zookeepr 简介
简介:
zookeeper是为分布式应用提供协调服务的高性能组件。zookeeper通过简单的接口暴露了一些公共服务(命名、配置管理、同步和分组服务), 因此你不需要从头开始写这些服务。你可以现成得使用zookeeper来实现共识、组管理、领导者选举和存在协议。你可以根据自己的特殊需求来构建它。
zookeepr是分布式、开源协调服务为分布式应用。zookeeper暴露了一些简单的原语。分布式应用通过原语实现更高层级的服务(命名、配置管理、同步和分组服务)。
zookeeper设计为易于编程、并仿照熟悉的文件系统目录树结构设计的数据模型。
ZooKeeper 背后的动机是减轻分布式应用程序从头开始实施协调服务的责任
设计目标:
简单:
zookeeper允许分布式进程通过类似于标准文件系统的共享分层namespace互相协调,namespace由 data registers 组成,按照zookeeper说法就是znodes 。znodes类似于文件或者目录,不同的是,znode被设计为可以存储。zookeeper数据保存在内存中,这意味着zookeeper可以轻易达到高吞吐和低延迟。
zookeeper非常重视高性能、高可用、严格的有序访问。zookeeper的高性能意味着可以用于大规模的分布式系统。zookeepr的可靠性保证不会成为单点故障。有序性意味着客户端可以复杂的一致性原语。
可复制-扩展:
就像它协调的分布式进程一样,ZooKeeper 本身旨在通过一组称为集成的主机进行复制。
正在上传…重新上传取消
构成 ZooKeeper 服务的服务器必须相互了解。它们在内存中维护状态图像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper 服务就可用。
客户端连接到单个 ZooKeeper 服务器。客户端维护一个 TCP 连接,通过它发送请求、获取响应、获取监视事件和发送心跳。如果与服务器的 TCP 连接中断,客户端将连接到另一台服务器。
有序性:
ZooKeeper用一个数字标记每个更新,这个数字反映了所有ZooKeeper事务的顺序,后续操作可以使用该顺序来实现更高级别的抽象,例如同步原语。
速度快:
它在“读主导”工作负载中特别快。ZooKeeper 应用程序在数千台机器上运行,它在读取比写入更常见的情况下表现最佳,比率约为 10:1。
场景:
概念:
namespace:
ZooKeeper 提供的namespace与标准文件系统的名称空间非常相似。名称是由斜杠 (/) 分隔的一系列路径元素。ZooKeeper 命名空间中的每个znode都由路径标识。
ZooKeeper 的分层namespace

znode:
Znodes 维护一个统计结构,其中包括数据更改的版本号、ACL 更改和时间戳,以允许缓存验证和协调更新。每次 znode 的数据更改时,版本号都会增加。
存储在命名空间中每个 znode 的数据是原子读取和写入的。读取获取与 znode 关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以做什么。
ZooKeeper 也有临时节点的概念。只要创建 znode 的会话处于活动状态,这些 znode 就会存在。当会话结束时,znode 将被删除。
ZooKeeper 旨在存储协调数据:状态信息、配置、位置信息等,因此每个节点存储的数据通常很小,在字节到千字节范围内
quorum:
A replicated group of servers in the same application is called a quorum,
watches
ZooKeeper 支持watches的概念。客户端可以在 znode 上设置监视。当 znode 更改时,将触发并删除 watch。触发监视时,客户端会收到一个数据包,说明 znode 已更改。如果客户端和其中一个 ZooKeeper 服务器之间的连接断开,客户端将收到本地通知。
3.6.0 中的新增功能:客户端还可以在 znode 上设置永久的递归监视,这些监视在触发时不会被删除,并且会递归地触发已注册 znode 以及任何子 znode 上的更改。
Guarantees:
ZooKeeper 非常快速且非常简单。但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证。这些都是:
- 顺序一致性——来自客户端的更新将按照它们发送的顺序应用。
- 原子性——更新要么成功要么失败。没有部分结果。
- 单一系统映像——无论连接到哪个服务器,客户端都将看到相同的服务视图。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。(全局数据试图)
- 可靠性——应用更新后,它将一直持续到客户端覆盖更新为止。
- 及时性——系统的客户视图保证在特定时间范围内是最新的。
-
tickTime:ZooKeeper 使用的基本时间单位,以毫秒为单位。它用于执行心跳,最小会话超时将是 tickTime 的两倍。
-
dataDir:存储内存数据库快照的位置,除非另有说明,否则存储更新数据库的事务日志。
-
clientPort:侦听客户端连接的端口
Simple API:
ZooKeeper 的设计目标之一是提供一个非常简单的编程接口。因此,它仅支持这些操作:
-
create:在树中的某个位置创建一个节点
-
delete : 删除一个节点
-
exists : 测试节点是否存在于某个位置
-
get data:从节点读取数据
-
set data:将数据写入节点
-
get children:检索节点的子节点列表
-
sync:等待数据传播
实现流程:
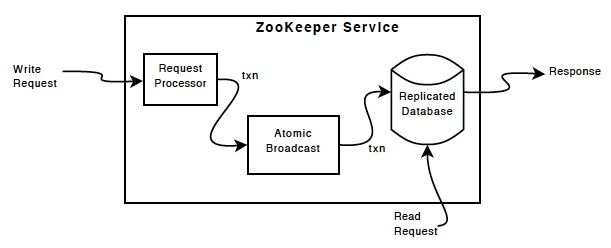
复制数据库是包含整个数据树的内存数据库。更新被记录到磁盘以实现可恢复性,写入在应用于内存数据库之前被序列化到磁盘。
每个 ZooKeeper 服务器都为客户端服务。客户端仅连接到一台服务器以提交请求。读取请求由每个服务器数据库的本地副本提供服务。更改服务状态的请求,写入请求,由协议协议处理。
作为协议的一部分,来自客户端的所有写请求都被转发到一个称为leader的服务器。其余的 ZooKeeper 服务器,称为followers,从领导者那里接收消息提议并就消息传递达成一致。消息传递层负责在失败时更换领导者并将追随者与领导者同步。
ZooKeeper 使用自定义原子消息传递协议。由于消息传递层是原子的,ZooKeeper 可以保证本地副本永远不会发散。当领导者收到写请求时,它会计算要应用写时系统的状态,并将其转换为捕获此新状态的事务。
数据模型:
zookeeper 使用分层的namespace,namespace中的每个node都会关联data和children。任何unicode字符都可以在受以下约束的路径中使用,因此是二进制安全的。
znodes:
zookeeper namespace 结构中的每个节点叫做znode。znode维护着一个状态结构,保存着数据改变的版本、acl changes、timestamp、version nubmber。允许ZooKeeper验证缓存并协调更新。每次znode的数据更改时,版本号都会增加。当客户端执行更新或删除操作时,它必须提供它正在更改的znode的数据版本。如果它提供的版本与数据的实际版本不匹配,则更新将失败
在分布式应用程序工程中,节点一词可以指通用主机、服务器、集合的成员、客户端进程等。在ZooKeeper文档中,znodes表示数据节点。服务器是指组成ZooKeeper服务的机器;Quorum对等体指的是组成集合的服务器;client指所有使用ZooKeeper服务的主机或进程。Znodes是程序员访问的主要实体。它们有几个值得一提的特点。
watches:
client可以在znodes上设置watches。znode上的改变会触发watch并且清除watch。当watch触发,zookeeper将发送client一个notification。
data access
每个znode的数据读写都是原子的。每个znode都有一个acl来限制谁来做什么!zookeeper不被设计为传统数据库或者大数据存储。相反,zookeeper管理协调数据。这些数据可以是 配置、状态、集合。ZooKeeper客户端和服务器实现进行了完整性检查,以确保znode的数据小于1M,但数据应该远远小于平均数据。对相对较大的数据进行操作会导致某些操作比其他操作花费更多时间,并且会影响某些操作的延迟,因为将更多数据通过网络移动到存储介质上需要额外的时间。
ephemeral nodes:
ZooKeeper也有临时节点的概念。只要创建znode的会话处于活动状态,这些znode就存在。当会话结束时,znode被删除。由于这种行为,ephemeral znode不允许有子节点。会话的ephemeral nodes列表可以使用getEphemerals() api检索。
sequence nodes:
当创建一个znode时,你也可以要求ZooKeeper在路径的末尾添加一个单调递增的计数器
container nodes:
Added in 3.6.0
zookeeper有container nodes的概念,主要用来服务leader、lock等,当container nodes节点的最后一个child删除后,container nodes变成一个候选人,会被server在未来的某一时刻将被删除。
TTL nodes:
Added in 3.6.0
如果节点在ttl内内有被修改且没有字节点 childern的话会变成一个候选人,会被server在未来的某一时刻将被删除。
Time in zookeeper:
zookeeper通过各种方式追踪时间:
Zxid:ZooKeeper Transaction Id。
对ZooKeeper状态的每一次更改都会以zxid (ZooKeeper事务Id)的形式接收一个戳。这将向ZooKeeper公开所有更改的总顺序。每个变化都有一个唯一的zxid,如果zxid1小于zxid2,那么zxid1发生在zxid2之前。
Version numbers:
对节点的每次更改都将导致该节点的一个版本号增加。这三个版本号分别是version(对znode的数据进行更改的次数)、cversion(对znode的子节点进行更改的次数)和averse(对znode的ACL进行更改的次数)。
Ticks:
When using multi-server ZooKeeper, servers use ticks to define timing of events such as status uploads, session timeouts, connection timeouts between peers, etc. The tick time is only indirectly exposed through the minimum session timeout (2 times the tick time); if a client requests a session timeout less than the minimum session timeout, the server will tell the client that the session timeout is actually the minimum session timeout.
Real time:
ZooKeeper doesn't use real time, or clock time, at all except to put timestamps into the stat structure on znode creation and znode modification.
zookeeper stat structure:
The Stat structure for each znode in ZooKeeper is made up of the following fields:
- czxid The zxid of the change that caused this znode to be created.
- mzxid The zxid of the change that last modified this znode.
- pzxid The zxid of the change that last modified children of this znode.
- ctime The time in milliseconds from epoch when this znode was created.
- mtime The time in milliseconds from epoch when this znode was last modified.
- version The number of changes to the data of this znode.
- cversion The number of changes to the children of this znode.
- aversion The number of changes to the ACL of this znode.
- ephemeralOwner The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero.
- dataLength The length of the data field of this znode.
- numChildren The number of children of this znode.
ZooKeeper Sessions:
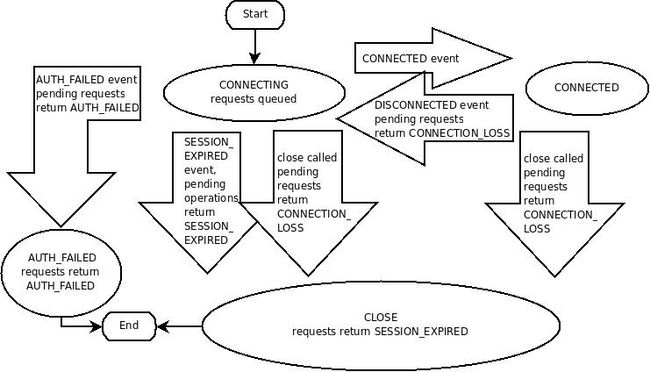
zookeeper watches
- Semantics of Watches
- Persistent, Recursive Watches
- remove watches
- what zookeeper guarantees about watches
- things to remember about watches
zookeeper access control using ACLs
-
Consistency Guarantees
-
ZooKeeper Operations