JAVA性能优化实例
目录
概述
Sql性能优化
多线程
利用内存缓存
功能优化
参考博客
概述
性能优化的几个点,大致可以分为:
- sql优化
- 使用多线程
- 利用内存,缓存等,将固定不常更改的数据放入在,存取更快的内存当中
- 功能实现逻辑优化
Sql性能优化
1、在需要接口性能优化的查询逻辑上,尽可能查询少的字段,减少sql耗时
这个就不再赘述了,尽量不使用*这样的查询在具体的业务逻辑中。
2、使用索引
使用索引,应该遵循以下几个原则:
- 使用尽可能简单的字段作为索引(因为小的字段在内存或者缓存当中处理都会更快,通常情况下,int,bight比string更适合作为索引列)
- 要避免索引所在的列有null,可以使用0或者其他字符代替(因为null会使索引的统计变得复杂)
- 组合索引需要考虑顺序问题(例如小A叫张三,直接通过张三去找小A,就可能出现全国十几万个张三,所以就会导致索引失效,应该是张三属于哪个国家,省份,城市,地区,类似于一个B-tree树,不能直接查找子节点,从根节点开始)
具体索引优化示例
select id,tablefield,langid,delete_type,fieldvalue
from bcw_area_multilineset
where tablefield = 'area_name'
and delete_type = 0
and langid = 7例如上述sql,所创建的索引应该尽量是langid ,delete_type而不是fieldvalue这种类型的。
索引的顺序为:
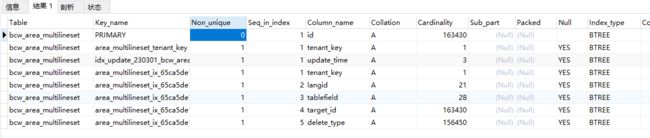
到了索引顺序的问题了,上述sql的索引是失效的,问题就是索引是一个B-Tree树,需要从根节点开始查询,不能直接从子节点开始,且不能跳过节点。
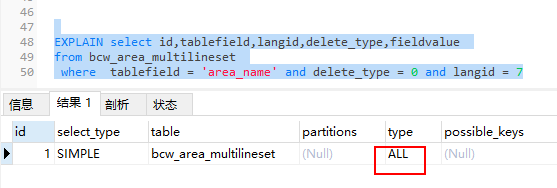
优化后的sql
select id,tablefield,langid,delete_type,fieldvalue,target_id
from
bcw_area_multilineset
where tenant_key = 'tyvmef1s3f' //增加的首列
and langid = 7 //调整顺序的次列
and tablefield = 'area_name'
and delete_type = 0
除此之外还有聚簇索引最好设置主键id这样的优化,or会导致索引失效,问题的点很多,使用explain排查,大多数情况下使用到了索引,性能都不会太差。
多线程
多线程适合:
- for循环批量处理数据的时候。
- 或者可以同步执行但不互相影响结果的步骤中。
例如下面的方法会执行很多次replace方法,replace有很多执行逻辑,如果改为并发执行,开启10个线程,理论上速度直接提高10倍。
if (CollUtil.isNotEmpty(areas)) {
for (AdministrativeArea area : areas){
replaceTree(area,langId);
}修改后多线程(这里使用线程池创建多线程会更好,也能够根据需要处理数据的量来动态规划线程的数量)
if (CollUtil.isNotEmpty(areas)) {
for (AdministrativeArea area : areas){
new Thread(() -> {
replaceTree(area,langId);
}).start();
}
至于可以同步执行的代码,通常情况下,在一个方法中封装了3-5个,甚至更多的方法,但是最后的结果需要合并到一起的,这样的也适合使用多线程。
利用内存缓存
内存通常可以存储多一些数据,缓存则一般都是存储常取长存的数据。这类的查询会比IO要快。
缓存的使用
例如有一个拦截器,这个拦截器对此进行权限的校验,每次接口请求都会走到拦截器当中,有可能一次加载页面,就走5-6次接口,这时候利用缓存,将暂时通过的结果缓存起来,设置一个较少的过期时间,这样就避免了大量的重复校验。
如下述示例:
if (requestUrl.contains("update") || requestUrl.contains("add") || requestUrl.contains("bathDelete")
|| requestUrl.contains("uploadIcon")|| requestUrl.contains("Update") || requestUrl.contains("uploadMoveIcon")){
//命中缓存不走rpc
if (ObjectUtils.nullSafeEquals(baseCache.get(CACHE_MODULE,UPDATE_PERMISSION),"true")){
baseCache.set(CACHE_MODULE,UPDATE_PERMISSION,"true",2);
return true;
}
boolean hasPermission = iconPermissionService.hasPermission(728679126513090562L,"1",UserContext.getCurrentEmployeeId(), TenantContext.getCurrentTenantKey());
if (hasPermission) {
baseCache.set(CACHE_MODULE,UPDATE_PERMISSION,"true",2);
return true;
}
}内存的使用
内存的使用一般情况下是存储,量比较大,但不常变动的数据。
例如级联选择城市的业务中,会有很多默认的业务数据,例如全国各地的城市,这类的数据一般情况下不会变动,每次去数据库查询会导致接口很慢,但是量又比较大,不适合存储在缓存中,这样的就比较适合使用内存。
但是内存的使用需要关注内存的占用量,具体如jprofilter这样的检查具体的占用内存量。
例如微服务项目启动时就把数据加载到内存当中。
@Slf4j
@Component
public class testRunner implements ApplicationRunner {
@Autowired
private testdao dao;
@Override
public void run(ApplicationArguments args) {
try {
cacheManager.setDefaultData(dao.queryDefault());
);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}功能优化
功能优化的点比较多,大致有:
- 减少IO流交互,数据库交互。
- 能放在sql当中执行的逻辑一般要比JAVA代码快。
性能优化的方面很多,这里只是记录一些。后续待补充。
参考博客
sql索引