MySQL数据库
什么是数据库
数据库(DataBase)通俗点来说就是数据的‘仓库’,按照数据结构(二维表)来组织、存储和管理数据的仓库。
常见术语
-
表:数据库中的数据都以表格的形式出现
-
行:各个记录的名称,也可以理解成一条信息,也可以看成是一个对象
-
列:记录名称所对应的数据域,就是对表格的描述,类似于Java中的属性
-
一个表格由很多的行和列组成
-
数据库由很多表格组成
-
冗余:多余的数据,无用数据,降低系统的性能
-
数据库管理系统(DBMS):一个软件,MySQL就是一个数据库管理系统,负责维护管理数据库的一个工具
MySQL数据库
MySQL是一个关系型数据库管理系统(RDBMS),是由瑞典的一个公司研发的免费的数据库管理系统,目前隶属于Oracle公司
-
MySQL是开源的,基础内容是免费的
-
MySQL支持大型的数据库,可以去处理拥有上千万条记录的大型数据库
-
MySQL使用标准的SQL语言来编写代码
结构化查询语言
结构化查询语言简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存储、更新、管理和查询关系数据库系统。也是关系型数据库的通用语言。
组成部分:
-
数据定义语言(DDL):在数据库中创建、删除、修改结构的操作,比如创建表、数据库、索引等
-
数据控制语言(DCL):它通过两个Grant和Revoke来对权限进行操作,这个部分不是我们的重点
-
数据操纵语言(DML):对数据的增加、删除和修改,对数据的影响
-
数据查询语言(DQL):对表中的数据进行查询的一种语言,也是我们最重要的部分
SQL语言不区分大小写,我们推荐命名时通过_来区分。
数据库的操作
创建数据库
##创建数据库 create database slxy2201;
删除数据库
##删除数据库 drop database slxy2201;
使用数据库
##使用数据库 模式的切换 use slxy2201;
数据库表的操作
创建表
##创建表 create table 表名 ( 列名 数据类型 [约束], 列名 数据类型 [约束], ...., 列名 数据类型 [约束] ); ##名称:命名规则和Java相同,规范:不能使用中文、不要以$开头,不要以_开头,没有驼峰,以_隔开 /* MYSQL的数据类型:数值、时间日期和字符串 常用数据类型 数值: 整数类型:int 小数:float 数值类型:decimal(m,d),m:有效数字 d:小数点后几位 时间日期: 日期:date 年月日 时间:time 时分秒 时间日期:datetime 年月日时分秒 字符串: 定长字符串:char 变长字符串:varchar 二进制字符串:longblob 二进制形式的文本数据 长文本数据:longtext */ /* 约束:对数据库表中的数据格式、内容进行限制 主键约束:约束表中的这列数据值唯一,一张表只能有一个主键约束并且主键约束不允许为null 唯一约束:约束表中的这列数据值唯一 check约束:根据相应的条件对列的数据进行约束 默认值约束:在不输入内容时填充默认值 外建约束:维护表之间关系 为空约束:设置这一列数据不能为空 */
修改表结构
#向表中插入一列 alter table users add newTab varchar(20) not null; #修改表中列名以及数据类型 alter table users change newTab new_column varchar(20); alter table users change new_column new_column char(20); #添加一个默认值约束和为空约束 alter table users modify new_column char(20) null default 'abcd'; #删除表中的列 alter table users drop new_column; #添加check约束 alter table emp add constraint CK_SAL check ( sal>0 );
删除表
drop table users;
DML操作
向表中插入数据
#插入数据 insert into 表名[(列字段列表)] values(值列表); #录入时一一对应 insert into emp(empno,ename,job,mgr,hiredate,sal,comm,depteno,empstate) values(1,'王雨荷','阿凡达',null,'2020-9-1',50000,3000.3,1,1); #未赋值的列赋予null值,如果有默认值用默认值填充 insert into emp(empno,ename,job,sal) values(2,'郭宇轩','程序员',9000); #❌ 非空列必须赋值 insert into emp(empno,sal) values(3,9999); #可以不需要和物理顺序一致 insert into emp(empno,job,mgr,ename) values(3,'阿凡达',1,'刘桂花'); #列字段列表可以省略,如果省略了必须按照物理顺序全填充 insert into emp values(4,'张静','姐',null,default,23000,null,2,default); #录入一条有自增效果的员工 insert into emp values(null,'冯文超','程序员',2,default,8900,4000,1,1); #批量数据的录入 insert into emp(empno, ename, job, mgr, sal, comm) select null,'赫宝宝','程序员',5,8000,3000 union select null,'邱紫坪','动漫评论员',null,6000,10000 union select null,'谢苗','程序员',1,9000,3000; #表复制 #1.表复制:使用查询出来的结果创建一个新表 create table emp2 as select * from emp; #2.表复制:将查询出来的内容插入到emp2表中 要求emp2表存在 不会创建新表 insert into emp2 select * from emp;
删除表中的数据
delete from 表名 [where 条件]; #删除表中的所有数据 delete from emp2 ; #将姓名是'张静'的员工删除 delete from emp2 where ename='张静'; #删除所有的表数据 没有条件的说法 truncate table 表名; truncate table emp2; /* drop、delete和truncate的区别? 答:drop是删除表结构,是将这张表都删除了 delete和truncate都只是删除数据,表结构还在 delete是可以删除所有数据,也可以删除部分数据,delete删除时有事务,有日志,可恢复,删除速度慢 truncate只能删除全表数据,truncate删除时没有事务,不写日志,不能恢复,删除速度快 */
修改表中的数据
update 表名 set 列名 = 新值 ,列名 = 新值,...,列名 = 新值 [where 条件]; #修改编号为3的员工入职时间为'2021-1-18'部门编号为3 update emp set hiredate='2021-01-18',depteno=3 where empno=7; #给所有员工工资+1000元 update emp set sal = sal + 1000 ; #给所有入职时间为今年的员工工资+300 update emp set sal = sal + 300 where hiredate>='2022-01-01';
数据的完整性
准备 + 可靠 = 完整的数据
实体完整性
保证表中的行都是唯一的,也就是说不会出现重复的数据,如何保证呢?我们可以通过给表添加主键的方式来完成。
域完整性
也叫做列完整性,其实就是对某一列的数据进行约束,如何保证呢?通过check约束来实现。
引用完整性
表和表之间关系的完整性设置,也就是说这张表中引用的数据必须在另一张表中存在,我们一般通过外建约束来保证。
自定义完整性
行业自定义的规则,根据各个行业的规则来设置,一般通过触发器实现。
数据库事务
数据库事务时访问并操作各种数据的一个数据库操作序列,这一系列操作要么全部执行,要么全部不执行,是一个不可分割的工作单元。数据库事务由事务开始与事务结束之间执行的全部操作组成。事务是一个批处理的操作。
数据库事务由四大特性(ACID):
原子性
事务中的全部操作(Insert、Update或者Delete)在数据库中是不可分割的,要么一起成功,要么一起失败。
一致性
事务在执行之前和执行之后对于数据库的完整性都是一致的,没有破坏。
隔离性
多个事务在并行执行过程中,相互之间不受干扰,事务执行的中间结果对于其他事务是透明的。
持久性
任意已提交的事务,对于数据库的影响是持久的。
##数据库事务 #DataGrip对于Insert、Update和Delete是自动提交事务 #手动设置不让自动提交事务 set autocommit = false; #向emp表中录入了一条数据 insert into emp values(null,'丁静','动漫评论员',7,'2019-12-21',9999.9,null,1,1); #设置了事务不自动提交,在执行Insert、Update和Delete后需要手动提交事务,因为这条数据并没有实际录入到数据库中 #需要确认 只有确认后对于数据库才是持久的 #成功确认 commit; #失败确认 rollback; insert into emp values(null,'刘云云','程序员',2,'2021-7-15',10086,32.76,1,1); ##更新时的操作 update emp set sal=sal+3000 where empno = 11; update emp set sal = 18888 where empno=11; #常见的一个面试题 delete from emp where empno=4; update emp set job='项目经理' where empno=4; #更新自动不成功,但是代码是成功的 #常见的一个面试题 insert into emp values(4,'张静','姐',null,default,23000,null,2,default); #无法录入的 insert into emp values(4,'张静','项目经理',null,default,23000,null,2,default); ##其他的几个关键字 insert into emp values(null,'郭喆雨','程序员',null,default,19800,null,2,default); SAVEPOINT S1; #设置了记录点 insert into emp values(null,'李宏伟','程序员',null,default,18800,null,2,default); savepoint s2; #设置了记录点 rollback to s1; #回滚到记录点S1 commit;
DQL操作
###DQL--数据查询语言()
select 待显示列子段列表 from 表名 [where 条件] [group by 分组] [having 筛选条件] [order by 排序] [limit ?,?];
##1.全表查询 *代表所有列
select * from emp;
##2.查询部分列的数据
select ename,job,sal from emp;
select hiredate,ename,sal from emp;
##3.给查询出来的列起一个别名 列名 as '别名'
select ename as '姓名',job as '职位' from emp;
##4.通过关系运算符来筛选部分行的信息 where 代表条件 是在筛选行的信息
#>,>=,<,<=,!=(<>),=
#求出工资sal大于20000的员工信息
select * from emp where sal>20000;
#求出职位不是动漫评论员的员工信息
select * from emp where job<>'动漫评论员';
#找出姓名为'刘云云'的员工信息
select * from emp where ename='刘云云';
##5.在查询中使用算术运算符 + - * / %
#所有员工查询出来的工资+1000显示
select ename,sal+1000 from emp;
#找出工资是偶数的员工信息
select * from emp where sal%2=0;
##6.通过逻辑运算符来筛选部分行的信息 and or not
#找出2021年入职的员工信息
select * from emp where hiredate>='2021-1-1' and hiredate<='2021-12-31';
#找出职位是程序员和阿凡达的员工信息
select * from emp where job='程序员' or job ='阿凡达';
##7.唯一查询 去除掉重复的选项 一般我们使用时去重是针对于一列
select distinct job from emp;
select distinct * from emp;
##8.常量查询
select 134;
select 134,'abc';
select ename,'张三' as '查询人' from emp;
##9.为空查询 与 NULL 进行比较应当使用 IS NULL 运算符
#查询没有奖金的员工
select * from emp where comm=null; #❌
select * from emp where comm is null;
#查询有奖金的员工
select * from emp where comm is not null;
##10.if和ifnull函数的使用
#统计每位员工的年收入
select ename ,sal,comm, (sal+comm) * 12 as '年收入' from emp; #❌
#当comm为null时 显示1
select ifnull(comm,1),comm from emp;
select if(comm is null,1,comm),comm from emp;#类似于Java中的三目运算符
select ename ,sal,comm, (sal + ifnull(comm,0) ) * 12 as '年收入' from emp;
select ename,sal,comm,(sal + if(comm is null,0,comm))*12 as '年收入' from emp;
##11.范围查询 between and
#查询工资在10000-20000之间的员工
select * from emp where sal>=10000 and sal<=20000;
select * from emp where sal between 10000 and 20000;
#查询工资不在10000-20000之间的员工
select * from emp where sal<10000 or sal>20000;
select * from emp where sal not between 10000 and 20000;
##12.范围查询 in和not in
#查询职位是阿凡达、程序员和动漫评论员的员工
select * from emp where job='阿凡达' or job='程序员' or job='动漫评论员';
select * from emp where job in('阿凡达','程序员','动漫评论员');
#查询职位不是阿凡达或者程序员的员工
select * from emp where job not in('阿凡达','程序员');
##13.模糊查询 看起来像 like %:通配符代表0到正无穷个任意字符 _:通配1个任意字符
#查询姓名中带'雨'的员工
select * from emp where ename like '%雨%';
#查询姓'郭'的员工
select * from emp where ename like '郭%';
#查询以'雨'结尾的员工
select * from emp where ename like '%雨';
#查询姓'郭'的员工并且名字只有1个字
select * from emp where ename like '郭_';
##14.排序查询 order by desc asc
#按照工资升序显示
select * from emp order by sal asc; ##asc可省略
#按照姓名降序显示
select * from emp order by ename desc;
#按照职位升序显示,职位相同时按照工资降序显示
select * from emp order by job,sal desc;
#按照工资升序显示所有的程序员
select * from emp where job='程序员' order by sal;
##15.聚合(分组、统计)函数查询 max min sum avg count
#分别统计员工表的最高工资和最低工资
select max(sal),min(sal) from emp;
#分别统计员工表的总工资和平均工资
select sum(sal),avg(sal) from emp;
#max、min可以用作所有数据类型,sum和avg只能用于数值类型
select max(ename),min(ename),sum(ename),avg(ename) from emp;
#sum和avg会自动忽略null
select sum(comm),avg(comm) from emp;
#统计表中一共有多少行
SELECT count(*) from emp;#不推荐写法 *代表所有行
select count(empno) from emp; #推荐写法 empno是主键
#统计有奖金的员工数量 会自动忽略null
select count(comm) from emp;
##16.分组查询
#统计每个职位的最高工资和最低工资
select job,max(sal),min(sal) from emp group by job;
#注意:常见错误 如果使用了聚合函数或者分组操作,那么select和from之间只允许出现分组字段和聚合函数
select job,max(sal),min(sal),ename from emp group by job;#❌
#查找有奖金的每个职位的最高工资和最低工资
select job,max(sal),min(sal) from emp where comm is not null group by job;
#查找每个职位有奖金的员工数
select job,count(empno) from emp where comm is not null group by job;
#查找那些职位有2个以上员工有奖金
#从语法上来说:使用分组后聚合函数不能应用于where中
#从逻辑上来说:先筛选有奖金的员工 然后按照职位进行分组 统计每个职位的有奖金员工数 在按照员工数进行筛选
#而这段内容呢,where是在group by之前进行筛选,那我就需要一个在分组后再次进行筛选的操作
select job,count(empno) from emp where comm is not null and count(empno)>2 group by job;#❌
#where在分组前筛选 having 在分组后筛选转为group by 语句准备的
select job,count(empno) from emp where comm is not null group by job having count(empno)>2;
#多字段分组 首先按照职位进行分组,在职位的分组列表中 再按照姓名进行二次分组
select job,ename from emp group by job,ename;
##17.union拼接查询 union不会拼接重复数据 了解
select 7 union
select 8 union
select 8 union
select 9;
select 7 union all
select 8 union all
select 8 union all
select 9;
##18.分页查询 只查询部分行数据 比如有1000W条件 每次并不会全查询 每次只选取其中的10条数据
select * from emp limit 0,5; #0:从第几条开始取 5:每次获取多少条
#假设page是页码 size是每页显示多少条
#select * from emp limit (page-1)*size, size;
##19.正则表达式查询 了解 一般都使用模糊查询
#查找姓名中带雨的员工
select * from emp where ename regexp '雨';
#查找姓名中以雨结尾的员工
select * from emp where ename regexp '雨$'; #$代表结束
#查找姓名中以郭开头的员工
select * from emp where ename regexp '^郭'; #^代表开头
#查找姓名中带郭、宝、凤的员工
select * from emp where ename regexp '[郭宝凤]';
#查找姓名以郭开头只有3个字的员工
select * from emp where ename regexp '^郭.{2}'; #.代表任意一个字符 {2}代表数量
select * from emp where ename regexp '^郭.{2,3}'; #{2,3}代表最少2个字符,最多3个字符
#问题:姓名中包含雨但是雨不能在首位和末尾的员工
select * from emp where ename regexp '雨' and ename not regexp '雨$' and ename not regexp '^雨';
##20.常用函数查询
#20.1 数字函数
#返回绝对值
select abs(-1),abs(8);
#取整数 重点 记住 floor
select floor(5.6),floor(5.4),ceil(5.6),ceil(5.4),round(5.6),round(5.4);
#返回随机数 [0,1)
select rand(),ceil(rand()*10);
#返回余数
select 8%3,mod(8,3);
#20.2字符串函数
#获取字符串的长度 字符数(重点),字节数,所占位数
select char_length('a8啊b好'),length('a8啊b好'),bit_length('a8啊b好');
#查询姓名中带中文的员工
select * from emp where char_length(ename)<>length(ename);
#截取字符串(重点)
select left('abcdefg',3);#截取前三个字符
select right('abcdefg',3); #截取后三个字符
select substr('abcdefg',2,3);#从第2个开始 截取三个字符
#查找字符串 重点
select instr('abcedfgabcd','a');#查找a在目标字符串(abcedfgabcd)第一次出现的位置,如果没有返回0
select position('a' in 'abcedfgabcd');#同上 只记一个
#反转字符串
select 'abcd',reverse('abcd');
#替换字符串 重点
select 'abcdefghasdsgdj',replace('abcdefghasdsgdj','a','M');
#重复书写
select repeat('abc',3);
#拼接字符串 重点
select 'abc'+'bcd';#❌ +只能求和
select concat('abc','bcd');
select concat('abc','bcd','cde','def'); #可以拼接多个字符串
select concat_ws(',','abc','bcd','cde','def'); #第一个字符串是分隔符
#去除空格
select trim(' a b '),ltrim(' a b '),rtrim(' a b ');
#大小写
select upper('aBcD'),lower('aBcD');
#获取ASCII码 但是0-127之间的内容
select ascii('a'),ascii('张');#张❌
#20.3时间日期函数
#获取当前时间 now()重点
select now(),current_date(),current_time();
#获取到年月日时分秒
select year(now()),month(now()),dayofmonth(now()),hour(now()),minute(now()),second(now()),dayofweek(now());
#时间日期的累加操作
select adddate(now(),interval 1 month); #获取1个月之后的日期
select adddate(now(),interval 5 year); #获取到5年之后的日期
select adddate(now(),interval -3 day); #获取到3天之前的日期
select ADDTIME(NOW(),'0:1:0'); #获取到4秒之后的时间
select ADDTIME(NOW(),'6:7:8'); #获取到6时7分8秒之后的时间
#获取到当月的最后一天
select last_day('2011-2-4'),last_day('2000-2-1');
#时间日期的累加操作 重点
select date_add(now(),interval 3 day);
select date_add(now(),interval -3 month);
select date_add(now(),interval 8 year);
select date_add(now(),interval 19 second );
select date_add(now(),interval -7 minute );
select date_add(now(),interval -29 hour );
#计算日期之差 重点
select datediff('2021-9-7','2022-11-7');
#格式化时间
select date_format(now(),'%Y年%m月%d日');
#20.4系统函数
#case类型转换 也可以使用+来计算
select '029'+1,cast('029' as signed integer ); #cast类型转换 string-->int
#小数点后保留几位
select format('2.9998',2);
##21.子查询
#概念:将一个查询的结果当成是另一个查询的条件时,这个查询就是子查询,外边的查询就是父查询,查询嵌套
#查询工资比胡凤娟工资高的员工
select sal from emp where ename='胡凤娟';
select * from emp where sal>12800;
select * from emp where sal>(select sal from emp where ename='胡凤娟');#一条SQL语句
#子查询的分类
#21.1 标亮子查询:子查询返回的结果是一行一列的单个值,最常见、最简单的子查询方式 重点
#查询职位和刘友腾一样并且工资比张静高的员工
select job from emp where ename='刘友腾';
select sal from emp where ename='张静';
select * from emp
where
job=(select job from emp where ename='刘友腾') and
sal>(select sal from emp where ename='张静');
#21.2 列子查询:返回的结果是多行一列的子查询 in或者not in 重点
#查询职位和张静或者邱紫坪一样的员工
select job from emp where ename='张静' or ename='邱紫坪';
select * from emp where job in (select job from emp where ename='张静' or ename='邱紫坪');
#查询职位和张静或者邱紫坪不一样的员工
#21.3 行子查询:子查询返回的结果是一行多列 了解
#查询职位和刘桂花一样并且部门和她一样的员工信息
select job,deptno from emp where ename='刘桂花';
select * from emp where (job,deptno)=(select job,deptno from emp where ename='刘桂花');
#21.4 表子查询:子查询返回的结果是多行多列 了解
select * from emp where sal=10087.90;
select * from emp where (ename,job,sal) in (select ename,job,sal from emp where sal=10087.90);
#两个关键字 all,any(some)
#查询工资比所有程序员工资高的员工
select sal from emp where job='程序员';
select * from emp where sal>(select sal from emp where job='程序员'); #❌
select * from emp where sal>(select max(sal) from emp where job='程序员');
select * from emp where sal>all(select sal from emp where job='程序员');
#查询工资比任意程序员工资高的员工
select * from emp where sal>(select min(sal) from emp where job='程序员') and job<>'程序员';
select * from emp where sal>any(select sal from emp where job='程序员') and job<>'程序员';
select * from emp where sal>some(select sal from emp where job='程序员') and job<>'程序员';
#注意:关系运算符的> >= < <=必须是一行信息
#练习1:查询工资比2号部门平均工资高的其他部门员工
#练习2:查询每个部门最高工资的员工是谁(员工信息)
#练习3:查询出来比公司平均工资高的员工信息
create table dept
(
deptno int primary key ,
dname varchar(20),
loc varchar(20)
);
insert into dept values(1,'研发部','西安');
insert into dept values(2,'产品部','渭南');
insert into dept values(3,'视觉部','汉中');
insert into dept values(4,'科技部','商洛');
insert into dept values(5,'财务部','长春');
##22.表连接查询
select * from emp;
select * from dept;
#22.1 内连接 多张表之间平等的关系按照相应的条件拼接起来 拼接列
select 待显示列子段 from 表A inner join 表B [on 连接条件] [where 筛选条件];
select * from emp inner join dept on emp.deptno=dept.deptno;
#给表起了一个别名
select * from emp e inner join dept d on e.deptno=d.deptno;
#缩写形式
SELECT * from emp e,dept d where e.deptno=d.deptno;
#查询职位是程序员的员工信息,显示:员工名、部门名、职位、工资和地址
select e.ename,dname,job,sal,loc from emp e inner join dept d on e.deptno=d.deptno where job='程序员';
#表和表之间是平等关系
select ename,dname,job,sal,loc from emp e,dept d where e.deptno=d.deptno and job='程序员';
select ename,dname,job,sal,loc from dept d,emp e where e.deptno=d.deptno and job='程序员';
#22.2 外连接
#22.2.1 左外连接:以左表为主、右表为辅来进行连接 左表在右表中未对应的行也会显示
select 待显示列子段 from 表A left [outer] join 表B [on 连接条件] [where 筛选条件];
select * from dept d left join emp e on d.deptno = e.deptno;
#22.2.2 右外连接:以右表为主、左表为辅来进行连接 右表在左表中未对应的行也会显示
select 待显示列子段 from 表A right [outer] join 表B [on 连接条件] [where 筛选条件];
select * from dept d right join emp e on d.deptno = e.deptno;
#22.2.3 全外连接:返回所有的行信息,未匹配上的以null填充 MySQL中没有全外连接
select 待显示列子段 from 表A full [outer] join 表B [on 连接条件] [where 筛选条件];
select e.*,d.* from dept d full join emp e on d.deptno = e.deptno;
#22.3 交叉连接 笛卡尔积 了解
select * from emp cross join dept;
##23.case查询
#查询显示每个员工的信息,工资以等级显示
select * from emp;
select e.*,
case
when sal>30000 then '神豪'
when sal>15000 then '土豪'
when sal>8000 then '中产'
when sal>3000 then '屌丝'
else '贫民'
end
as '工资区间' from emp e;
##24.exists查询 括号中跟的一定是子查询语句,只判断是否存在行的信息,如果没有行 条件为false 反之条件为真
select * from emp where exists(select 8);
select * from emp where exists(select * from emp where sal>100000);
索引
介绍
对于一个正常软件系统,一般查询和更新比例是10:1,而且更新操作很少出现问题,在正常(生产环境)使用中,我们遇到的最多的问题就是查询,尤其是复杂的查询,尤其对于查询的效率更加看重,所以说索引对我们来说是一种提升查询效率的手段。
索引就像一本字典中的拼音或者偏旁部首部分,我们可以通过它们快速找到想要的内容。
原理
索引的目的是为了提升查询效率,这个跟我们看书中的目录作用是一样的,首先定位到章,然后在定位到节,最后查找具体的页数。这些操作它们本质来说缩小范围的方式来筛选出最终的结果,同时把随机的事件变成了顺序的事件。
通过B+树的方式来实现的
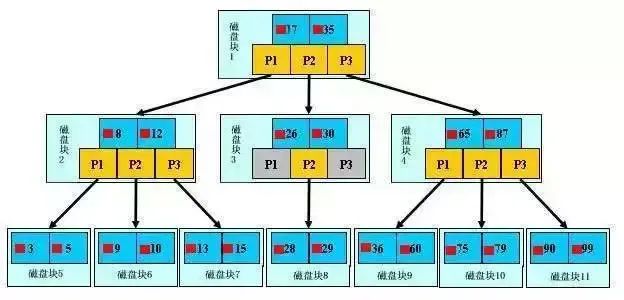
分类
普通索引
仅仅为加速查找,但是对于效率的提升不是很明显
唯一索引
主键唯一索引:加速查找、约束(唯一、非空)
普通唯一索引:加速查询、约束(唯一)
这两种的效率提升是很明显的
组合索引
其实就是普通和唯一索引,只不过可以有多个健来组合到一起生成一个索引
联合主键索引
联合唯一索引
联合普通索引
全文索引
用于在文章中搜索的时候,快速定位
空间索引
不使用,不讲解
实现
普通索引
#1.1 create index index_1 on emp(sal); #创建了一个普通索引,索引放到了sal列 #1.2 create table demo1 ( did int primary key , #创建主键索引 dname VARCHAR(20) NOT NULL, dage int, index(dage) #在建表时给dage添加了一个普通索引 ); #1.3 alter table emp add index index_2(hiredate);#创建了一个普通索引,索引放到了hiredate列
唯一索引
#2.1 create unique index index_3 on emp(ename); #2.2 create table demo2 ( did int , dname varchar(20), primary key (did),#添加了主键索引 unique (dname) #添加了唯一索引 ); #2.3 alter table demo1 add unique index index_4(dname); alter table demo1 add primary key (did);#主键索引
组合索引
#3.组合索引 同一个性别中姓名不能重复,但是可以有男张三和女张三
create table demo3
(
dname varchar(20),
dsex char(1),
dage int,
dphone char(11),
demail varchar(100),
dcolumn1 int,
dcolumn2 int,
dcolumn3 int
);
create index index_5 on demo3(dcolumn1,dcolumn2);#添加了一个普通组合索引
create unique index index_6 on demo3(dcolumn2,dcolumn3);#添加了一个唯一组合索引
alter table demo3 add primary key (dname,dsex);#添加了一个主键组合索引
存储过程
类似于Java中的方法,一段编译后执行的代码块
语法
delimiter // create procedure 存储过程名称(形式参数列表) begin 存储过程体; end //; delimiter ;