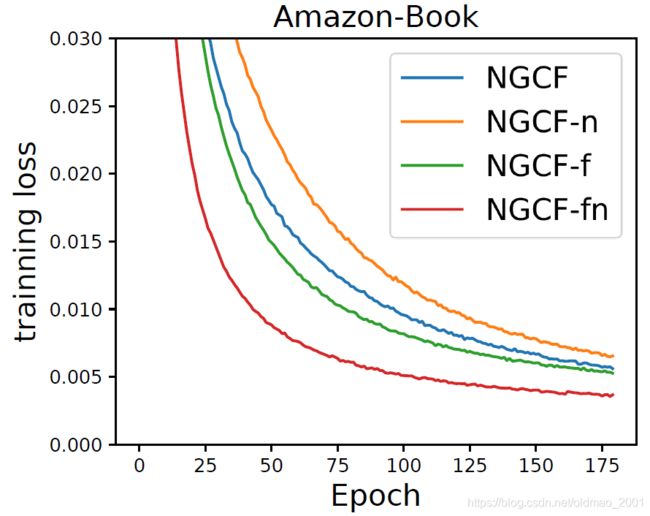
里面有四根线,蓝色线是NGCF原始算法。
• NGCF-f, which removes the feature transformation matrices W 1 W_1 W1 and W 2 W_2 W2.去掉特征变化
• NGCF-n, which removes the non-linear activation function σ σ σ. 去掉非线性变化
• NGCF-fn, which removes both the feature transformation matrices and non-linear activation function.两个都去掉。
上面的图可以明显看到把两个都去掉效果最好,去掉后就是我们今天要学的模型了。
总的来说,LightGCN阉割了三个东西:
Only simple weighted sum aggregator is remained
·No feature transformation:编号1
·No nonlinear activation:编号2
·No self connection:编号3就是去掉Propagation中的 W 1 W_1 W1 和 W 2 W_2 W2.
e u ( 1 ) = LeakyReLU 要 阉 割 编 号 2 ( m u ← u 要 阉 割 编 号 1 + ∑ i ∈ N u m u ← i ) e_u^{(1)}=\underset{要阉割编号2}{\text{LeakyReLU}}\left(\underset{要阉割编号1}{m_{u\leftarrow u}}+\sum_{i\in \mathcal{N}_u }m_{u\leftarrow i}\right) eu(1)=要阉割编号2LeakyReLU(要阉割编号1mu←u+i∈Nu∑mu←i)
原文的分析
Theoretically speaking, NGCF has higher representation power than NGCF-f, since setting the weight matrix W 1 W_1 W1 and W 2 W_2 W2 to identity matrix I I I can fully recover the NGCF-f model. However, in practice, NGCF demonstrates higher training loss and worse generalization performance than
NGCF-f.
原理其实就是复杂的模型表达能力虽然更加强悍,但是训练难度更大。
摘要
GCN在CF上取得SOTA
Graph Convolution Network (GCN) has become new state-of-the-art for collaborative filtering.
但是其在RS上取得成功的原因还木有人研究
Nevertheless, the reasons of its effectiveness for recommendation are not well understood.
缺少消融实验(类似于“控制变量法”。例如在模型中,使用了X,Y,Z三个模块取得了不错的效果,为了弄清楚是X,Y,Z中哪一个起的作用,可以保留X,Y移除Z进行实验,以此为依据观察Z在整个模型中的作用。)
Existing work that adapts GCN to recommendation lacks thorough ablation analyses on GCN, which is originally designed for graph classification tasks and equipped with many neural network operations.
作者使用消融实验得到了GCN的两个操作(特征编号和非线性激活)对于CF影响不大
However, we empirically find that the two most common designs in GCNs — feature transformation and nonlinear activation — contribute little to the performance of collaborative filtering.
甚至还会使得模型扑街
Even worse, including them adds to the difficulty of training and degrades recommendation performance.
先讲本文总体目标
In this work, we aim to simplify the design of GCN to make it more concise and appropriate for recommendation.
我们提出了
We propose a new model named LightGCN, including only the most essential component in GCN — neighborhood aggregation — for collaborative filtering.
尤其是
Specifically, LightGCN learns user and item embeddings by linearly propagating them on the user-item interaction graph, and uses the weighted sum of the embeddings learned at all layers as the final embedding.
实验巴拉巴拉SOTA巴拉巴拉
Such simple, linear, and neat model is much easier to implement and train, exhibiting substantial improvements (about 16.0% relative improvement on average) over Neural Graph Collaborative Filtering (NGCF) — a state-of-the-art GCN-based recommender model — under exactly the same experimental setting.
将来咋整,有源码
Further analyses are provided towards the rationality of the simple LightGCN from both analytical and empirical perspectives. Our implementations are available in both TensorFlow1 and PyTorch2.
3.1 LightGCN
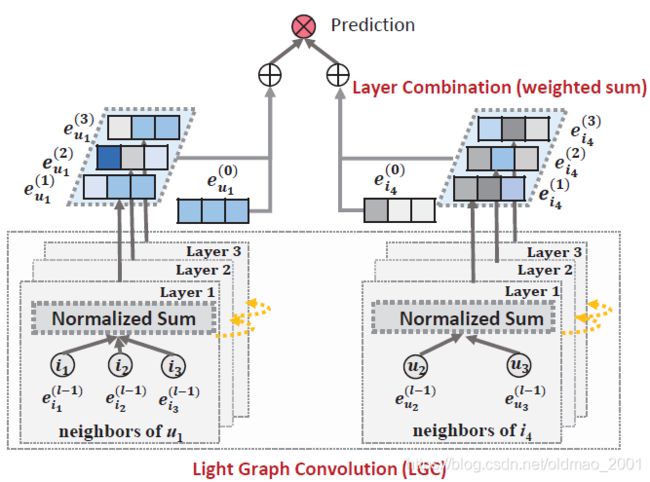
上图是LightGCN的结构,三去(去selfloop,去非线性激活,去特征变化),最后的特征是各层特征进行加权求和。这个操作非常重要,内含三层意义:
(1) With the increasing of the number of layers, the embeddings will be over-smoothed [27]. Thus simply using the last layer is problematic. 直接使用最后一层作为embedding,当GCN层数多了容易over-smooth
(2) The embeddings at different layers capture different semantics. E.g., the first layer enforces smoothness on users and items that have interactions, the second layer smooths users (items) that have overlap on interacted items (users), and higher-layers capture higher-order proximity [39]. Thus combining them will make the representation more comprehensive. 不同层的embedding包含的信息不一样,对于这里的RS任务,是二部图,因此第一层捕获的item信息,二层捕获的是user信息,聚合每一层能使得表达信息更加丰富
(3) Combining embeddings at different layers with weighted sum captures the effect of graph convolution with self-connections, an important trick in GCNs (proof sees Section 3.2.1).做这个操作是可以去掉selfloop的原因。
第k+1层节点u和i的embedding公式为:
e u ( k + 1 ) = ∑ i ∈ N u 1 N u N i e i ( k ) e_u^{(k+1)}=\sum_{i\in \mathcal{N}_u}\cfrac{1}{\sqrt{\mathcal{N}_u}\sqrt{\mathcal{N}_i}}e_i^{(k)} eu(k+1)=i∈Nu∑NuNi1ei(k)
e i ( k + 1 ) = ∑ u ∈ N i 1 N i N u e u ( k ) e_i^{(k+1)}=\sum_{u\in \mathcal{N}_i}\cfrac{1}{\sqrt{\mathcal{N}_i}\sqrt{\mathcal{N}_u}}e_u^{(k)} ei(k+1)=u∈Ni∑NiNu1eu(k)
公式里面的根号没有+1是去掉selfloop的表现。上面公式都是直接计算,没有参数需要训练的。
3.2 Model Analysis
这里LightGCN和SGCN的关系不写了,实际上就是证明了一下SGCN里面加了selfloop得到结果和LightGCN不加selfloop推导出来的结果是一样的,所以结论是LightGCN不加selfloop是阔以的。
这里面比较有意思的就是模型对于CF思想的对应关系分析:
c v → u = 1 ∣ N u ∣ ∣ N v ∣ ∑ i ∈ N u ∩ N v 1 N i c_{v\rightarrow u}=\cfrac{1}{|\sqrt{\mathcal{N}_u}||\sqrt{\mathcal{N}_v}|}\sum_{i\in \mathcal{N}_u\cap\mathcal{N}_v}\cfrac{1}{\mathcal{N}_i} cv→u=∣Nu∣∣Nv∣1i∈Nu∩Nv∑Ni1
用户v对于用户u的的影响系数由三个方面决定:
1、两个用户共同买过的商品的数量,越多关系越紧密;对应公式的求和项,越多求和的项目越多,c越大
2、共同买过的商品越小众(例如:只有张三和李四买过榴莲味的棒棒糖,这个商品没有别人买过,说明张三和李四都是榴莲味的棒棒糖的真爱粉,如果张三和李四买过Jay的专辑,那说明不了啥,因为喜欢Jay的人多的去了),二者关系越密切;购买商品的人对应公式 N i \mathcal{N}_i Ni,它越小说明买i这个商品的人越少, 1 N i \cfrac{1}{\mathcal{N}_i} Ni1就越大,,c越大
3、用户v的喜好越窄(例如:如果张三和李四买过Jay的专辑,虽然喜欢Jay的人多的去了,但是张三和李四只买过Jay的专辑,别的东西都没买过,说明张三和李四是Jay的真爱粉,和别人啥专辑都随便买的假粉不一样),二者关系越密切;这个对应公式的根号里面的东西,不解释了。
实验
数据集:
Gowalla,Yelp2018,Amazon-Book
评价指标:
recall@20,ndcg@20
ndcg看这里:https://www.cnblogs.com/by-dream/p/9403984.html
数据集切分:
随机取80%做训练集,20%做测试
最后对如何把所有层的embedding按什么方式进行求和留下悬念,未来工作。