Apache sentry架构分析-(与hive、hdfs集成)
前言
Apache Sentry是Cloudera公司发布的一个Hadoop开源组件,它提供了细粒度级、基于角色的授权以及多租户的管理模式。类似的安全管理框架还有Hortonworks公司开源的Apache Ranger。
通过引进Sentry,Hadoop目前可在以下方面满足企业和政府用户的RBAC需求:
安全授权:Sentry可以控制数据访问,并对已通过验证的用户提供数据访问特权。细粒度访问控制:Sentry支持细粒度的Hadoop数据和元数据访问控制。在Hive和Impala中Sentry的发行版本中,Sentry在服务器、数据库、表和视图范围提供了不同特权级别的访问控制,包括查找、插入等,允许管理员使用视图限制对行或列的访问。管理员也可以通过Sentry和带选择语句的视图或UDF,根据需要在文件内屏蔽数据。基于角色的管理:Sentry通过基于角色的授权简化了管理,你可以轻易将访问同一数据集的不同特权级别授予多个组。
多租户管理:Sentry允许为委派给不同管理员的不同数据集设置权限。在Hive/Impala的情况下,Sentry可以在数据库/schema级别进行权限管理。统一平台:Sentry为确保数据安全,提供了一个统一平台,使用现有的Hadoop Kerberos实现安全认证。同时,通过Hive或Impala访问数据时可以使用同样的Sentry协议。
我司目前的大数据平台是CDH发行版v5.7.1,Senrty组件版本为v1.5.2,在我们将Hive和Impala纳入到Sentry的权限管控之后,Hive在HDFS上的WareHouse目录统一使用了Hive这个用户进行管理,鉴权的过程在HiveServer2提交任务之前进行。但是,这对于Spark或者Flink操作Hive表数据(直接从HDFS上操作数据)不免带来了权限问题,我们必须手动去HDFS为库表相应目录设置ACLs权限,才能让应用成功读取到数据。这实际上是很不利于管理的。
当然,Sentry也是提供了HDFS Sync Plugin,作用是可以将Sentry上面相应的权限同步到HDFS的ACLs中,可以很好的解决执行Spark应用的难题。但是,由于工程架构设计上的问题,v1.5.2开启了HDFS Sync之后,是不支持Sentry HA和Hive Metastore HA的,这次生产环境上还是要承受风险的。v1.8.0 Sentry团队重新设计了工程架构,可以支持 Sentry HA和Hive Metastore HA。
本文将分别阐述这两个版本整体架构,重点说明在开启HDFS Sync之后为什么前个版本不支持HA的缘由。
鸟瞰图

从上面的鸟瞰图,我们看出Sentry接入各个组件的模式,Sentry会启动常驻的Thrift服务,元数据中存储着库/表/路径和Role、Role和Group等之间的映射关系。Hive等组件通过Sentry提供的客户端和Thrift服务进行通信,用于鉴权和赋权。
让我们再将上图具体化一些:
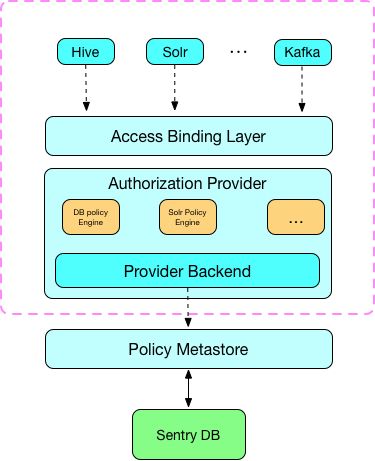
- Binding实现了对不同的查询引擎授权,Sentry将自己的Hook函数插入到各SQL引擎的编译、执行的不同阶段。这些Hook函数起两大作用:一是起过滤器的作用,只放行具有相应数据对象访问权限的SQL查询;二是起授权接管的作用,使用了Sentry之后,grant/revoke管理的权限完全被Sentry接管,grant/revoke的执行也完全在Sentry中实现;对于所有引擎的授权信息也存储在由Sentry设定的统一的数据库中。这样所有引擎的权限就实现了集中管理。
- Policy Engine判定从Binding层获取的输入的权限要求与服务提供层已保存的权限描述是否匹配。
- Policy Provider负责从数据库中读取出原先设定的访问权限。
Sentry接管HS2服务
从上节我们可以知道,Sentry要想对HS2上的操作进行权限管控,需要将自己的相应的Hook添加到操作的相应节点中。Hive的代码相对来说是写的比较优雅的,在用户可能需要扩展Hook的位置,都写好了相应配置点:
- HIVE_SERVER2_SESSION_HOOK:
// execute session hooks private void executeSessionHooks(HiveSession session) throws Exception { ListsessionHooks = new HooksLoader(hiveConf).getHooks(HiveConf.ConfVars.HIVE_SERVE R2_SESSION_HOOK); for (HiveSessionHook sessionHook : sessionHooks) { sessionHook.run(new HiveSessionHookContextImpl(session)); } } - SEMANTIC_ANALYZER_HOOK:
// Do semantic analysis and plan generation if (saHooks != null && !saHooks.isEmpty()) { HiveSemanticAnalyzerHookContext hookCtx = new HiveSemanticAnalyzerHookContextImpl(); hookCtx.setConf(conf); hookCtx.setUserName(userName); hookCtx.setIpAddress(SessionState.get().getUserIpAddress()); hookCtx.setCommand(command); for (HiveSemanticAnalyzerHook hook : saHooks) { tree = hook.preAnalyze(hookCtx, tree); } sem.analyze(tree, ctx); hookCtx.update(sem); for (HiveSemanticAnalyzerHook hook : saHooks) { hook.postAnalyze(hookCtx, sem.getAllRootTasks()); } } else { sem.analyze(tree, ctx); }
Snetry接管HS2的权限之后,我们应该在HS2做到以下两点:
- 鉴权:对于需要执行的SQL操作,我们应该判断提交的用户对于相应的库/表/路径有相对应的权限。
- 更改权限:对于管理员用户,我们可以在HS2上执行的赋权或者销毁权限的操作,要同步到Sentry服务上。
HS2-鉴权
HS2会为每一个connect的用户创建一个独有的Session,我们为每个Session添加上我们的属于我们Sentry的Hook -HiveAuthzBindingSessionHook
在这个Binding Hook中做了这么几件事:
- 挂上SEMANTIC_ANALYZER_HOOK -
HiveAuthzBindingHook,为下面从这个Session提交的SQL进行鉴权做准备; - 设置命令白名单;
- 管控创建的文件/目录的权限为700;
- 记录当前Session的执行用户,以便鉴权的时候使用。
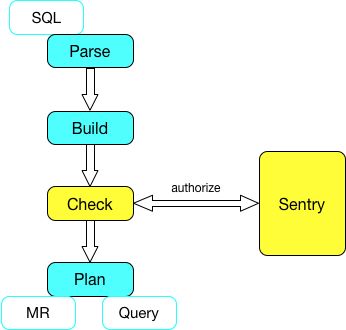
当该Session提交了一个SQL执行,在对SQL解析的过程中,Driver的compile阶段会调用我们在上一步挂上去的钩子SEMANTIC_ANALYZER_HOOK - HiveAuthzBindingHook,它主要的功能就是根据AstNode的解析树,探测到操作的表/库/路径以及动作,HiveAuthzBindingHook会去与Sentry服务器通信,校验该用户的行为是否在权限范围内。如果在,继续执行;如果不在,停止执行,抛出异常信息。
HS2-更改权限
管理员可以通过HS2进行对库/表/路径赋权,这部分的信息我们需要保存到Sentry元数据中。
Hive提供可扩展的 HIVE_AUTHORIZATION_TASK_FACTORY,Sentry提供自己的定义类 - SentryHiveAuthorizationTaskFactoryImpl,其作用就接管权限管理的任务,将权限的关系保存到Sentry的元数据库中。

Sentry HA & HS2 HA
我们可以看到,在Sentry接管HS2的权限的系统中,我们查询的是Sentry数据库中的权限信息,更改的也是Sentry数据库中的权限信息,所以Sentry服务在这里是无状态的,可以支持Sentry HA,部署多台Sentry服务用于负载均衡。
Sentry开启HDFS Sync
为了同步Sentry与HDFS ACLs的权限,这里有几个知识点需要注意:
- 我们需要从Metastore中获取库/表和具体的WareHouse对应关系;
- 如果使用我们的权限覆盖HDFS原生的ACLs,同时当我们撤销
HDFS Sync不应该影响原有的ACLs。
自定义Hadoop ACL
当集群开启dfs.namenode.acls.enabled之后,我们使用setfacl就可以设置ACLs,使用getfacl就可以获得相应目录的ACLs。我们如果能捋顺它的ACLs方式,我们就可以自己的ACL信息替代原有的。
- 命令行命令
getfacl调用客户端getAclStatus方法获取ACL状态; - NameNode收到请求之后,会调用INode的
readINodeAcl,得到ACL列表返回。public static ListreadINodeAcl(INodeAttributes inodeAttr) { AclFeature f = inodeAttr.getAclFeature(); return getEntriesFromAclFeature(f); }
我们已经找到了我们可以扩展的着力点了,hadoop2.7.1以后提供了友好的INodeAttributeProvider供我们扩展,有兴趣的可以参考网上的文章自定义Hadoop ACL
我们平台目前的版本是2.6.1还没有对应的接口,但是CDH深度定制了自己的代码,以实现想要的功能。
- 设计了AuthorizationProvider,外放了Provider,用户可配置。
- 改变类INodeWithAdditionalFields的接口,使其使用上层Provider的结果。
public final AclFeature getAclFeature(int snapshotId) {
return AuthorizationProvider.get().getAclFeature(this, snapshotId);
}
我们只要在继承AuthorizationProvider的自己的扩展类中实现逻辑即可。
注意,我们并没有更新sefacl的逻辑,所以sefacl的结果会固化到NameNode中,但是我们可以改变getfacl,这很重要。因为HDFS系统中实际上是根据这个逻辑权限管控的。
我们现在可以知道,要实现HDFS Sync要做的将Metastore中表/库与Path的对应关系、Sentry元数据中表/库/路径与Role的权限关系推到我们的AuthorizationProvider中,这样我们的权限实际上就同步了。
,Sentry提供的AuthorizationProvider - SentryAuthorizationProvider并不会持久化掉我们的Sentry权限信息,而是缓存在NameNode中,但是如何去同步这个信息,产生了两个工程框架思路,也就产生了我们本问要讲的信息。
Sentry1.5.2的HDFS Sync实现
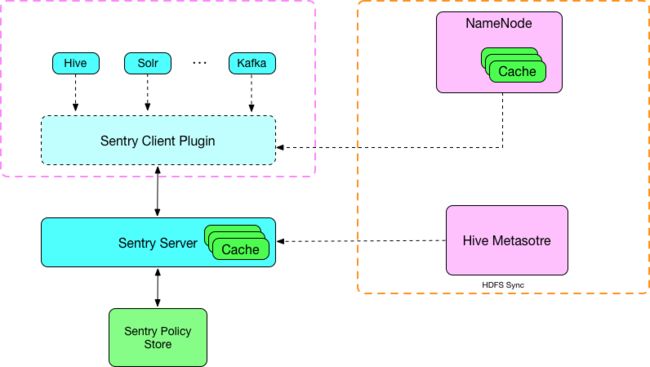
HDFS Sync实际上可以拆成两个同步问题:
- Metastore包含我们Sentry服务启动之前就已经存在的映射数据,我们称之为快照数据,这部分数据我们Sentry服务初始化的时候一次性获取过来;Metastore是在不断的处理请求的,这里的数据,我们称之为增量数据,这部分数据我们需要增量的同步到我们的Sentry服务中;
- NameNode也要增量的从Sentry服务器中获取信息,更新自己的缓存。
低版本的Hive Metastore提供了事件监听回调机制,Sentry在Metastore上设置了回调类SentryMetastorePostEventListener,当有更新请求打到Metastore,Metastore会调用Sentry Client将增量数据推到Sentry服务上。
CDH版本的hadoop源码在NameNode启动的时候,自启动了一个线程定时向Sentry服务同步上数据,增量数据使用递增的唯一ID,用来判断NameNode是否已经同步了所有的增量信息。
Sentry1.5.2的HA分析
基于以下天然设计:
- 我们的增量事件是有序的;
- 增量事件是由Metastore推到Sentry上去的;
- Sentry的这部分信息是缓存,没有持久化;
决定了没办法支持Metastore HA和Sentry HA
如果HA,会导致:
- 每个Metastore都都发送增量事件,它们的顺序id,目前没办法做到唯一递增;
- 每个Sentry服务的缓存Cache不一致;
所以,很遗憾,Sentry1.5.2开启了HDFS Sync之后没办法支持Metastore HA和Sentry HA。
Sentry1.8.0的HDFS Sync实现
针对上面的分析,要解决Sentry设计上的缺陷其实也不难:
- 针对Sentry Cache产生的HA问题,我们可以持久化到一个共享的数据存储中,这样就能保证多个Sentry服务读取的信息是一致的了,NameNode连接到任何一个Sentry服务节点上是等效的,实现上又恢复了Sentry服务的无状态性;
- 解决多个Metastore的id问题,并且保证顺序存储也可以解决Metastore HA的问题。
针对 Metastore HA产生的增量事件顺序紊乱的情况,新版的Hive Metastore提供了获取NotificationEventId的API,并且可以根据事件Id,获取相应的事件,所以问题二已经天然解决。

上图是Sentry1.8.0以上的架构图,不同时刻的全量快照和增量事件被保存到Sentry的DB中,这样不管NameNode连接到哪一台都可以获取到相同的信息,我们在工程需要做的事情包括:
- 应该只有一台Sentry服务去连接Metastore上去拉取增量数据或者全量数据;
- 应该只有一台Sentry服务可以将获取的信息保存到DB中。
为了实现这一的要求,Sentry1.8.0借助Zookeeper来选择执行上述操作的Leader服务,一旦Leader服务挂掉之后,会有一台Follower变成Leader进行上述同步Metastore中的数据的操作。
Sentry1.8.0的HA分析
通过上面的实现架构变更,已经很好的实现了在HDFS Sync开启的状态下Metastore HA和Sentry HA。
作者:PunyGod
链接:https://www.jianshu.com/p/6d85d884c558
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。