知识图谱(七)——事件抽取
文章目录
- 一、任务概述
-
- 1、事件的定义
- 2、事件抽取的定义
- 3、相关评测和语料资源
- 二、限定域事件抽取
-
- 1、基于模式匹配的事件抽取方法
-
- 1)有监督的事件模式匹配
- 2)弱监督的事件模式匹配
- 3)优缺点:
- 2、基于机器学习的事件抽取方法
-
- 1)有监督事件抽取方法
-
- (1)基于特征工程的方法
- (2)基于神经网络的方法
- 2)弱监督事件抽取方法
-
- (1)基于 Bootstrapping 的事件抽取
- (2)基于Distant Supervison的事件抽取
- 三、开放域事件抽取
-
- 1、基于内容特征的事件抽取方法
- 2、基于异常检测的事件抽取方法
- 四、事件关系抽取
-
- 1、事件共指关系
- 2、事件因果关系
- 3、子事件关系
- 4、事件时序关系
一、任务概述
1、事件的定义
没有统一的定义,在知识图谱领域,自动内容抽取(ACE)评测会议中对事件的定义如下:
- 事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或多个角色参与的一个或多个动作组成的事情或状态的改变。
2、事件抽取的定义
研究:如何从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来。重点在从非结构化文本中进行事件抽取。
过程:首先从非结构文本中识别出事件及其类型,然后抽取出该事件所涉及的事件元素。
相关概念:
- 事件指称(event mention):对一个客观发生的具体事件进行的自然语言形式的描述,通常是一个句子或句群。同一事件可有不同的事件指称、在文档中分布的位置也不同、或分布在不同对的文档中。
- 事件触发词(event trigger):一个事件指称中最能代表事件发生的词,是决定事件类别的重要特征。一般是动词或是名词。
- 事件元素(event argument):指事件中的参与者,是组成事件的核心部分,它与事件触发词构成了事件的整个框架。
- 主要由实体、事件和属性值组成,这些短语可作为表达完整语义的细粒度单元,可表示事件参与者。
- 注意:并不是所有的实体、事件和属性值都是事件元素,要根据具体上下文语义环境确定。
- 元素角色(argument role):事件元素与事件之间的语义关系,即事件元素在相应的事件中扮演什么角色。
- 事件类别(event type):事件元素和触发词决定了事件的类别。很对测评和任务都为事件制定了类别,每个类别下又定义类若干子类别并为每个事件子类别制定了模板,方便事件元素的识别及事件角色的判定。
3、相关评测和语料资源
- MUC会议(Message Understanding Conference,消息理解会议)
- TDT会议(Topic Detection and Tracking,话题识别与跟踪):以事件的形式组织新闻事件,对其进行研究与评测。
- 话题(Topic)是TDT中的最基本的概念,一个话题是指由某种原因引起的,发生在特定时间点或时间段,在某个地域范围内,并可能导致某些必然结果的一个事件。
- 事件 vs 话题:起初含义相同,后来话题含义为包括一个核心事件以及与之直接相关的事件的集合。
- TDT的五个子任务:新闻报道切分、新事件识别、报道关系识别、话题识别、话题跟踪。
- ACE会议(Automatic Context Extraction,自动内容抽取):ACE的事件是预定义类型的、句子级的事件,语料中标注事件的类型、触发词、事件元素及其在事件中扮演的角色。
- 使用最广泛:ACE2005事件语料数据集
- ACE中将事件定义为一个动作的发生或状态的改变。事件包含事件触发词和事件元素两部分。ACE中定义8大类23小类事件类型。
- ACE语料的标注格式采用XML方式,每个事件都标注了事件触发词、事件类型、事件子类型、事件元素和事件元素扮演的角色信息,此外还有四种属性:
- 事件的极性(polarity):表示肯定的事件 或 表示否定的事件
- 事件的时态(tense):过去发生的事件、正在发生的事件、将来即将发生的事件,以及无法确定时态的事件
- 事件的指属(genericity):特指(specific)事件 和 泛指(generic)事件
- 事件的形态(modality):语气非常肯定(asserted)的事件 和 信念事件(believed event)、假设事件(hypothetical event)等
- KBP会议(Knowledge Base Population):研究从自然语言文本中抽取信息,并且链接到现有知识库的相关技术。
- BioNLP会议:从生物医学文献中抽取出事件触发词、事件类型和事件元素等生物事件信息。
- TimeBank语料库:面向问答系统的时间和事件的识别会议
- 等等
二、限定域事件抽取
按照事件类别方式不同,可分为:
- 限定域事件抽取:在抽取之前,预先定义好目标事件的类别及每种类型的具体结构(包含哪些事件元素)。
- 根据抽取方法的不同,可分为:基于模式匹配的方法、基于机器学习的方法
- 开放域事件抽取
1、基于模式匹配的事件抽取方法
基于模式匹配的事件抽取方法:对某种类别事件的识别和抽取是在某一些模式的指导下进行的,匹配的过程就是事件识别和事件抽取的过程。
过程:模式获取 和 模式匹配。模式准确性尤为重要。

1)有监督的事件模式匹配
模式的获取完全基于人工标注的语料,学习效果高度依赖人工标注效果。
步骤:
- 语料的人工标注:需人工预先标注大量的语料。
- 模式的学习:通过各种学习模型方法得到相应的抽取模式。
- 模式的匹配:利用学习得到的模式与待抽取文档进行匹配,进而完成事件抽取。
典型系统:AutoSlog、PALKA模式抽取系统
2)弱监督的事件模式匹配
不需要对语料完全标注,只需要人工对语料进行一定的预分类或者制定少量种子模式,由机器根据预分类语料或者种子模式自动学习事件模式。
步骤:
- 语料的人工预分类或种子模式的制定
- 模式的学习:利用机器根据预分类语料或者种子模式自动学习事件模式。
典型系统:AutoSlog-TS系统、ExDisco系统、GenPAM系统、NEXUS系统
3)优缺点:
- 在特定领域中性能较好。
- 然而,依赖于文本的具体形式,获取模板的过程费时费力,具有很强的专业性,而且制定的模式很难覆盖所有的事件类型,当语料发生变化时,需要重新获取模式。
- 可移植性不强,召回率低。
2、基于机器学习的事件抽取方法
根据所需监督数据不同,可分为:有监督事件抽取方法 和 弱监督事件抽取方法
1)有监督事件抽取方法
步骤:
- 训练样本的表示。eg:基于特征向量方法中特征向量的抽取与构建
- 选择分类器并训练模型,优化参数。
- 未标注数据中事件抽取。
(1)基于特征工程的方法
需显式地将 事件实例 =》特征向量(如何提取具有区分性的特征)
步骤:
- 特征抽取:提取词汇、句法和语义等特征并收集起来,产生描述事件实例的各种局部和全局特征。
- 模型训练:训练分类器
- 事件抽取:用分类器对非结构化文本进行分类,进而完成事件抽取
典型方法:2006年,Ahn提出的一个两阶段的多分类问题。
事件触发词的特征:
- 词汇特征:词汇,词汇小写形式,词干,词性标签,相邻词特征
- 句子级特征:依存路径,依存词汇,候选词在依存树的深度,依存词汇的词性标签,句子中的实体类型,最近距离范围内的实体类型等
- 外部知识:在wordnet中的同义词id
事件元素分类的特征:
- 触发词特征
- 词汇特征
- 句子级特征
不足:
- 过程过分依赖词性标注器、句法分析器等传统的NLP工具 ==》造成累计误差
- 很多语言没有NLP工具
(2)基于神经网络的方法
步骤:
- 特征表示:将纯文本表示为分布式特征信息,eg:词表示为词向量。
- 神经网络的构建与高层特征学习:涉及搭建神经网络模型并基于基本特征自动捕获高层特征。
- 模型训练:利用标注数据,优化网络参数,训练网络模型。
- 模型分类:利用训练的模型对新样本进行分类,进而完成事件抽取。
典型方法:2015,动态多池化卷积神经模型,该方法将事件抽取当作一个二阶段的多分类问题,第一阶段为触发词抽取,第二阶段为元素抽取(更为复杂,以此为例进行说明)。
- 词向量学习:通过非监督信息得到每个词的向量化表示。
- 词汇级特征表示:利用词向量捕获词汇级语义。
- 将候选词(候选触发词和候选事件元素)的词向量和候选词上下文的词向量拼接起来作为事件元素抽取段的词汇级表示。
- 句子级特征表示:利用动态多池化CNN学习句子内部的组合语义特征。
- 为了处理一句话有多个事件的情况,利用动态多池化技术,根据触发词和候选元素动态地捕获一个句子中的事件信息。
- 事件元素分类:利用Softmax分类器为每个候选事件元素计算扮演不同角色的概率。
模型训练:定义训练的目标函数,然后利用随机梯度下降等训练方法优化模型参数,进而训练整个网络的参数。为防止过拟合,可使用Adadelta等更新规则。
其他方法:联合循环神经网络进行事件抽取
2)弱监督事件抽取方法
- 有监督方法:人工标记数据耗时费力、一致性差,尤其在面向海量异构的网络数据时;
- 无监督方法:得到的事件信息没有规范的语义标签(事件类别、角色名称等)。
- 弱监督方法:为了得到规范的语义标签,需要给出具有规范语义标签的标注训练数据,与有监督方法不同,获得大规模标注语料(关键)的途径主要有两种:
- 利用 Bootstrapping 方法扩展语料。首先人工标注部分数据,然后自动扩展数据规模。
- 利用 Distant Supervison 方法自动生成大规模语料。主要利用结构化的事件知识回标非结构化文本,获取大规模训练样本后完成事件的抽取。
(1)基于 Bootstrapping 的事件抽取
基本框架:
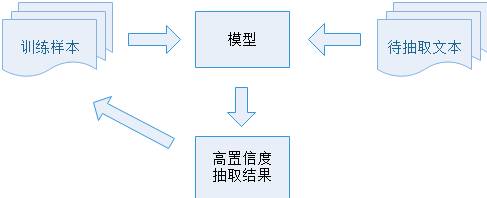
核心思想:首先利用小部分标记数据训练抽取模型,然后利用训练好的模型对未标注数据进行分类,从中选取高置信度的结果加入到训练数据中,再次训练分类器,上述过程反复迭代进而完成标注数据的自动扩充和事件的自动抽取。
现状:基于弱监督的事件抽取方法还处于起步阶段,迫切需要自动生成大规模的、高质量的标注数据法人方法来提升性能。
(2)基于Distant Supervison的事件抽取
基本框架:
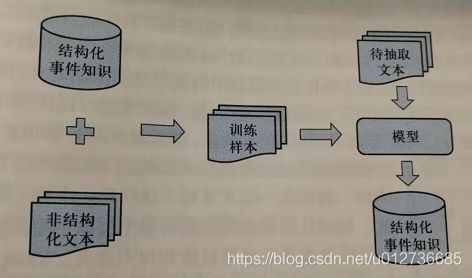
核心思想:首先提出回标的假设规则(即 Distant Supervison),然后利用结构化事件知识去非结构化文本中进行回标,将回标的文本当作标注样本,然后利用标注的样本训练模型,进而完成事件的抽取。
代表方法:2017年,Chen提出的事件语料的大规模自动生成方法,其框架如下图所示。

- 核心元素检测:自动区分每个类型的事件中元素的重要程度并找到每个事件类型的核心事件元素。
- 事件触发词检测:利用核心元素回标可能包含相应事件实例的句子并检测其中的事件触发词。
- 事件触发词过滤和扩展:用语言学知识FrameNet过滤上一模块中发现的噪声触发词,并扩展确实的触发词,进而提高触发词的正确率和召回率;
- 标注数据的自动生成:利用本文提出的远距离监督方法自动从非结构化文本中标注事件信息。
不足:该方法无法自动生成篇章级标注数据并进行篇章级事件抽取(具有重要价值和现实意义)。
三、开放域事件抽取
开放域事件抽取主要基于无监督的方法,该方法主要基于分布假设(Distributional Hypothesis)理论,将候选词的上下文作为表征事件语义的特征。按照所用方法的不同,可分为 基于内容特征的事件抽取方法 和 基于异常检测的事件抽取方法。
无监督事件抽取的关键:寻找更好的文本表示方式、文本相似度衡量指标
难以应用到其他NLP任务中。
1、基于内容特征的事件抽取方法
步骤:
- 文本表示:对表示事件的句子、段落或者文档进行预处理,并表示为同一的特征形式,为后面的模块做准备。
- 事件聚类与新事件发现:基本文本表示,利用无监督方法将同类事件表示聚类,并发现新事件。
代表方法:1998年,Yang等提出 组平均聚类方法。
- 文本表示:对每篇文档首先进行句子划分和去停用词等预处理操作,然后对篇章中的词计算TF-IDF并据此进行排序,利用 Top K 个词的 TF-IDF 值组成的特征向量代表整个篇幅。
- 事件聚类与新事件发现:组平均聚类方法(Group Average Clustering)
- ① 将待聚类文本按时间顺序排序,把每篇文档都当作一个类。(原因:数据观察得出,新闻对事件的报告在时间上具有时效性(一般周期为两个月)和集中性)
- ② 将现有的结果划分成连续但不重叠的固定个数的部分。
- ③ 对每个部分利用聚类算法进行聚类,将底层的类聚类为高层的类。知道每个部分聚类为指定的规模。
- ④ 取消部分的边界限制,对所有的类进行聚类,并更新第②步中的划分。
- ⑤ 重复第②~⑤步,直到所有的类别到达指定的规模。
不足:可以发现新的事件,但其发现的新事件往往是相似模板的聚类,难以规则化,很难被用于构建知识库,需要将其同现有知识库的事件框架进行对齐,或者通过人工方式来给每个聚类事件簇赋予语义信息。
2、基于异常检测的事件抽取方法
基本假设:某个重大事件的发生会导致新闻媒体或社交网络上涌现出大量的相关报道或讨论;反之关于某一主题的报道或讨论突然增多则暗示着某一重大事件的发生。
通用方法:对文档整体的异常情况进行分析 或 对每个词频进行异常检测
四、事件关系抽取
核心任务:以事件为基本语义单元,实现事件逻辑关系的深层检测和抽取。
现状:目前没有清晰统一的框架和定义,比较公认的有事件共指关系、事件因果关系、子事件关系和事件时序关系等。
1、事件共指关系
定义:当两个事件指称项指向真实世界的同一个目标事件,则认为这两个事件具有共指关系。有助于在多源数据中发现相同事件,对事件信息的不全和验证有积极作用。
- eg:“2014年10月,联想集团正式完成对摩托罗拉移动的收购” 和 “联想集团以29.1亿美元的价格收购了摩托罗拉移动”描述的是同一个事件。
核心问题:计算两个指称项之间的相似度,一般会利用两类特征:
- 事件指称的文本语义相似度;
- 事件类型和事件元素之间的相似度
数据集:ECB(Event Coreference Bank)
2、事件因果关系
定义:因果关系反映了事件间先后相继、由因及果的一种关系。对文本的深层语义理解有重要意义,有助于掌握事件演变的过程,从而为决策者提供重要的决策信息。
难点:
- 因果关系错综复杂,一个事件的发生可能包含多个原因,须同时考虑多个因果事件间的传递作用。
- eg:“睡前喝咖啡导致失眠”,“失眠导致上班迟到”,“上班迟到导致被老板批评”是一个因果关系链。
- 在某些情况下,单独从文本中很难抽取出因果关系,需要背景知识的辅助推断。
- eg:“近日国家公布消息称在未来五年将继续加大对新能源汽车行业的扶持力度”和“今天比亚迪汽车的国家开盘10分钟就涨停了”。借助背景知识:“比亚迪是一家中国新能源汽车制造厂商。”,就可以推断出两个事件是因果关系。
3、子事件关系
定义:子事件关系反映了事件之间的粒度和包含关系,例如:“地震事件”一般包含“伤亡”、“救援”、“捐款”和“重建”等子事件。eg:连续报道、专题报道。
典型方法:基于先验的增量子事件学习模型、基于概率的贝叶斯网络结构学习方法、端到端的上下文相关的层次LSTM模型。
4、事件时序关系
定义:事件时序关系是指在时间上的先后顺序。可以辅助其他事件关系的发现。
目前,绝大多数事件时序关系的研究都集中在英文文本上,最广泛应用的语料是TimeBank;主流方法是基于机器学习方法的事件时序关系抽取,该类方法一般将事件时序关系识别转化为一个多分类问题。
语料库:
- TimeBank的标注遵循TimeML标注体系,TimeML是一种标识新闻语料中事件、事件以及它们之间关系的标注体系,它将时序关系分为13种。eg:之前(Before)、之后(After)、包含(Includes)、被包含(Is Included)和同时(SImultinous)等。
- TimeEval将时序关系分为之前(Before)、之后(After)和重叠(Overlap)三类。