Redis cache-aside模型-分布式锁等问题研究
目录
1.Read模式:
1.布隆过滤器:缓存穿透
2.并发排他
3.小总结:
2.Write模式:双写一致性
3.Redis分布式锁:
4.Redis缓存存什么数据:
参考文章:
Cache-aside模型包括两种模式:read模式和write模式
1.Read模式:
Note:查询不能保证强一致性。
下面讲述这种模式下会遇到的问题,以及解决方案。
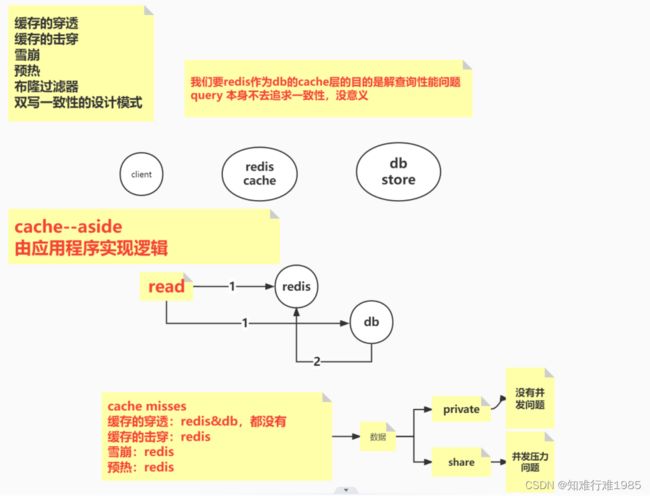
并发读缓存可能遇到的问题:缓存穿透,缓存击穿,雪崩,预热,都是Redis缓存里没有对应数据的情况,这种时候如果发生并发读怎么办?分两种情况:
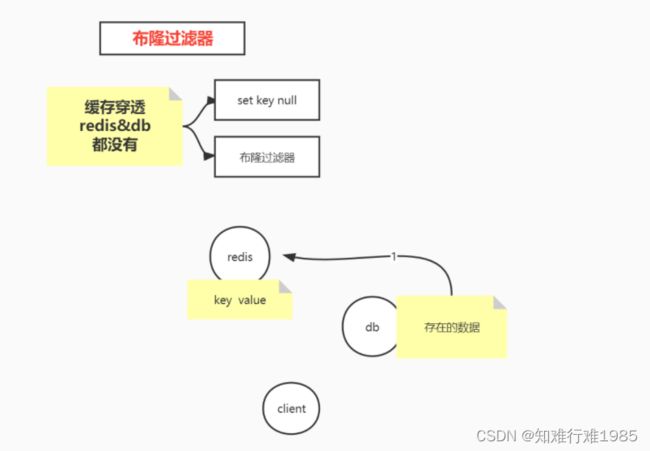
- Redis&DB都没有数据(缓存穿透),使用布隆过滤器,将数据库中的数据通过多次hash,以bit的方式存储到布隆过滤器的bitMap数组,并发请求过来的时候,请求的数据也要经过这样的多次hash,找到对应的多个bit,如果都是1,则认为数据库中是存在的,放行;如果有任何一个bit为0,则直接返回,找不到数据。放行的请求的请求数据有可能在数据库中也是没有的(hash碰撞,但是这种情况很少),那么则在Redis 缓存中设置value为null(一定要加过期时间,因为,万一数据库中有数据了呢???)。这样两种办法结合,就能很好的解决缓存穿透问题。
- Redis中没有数据,但是DB中有(缓存击穿、雪崩、预热失败的情况),这个时候并发来了,需要采用并发排他的方式来处理。
1.布隆过滤器:缓存穿透
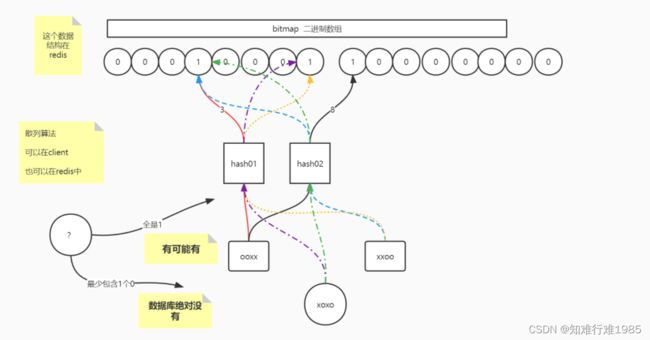

举例:系统数据库中商品编号为1到100,我们可以为商品创建一个布隆过滤器,然后将商品编号1到100都添加到布隆过滤器中,前端查找商品的时候,使用商品编号去布隆过滤器中查找
- 如果布隆过滤器中存在该商品编号,直接查询redis缓存,如果布隆过滤器出现误判(概率很小),在redis中不存在,并且在数据库中也不存在(缓存穿透),则设置 set key null,并且一定要设置过期时间,万一后面增加了这种商品呢?
- 如果不存在,直接返回找不到商品
具体示例代码如下图所示:设置了误判率为%1

布隆过滤器在项目中的使用流程:
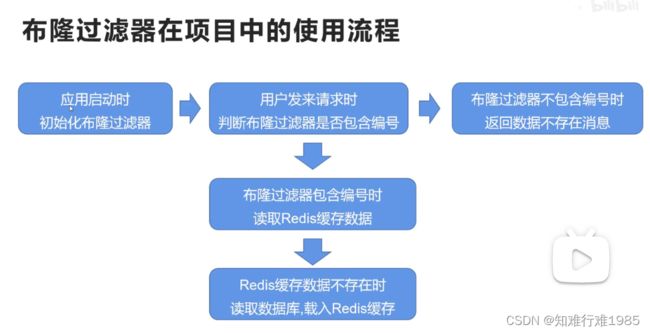
如果商品信息在数据库中被删除了,怎么办?

2.并发排他
现在我们单就缓存击穿和预热的情况(缓存里没有数据,但是数据库中有数据)来研究一下。
并发排他说白了就是并发请求来了,但是Redis缓存中没有数据,这时候应该只让一个线程去数据库拿数据,然后放入缓存,然后其它线程从缓存中取数据。
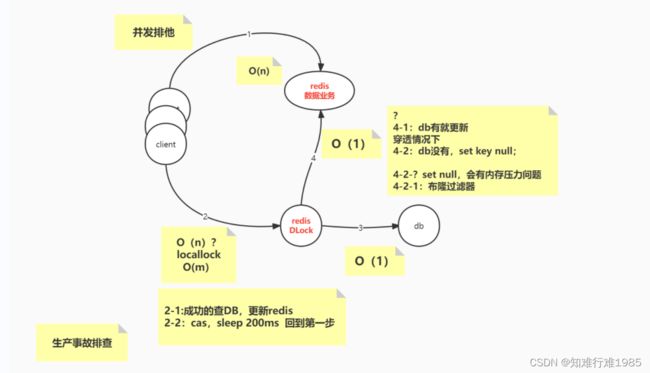
下面以我们在实际项目中遇到的问题,来讲述一下并发排他
预热:
为了达到预期的并发处理能力,我们在查询的时候采用Redis缓存,但是一开始Redis里并没有缓存对应的数据,我们需要先将数据从数据库中取出,然后存储到Redis中,在高并发情况下应该怎么处理?所有请求都去数据库取数据,然后存储到Redis中?显然这是不合理的,只要由一个线程(请求)去访问数据库,将获取的数据存入Redis,其它请求只需要从Redis中获取就好了。
要达到上述效果,就需要加锁,如果系统做了集群,那么就要考虑使用分布式锁,正好Redisson为我们提供了分布式锁功能,就用它了。
下面这段代码就是用了Redis分布式锁保证只有一个线程去访问数据库并将结果存入Redis。
但是能看出来这里有什么问题吗???
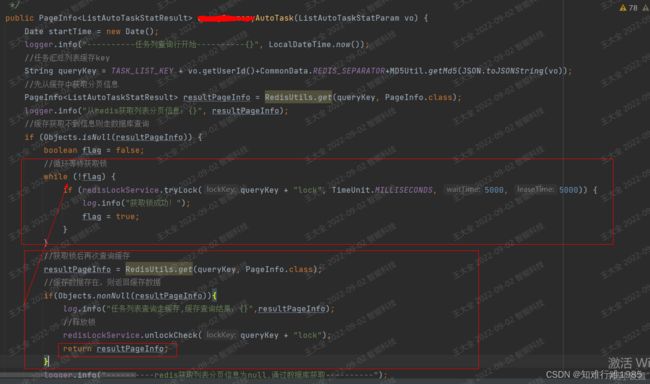
在并发的情况下,如果有几百个请求在同一时刻打过来,同时发现缓存里没有数据,那肯定不能都去数据库里取数据,然后再写入缓存,只需要一个线程去做这件事情就行了。
这一个线程拿到锁,然后从数据库拿到数据,并且存入Redis缓存,然后其它的请求从Redis缓存里取数据就行了。
其它请求不用每次都在那里(while循环里)等着拿锁,在拿锁之前先看看能不能从Redis缓存里取出数据(第一个线程大概率已经写入了),如果有Redis数据,我不用再去拿锁了,拿锁的话线程要在这里干等着。
直接能从Redis里拿到数据,我还去拿锁干什么?正常情况下,一个线程(请求)拿锁然后把事情做了(数据写到Redis缓存),其它请求不需要拿到锁之后才能从Redis缓存里取,可以在拿锁之前取一次,一般就取到了。
现在是每个请求都要拿锁之后才能从Redis取数据,这是一个挨着一个,排队取。while循环里就只有拿锁的操作,拿到锁之后才能继续从Redis里获取数据。在while循环里,我拿锁之前,先获取一次Redis缓存数据,不要先去获取Redis分布式锁。
代码应该改成这样:
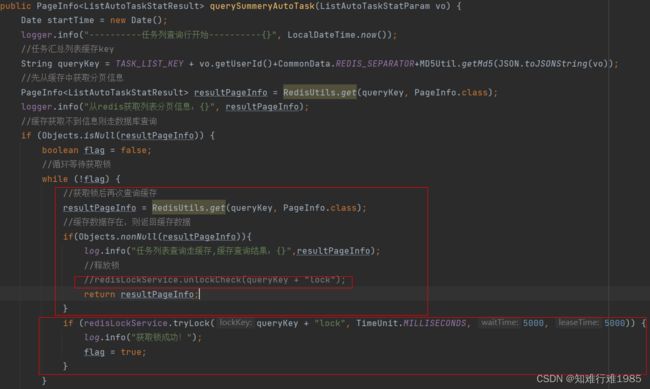
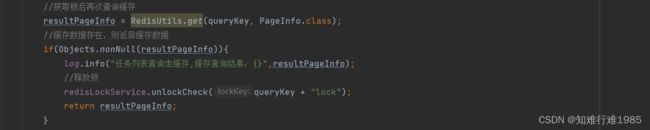
3.小总结:

2.Write模式:双写一致性
在需要修改数据的时候,怎样保证数据库和Redis缓存中数据一致性???
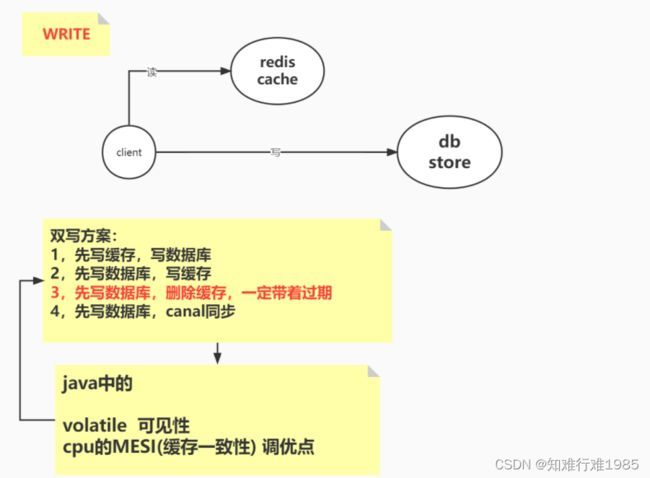
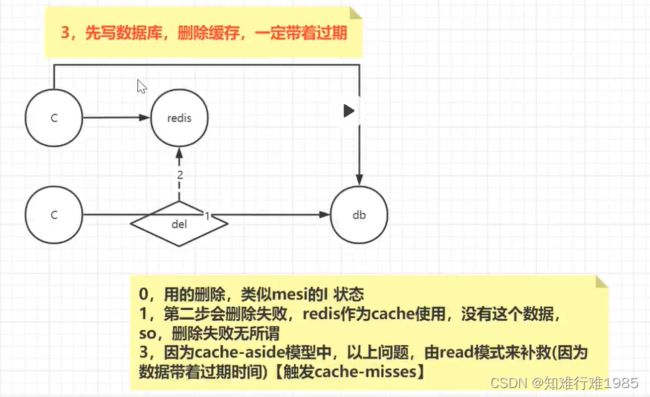
补充:先写数据库,再删缓存,可能发生删除缓存失败的情况,为了应对这种情况,缓存要设置过期,还有就是可以使用延迟双删
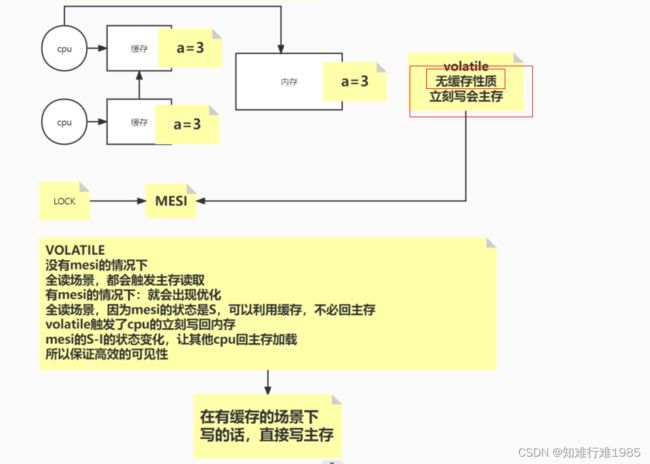
类似的理论:拿java中的volatile举例说明,其实就是无缓存性质保证数据的一致性。
下面是双写的四种方案的介绍:
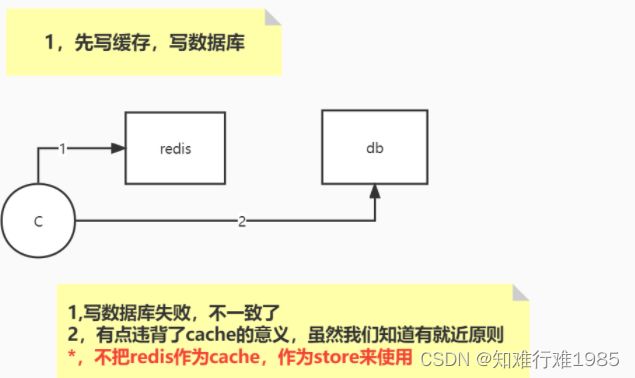
为什么说违背了cache的意义?这样解释:缓存是为了提高读性能的,写的时候没有必要一定要写缓存,因为写缓存之后,没有并发去读,这是浪费Redis内存。当然了,如果确定后续会接着发生并发读,那么可以考虑写入数据库并写入缓存。
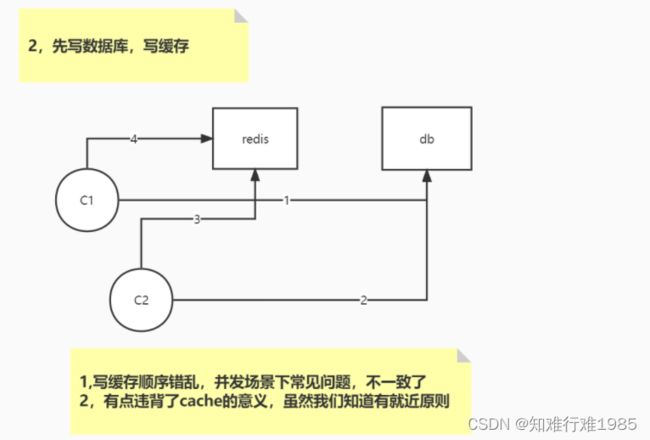
canal不知道知道哪些数据是热点数据,需要放入Redis缓存。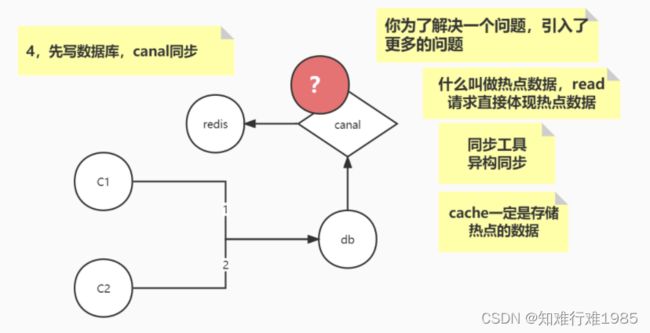
以上3种方案因为各种各样的原因,都被否定了,只剩先写数据库后删缓存这一种方案。目前我们用的是这种方案。
不过它也有自己的问题,例如删除失败,等待过期的这段时间内,数据是不一致的,所以无法保证强一致性,但是能保证最终一致性(过期后,从数据库拿数据放入缓存),符合CAP中的AP。
3.Redis分布式锁:
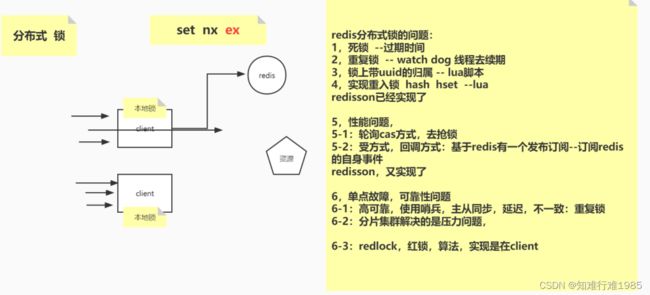
redLock红锁,解决单点故障问题:
例如3个互相之间没有联系的Redis实例

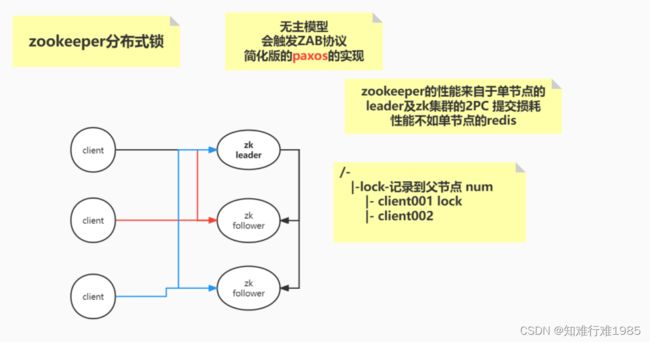
Zookeeper分布式锁比红锁更好用:
4.Redis缓存存什么数据:
Redis也可以做为存储store,存储全量数据,但是如果做为缓存,那么肯定不需要存储全量数据,只存储静态字典数据,热点数据等。
缓存是存储热数据的,不是什么数据都要往redis存。

如果Redis缓存快满了,导致LRU比较频繁,那么会导致redis性能急剧下降。
参考文章:
Cache-Aside pattern - Azure Architecture Center | Microsoft Docs