刷LeetCode的SQL题库全记录【Medium篇】
Outline
- 534. Game Play Analysis III
非常希望如果有B- tree觉得至今为止在LeetCode的SQL练习中表现的不咋地的,有必要去看看Advanced的SQL语句的handbook。目前我是停下来看了两遍,因为上周被数据仓库教授的SQL语句逻辑秀瞎了,所以觉得只有从底层清楚这些东西才有熟练和进步的可能。我暂时没有比较出来哪个好用,但是先贴一个还算全的:
SQL Quick Guide
534. Game Play Analysis III

Solution:
主要核心是用到OVER,其支持基于GROUP的聚合值。
SELECT player_id, event_date,
sum(games_played) OVER (partition by player_id order by event_date) AS games_played_so_far
FROM Activity
ORDER BY player_id, event_date ASC
550. Game Play Analysis IV

不禁感叹刷题最重要的还是思路啊。无非就几种选择——JOIN表,依赖划分。。。
这题一看就应该想到这start date应该可以和event_date并排一起放,设置规则以后LEFT JOIN不满足要求的直接就过滤掉了。
SOLUTION:
SELECT round(count(a2.player_id) / count(a1.player_id), 2) As fraction
FROM(
SELECT player_id, min(event_date) AS start_date
FROM Activity
GROUP BY player_id) AS a1
LEFT JOIN(
SELECT player_id, event_date
FROM Activity
) AS a2
ON a1.player_id = a2.player_id AND event_date = start_date + 1
570. Managers with at Least 5 Direct Reports

SOLUTION:
我的逻辑最开始想到的是JOIN的写法。刚开始用的是LEFT JOIN,结果一个测试样例结果应为[[ ]],我的跑出来是[[null]]。后面突然想到LEFT JOIN的属性就是就算为null的匹配也要强行怼上去填个null。刚好可以用JOIN,就改成如下,通过。
SELECT name
FROM(
SELECT managerId
FROM Employee
GROUP BY managerId
HAVING count(*) >= 5 ) AS e1
JOIN Employee e ON e1.managerId = e.id
考虑到其实在同一张表里面去限制ID也是绝对可行的,稍微改改(但是其实runtime是增加了的),无JOIN写法如下:
SELECT name
FROM Employee
WHERE id IN(
SELECT managerId
FROM Employee
GROUP BY managerId
HAVING count(*) >= 5
)
580. Count Student Number in Departments
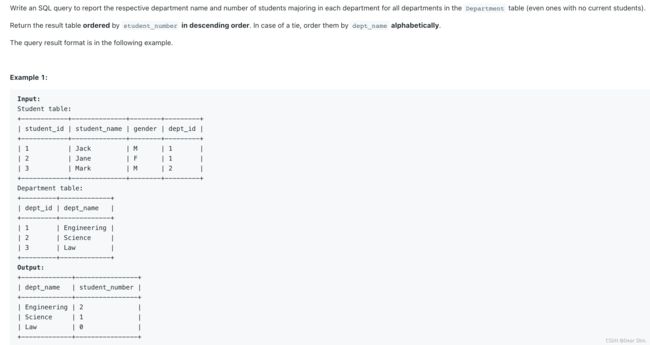
SOLUTION:
一点都不复杂,就是JOIN的问题,因为两个表链接起来才能获得所有的信息。但是我一开始遇到了很短暂的报错(菜),就是在为0的Architecture显示的基础上为0的Art没有出现在表中。因为我原来GROUP BY里面写的是s.dept_id,如果按照Student来GROUP BY的话,会出现部门缺失着实是见怪不怪。
SELECT d.dept_name, count(s.dept_id) AS student_number
FROM Student s RIGHT JOIN Department d ON s.dept_id = d.dept_id
GROUP BY d.dept_name # 也可写成 GROUP BY 1
ORDER BY student_number DESC # 也可写成 ORDER BY 2 DESC
608. Tree Node

这题我喜欢!一方面是正式用到了CASE,让我好歹有了点在coding的感觉。第二,我从来没有注意过IS NULLh和='null’的区别在这里直接彰显出来了。
当我第二行IS NULL写为=‘null’的时候,报错如下:

可见这 = null在这里就匹配不出来东西。参考:数据库查询—is null与= null的区别
讲了一大堆提出上面作者的一句话重点:
null 表示什么也不是, 不能=、>、< … 所有的判断,结果都是false,所有只能用 is null进行判断。
SOLUTION:
思路见注释
SELECT id,
CASE WHEN p_id IS NULL THEN 'Root'
WHEN id IN (SELECT p_id FROM Tree) THEN 'Inner' ELSE 'Leaf' END
AS type
FROM Tree
ORDER BY id ASC
1045. Customers Who Bought All Products

SOLUTION:
这个题到最后一行对我来说全靠瞎写,特别是基础不够扎实的话。但是摸爬滚打只要把意思表示对了,能搞出来正确答案以后印象就深了(我之前是不知道HAVING里面还能加个括号去重新SELECT)。
不过这道题明显重点也不在这,主要在思路和切入点要对。这题切入点就是Product表里面的数量等于GROUP BY以后的Customer表对应的商品的不重复数量。
SELECT customer_id
FROM Customer
GROUP BY customer_id
HAVING count(DISTINCT product_key) = (SELECT count(product_key) FROM Product)
1077. Project Employees III

SOLUTION:
思路:啥都不想先JOIN起来。因为考虑到排序的问题就自然而然想到几大排序函数,考虑row_number()和rank()。 还记得吧,前者是不重复的,后者是重复的。想不起来的再看一遍:任意一篇讲几个函数区别和示例的文章
SELECT project_id, wholeTable.employee_id
FROM(
SELECT project_id, p.employee_id,
rank() OVER (partition by project_id ORDER BY experience_years DESC) AS rn
FROM Project p JOIN Employee e ON p.employee_id = e.employee_id
) AS wholeTable
WHERE wholeTable.rn = 1
1098. Unpopular Books
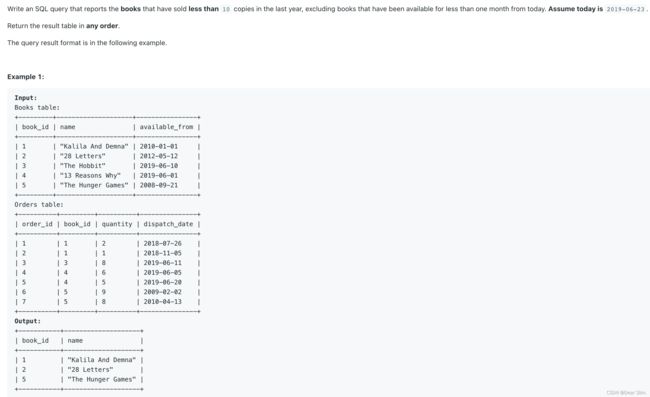
SOLUTION:
非常不好意思,是一个很垃圾的算法,至少时间复杂度是高的惊人的。但是我觉得思路是清晰的。
# 先找出来卖出10本以上的 -> 剔除
# 再找在售一个月以内的 -> 剔除
# 从Books里面减掉这俩筛选结果
SELECT c.book_id, c.name
FROM(
# 全集
SELECT *
FROM Books
) c
LEFT JOIN(
# 规定时间内卖出了10本以上的
SELECT b.book_id, b.name
FROM Books b JOIN Orders o ON b.book_id = o.book_id
WHERE dispatch_date > '2018-06-23'
GROUP BY 1
HAVING sum(quantity)>=10
) ten ON c.book_id = ten.book_id
LEFT JOIN(
# 发售晚不算数
SELECT book_id, name
FROM Books
WHERE available_from >= '2019-05-23'
) late ON late.book_id = c.book_id
WHERE late.book_id IS null and ten.book_id IS null
其实最后一个发售晚完全没有必要JOIN,因为他和c表的来源与基本结构是一样的。可以改写为:
SELECT c.book_id, c.name
FROM(
# 全集
SELECT *
FROM Books
) c
LEFT JOIN(
# 规定时间内卖出了10本以上的
SELECT b.book_id, b.name
FROM Books b JOIN Orders o ON b.book_id = o.book_id
WHERE dispatch_date > '2018-06-23'
GROUP BY 1
HAVING sum(quantity)>=10
) ten ON c.book_id = ten.book_id
WHERE ten.book_id IS null and c.available_from < '2019-05-23'
好吧,提升了4%(狗头)。
1112. Highest Grade For Each Student

SOLUTION:
SELECT student_id, course_id, grade
FROM (
SELECT *, row_number() OVER(partition by student_id ORDER BY grade DESC, course_id) AS rn
FROM Enrollments) t
WHERE t.rn = 1
ORDER BY student_id
1126. Active Businesses <可以看看逻辑>

SOLUTION:
两个主要需求:
1 - event_type对应的occurrence要高于这个business的平均
2 - 这个business里面要有一条以上符合条件1的
WITH eventView AS(
SELECT *, avg(occurences) AS average
FROM Events
GROUP BY event_type
)
SELECT Events.business_id
FROM Events JOIN eventView ON Events.event_type = eventView.event_type
WHERE eventView.average < Events.occurences # 1
GROUP BY Events.business_id # 限制条件1
HAVING count(*) > 1 # 2
1164. Product Price at a Given Date

SOLUTION:
高兴高兴! 学到新东西了:COALESCE()函数
WITH ranked AS(
SELECT product_id, new_price AS price, change_date,
row_number() OVER (partition by product_id ORDER BY change_date DESC) AS rn
FROM Products
WHERE change_date <= '2019-08-16'
) ,
template AS(
SELECT DISTINCT product_id
FROM Products
)
SELECT template.product_id,COALESCE(e1.price, 10) AS price
FROM (SELECT product_id, price
FROM ranked
WHERE rn = 1) AS e1
RIGHT JOIN template ON template.product_id = e1.product_id
思路就是,一个表去把8-16之前的更新整出来并加上一排序的列,另一个表是所有的product_id用于后面JOIN去补充默认值10。两个表的合并就是JOIN的问题。COALESCE的作用就是类似CASE WHEN的简化版。
<复习阶段>
在此基础上高频的SQL70精选已经差不多做了一遍了,开始正经做!
176. Second Highest Salary
这题我一直想不出来为什么用MAX(),后面搞明白了是因为如果rn=2找不到就会直接返回[ ],而我们想要null,所以当使用Max()的时候可以按照题目要求返回一个null。
WITH ranked AS(
SELECT *, rank() OVER(ORDER BY salary DESC) rn
FROM Employee
)
SELECT max(CASE WHEN rn = 2 THEN salary ELSE null END) AS SecondHighestSalary
FROM ranked
WHERE rn = 2
177. Nth Highest Salary
随之而来一道很类似的,但是直接套进去发现上面的用不了了。很快定位问题一定出现在rank()上。他们三个到底用哪个?再来一遍总结!
row_number: 不管排名是否有相同的,都按照顺序1,2,3……n
rank: 排名相同的名次一样,同一排名有几个,后面排名就会跳过几次
dense_rank: 排名相同的名次一样,且后面名次不跳跃
首先我们肯定不希望出现1,1,3这种直接把2跳没了的情况,所以rank就不用了;row_number的话会把同样的工资分配不同的序号,其实如果只考虑salary视角是不正确的。所以就选dense_rank。
570. Managers with at Least 5 Direct Reports
理清思路,不要搞太复杂。归根结底就是在数ManagerId的重复个数,然后把经理的个人信息JOIN一下对应到右边可以直接提取就OK了。但是我又遇到一个和1164相反的小问题——有个样例结果是[ ], 但我输出[null]。诊断起来,其实是因为我原来写的是LEFT JOIN,其定义应该是就算左边对应右边为空,也要硬着头皮写个null上去。但是如果我们改成JOIN,如果在ID里面没有出现,那后面根本别提可以匹配上了,也不会出现null。

两道都是有创意的好题:
612. Shortest Distance in a Plane
我很想让他们错位JOIN,但是如果没有任何ID的话很难办,并且意识到错位JOIN是没办法满足所有对匹配的。所以直接模糊的在WHERE里面把条件限定好就成。
SELECT round(min(sqrt(power(a.x-b.x, 2) + power(a.y-b.y, 2))),2) AS 'shortest'
from Point2D a, Point2D b
where (a.x, a.y) < (b.x, b.y)
626. Exchange Seats
这道题有点coding的时候写ifelse的内味了。虽然不是什么fast解法,但是思路能够搬移过来还是很让人开心的。
SELECT s1.id, s2.student
FROM Seat s1, Seat s2
WHERE if(s1.id%2=1, s1.id + 1 = s2.id or if((select max(id) from Seat) = s1.id, s2.id = s1.id,null), s1.id - 1 = s2.id)
ORDER BY s1.id
627. Swap Salary
不是单纯的语句,是update的语句。
第一次见这种题型所以也po一下:
UPDATE Salary SET sex = IF(sex = 'm', 'f', 'm');
550. Game Play Analysis IV
遇到第二道OVER用在别的函数上面的题,通过这个例子希望可以加深你对OVER使用方法的理解:
SELECT player_id, event_date, sum(games_played) over (partition by player_id order by event_date) AS games_played_so_far
FROM Activity
1853. Convert Date Format
可以参考链接:MySQL DATE_FORMAT() 函数
SELECT date_format(day, '%W, %M %e, %Y') as day
FROM days
1875. Group Employees of the Same Salary
这道题让我明白一个细节——拿一行出来说:SELECT *, count(salary) over (partition by salary) as ct FROM Employees
我是想加个一个列列出来每个salary在表中全局重复的次数。
如果我写成
SELECT *, count(salary) as ct FROM Employees GROUP BY salary, 我得到的结果会只有3行:工资为3000、7400, 6100的各一行。
本题中这种写法,就会把所有的employee行列出来。
所以GROUP BY和partition by的区别是:
GROUP BY是针对表全局的去分组,并且显示出分组
partition by是在变量内部计算过程中利用分组,但是不用显示出来分组。
SELECT employee_id, name, salary, DENSE_RANK() over (order by salary) AS team_id
FROM (SELECT *, count(salary) over (partition by salary) as ct FROM Employees) t
WHERE t.ct >= 2
ORDER BY 4, 1
1939. Users That Actively Request Confirmation Messages
涉及时间的题目经常触碰到我的知识盲区,但是又特别令人兴奋!两个知识点:lag()和时间窗口的表达
SELECT DISTINCT
user_id
FROM
(SELECT user_id, (time_stamp - LAG(time_stamp) OVER (PARTITION BY user_id ORDER BY time_stamp)) AS diff
FROM Confirmations) t
WHERE
diff <= 1000000
这里我们在内部将行排序以后,Lead()就是取当前顺序的下一条记录,相对Lag()就是取当前顺序的上一行记录。这里选LAG是因为内部升序排序,然后time_stamp只有减前面一条记录才能顺利计算窗口。
这里的diff <= 1000000也很神奇——解释如下

还有一种解法大致相同,就是不直接比diff <= 1000000,而是调用DATEDIFF()函数:
SELECT
distinct user_id
FROM
(SELECT user_id,
time_stamp AS T1,
LAG(time_stamp) OVER(PARTITION BY user_id ORDER BY time_stamp) AS T2
FROM Confirmations
) as c
WHERE DATEDIFF(second,T2,T1) BETWEEN 0 and 86400
1949. Strong Friendship
看完题目就感觉很兴奋,这是一道很有逻辑的题目。
1)首先,因为所有的friend组合都放在第一列和第二列,所以单凭原来那个表不能呈现所有可筛选的组合:我们要做的第一件事就是把组合放在第一列列出来。很明显先用UNION。
2)其次,我们需要找到user1的第二个好友——第一次用JOIN
3)为了确认,我们得让这个‘第二个好友’也是user2的好友——第二次用JOIN
WITH t AS(
SELECT * FROM Friendship
UNION ALL
SELECT user2_id as user1_id, user1_id as user2_id FROM Friendship
)
SELECT t1.user1_id, t1.user2_id, count(t2.user2_id) as common_friend
FROM t t1 JOIN t t2 ON t1.user1_id = t2.user1_id and t1.user2_id != t2.user2_id
JOIN t t3 ON t3.user1_id = t1.user2_id and t2.user2_id = t3.user2_id
WHERE t1.user1_id < t1.user2_id
GROUP BY 1, 2
HAVING count(t2.user2_id) >= 3
以后这种题可以来一打。