IMDB数据集分类,使用EDA数据增强+CNN+LSTM
目录
一、介绍
二、数据收集与预处理
三、EDA数据增强
四、构建训练测试集和训练模型
五、所有代码(可直接跑通)
Bug:1.停用词stopwords不能使用
一、介绍
此项目仅供学习用,读者可随便修改。IMDB数据集文本分类的流程大致分为数据预处理、数据增强、模型训练、模型优化与评估以及模型应用等几个部分。
二、数据收集与预处理
1.IMDB数据集:一个常用的二分类电影评论数据集,分成文本和标签两个部分,包括50,000个电影评论,其中25,000个用于训练,25,000个用于测试。数据集示例如下:
text = "This movie was terrible, acting was bad, plot was predictable and overall just a bad movie."
label = "negative"2.数据集下载方式:
第一种:直接使用keras下载。其中,num_words参数用于控制用于构建词典的单词数量。在这里,我们将单词数量限制在了前10000个最常见的单词,以便对数据进行处理和训练。
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
第二种:直接从网址下Sentiment Analysis
3.数据预处理:预处理包括分词、去除停用词、转换大小写等动作。在对文本进行分词的时候可以采用tokenizer进行操作,此外还需要将文本转换为数字序列。这里主要是构建了词汇表和填充长度不够的样本。
# 构建词汇表
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(train_texts)
sequences = tokenizer.texts_to_sequences(train_texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
三、EDA数据增强
1.EDA:使用数据增强(EDA)方法,增加更多的文本样本。可以采用Synonym Replacement、Random Insertion、Random Swap、Random Deletion等方法进行数据增强。这里主要采用添加噪声的方式,噪声通常是指一些无关紧要或错误的内容,会影响到文本的语义,降低文本质量。
# EDA 添加噪声
def add_noise(text, noise):
text_tokens = re.findall(r"\b\w+\b", text)
result = []
# word:每句话的每个单词
for word in text_tokens:
# 判断当前词是否在noise中 如果不在且生成的随机数小于0.1,
# 其中生成的随机数的作用是为了控制噪声添加的概率,当生成的随机数小于0.1时,数据样本就有10%的概率添加噪声,可以通过调整这个随机数生成概率控制添加噪声的比例。
if word.lower() not in noise and np.random.uniform() < 0.2:
result.append(word)
return " ".join(result)
stop_words = set(stopwords.words('english'))
train_noise = []
# 添加噪声
for text in texts:
train_noise.append(add_noise(text, stop_words))
# 合并训练数据和增强数据
texts = texts + train_noise
labels = labels + labels
print("添加噪声完成!")四、构建训练测试集和训练模型
1.训练和测试集按照8:2分配
2.神经网络采用CNN和LSTM结合的模型,并在一开始使用Embedding进行操作,
# 构建CNN+LSTM模型
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=embedding_dim, input_length=maxlen))
model.add(Conv1D(filters=filters, kernel_size=kernel_size, padding='same', activation='relu'))
model.add(MaxPooling1D())
model.add(LSTM(hidden_dims))
model.add(Dense(2, activation='softmax'))
optimizer = Adam(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])3. 模型优化和评估。通过一系列优化方法对模型进行训练,如改变层数、改变词向量维度、调整学习率等等。使用交叉验证等方法对模型进行评估。可以使用准确率、精确率、召回率等指标来衡量模型的性能。
五、所有代码(可直接跑通)
需要修改imdb数据集的路径,可能模型的评估会有点问题,可以使用其他评估手段。
import os
import pandas as pd
import numpy as np
import random
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Conv1D, MaxPooling1D, LSTM, Dense, Dropout, Flatten
from keras.optimizers import adam_v2
# 设置随机种子
random.seed(1)
np.random.seed(1)
# 设置参数
maxlen = 100 # 句子的最大长度
embedding_dim = 300 # 词嵌入的维度
max_words = 10000 # 设定词汇表大小
filters = 256 # 卷积核个数
kernel_size = 3 # 卷积核长度
hidden_dims = 64 # 隐藏层神经元个数
batch_size = 128 # 批次
epochs = 10 # 迭代次数
# 测试样本
# texts = ["This movie was terrible, acting was bad, plot was predictable and overall just a bad movie.",
# "This movie is a masterpiece, the acting was superb, the story was captivating and kept me glued to my seat until the very end.",
# 'The acting in this movie was top-notch and the story kept me engaged from beginning to end.',
# 'I found this movie to be quite boring and the acting was very disappointing.',
# "This is definitely one of the best movies I've seen recently. The acting was phenomenal and the story was emotionally gripping.",
# 'I was really disappointed with this movie. The story was weak and the acting was subpar.',
# "This movie completely exceeded my expectations in every way possible. The acting was superb, the story was captivating",
# 'I found the story to be very cliched and the acting mediocre.',
# 'This movie was not what I expected at all. The story was convoluted and the acting was not great.',
# 'This is a must-see movie for anyone who loves great acting and a compelling story. I was on the edge of my seat the whole time.',
# 'The acting in this movie was terrible and the story was predictable. I would not recommend it.',
# "I was absolutely blown away by this movie. The acting was phenomenal and the story was both heartwarming and heartbreaking. "]
# labels = [0, 1,1,0,1,0,1,0,0,1,0,1]
# 加载数据集IMDB
def load_imdb_dataset():
imdb_dir = 'D:\\dataset_sum\\aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
texts = []
labels = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
with open(os.path.join(dir_name, fname), 'r', encoding='utf-8') as f:
texts.append(f.read())
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
return texts, labels
texts, labels = load_imdb_dataset()
print("加载数据完成!")
# EDA 添加噪声
def add_noise(text, noise):
text_tokens = re.findall(r"\b\w+\b", text)
result = []
# word:每句话的每个单词
for word in text_tokens:
# 判断当前词是否在noise中 如果不在且生成的随机数小于0.1,
# 其中生成的随机数的作用是为了控制噪声添加的概率,当生成的随机数小于0.1时,数据样本就有10%的概率添加噪声,可以通过调整这个随机数生成概率控制添加噪声的比例。
if word.lower() not in noise and np.random.uniform() < 0.2:
result.append(word)
return " ".join(result)
stop_words = set(stopwords.words('english'))
train_noise = []
# 添加噪声
for text in texts:
train_noise.append(add_noise(text, stop_words))
# 合并训练数据和增强数据
texts = texts + train_noise
labels = labels + labels
print("添加噪声完成!")
# 将训练和测试数据分成两个组
indices = np.arange(len(texts))
np.random.shuffle(indices)
texts = [texts[i] for i in indices]
labels = [labels[i] for i in indices]
num_validation_samples = int(0.2 * len(texts))
train_texts = texts[num_validation_samples:]
train_labels = labels[num_validation_samples:]
val_texts = texts[:num_validation_samples]
val_labels = labels[:num_validation_samples]
print('训练集数据数量:', len(train_texts))
print('测试集数据数量:', len(val_texts))
# 构建词汇表
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(train_texts)
sequences = tokenizer.texts_to_sequences(train_texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
# 训练集数据填充
train_sequences = pad_sequences(sequences, maxlen=maxlen)
train_labels = pd.get_dummies(train_labels).values
# 测试集数据填充
sequences = tokenizer.texts_to_sequences(val_texts)
val_sequences = pad_sequences(sequences, maxlen=maxlen)
val_labels = pd.get_dummies(val_labels).values
# 构建CNN+LSTM模型
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=embedding_dim, input_length=maxlen))
model.add(Conv1D(filters=filters, kernel_size=kernel_size, padding='same', activation='relu'))
model.add(MaxPooling1D())
model.add(LSTM(hidden_dims))
model.add(Dense(2, activation='softmax'))
optimizer = adam_v2.Adam(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
# 模型训练
history = model.fit(train_sequences, train_labels, batch_size=batch_size, epochs=epochs, validation_data=(val_sequences, val_labels))
# 模型评估
test_dir = os.path.join('aclImdb', 'test')
texts = []
labels = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(test_dir, label_type)
for fname in sorted(os.listdir(dir_name)):
if fname[-4:] == '.txt':
with open(os.path.join(dir_name, fname), 'r') as f:
texts.append(f.read())
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = pd.get_dummies(labels).values
score = model.evaluate(x_test, y_test, verbose=0)
print('\n测试损失:', score[0])
print('测试准确率:', score[1])Bug:1.停用词stopwords不能使用
方法一:直接在keras中运行代码。
import nltk
nltk.download('stopwords')如果出现以下问题,直接在最下面的路径中创建相同的文件夹即可。再运行上面的代码就可以了。最后会在创建的文件夹看见download的停用词包。
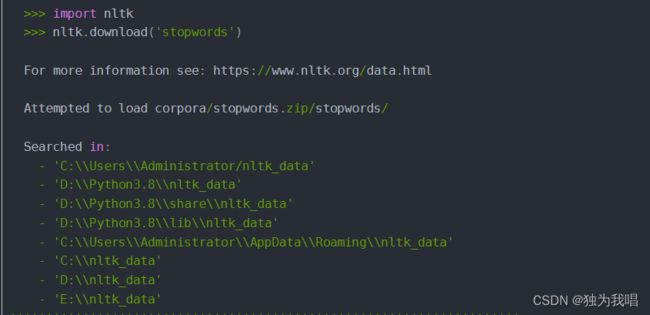
方法二:https://devpress.csdn.net/gitcode/64117dc8986c660f3cf92835.html