Dolphin Streaming实时计算,助力商家端算法第二增长曲线
丨目录:
1.背景
2.业务问题
3.业界解决方案
4.技术方案
5.应用示例
6.业务收益
7.总结
1. 背景
随着业务朝向精细化经营增长,阿里妈妈商家端营销产品更加聚焦客户投放体验,旨在帮助商家提升经营效果,在变化的市场中找到确定增长。近年来,商家端算法业务使用的数据是离线T+1甚至T+7更新,为进一步捕捉用户意图,更全面实时的挖掘潜在需求,利用实时行为及投放效果帮助广告主在成效预估、货品工具推荐等业务有更好效果,阿里妈妈数据引擎团队从21年开始在数据实时化开发方面进行探索尝试,从实时角度助力商家端算法第二增长曲线。
货品工具推荐场景2. 业务问题
与用户端(C端)相比,商家端(B端)算法业务更具多样性,但对实时数据的使用还处于启蒙阶段。目前面向C端的实时开发服务已经很成熟,但开放的能力比较基础,且这些能力主要面向工程同学,但在实际B端场景中,因算法工程支持资源有限,而算法同学自己直接开发实时作业成本较高,不仅需要学习了解上游实时数据源订阅信息,还需要了解不同存储引擎选型等工程技术支持,例如Igraph(阿里集团内部KV存储引擎)、Lindorm(阿里云多模存储引擎)和Hologres(阿里云HTAP存储引擎)等,所以需要有一个更算法友好的开发平台,实现让非工程同学也能轻松开发实时作业。
那么,对于算法同学什么开发方式最简单?因为算法同学对SQL非常熟悉,每天大量工作都在Dataworks(Dataworks是阿里集团大数据开发平台)完成,所以能让实时作业SQL化开发是平台确定方向。目前Flink已经可以提供SQL化开发,但仅提供基础实时计算开发能力,存储方面需要自己选择,对于非工程技术人员仍有较高的学习成本,故期望如下能力:
屏蔽底层细节的SQL化开发,不仅开发SQL化,还可以帮助用户屏蔽底层存储和上层数据源配置信息,降低学习及开发成本;
统一的数据中心,从实时开发的数据获取、开发调试及上线End2End一体化,提升开发效能。
3. 业界解决方案
如何更高效开发实时作业,业界有很多尝试和探索。
3.1 集团内部解决方案
在集团内部,经常使用的实时化产品有AMC特征中心和蚂蚁特征服务平台等,它们体系化建设完善且功能全面,但大多是工程同学使用,有一定开发使用成本。
3.1.1 AMC特征中心
AMC是特征样本平台,解决主搜场景算法同学特征迭代遇到的问题,提供复杂特征开发和统一特征管理问题。

在复杂特征开发方面提供TableApi,支持算法自助开发复杂特征,该方案灵活性比较高,但是从算法开发体验和debug角度看,成本仍然较高。
3.1.2 蚂蚁特征服务平台
蚂蚁提供全平台统一的特征服务平台,提供特征管理、服务、分析和计算等能力。

为了简化计算流程,平台提出特征SQL语法,该语法使用类似SQL,但区别较大,对新开发同学学习成本不低,因为新语法有很多非通用概念。
3.2 外界解决方案
调研发现外界有很多类似的设计,主要有老牌云厂商Cloudera的SSB和新兴公司RisingWave。
3.2.1 Cloudera Stream Builder
Cloudera在实时开发方面有成熟商业化实践,Stream Builder整体上是基于Flink和Database封装形成实时开发平台,使用SQL进行开发,数据经过Flink处理写入database,从Database读取数据,架构图如下。
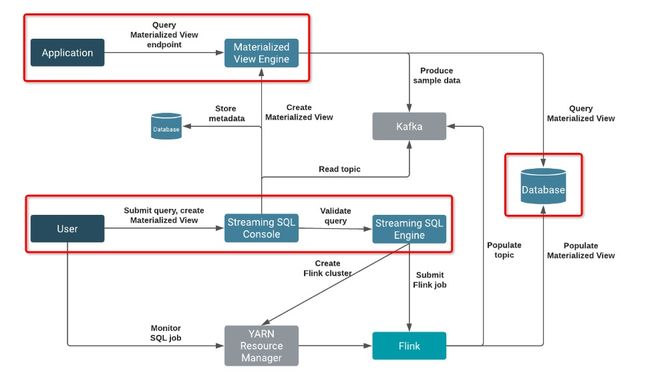

上图为用户开发页面,所有的数据源和存储库都抽象出来,配置一次即可,无需每个job都配置一次,此外该平台还提供sample能力支持数据preview,大幅提升数据开发效率。
3.2.2 RisingWave
RisingWare在2021年底开源,主打实时数据库,不仅包括实时计算能力,还有自己的存储,提供PG SQL语法,用户可以像使用传统数据库一样开发实时作业,整个流程就像操作传统数据库,所写即所得。
它和我们系统设计的目标非常一致,提供通用的SQL语法,且使用方面不用过多考虑数据来源和存储选择,学习成本、开发、调试及上线都一体化,是用户体验和开发成本更优的方案,但RisingWave还在dev阶段。
4. 技术方案
当前集团提供的实时开发方案多面向工程技术同学,具有相对灵活的控制能力,可解决超大规模复杂场景;但在广告商家端场景,面对百万规模的用户实时行为,业务更看重开发迭代效率,期望把复杂工程细节屏蔽,节省人力成本提升迭代效率。
Dolphin引擎是阿里妈妈数据引擎团队自2018年底研发的超融合一体化计算引擎,在面向商家端营销产品场景下经过多年发展,已经从最初的OLAP计算延伸到AI计算、实时计算和批量计算,让业务迭代效能达到较高水位。
引擎基于在SQL领域的基础能力,在2021年中研发出Streaming框架能力,填补实时计算能力空白,解决实时计算高开发及维护成本问题,下图是Dolphin Streaming在整体B端工程解决方案的定位,主要是基于计算存储引擎以及SQL引擎能力构建。

4.1 设计思路
Dolphin Streaming设计目标是像开发数据库一样开发实时作业(DB for Streaming),让算法等非工程用户也可以轻松开发实时作业,具体包括:
极简SQL语法:屏蔽有理解成本的实时开发术语,如TUMBLE、HOP等;
底层技术无感知:为算法用户及其他非工程用户提供一套开发平台,无需过多感知上下游数据源和存储;
流程一体化:打通从实时数据开发、迭代到上线读取全流程。
该设计跟Cloudera、Risingwave有很多相似,但也有区别:
不仅关注实时开发平台,还关注用户对实时数据获取、开发及高效复用;
设计简化SQL语法,屏蔽TUMBLE、HOP等概念;
不仅关注数据开发产出,还关注用户开发后直接上线数据流程。
4.2 架构图
我们开发了从数据、计算引擎到上线一体化方案,端到端高效实现数据开发、存储、debug查询及上线整个流程。
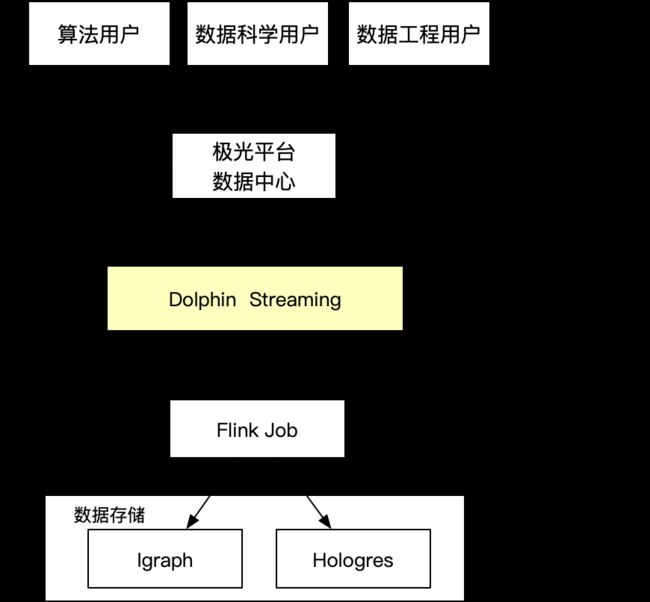
4.3 数据层
目前阿里妈妈广告商家端数据散落在各个团队,我们期望面向商家端场景搭建数据中心,让离线和实时数据被更好的管理、复用。具体设计如下:
将实时行为标准化,沉淀实时、离线特征基础设施,提升数据复用,减少重复存储和开发。
建立实时数据地图,降低实时数据查找、管理及维护成本。
建立商家端数据中心,并跟极光开发平台结合,形成集团公共层、妈妈商家端中间层到业务应用层三层数据体系。

此外,我们还建立了面向商家端算法实时开发的协作模式:
数据同学负责将集团公众层非结构化数据ETL为结构化的实时数据中间层;
算法等非工程同学自主使用Dolphin SQL将上游中间层实时数据进一步开发聚合为所需要的特征数据;
特征数据会进入商家数据中心被复用。

数据同学开发的中间层数据进入商家数据中心,数据一方面可被直接被查询,另一方面可以给算法同学开发特征使用,开发的特征会进入商家特征中心,从而形成数据闭环和复用,如下图所示。

4.3 Dolphin引擎
Dolphin Streaming在实现方面基于Flink实现,使用OpenAPI实现对Flink job的创建、资源配置和启停;在存储方面使用GP、Hologres和igraph,该方案既利用现有引擎支撑大规模场景的成熟能力,又让使用体验像数据库一样简单。下图是Flink、RisingWave和Dolphin Streaming的架构特点:

这里主要对比Dolphin Streaming跟Flink的区别:
Flink定位实时计算引擎,没有自己的存储,用户在使用必须定义外部存储
Dolphin Streaming屏蔽计算和存储引擎,计算引擎使用Flink,存储使用不同引擎
用户无需感知Flink SQL语法,只需要使用更简单,更接近SQL标准的Dolphin SQL
用户开发无需感知底层存储类型、表配置等信息
Dolphin Streaming提供数据库SQL操作方法,使用Flink成熟大规模计算能力,屏蔽存储,让实时数据开发和查询一体化,是结合用户使用体验和性能的不二之选。
4.3.1 SQL转译
Dolphin streaming提供一套面向算法用户友好的SQL语法,屏蔽数据源信息、中间结果处理、输出信息,让算法用户开发实时特征就像在Dataworks上开发离线计算作业一样简单。
(1)实时作业开发
新作业的整体开发流程分为定义输入源、定义输出源和定义计算逻辑三个部分,定义数据源只需要执行一次全局可用,无需每个作业都重复定义。为了屏蔽底层复杂的实时计算语义理解问题,我们设计更简化的UDF,让开发更简单,例如:
window_row(amount),窗口函数,按时间排序取最近amount条行为。
window_time(timecloum,timeunit) 按照单位时间进行指标序列聚合
(2)实时数据查询
传统方案特征查询都是使用存储引擎对应的client来查询,不同引擎查询方法都不一致,这里我们使用Dolphin SQL屏蔽底层查询引擎,使用统一的SQL语法查询,不仅降低开发成本,还让特征debug调试更简单,调试完的SQL可以直接在线上使用。
很多场景都存在实时特征和离线特征一起作为请求入参,一般都是分别查询实时和离线特征再拼接,为提升效率,Dolphin SQL支持在SQL查询就可以让实时特征和离线特征join实现参数拼接,极大提升开发效率。
SELECT a.id, a.action_list, b.city, b.level
FROM realtime_feature_table a
JOIN offline_feature_table b ON a.id = b.id4.3.2 作业调度
Dolphin Streaming通过openApi进行作业进行调度运维,包括:
作业创建、执行计划生成、作业启动
作业停止、作业暂停、作业状态查询
4.3.4 Debug功能
传统使用Flink debug都是写一个job打印数据记录,需要写一个完整的job,效率较低。为了让用户debug更简单支持用户使用select语句探查实时数据源表,进行快速ETL开发,无需提前定义上游源数据,相较Flink非常高效。
5. 应用示例
作为整体端到端方案,我们实现极光开发平台打通Dolphin Streaming能力,可以直接在极光开发平台(极光是阿里妈妈商家端数据开发平台)进行数据管理、实时作业开发、debug调试及运维管理,让实时数据问题在这里一站式解决。
5.1 数据开发
用户直接基于上游中间层实时数据进行开发,定义好输入输出源,然后定义计算逻辑即可,上游TT的subId,accessId,accessKey信息都在SQL转译阶段生成,用户无感知,下游存储表信息也都是自动创建和生成。

5.2 特征数据查询
开发好特征数据之后可以直接查询实时结果,验证计算逻辑,如果没问题该查询SQL可以在线上直接查询Dolphin使用。

5.3 数据探查
当上游TT表已经提前注册好,直接像数据库一样select查询表就可以实时获取探查结果,在数据debug,数据探查方面非常实用高效。

6. 业务收益
Dolphin Streaming支撑商家端算法实时特征开发,包括阿里妈妈直通车、引力魔方成效预估及如意货品推荐等场景,已取得显著收益。
支持客增如意货品推荐服务顺利经历本次双十一大促考验,通过对客户行为序列的精细化兴趣建模,应用到5+场景,实现拉新、活跃和新建计划客户数增长显著,整体实时特征在线查询QPS达到6000+,实现Dolphin引擎查询业务量翻倍增长。
通过引入实时广告效果数据,支持万相台MCB、千牛小程序及直通车智能计划等3+场景成效预估,其中万相台MCB带来cost及ARPU值显著提升。
7. 总结
在大规模实时场景,数据开发需要专业的工程技术同学支持,优势是可以达到极致性能;但在大多数普通规模实时场景中,如何简单高效的开发、迭代、测试和上线是业务方更关注的因素。
通过Dolphin Streaming提供面向算法等非工程同学的实时开发DB for Streaming解决方案,实现从数据获取、特征开发到特征上线整个流程一体化完成,在广告商家端算法场景不仅节省了算法到工程之间的沟通时间,还降低了开发人力成本,让业务迭代效率更高,实现规模化提升实时研发效能。
用户使用越简单,关心的内容越少,越是需要背后大量的用户理解和研发工作,未来我们会继续以用户体验和研发效能为中心,用技术提升商家经营增长。
附阿里妈妈工程平台智能分析引擎团队系列文章,欢迎阅读交流~
阿里妈妈Dolphin分布式向量召回技术详解
FAE:阿里妈妈归因分析与用户增长分析引擎
面向数智营销的 AI FAAS 解决方案
END

关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~