Zendesk 是一家 SaaS 公司,该公司以简单为本,专注于开发面向所有人的支持、销售和客户参与软件。通过帮助全球超过 17 万家公司高效地为数亿客户提供服务,该公司得以蓬勃发展。Zendcaesk 的机器学习团队负责提升客户体验团队,使其实现最佳绩效。通过将数据和人员的力量结合起来,Zendesk 开发出了多种智能产品,这些产品可以自动化手动工作,从而提高客户的工作效率。
自 2015 年以来,Zendesk 一直在构件机器学习产品,包括 Answer Bot、满意度预测(Satisfaction Prediction)、内容提示(Content Cues)、建议宏(Suggested Macros)等。在过去的几年中,随着深度学习(尤其是 NLP)的发展,他们看到了很多自动化工作流的机会,并帮助座席使用 Zendesk 解决方案为客户提供支持。Zendesk 目前使用 TensorFlow 和 PyTorch 构建深度学习模型。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
像 Zendesk 这样的客户已经在 Amazon Web Services(Amazon)上成功建立了大规模的软件即服务(SaaS, Software as a Service)业务。成功的 SaaS 业务模式的一个关键驱动因素是能够在应用程序和基础设施中应用多租户。这将提高成本效率和运维效率,因为应用程序只需构建一次,但可供多次使用,并且可以共享基础设施。我们发现许多客户在 Amazon 的堆栈的所有层(从计算、存储、数据库到联网)上构建了安全、经济高效的多租户系统,并且目前我们发现客户需要将该系统应用于机器学习(ML,Machine Learning)。
在模型重用和超个性化之间做出艰难的权衡
SaaS 业务的多租户通常意味着将在多个用户(SaaS 客户)之间重用单个应用程序。这既实现了成本效率,又降低了运营开销。不过,有时需要对机器学习模型进行个性化设置,使其达到高度的特异性(超个性化),才能做出准确的预测。这意味着,如果模型具有特异性,则“一次构建,多次使用” 的 SaaS 范式不能总是应用于 ML。以客户支持平台的使用案例为例。用户在支持票证中包含的语言会有所不同,具体取决于是拼车问题(“乘车时间太长”)还是服装购买问题(“洗后变色”)。在这个使用案例中,要提高预测最佳补救措施的准确性,可能需要在特定于业务领域或垂直行业的数据集上训练自然语言处理(NLP,Natural Language Processing)模型。Zendesk 在其解决方案中尝试利用 ML 时就遇到了这一挑战。他们需要创建数千个高度定制的 ML 模型,每个模型都是为特定客户量身定制的。为了经济高效地应对部署数千个模型这一挑战,Zendesk 转而使用 Amazon SageMaker。
在本博文中,我们将说明如何使用 Amazon SageMaker(一种完全托管式机器学习服务)的一些新功能来构建多租户 ML 推理功能。我们还分享了一个实际例子,说明 Zendesk 如何通过在 ML 模型中支持超个性化与使用 SageMaker 多模型端点(MME,Multi-Model Endpoint)来经济高效地共用基础设施之间部署一个良好的媒介,成功实现相同的结果。
SageMaker 多模型端点
借助 SageMaker 多模型端点,您可以在可能包含一个或多个实例的单个推理端点后面部署多个模型。每个实例均设计为加载和支持多个模型,直至达到其内存和 CPU 容量。利用此架构,SaaS 业务可以中断托管多个模型的成本的线性增长情况,并实现与应用程序堆栈中的其他位置应用的多租户模式一致的基础设施的重用。
下图展示了 SageMaker 多模型端点的架构。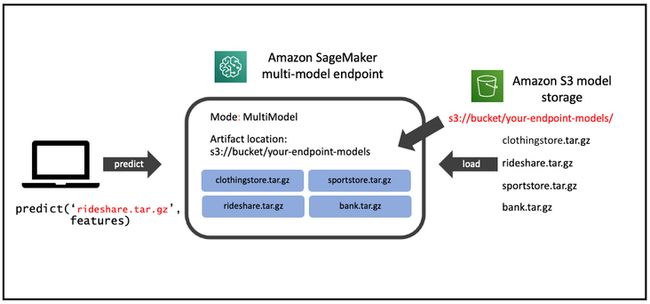
SageMaker 多模型端点在被调用时会从 Amazon Simple Storage Service(Amazon S3)动态加载模型,而不是在首次创建端点时下载所有模型。因此,初次调用模型的推理延迟可能高于后续推理,这些后续推理以低延迟完成。如果模型在调用时已加载到容器中,则可以跳过下载步骤,模型将以低延迟返回推理。例如,假设您有一个一天只使用几次的模型。它根据需要自动加载,而频繁访问的模型则保留的内存中,并以一贯的低延迟调用。
让我们仔细看看 Zendesk 如何使用 SageMaker MME 通过其建议宏(Suggested Macros)ML 功能来实现经济高效的超大规模 ML 部署。
为什么 Zendesk 构建超个性化模型
Zendesk 的客户遍布全球不同的垂直行业,使用不同的支持票证语义。因此,为了向客户提供最出色的服务,他们通常必须构建个性化模型,这些模型将根据客户特定的支持票证数据进行训练,从而正确识别意图、宏等。
2021 年 10 月,他们发布了一项新的 NLP ML 功能,即建议宏(Suggested Macros),此功能根据数千个客户特定的模型预测来推荐宏(预定义的操作)。Zendesk 的 ML 团队构建了一个基于 TensorFlow 的 NLP 分类器模型,该模型已根据每个客户以前的票证内容和宏历史记录进行训练。利用这些模型,可以在座席查看票证时建议宏预测(如以下屏幕截图所示),这可帮助座席快速为客户提供服务。由于宏特定于客户,因此 Zendesk 需要客户特定的模型来提供准确的预测。

Zendesk 的建议宏(Suggested Macros)揭秘
建议宏(Suggested Macros)模型是基于 NLP 的神经网络,大小约为 7 – 15 MB。主要挑战是通过经济高效、可靠且可扩展的解决方案将其中的数千个模型投入生产。
每个模型都有不同的流量模式,每秒最少有两个请求,峰值为每秒数百个请求,当模型在内存中可用时,每天提供数百万个预测,并且模型延迟约为 100 毫秒。SageMaker 端点部署在多个 Amazon 区域中,每个端点每分钟处理数千个请求。
SageMaker 能够在单个端点上托管多个模型,与为每个客户部署单一模型端点相比,它帮助 Zendesk 减少了部署开销并创建了一个经济高效的解决方案。这里的权衡方式是减少对每个模型管理的控制;而这正是 Zendesk 与 Amazon 合作以改进多模型端点的领域。
SageMaker 的多模型功能之一是延迟加载模型,即模型在首次被调用时就加载到内存中。这是为了优化内存利用率;但它会导致首次加载时出现响应时间峰值,可以将此情况视为冷启动问题。对于建议宏(Suggested Macros)来说,这是一个难题;但是,Zendesk 解决了这个难题,方式是基于 SageMaker 端点预置实施预加载功能,从而在提供生产流量之前将模型加载到内存中。其次,MME 会从内存中卸载不常用的模型,因此,为了在所有模型上实现一致的低延迟,并避免“嘈杂的邻居”影响其他不太活跃的模型,Zendesk 正在与 Amazon 合作来增加新功能(在本博文到后面将讨论)以实现更明确的每模型管理。另外,作为一个临时解决方案,Zendesk 合理精简了 MME 实例集,以最大限度地减少过量模型卸载。这样一来,Zendesk 便能够以低延迟(约 100 毫秒)为所有客户提供预测,与专用端点相比,仍能节省 90% 的成本。
在合理精简的 MME 上,Zendesk 在负载测试期间观察到,在 MME 后面有较多的小型实例(偏向于水平扩展)优于拥有较少的大型内存实例(垂直扩展)。Zendesk 发现,无法顺利地在单个大型内存实例上打包太多模型(超过 500 个 TensorFlow 模型),因为内存并不是实例上唯一可能成为瓶颈的资源。更具体地说,他们发现 TensorFlow 为每个模型产生了多个线程(实例 vCPU 总数的 3 倍),因此,在单个实例上加载超过 500 个模型会导致在实例上产生的线程的最大数目违反内核级别限制。有关使用更少的大型实例的另一个问题会是 Zendesk 在 MME 后面的某些实例上遇到限制(作为一种安全机制)是出现,因为每秒唯一模型调用速率超过了多模型服务器(MMS,Multi Model Server)可以在单个实例上安全处理而不关闭实例的速率。这是通过使用更多小型实例解决的另一个问题。
从作为任何生产应用程序的关键组成部分的可观察性角度来看,Amazon CloudWatch 指标(例如,调用、CPU、内存利用率)和特定于多模型的指标(例如,内存中加载的模型、模型加载时间、模型加载等待时间和模型缓存命中)都能提供有用的信息。具体来说,模型延迟细分有助于 Zendesk 了解冷启动问题及其影响。
MME 自动扩展功能揭秘
每个多模型端点后面都有模型托管实例,如下图所示。这些实例根据模型的流量模式在内存中加载和移出多个模型。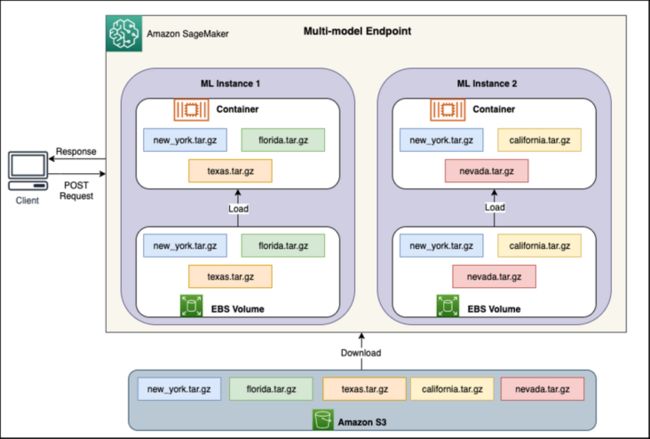
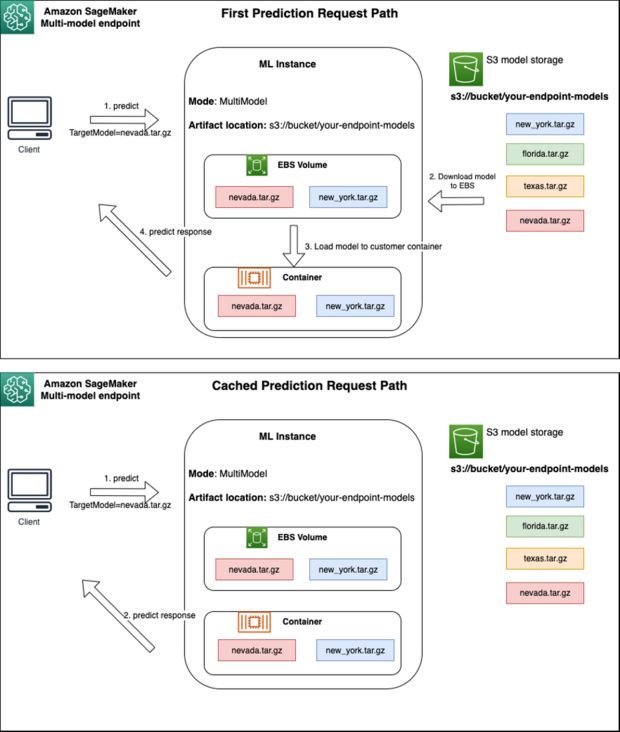
SageMaker 仍将模型的推理请求路由到已加载模型的实例,以便从缓存的模型副本中处理请求(参见下图,其中比较了第一个预测请求的请求路径与缓存的预测请求路径)。不过,如果模型收到许多调用请求,并且多模型端点还有其他实例,则 SageMaker 会将一些请求路由到另一个实例以适应增加的请求。要利用 SageMaker 中的自动模型扩展功能,请确保将设置实例自动扩展以预置额外的实例容量。使用自定义参数或每分钟调用次数(推荐)设置端点级别扩展策略,以便向端点实例集添加更多实例。
最适合 MME 的使用案例
SageMaker 多模型端点非常适合托管大量类似的模型,您可以通过共享服务容器提供这些模型,并且不需要同时访问所有模型。MME 最适合大小和调用延迟类似的模型。模型大小发生一些变化是可以接受的;例如,Zendesk 模型的大小在 10-50 Mb 之间变化是可以接受的,但大小的变化超过了 10 倍、50 倍或 100 倍就不合适了。大型模型可能会导致小型模型的加载和卸载次数更多,以容纳足够的内存空间,这可能会导致端点上的延迟增加。大型模型的性能特性差异也可能会不均匀地消耗 CPU 等资源,从而影响实例上的其他模型。
MME 也为使用相同 ML 框架的共同托管模型而设计,因为它们使用共享容器来加载多个模型。因此,如果您的模型实例集中混合了 ML 框架(例如 PyTorch 和 TensorFlow),则 SageMaker 专用端点或多容器托管是更好的选择。最后,MME 适用于能够容忍偶尔的冷启动延迟损失的应用程序,因为可以卸载不常使用的模型来支持频繁调用的模型。如果您有大量不常访问的模型,则多模型端点可以高效服务这些流量,并实现显著的成本节省。
总结
在本博文中,您已了解 SaaS 和多租户与 ML 的关系,以及 SageMaker 多模型端点如何实现 ML 推理的多租户和成本效率。您已了解 Zendesk 的每客户 ML 模型的多租户使用案例,以及他们如何在 SageMaker MME 中为其建议宏(Suggested Macros)功能托管数千个 ML 模型,并实现 90% 的推理成本节省(与专用端点相比)。超个性化使用案例可能需要数千个 ML 模型,对于这个使用案例而言,MME 是经济高效的选择。我们将继续增强 MME,使您能够以低延迟托管模型,并针对每个个性化模型提供更加精细的控制。要开始使用 MME,请参阅在一个端点后面的一个容器中托管多个模型。
关于作者

Syed Jaffry 是 Amazon 的高级解决方案构架师。他与许多公司合作(从中型企业到大型企业,从金融服务公司到独立软件开发商),帮助他们在云端构建和运营安全、有弹性、可扩展和高性能的应用程序。

**
Sowmya Manusani** 是 Zendesk 的高级员工机器学习工程师。她致力于生产基于 NLP 的机器学习功能,这些功能旨在提高数千名 Zendesk 企业客户的座席的工作效率。她在为数千个个性化模型构建自动训练管道以及使用安全、有弹性、可扩展和高性能的应用程序为这些模型服务方面拥有丰富的经验。闲暇时,她喜欢解谜和尝试绘画。

Saurabh Trikande 是 Amazon SageMaker Inference 的高级产品经理。他对与客户打交道和使机器学习更加浅显易懂很感兴趣。业余时间,Saurabh 喜欢徒步旅行、学习创新性技术、关注 TechCrunch 和陪伴家人。

Deepti Ragha 是 Amazon SageMaker 团队中的软件开发工程师。她目前的工作重点是构建用于高效托管机器学习模型的功能。业余时间,她喜欢旅行、远足和种植植物。
文章来源:https://dev.amazoncloud.cn/column/article/63098a79d4155422a46...