深入学习MongoDB---1---入门篇+基础重点篇
MongoDB入门
- MongDB作为NoSQL数据库之一,主要关注:灵活性、扩展性、高可用
- 灵活性:NoSQL的特点就是反范式理论,为数据的水平扩展和字段的组织提供了巨大的便利
- 高可用:天生就伴随副本集(从节点)的概念,通过Raft算法实现集群的高可用;
- 扩展性:拥有分片机制,不需要应用程序或者插件就能实现数据分片和分片集群的搭建,只需要启动一个分片服务器、分片配置服务器、路由服务器即可自动进行分片和分片查询;
- MongoDB是最接近关系数据库的非关系型数据库,提供了关系数据库的众多核心功能,实现了其中众多核心概念:
- 索引机制
- 存储引擎和存储函数:WiredTiger存储引擎、js的存储函数;
- 事务机制:ACID和Base理论的结合
- 日志系统:慢查询、journal log(redo log)、oplog
- 类SQL的查询(甚至支持Lookup左连接查询)
基础
快速入门
数据结构
数据结构(逻辑)
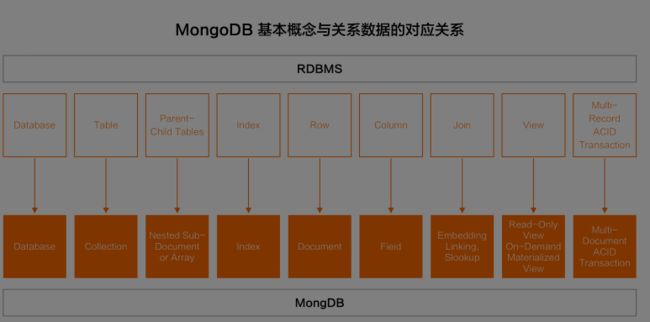
| SQL | MongoDB | 备注 |
|---|---|---|
| database | database | |
| table | collection | |
| row | document | |
| column | field | |
| primary key | primary key | 主键 |
| index | index | 索引 |
| view | view | 视图 |
- 支持视图、索引、事务、数据分片和分布式管理
- 通过命名空间进行操作,一般MongoDB有三层命名空间
- databse
- collection
- document
- 文档的id一般由**:时间戳、客户端ID、客户进程ID、三个字节的增量计数器**组成
- MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。
数据模型
-
前面学习NoSQl的时候已经介绍过,作为反范式,MongoDB可以灵活保存数据
- 可以没有任何文档结构(数据模型)约束
- 文档的属性也可以没有任何约束
-
文档校验:处于规范,很多时候我们需要对文档进行约束
- 校验器(validator):MongoDB通过校验器校验数据和文档格式是否合法
- 拒绝策略:
- error:报错
- warn:继续保存,但是发出警告
- 拒绝策略:
- 跳过校验:通过bypassDocumentValidation跳过校验
- 校验器(validator):MongoDB通过校验器校验数据和文档格式是否合法
校验器
required: 数据可以是任意类型,表示这个数据必须传入max: 用于Number 类型数据,最大值min: 用于Number 类型数据,最小值enum:枚举类型(数组中的类型是String),要求数据必须满足枚举值enum: [‘0’, ‘1’, ‘2’]match:增加的数据必须符合match(正则)的规则maxlength:数据必须是String类型,数据最大长度minlength:数据必须是String类型,数据最小长度bsonType:数据类型
validator: { #校验器
$jsonSchema: { #json数据格式约束
bsonType: "object", #类型
required: [ "name", "year", "major", "address" ], #必须的字段
properties: { #字段规则
name: {
bsonType: "string",
description: "must be a string and is required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
description: "must be an integer in [ 2017, 3017 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
description: "must be a double if the field exists"
},
address: {
bsonType: "object",
required: [ "city" ],
properties: {
street: {
bsonType: "string",
description: "must be a string if the field exists"
},
city: {
bsonType: "string",
"description": "must be a string and is required"
}
}
}
}
}
}
数据结构(物理)
- JSON格式存取
- BSON格式保存(BSON就是JSON的二进制形式,并且增强了JSON)
- 数据最终通过B-Tree的形式在文件系统中组织存储;
数据库基本操作
- options是操作可以携带的条件,同样是key-value形式
数据库操作
- 数据库增删改查
- 使用:use
- 增:在use的数据库中插入数据即可(如果没有该数据库则创建、有则插入数据)
- 删:db.dropDatabase()
- 删除use的数据库
- 查:show dbs
- 使用:use
- 用户
- 切换用户use usernam
- 登录:auth(“用户名”,“密码”)
- 创建用户:db.createUser
- 视图
- 索引
集合操作
- 增删改查
- 增:db.createCollection(name,options)
- 可选的options:
-

- 删:db.集合名.drop()
- 改:
- 查
- 查看该数据库全部集合:show collections()
- 查看某一个集合的状态:db.集合名称.stats()
- 增:db.createCollection(name,options)
文档操作(集合操作文档)
-
MongoDB通过BSON格式保存文档数据,BSON由一个到多个key-value键值对组成;
-
文档就像关系数据库的具体数据一样,操作是通过collection进行;
-
文档操作类似关系数据库,主要分为
- select子句:
- where子句
- limit子句
- group by子句
- order by子句
-
命令:
-
增删改:
db.<collectionName>.<操作>() -
查
db.<collectionName> .find( {query},#where子句 {fields}#select子句(一般指定查询的field字段) ) .group()#group子句 .sort()#order by子句 .limit().skip()#limit子句
-
增
-
insertOne
-
insertMany
-
insert
-
# db..insert({data},{options}) db.test1.insert({ "name":"www", "hhh":123 }) #db..insertMany([{data}……],{options}) db.test.insertMany( [ {"name":"lili","age":19}, {"name":"liyi","age":20}, {"name":"liuliu","age":21} ] )
删
-
有delete和remove俩种删除方法(推荐使用delete)
- deleteOne
- deleteMany
- remove
-
# db..remove( db.test1.remove({ {"tid":"test"},#query,相当于SQL的where {"justOne":true}#只删除一条记录 }) db.test1.insert( { item: "envelopes", qty : 100, type: "Clasp" }, { writeConcern: { w: "majority" , wtimeout: 5000 } } #开启写关注 ),{options})
改
-
改主要有两种手段:覆盖(save、replace)、查询修改(update)
- updateOne
- updateMany
- update
- save
- replaceOne
-
主要操作
- $set:修改
- $unset:删除字段
- $push:添加元素(一般用在数组)
- $inc:数值+x
-
#覆盖,save覆盖一般需要携带_id,来覆盖指定id的文档 # db..save(data,{options}) db.test1.save("_id":ObjectId("xxxxxxxxxx"),其他数据部分,{options}) #更新 # db..update( #update:$set、$inc等 db.test1.update({},{$set:{'title':'HHHH'},{options}}),
查
-
支持组合操作、支持批量操作
-
-
# db..find( db.test1.find({}) #查询所有 #查询名字为lili的age字段 SELECT age FROM test1 WHERE name = 'lili' db.test1.find({"name":"lili"},{"age":1}) db.test.find({$or: [{"age": {$gt:22}},{name:"www"}]}), )
query子句
-
即SQL的where子句,
- 支持聚合运算、
- 支持数值运算、条件运算(in、or、and、等于、大于、大于等于、小于、小于等于、不等于)、
- 正则表达式、
- 模糊查询、
- exists和not exists等
-
数值运算
-
“key”:{<运算符>:数值}
- 运算符:
- 大于:$gt
- 大于等于:$gte
- 小于:$lt
- 小于等于:$lte
- 不等于: $ne
- 运算符:
-
#score大于等于50分 { 'score':{$gte:50} } # 等于 { 'score':50 }
-
-
IN
-
$in
-
{ 'status': { $in: [ "A", "D" ] } }
-
-
条件运算
-
或:$or
-
#score大于90或者num小于80 { $or : [ {'score':{$gt:90}}, {'num':{$lt:80}} ] } #与操作 #score大于90并且num小于80 { 'score':{$gt:90}, 'num':{$lt:80} }
-
-
模糊查询和正则表达式
-
MongoDB支持正则表达式操作符$regex来做字符串模式匹配。
-
{ 'title': /^震惊/ #以震惊开头 }
-
内置函数
-
主要有:
- 事务相关
- snapshot
- readConcern
- readRef
- 统计相关
- explain:类似SQL的expail,用于分析
- count:统计数量
- 聚合相关
- limit和skip:SQL的limit
- sort:SQL的sort(
-1表示倒排,1表示顺序) - max和min
- 连接相关
- close
- maxTimeMS
- 其他
- pretty:提高可读性
- forEach、next、hashNext
- 事务相关
-
-
-

管道聚合框架
- 聚合框架(Aggregation Framework)是用于在一个或几个集合上进行的一系列运算从而得到期望的数据集的运算框架。主要有管道聚合、map-reduce、单一目的聚合;
- 下面主要介绍管道聚合
- 管道(PipeLine):管道是聚合框架对数据进行处理的过程,和操作系统的管道类似(单向、流、保存在内存中)
- 构件:筛选($filter)、投射($project)、 分组($group)、 排序($sort)、 限制($limit)和跳过($skip)、过滤($match )、连接运算($lookup)、展开、图搜索($graphLookup)、分面搜索($facet/$bucket )、运算的子运算等。
- 连接运算:只支持左外连接
- 子运算:
-
- 步骤(Stage):步骤是管道中数据流动的一系列操作,就是执行的构件;

#
db.<collectionName>.aggregate({stage},……)
#下面是管道的两步操作
db.test1.aggregate([
{
$match: { status: "A" }
}, #stage1
{
$group: {
_id: "$cust_id",
total: { $sum: "$amount" }
}
}#stage2
])
使用
- 下面主要基于SpringBoot整合MongoDB
SpringBoot-mongo基础
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
dependency>
mongodb:
host: localhost
port: 27017
database: 数据库名
username: XXX
password: xxx
authentication-database: 认证的权限
- 实体类:
@Document:标记实体类@MongoId:标记主键@Field:标记为属性(如果属性名和数据库不同需要指定)@Transient:标记属性不作为数据库的属性@DBRef:标记属性位一个document对象@Indexed:标记为该key设置索引@CompoundIndex:联合索引@CompoundIndexes:多个联合索引
- 通过MongoTemplate进行操作常用的类
- 查询:Query类
- 如果文件很大需要允许使用磁盘:query.allowDiskUse(true);
- 条件:BasicDBObject、Criteria
- Update:更新类(拼接数据)
- DeleteResult、UpdateResult:删除结果、更新结果
- 查询:Query类
例子
https://www.cnblogs.com/luoxiao1104/p/15145686.html
//实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@CompoundIndexes(
{
@CompoundIndex(def = "{name:1,clazz:1,age:-1}")//联合索引
}
)
@Document("test")
public class StudentEntity {
@MongoId
//@Indexed(unique = true,name = "_id"):默认主键就是唯一索引
private Long id;
private String name;
@Field("class")
@Indexed(name = "class_text")//普通索引
private String clazz;
private Integer age;
private String[] hobby;
private Date dateTime;
@Transient
private String other;
}
//使用
public void updateUser(){
//根据id查询数据
User user = mongoTemplate.findById("611a1cf8d5ba747098ff4625", User.class);
//设置修改的值
user.setName("lisi");
user.setAge(18);
//调用方法实现修改操作
Query query = new Query(Criteria.where("_id").is(user.getId()));
Update update = new Update();
update.set("name",user.getName());
update.set("age",user.getAge());
UpdateResult upsert = mongoTemplate.upsert(query, update, User.class);
long count = upsert.getModifiedCount();
System.out.println(count);
}
MongoDbTemplate
-
可选配置(主要涉及事务和分布式:事务处理机制、读写关注、ack机制、读依赖、写检查)
-
- 事务:sessionSyncronization
-
- 读写关注
- WriteConcern、ReadConcern
- 读依赖:ReadPreference
- ack机制:entityCallBack
- 写检查:WriteResultChecking,有严格检查(报异常)和不检查
-
-
使用
-
增:insert和save
-

-
//MongoTemplate studydb; //既可以通过集合也可以通过实体类插入 //以实体类为例子:实体类:StudentEntity,集合名:test4 studydb.insert(new StudentEntity(),"test");
-
-
改
-
修改:可以只改一个或者修改多个(First\Multi);可以是update(modify)或者replace
- update和modify:用于部分字段更新
- repalce:覆盖
-

-
-
//以只更新一个为例子 //Query:查询更新的文档;BasicUpdate:更新的内容;document更新的文档(key-value形式) //Class:更新文档参考字段名(即key的字段名),不指定则参考集合的字段名; //String:集合名 studydb.updateFirst(new Query(), new BasicUpdate(document),StudentEntity.class,"test"); studydb.findAndModify(new Query(), new Update(), new FindAndModifyOptions(), StudentEntity.class,"test"); //覆盖 studydb.findAndReplace(new Query(), new StudentEntity(), new FindAndReplaceOptions(),StudentEntity.class,"test");
-
-
删
-
删除:主要是删除多个或者删除一个;只有remove没有delete
-
-
//删除多个 studydb.remove(new Query(),StudentEntity.class,"test"); //删除一个 studydb.remove(new Query(),"test"); //删除多个 studydb.findAllAndRemove(new Query(),StudentEntity.class,"test"); //删除一个 studydb.findAndRemove(new Query(),StudentEntity.class,"test");
-
-
查
-


-
// studydb.find(new Query(),StudentEntity.class,"test"); //fieldName:去重的字段;List:结果集 studydb.findDistinct(new Query(),"fieldName","test",StudentEntity.class, List.class);
-
-
-
聚合函数
-
管道操作
-
agreegate:
-
-
//TypedAggregation:聚合操作 studydb.aggregate( TypedAggregation.newAggregation(Aggregation.match(Criteria.where("a").gt("11"))), "test", StudentEntity.class);
-

Criteria
-
用于创建查询的中心类。它遵循流畅的API风格,因此您可以轻松地将多个条件链接在一起。标准的静态导入。这种方法提高了可读性。
-
简单来说就是专门处理条件的类,一般通过静态方法直接创建;
-
包含前面提到的几乎所有查询:例如
-
//爱好必须为"睡觉", "吃饭",且顺序一致; //Criteria.where("hobby").all("睡觉", "吃饭").size(2);爱好是吃饭睡觉,顺序不要求 final Criteria hobby = Criteria.where("hobby").is(new String[]{"睡觉", "吃饭"}); final Criteria criteria = new Criteria();//用于组合条件 final Criteria age = new Criteria("age").lt(22).gt(5);//年龄6-21 final List<StudentEntity> studentEntities = mongoTemplate.find( new Query(criteria.andOperator(age,new Criteria().orOperator (hobby,Criteria.where("name").is("zhangsan3")))), StudentEntity.class, "test4");
-
Query
Aggregation
- SpringBoot提供了:Aggregation和TypeAggregation、AggregationUpdate处理聚合条件,
- TypeAggregation:对指定集合聚合,输出指定的实体类型
- Aggregation:通用的聚合类(另外两个都是其子类)
- AggregationUpdate:显然是用于update
重点
索引
- MongoDB能快速查找到主要原因是其强大的索引机制:
-

- 除了和关系数据库类似的:单字段索引、复合索引(同样有最左匹配原则)、hash索引、
- Hash索引(散列索引):散列索引是指按照某个字段的散列值来建立索引;
- 多键值索引(数组索引):主要是key对应的value是数组的情况
- 过期索引:会过期的索引,在索引过期之后,索引对应的数据会被删除
- 全文索引:MongoDB会自动对索引的Field的数据进行分词,极大加快查找速度(不支持中文分词)
- 地理空间索引:
- 2d索引:可以用来存储和查找平面上的点
- 2d sphere索引:可以用来存储和查找球面上的点。
文本搜索
-
文本搜索显然是MongoDB的亮点之一,
- 基于正则表达式的全文搜索:range
- 基于全文索引的$text
-
进行文本搜索,首先需要在文本搜索的Field建立索引
-
和ES类似,MongoDB的文本搜索也是一个赋分的制度,分值越高说明匹配度越高;
-
$$text、$search、score、$meta$:是核心关键字
-
#简单的搜索 db.<collectionName>.find({$text:{$search:"Jon"}}) #多关键词搜索,注意这种搜索是 or的关系,有index 或者 有 operator都可以,所以,这个搜索会出来 Jon Snow,Jon Bon Jovi, Don Jon 等好多名字,而且 Jon Snow还不一定能出现在第一个 db.<collectionName>.find({$text:{$search:"Jon Snow"}}) #有Jon 但是没有Don的 db.<collectionName>.find({$text:{$search:"Jon -Don"}}) #搜索包含Jon Snow的词组。用这个搜索,我发现就出不来了。 因为我们的库里面的词组是Jon Aegon Snow db.<collectionName>.find({$text:{$search:"\"Jon Snow\""}}) #加了下评分权重的排序。 db.<collectionName>.find( {$text:{$search:"Jon Snow"}}, {score:{$meta:"textScore"}} ).sort({score:{$meta:"textScore"}}) #使用两个短语,这就是一个逻辑上的AND关系,完美。假如你要使用mongodb 多个字符串匹配的查询,就用这个。不过,据说对中文分词不行。 db.<collectionName>.find({$text:{$search:"\"Jon\"\"Snow\""}})
-
视图
-
和关系数据库一样,MongoDB的视图也是为了方便对查找进行权限控制
-
MongoDB的视图支持:查找、统计、管道操作
-
#视图创建 db.createCollection() db.createView() #查找 db.collection.find() db.collection.findOne() #聚合操作 db.collection.aggregate() #统计操作 db.collection.countDocuments() db.collection.estimatedDocumentCount() db.collection.count() #去重 db.collectionName.distinct() #删除视图 db.collectionName.drop()
-
聚合
- 聚合操作处理数据记录和 return 计算结果。聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回单个结果。
- MongoDB 提供了三种执行聚合的方法:聚合管道,map-reduce function和单一目的聚合方法。
- 管道聚合:前面已经介绍过
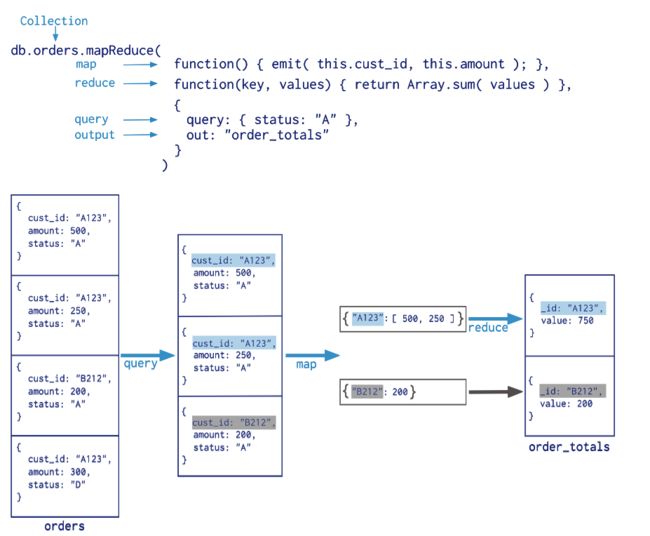
- 映射规约(map-reduce):映射规约是大数据处理的一种基本思想;
- Map-reduce 使用自定义 JavaScript 函数来执行 map 和 reduce操作,以及可选的 finalize 操作。
- map-reduce 操作有两个阶段:
- map 阶段:它处理每个文档并为每个输入文档发出一个或多个对象
- reduce阶段:将map操作的输出组合在一起
-
- 单一目的聚合
- MongoDB 还提供 db.collection.estimatedDocumentCount(), db.collection.count()和db.collection.distinct()进行简单的聚合操作(统计和去重)
-

事务

复杂的查询
数组和嵌套文档
数组
-
{ : { : , … } }
-
# fruits和aminal都是数组 db.test2.insertMany( [ {"name":"lili","age":19,"fruits":["apple","banana"],"aminal":["cat","dog"]}, …… ] ) # {: { db.test2.find( { fruits: ["apple", "banana"], aminal: { $all: ["cat", "dog"] } ) # fruits只包含两个元素"apple","banana"并且按顺序的数组 # $all:表示只要包含"cat"和"dog",不需要知道是否包含其他和顺序 #可以通过下标指定元素(下标由0开始); db.test2.find( { fruits.1: "apple"} ) #指定fruits第二个元素必须为apple # $elemMatch:对元素进行多条件查询 #数组中最少一个元素同时满足所有的查询条件。 db.test2.find( { age: { $elemMatch: { $gt: 22, $lt: 30 } } } ) #数组存在一个元素大于22且小于30 # $size:元素的个数 db.test2.find( { fruits: { $size: 3 } } ) #fruits有三个元素的文档: , ... } }
嵌套文档
- { : { : }, … }
- 和数组基本一致,不过嵌套文档嵌套的数据可以比较复杂;
- 需要子文档属性的顺序
- 对嵌套文档整体做等值匹配的时候,要求的是对指定文档的精确匹配,包含字段顺序。
- 可以像数组一样指定字段
- 例如``likes.amnimal`:指定为嵌套文档的amniamal字段
- 需要子文档属性的顺序
db.test2.insertMany(
[
{"name":"liyi","age":20,"likes":{{"fruits":["watermalon","banana"]},{"aminal":["panda","mouse"]}}},
……
]
)
#由于等值查询,必须对查询的fruits、aminal和likes保存的顺序一致
db.inventory.find( { likes: { fruits: [], aminal:[] } } )
#指定likes的fruilts的第二个元素
db.test2.find( { likes.fruits.1: "apple"} )
集合框架搜索
-
支持运算符
-
$match:滤波操作(相当于where)
-
$project:投影操作(相当于SELECT xxx)
-
$group: 相当于group by
-
$sort: 相当于order by
-
$limit和$skip: 相当于limit
-
$lookup: 左连接
-
$graphLookup:图连接
-
{ $lookup: { from: "xxx", #连接的外部表 localField: "xx", #外部表和本表连接的键 foreignField: "xx", #外键 as: ""#连接的外部表的属性的别名 } } { $graphLookup: { from: <collection>, startWith: <expression>, connectFromField: <string>, connectToField: <string>, as: <string>, maxDepth: <number>, depthField: <string>, restrictSearchWithMatch: <document> } }
-
-
$unwind:拆分数组
-
//原数据 { "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : [ { "name" : "呐喊", "publisher" : "花城出版社" }, { "name" : "彷徨", "publisher" : "南海出版出" } ] } //拆分 db.xxxxx.aggregate({$unwind:"$books"}) { "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : { "name" : "呐喊", "publisher" : "花城出版社" } } { "_id" : ObjectId("59f93c8b8523cfae4cf4ba86"), "name" : "鲁迅", "books" : { "name" : "彷徨", "publisher" : "南海出版出" } }
-
-
-
db..aggregate([{管道操作}])
文本查询(文本搜索)
-
视图不支持文本搜索。
-
前面已经介绍过使用(在有文本所有的field中)
- $test+$search:进行文本搜搜
- score+$meta:进行匹配度排序
-
聚合框架下的文本查询的限制
-
$text的$search必须在聚合的第一个Stage
-
只能有一次$search
-
如果需要按照分数排序需要在后面的Stage中进行(默认不会排序)
-
db.test.aggregate( [ { $match: { $text: { $search: "cake tea" } } }, #第一阶段进行search { $project: { title: 1, _id: 0, score: { $meta: "textScore" } } },#需要排序,必须自己排序 { $match: { score: { $gt: 1.0 } } } ] )
-
地理空间查询
- 待学习
集合
- MongoDB的集合类似MySQL的表(关系模型),类似redis的hash表,在MongoDB中,几乎一切数据都是通过集合组织起来的;
- 在MongoDB中集合有俩种类型:固定集合和动态分配集合,动态分配集合又可以分为:有约束和没有约束(即校验器校验)
- capped collection:固定集合,顾名思义,就是大小、存储文档数量固定的集合;在固定集合中:
- 循环覆盖:没有足够空间时,最老的文档会被删除以释放空间,新插入的文档会占据这块空间。
- 不能更改:无法将固定集合转换为非固定集合,也不能修改固定集合容量和可存最大文档数据
- 有序:自然顺序就是文档的插入顺序,可以指定由就到新或者相反;
- 动态分配集合:就是一般的集合,没有固定的大小,由hash节点的node记录相关信息;