re.findall获取CSDN博文阅读点赞收藏和评论实时数据
学用curl命令获取博文页面源码,学不会爬虫先用re.findall手剥CSDN博文阅读点赞收藏和评论实时数据。
-
Python 官网:https://www.python.org/
-
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
地址:https://lqpybook.readthedocs.io/
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
- My CSDN主页、My HOT博、My Python 学习个人备忘录
- 好文力荐、 老齐教室

本文质量分:
CSDN质量分查询入口:http://www.csdn.net/qc
- ◆批量收集CSDN博文阅读量
-
- 1、curl url > filename
-
- 1.1 保存获取页面源码文本
- 1.2 将源码文本读入内存
- 2、抽丝剥茧
-
- 2.1 re.findall剥离CSDN博文阅读点赞等数据
- 2.2 格式化输出
- 2.3 打开网页报错拦截
- 3、测试的Url
-
- 3.1 测试url的csv文本
- 3.2 佬的文章
- 3.3 异常地址
- 3.4 我的笔记
- 4、期望即将兑付
- 5、源码
◆批量收集CSDN博文阅读量
1、curl url > filename
在C站闲逛的时候,偶然拾得Linux页面源码获取指令“curl”,可以用“>”指令将获取到的页面源码写入磁盘文件。
1.1 保存获取页面源码文本
Linux命令行
curl url > filename
filename 文件存储路径,最好用相对路径(我用绝对路径是方便我在python安装目录下执行python .py程序),在Linux下cd到代码.py和csdn_get_bloghtml.txt同在的目录,python *.py执行程序。
python代码(用os.system()执行Linux命令行指令)
os.system(f"curl {url} > /sdcard/Documents/csdn_get_bloghtml.txt")
代码用os模块的system方法执行Linux命令行命令,将curl获取的CSDN博文页面源码,保存到磁盘。(关于os.system 方法执行系统命令行指令,我之前写过一篇学习笔记“Python的系统命令行指令容器”,可以点击蓝色文字跳转翻阅)
1.2 将源码文本读入内存
用变量text_html接收从磁盘文本文件读取的博文页面源码字符串。
with open('/sdcard/Documents/csdn_get_bloghtml.txt') as f:
text_html = f.read()
2、抽丝剥茧
2.1 re.findall剥离CSDN博文阅读点赞等数据

为避免笔记不过审,代码上截屏图片,屏蔽了re条件表达式源码。完成源码已上传CSDN文库,可以从我的CSDN主页进入资源列表查阅。
2.2 格式化输出
获取的博文信息数据,用python 最新格式化方法“插值字符串格式化”做个输出模块,一条print() or input() 格式化输出。(我之前有写过类自然语言的“插值字符串格式化”学习笔记,可以点击蓝色文字跳转康康)
效果截屏图片

调用函数,从博文源码字符串提取博文信息,参数text_html是curl抓取的博文源码。
blog_info = get_article_info(text_html) # 调用函数,从博文源码提取信息。
print('\n'.join(blog_info)) # 打印当前博文信息。
2.3 打开网页报错拦截
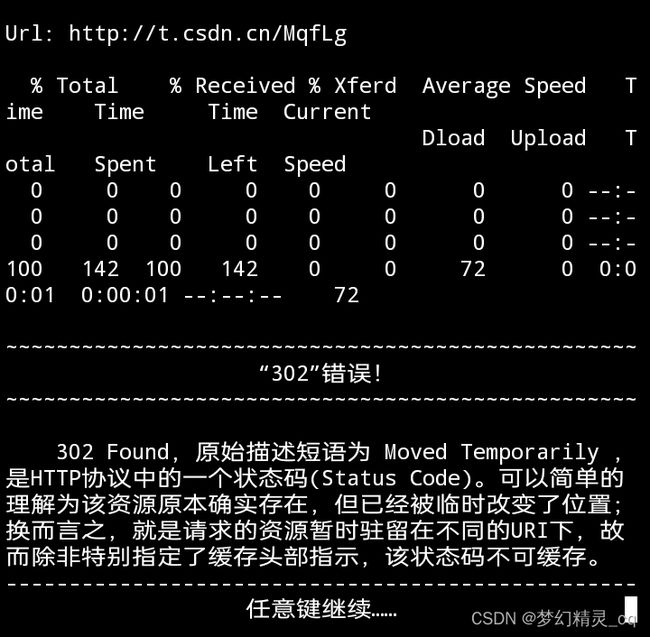
- “302”报错码
302 Found,原始描述短语为 Moved Temporarily ,是HTTP协议中的一个状态码(Status Code)。可以简单的理解为该资源原本确实存在,但已经被临时改变了位置;换而言之,就是请求的资源暂时驻留在不同的URI下,故而除非特别指定了缓存头部指示,该状态码不可缓存。
- “404”报错码
404,是一种HTTP状态码,指网页或文件未找到。\n\n{’’:>4}HTTP 404或Not Found错误信息是HTTP的其中一种“标准回应信息”(HTTP状态码),此信息代表客户端在浏览网页时,服务器无法正常提供信息,或是服务器无法回应且不知原因。
- 无效Url报错
无效地址报错。比如空白字符串’’、’ '。
错误代码捕捉代码
def html_error(text_html):
''' 获取博文页面源码错误提示 '''
if not text_html: # 获取博文页面源码为空。
tip = f"{'':>13}请核查Url拼写是否正确!"
input(f"\n{'':~^50}\n{' Url错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
else:
flag = ''.join(re.findall(r'\d+', text_html))[:3]
# 找不至网页报错。
if flag == '302' :
tip = f"{'':>4}302 Found,原始描述短语为 Moved Temporarily ,是HTTP协议中的一个状态码(Status Code)。可以简单的理解为该资源原本确实存在,但已经被临时改变了位置;换而言之,就是请求的资源暂时驻留在不同的URI下,故而除非特别指定了缓存头部指示,该状态码不可缓存。"
input(f"\n{'':~^50}\n{' “302”错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
elif flag == '404' :
tip = f"\n{'':>4}404,是一种HTTP状态码,指网页或文件未找到。\n\n{'':>4}HTTP 404或Not Found错误信息是HTTP的其中一种“标准回应信息”(HTTP状态码),此信息代表客户端在浏览网页时,服务器无法正常提供信息,或是服务器无法回应且不知原因。"
input(f"\n{'':~^50}\n{' “404”错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
return True # 正常获取博文页面源码,返回真。
报错截屏图片
“302”错误(CSDN博文分享地址)

“404”错误(故意把地址漏写一个字符)

空字符串地址错误(用空白’ '字符,测试代码容错能力)

3、测试的Url
3.1 测试url的csv文本
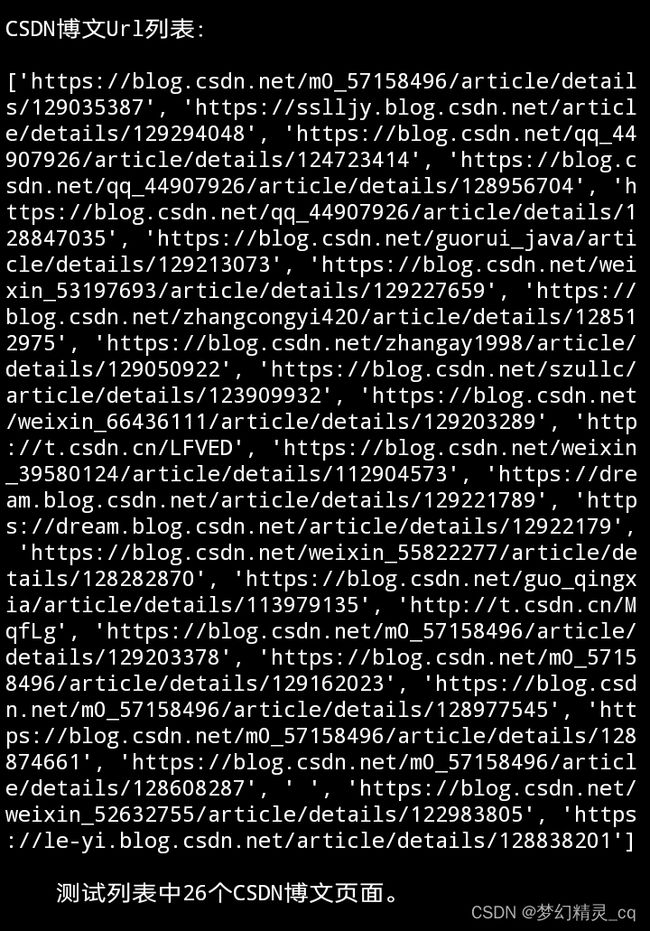
保存到磁盘的CSV文本文件

测试博文地址csv文本内容
Url\Title\Url_type
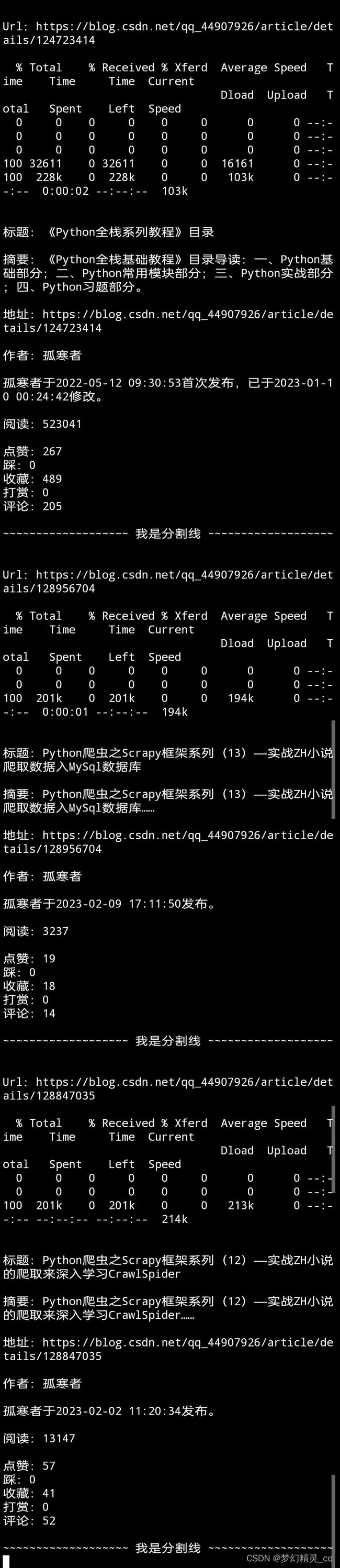
https://blog.csdn.net/qq_44907926/article/details/124723414\《Python全栈系列教程》目录\博文原始地址
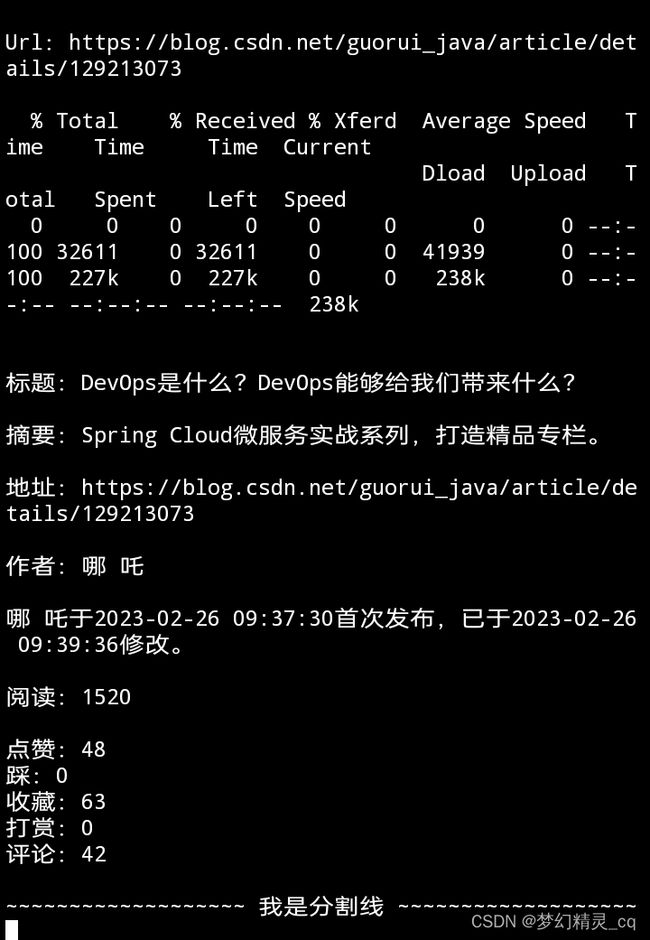
https://blog.csdn.net/qq_44907926/article/details/128956704\小说爬取数据入MySql\博文原始地址
https://blog.csdn.net/qq_44907926/article/details/128847035\小说爬取来深入学习CrawlSpider\博文原始地址
…
https://dream.blog.csdn.net/article/details/12922179\ \故意写错地址
https://blog.csdn.net/weixin_55822277/article/details/128282870\Python编程零基础如何逆袭成为爬虫实战高手之《WIFI破解》(甩万能钥匙十条街)爆赞爆赞\博文原始地址
…
\空白地址(一个英文空格)\检验程序健壮用
https://blog.csdn.net/weixin_52632755/article/details/122983805\【C语言】一篇速通结构体\博文原始地址
https://le-yi.blog.csdn.net/article/details/128838201\解数独\博文原始地址
~~~~~为不占篇幅,仅列显csv文档部分Url~~~~~
(程序试炼效果截屏图片较长,点此跳过)
3.2 佬的文章
寒佬
叔叔佬

哪 咤佬
呆呆佬

李肯佬
wlz249佬

龙佬
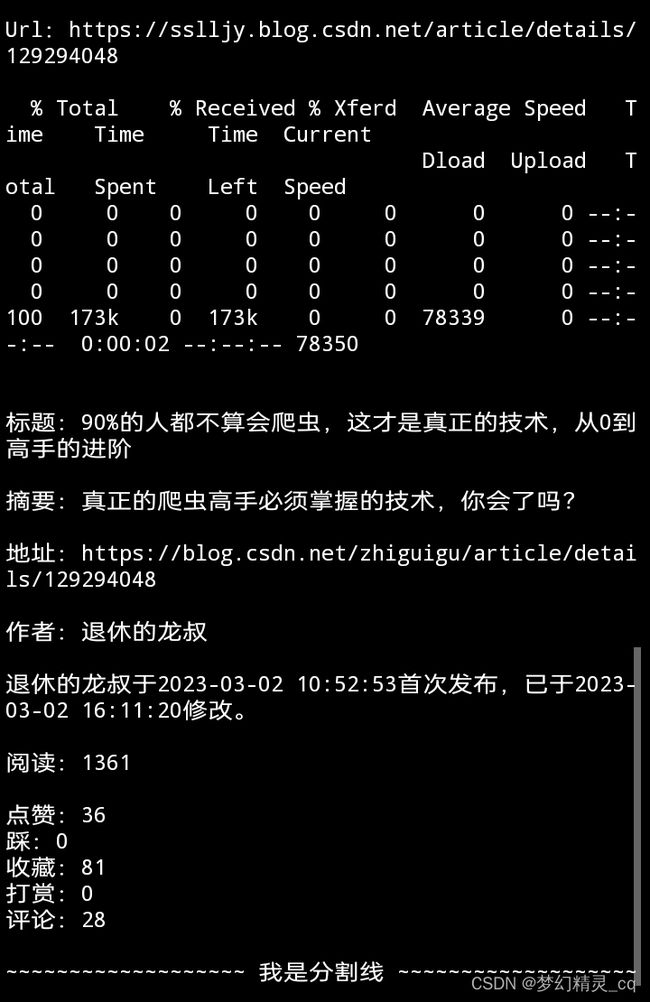
茅佬
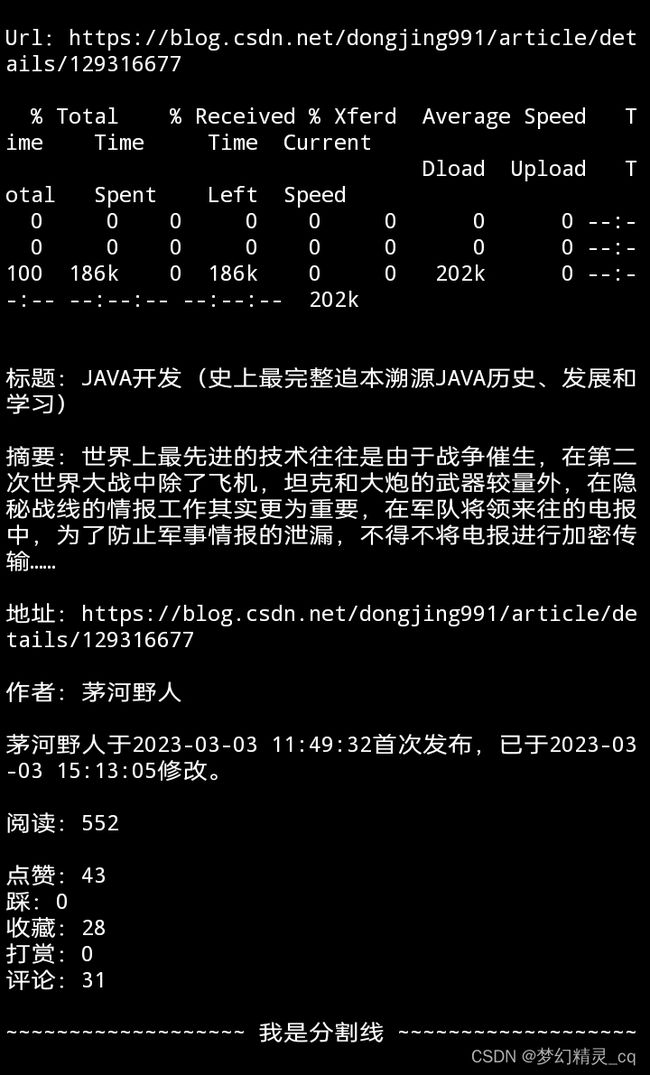
橡皮擦佬

木子佬
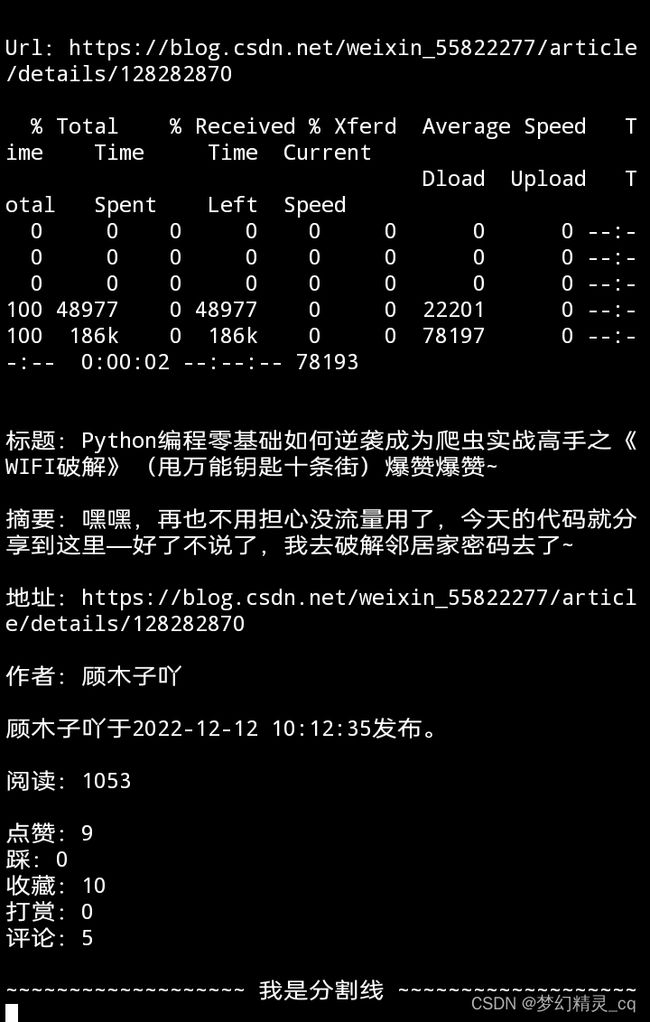
二当家佬

謓泽佬

码银佬

nee~
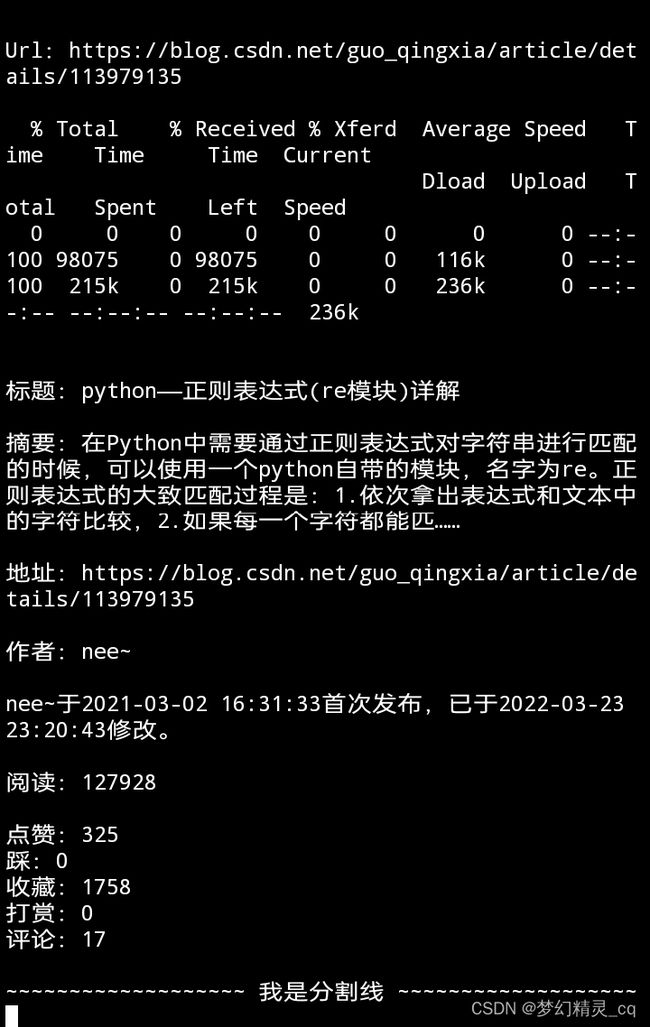
weixin_39580124
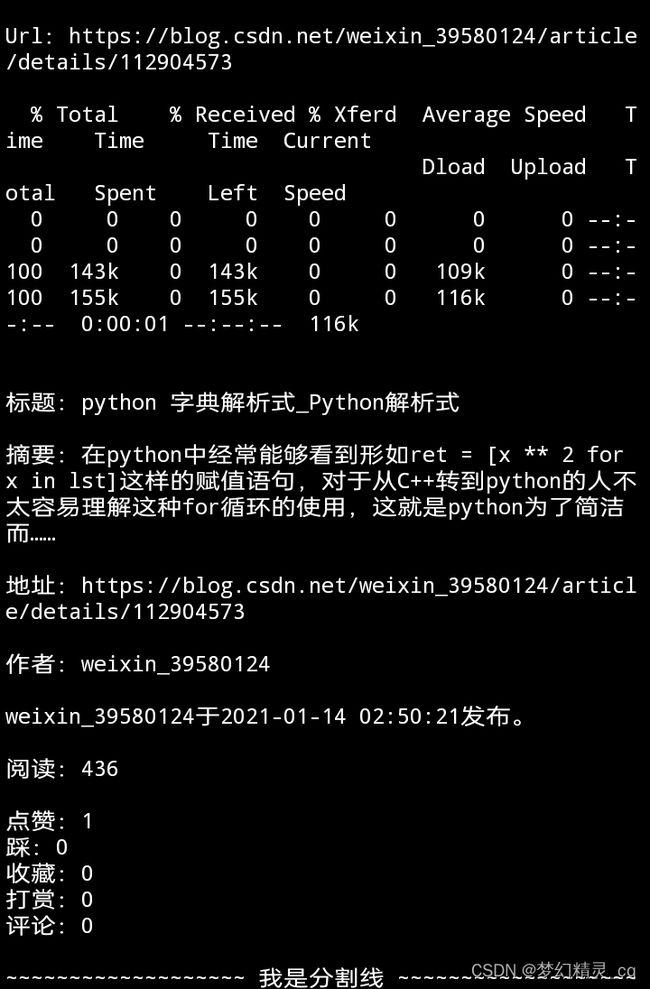
3.3 异常地址
CSDN博文分享地址

故意写错地址

空白字符’ '地址

被下架的关于ChatGPT的博文地址(失效地址)

3.4 我的笔记

4、期望即将兑付
我一直都有不定时统计CSDN博文笔记阅读量,从大家的认可度来衡量我对“知识点”的识记程度和“输入→输出”的转化率,以此来“自我肯定”。
当笔记记得多了,一条条查阅,也是件费神的事儿。老想要“自动”,但以我目前的水准,总看不懂爬虫,无法践行。经过对笔记页面源码“手撕”,让我看到了“自动”的希望。
5、源码
为避免笔记不过审,贴出的源码略去了re提取博文信息数据的表达式。完整源码已传CSDN资源文库,有需要可以点击我的主页进入资源列表页面查阅。
(源码较长,点此跳过源码)
#!/sur/bin/nve python
# coding: utf-8
import os
import re
def get_article_info(blog):
''' 提取CSDN博客文章访问量等信息,返回各项信息格式化字符串元组 '''
blog = text_html # 变量别名。
# re.findall方法提取各项信息。
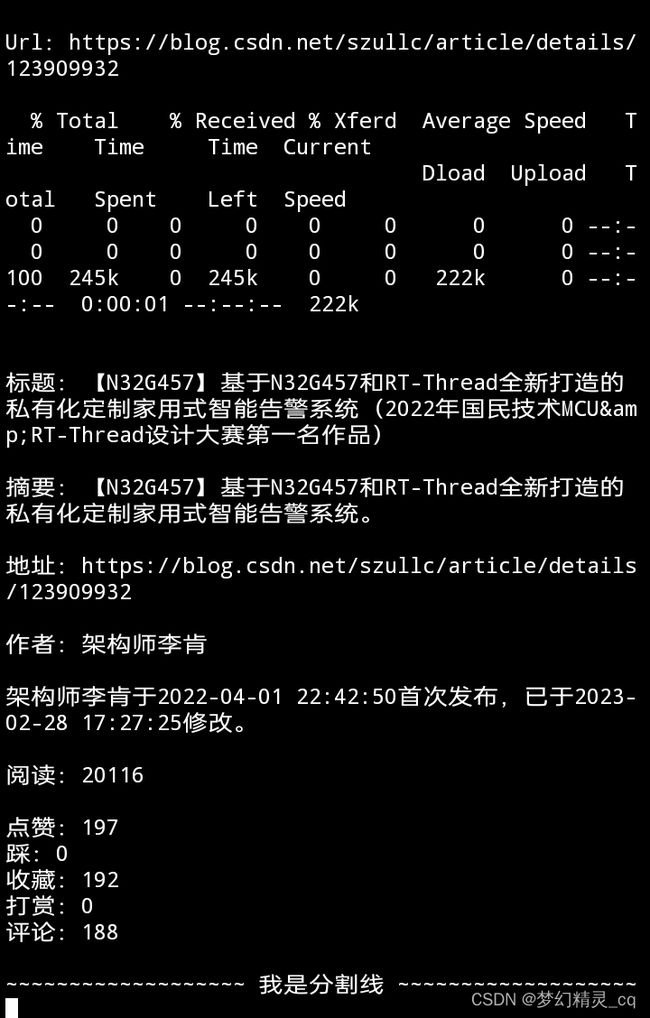
title = '\n\n标题:' + ''.join(re.findall(r'条件表达式略', text_html))
url = '\n地址:' + ''.join(re.findall(r'条件表达式略', text_html)).strip()
articleDesc = '\n摘要:' + ''.join(re.findall(r'条件表达式略', text_html))
if re.findall(r'\w', articleDesc[-1]): # 句末无标点,加句号。
articleDesc += '。'
nike = ''.join(re.findall(r'条件表达式略', text_html))
first = ''.join([''.join(i) for i in re.findall(r'条件表达式略', text_html)])
late = ''.join([''.join(i) for i in re.findall(r'条件表达式略', text_html)])
if first and late: # 拼接博文编辑信息。
edit = f"\n{nike}{first},{late}。"
elif first and not late:
edit = f"\n{nike}{first}。"
else:
edit = ''
read = '\n阅读:' + ''.join(re.findall(r'(\d+)', text_html))
active = re.findall(r'条件表达式略', text_html)
active = '\n' + '\n'.join([f"{y}:{x}" if x else f"{y}:0" for x,y in active]) # 格式化博文的点赞、踩、收藏、打赏、评论信息。
return title, articleDesc, url, '\n作者:' + nike, edit, read, active # 返回提取的信息数据元组。
def html_error(text_html):
''' 获取博文页面源码错误提示 '''
if not text_html: # 获取博文页面源码为空。
tip = f"{'':>13}请核查Url拼写是否正确!"
input(f"\n{'':~^50}\n{' Url错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
else:
flag = ''.join(re.findall(r'\d+', text_html))[:3]
# 找不至网页报错。
if flag == '302' :
tip = f"{'':>4}302 Found,原始描述短语为 Moved Temporarily ,是HTTP协议中的一个状态码(Status Code)。可以简单的理解为该资源原本确实存在,但已经被临时改变了位置;换而言之,就是请求的资源暂时驻留在不同的URI下,故而除非特别指定了缓存头部指示,该状态码不可缓存。"
input(f"\n{'':~^50}\n{' “302”错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
elif flag == '404' :
tip = f"\n{'':>4}404,是一种HTTP状态码,指网页或文件未找到。\n\n{'':>4}HTTP 404或Not Found错误信息是HTTP的其中一种“标准回应信息”(HTTP状态码),此信息代表客户端在浏览网页时,服务器无法正常提供信息,或是服务器无法回应且不知原因。"
input(f"\n{'':~^50}\n{' “404”错误!':^47}\n{'':~^50}\n\n{tip:>4}\n{'':-^50}\n{' 任意键继续…… ':^45}")
return
return True # 正常获取博文页面源码,返回真。
if __name__ == '__main__':
# ↓ 此为程序功用微调语句
with open('/sdcard/Documents/csdn_get_bloghtml.txt') as f:
text_html = f.read()
input(f"\n获取的博文信息元组:\n\n{get_article_info(text_html)}\n")
# ↑ 此为程序功用微调语句
# CSDN博文Url的csv文本文件存储路径。可以用相对路径,但一定要保证执行的py文件和保存CSDN博文Url的文本文件在同一目录,且要先cd到该目录再执行python *.py命令,启动捕获CSDN博文信息作业。
filename = '/sdcard/Documents/csdn_blogurl.txt'
# 从csv文本解析博文网址,打印从csv文本解析出的CSDN博文Url。
with open(filename) as f:
blogurl = [i.split('\\')[0] for i in f.read().split('\n')[1:]]
print(f"\nCSDN博文Url列表:\n\n{blogurl}\n\n{'测试列表中':9}{len(blogurl)}个CSDN博文页面。\n") # 打印CSDN博文Url列表。
for url in blogurl: # 遍历Url列表,依次捕获博文网页源码文本,保存到本地磁盘。
print(f"\nUrl:{url}\n")
os.system(f"curl {url} > /sdcard/Documents/csdn_get_bloghtml.txt")
with open('/sdcard/Documents/csdn_get_bloghtml.txt') as f: # 读取保存的博文页面源码文本。
text_html = f.read().split(r'"target="_blank">')[0]
if not html_error(text_html): # 获取博文页面源码查错。
continue
blog_info = get_article_info(text_html) # 调用函数,从博文源码提取信息。
#input(f"\n获取的博文信息元组:\n\n{blog_info}\n") # 程序功用微调语句。
print('\n'.join(blog_info)) # 打印当前博文信息。
print(f"\n{' 我是分割线 ':~^45}\n") # 分割线。
__上一篇:__ 我的零分周赛(CSDN周赛第30期,成绩“0”分,天然气定单、小艺读书、买苹果、圆桌)
__下一篇:__
我的HOT博:
- New:ChatGPT初体验(ChatGPT国内镜像站初体验,聊天、Python代码生成。)CSDN质量分92。(30687阅读)
- 尼姆游戏(彩色文字界面版,\033控制码实现。Linux系统有效。)CSDN质量分xx。(1001阅读)
- 神奇的 \033 ,让打印出彩(1739阅读)
- 小炼二维数组(1764阅读)
- 仿真模拟福彩双色球(2622阅读)
- Python之魔幻切片(1417阅读)
- 数列求和a, aa, aaa, ..., aa...aa(n个a)(1729阅读)
- 个人信息提取(2671阅读)
- 中文字符命名Python变量和函数(1021阅读)
- 我的Python学习笔记(1021阅读)
- 十六进制字符串转Python代码(utf-8字符串转十六进制字符串)(1319阅读)
- 生成100个随机正整数(2489阅读)
- 给定字符串提取姓名(字符串、list、re“零宽断言”)(1842阅读)
- 我的 Python.color() (Python 色彩打印控制)(2370阅读)
- python清屏(3150阅读)
- 回车符、换行符和回车换行符(3558阅读)
- Linux 脚本文件第一行的特殊注释符(井号和感叹号组合)的含义(2301阅读)
- random.sample()将在python 3.9x后续版本中被弃用(2045阅读)
- pandas 数据类型之 Series(1809阅读)
- 聊天消息敏感词屏蔽系统(字符串替换 str.replace(str1, *) )(2332阅读)
- 练习:银行复利计算(用 for 循环解一道初中小题)(2159阅读)
- pandas 数据类型之 DataFrame(5932阅读)
- 班里有人和我同生日难吗?(蒙特卡洛随机模拟法)(2921阅读)
- Python 续行符(\)“拯救”你的超长语句(1502阅读)
- Python字符串居中显示(4684阅读)
- 练习:求偶数和、阈值分割和求差( list 对象的两个基础小题)(2331阅读)
- 用 pandas 解一道小题(2268阅读)
- 可迭代对象和四个函数(1752阅读)
- “快乐数”判断(1847阅读)
- 罗马数字转换器(构造元素取模)(3157阅读)
- Hot:罗马数字(转换器|罗生成器)(5783阅读)
- Hot:让QQ群昵称色变的代码(49777阅读)
- Hot:斐波那契数列(递归| for )(4719阅读)
- 柱状图中最大矩形(2348阅读)
- 排序数组元素的重复起止(1964阅读)
- 电话拨号键盘字母组合(2170阅读)
- 密码强度检测器(3124阅读)
- 求列表平衡点(2498阅读)
- Hot:字符串统计(4581阅读)
- Hot:尼姆游戏(聪明版首发)(4135阅读)
- 尼姆游戏(优化版)(1968阅读)
推荐条件 点阅破千
回页首

精品文章:
- 好文力荐:齐伟书稿 《python 完全自学教程》 Free连载(已完稿并集结成书,还有PDF版本百度网盘永久分享,点击跳转免费下载。)
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
回页首
◆ Python 入门指南【Python 3.6.3】
好文力荐:
-
全栈领域优质创作者——寒佬(还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是学习的两大利器。
-
【8大编程语言的适用领域】先别着急选语言学编程,先看它们能干嘛
-
靠谱程序员的好习惯
CSDN实用技巧博文:
- 8个好用到爆的Python实用技巧
- python忽略警告
- Python代码编写规范
- Python的docstring规范(说明文档的规范写法)