spark词频统计
spark词频统计

**最开始进入spark文件目录bin下输入“./pyspark”,就进入python交互式命令行,如果出现下图,表示成功,会显示spark的图表和版本号,我的版本是3.1.2
**
第一步、在尖括号右侧写代码sc是一种抽象接口,在pyspark中我们可以直接调用,不必写sc。sc.textFile(“输入自身文件地址”)获取文件数据。
lines = sc.textFile("输入自身文件地址")
第二步、得到数据后就需要分割数据,这里是按照空格分隔
lambda是python中的匿名函数也叫做表达式
wordCount_1 = lines.flatMap(lambda line:line.split(" "))
第三步、数据按照空格分隔后,得到的是一个个的单词,现在需要把单词转换成KV类型的,方便下一步单词计数。
wordCount_2 = wordCount_1.map(lambda x:(x,1))
第四步、接下来,需要把数据聚合了,用到reduceByKey算子,按照key进行分组
wordCount_3 = wordCount_2.reduceByKey(lambda a,b:a+b)
#分组过程是两两合并,因为他们的key是相同的,只有它们的Value相加就会得到这个单词的总次数
第五步、所有计算工作都做好之后,可以使用collect方法查看完成的词频统计
print(wordCount_3.collect())
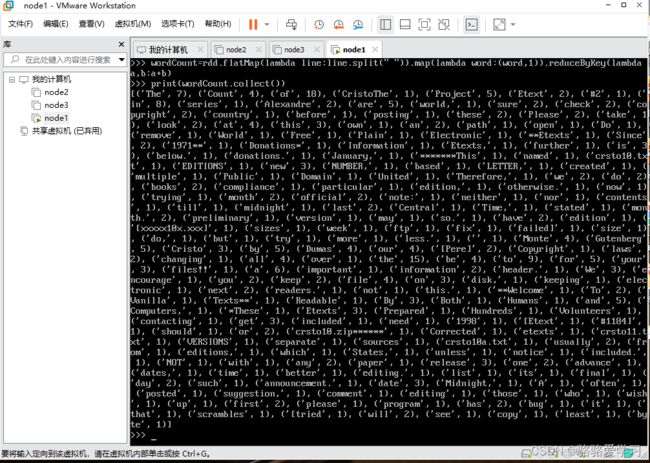
在此附上我的结果图,因为我的数据文件很大,单词很多,有点乱
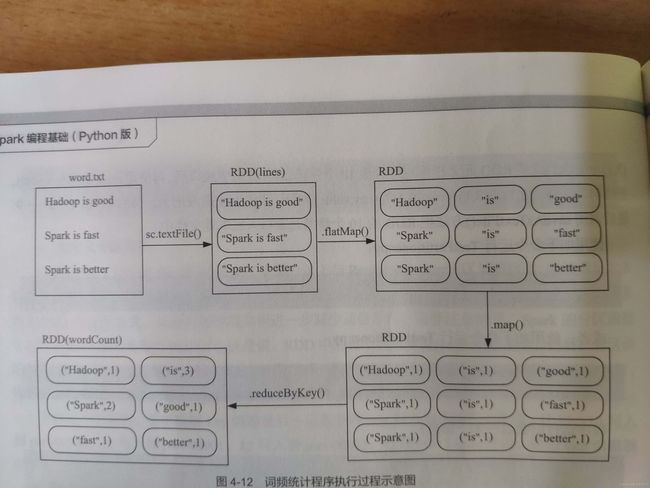
最后再附上课本中spark词频统计流程示意图,以便加深理解
到此spark 词频统计就结束了,这是最基本spark的入门实操,上图如有侵权,联系我删除
博客更新于2022.4.8日18点15分