查询提速 20 倍,Apache Doris 在 Moka BI SaaS 服务场景下的应用实践
导读: MOKA 主要有两大业务线 MOKA 招聘(智能化招聘管理系统)和 MOKA People(智能化人力资源管理系统),MOKA BI 通过全方位数据统计和可灵活配置的实时报表,赋能于智能化招聘管理系统和人力资源管理系统。为了提供更完备的数据支持,助力企业提升招聘竞争力,MOKA 引入性能强悍的 Apache Doris 对早期架构进行升级转型,成就了 Moka BI 强大的性能与优秀的用户体验。
作者|Moka 数据架构师 张宝铭
业务需求
MOKA 主要有两大业务线 MOKA 招聘(智能化招聘管理系统)和 MOKA People(智能化人力资源管理系统)。
- MOKA 招聘系统覆盖社招、校招、内推、猎头管理等场景,让 HR 获得更高效的招聘体验,更便捷的协作体验,让管理者获得招聘数据洞见,让招聘降本增效的同时,树立企业在候选人心目中的专业形象。
- MOKA People 覆盖企业所需要的组织人事、假期考勤、薪酬、绩效、审批等高频业务场景,打通从招聘到人力资源管理的全流程,为 HR 工作提效赋能。通过多维度数据洞见,助力管理者高效科学决策。全生态对接,更加注重全员体验,是一款工作体验更愉悦的人力资源管理系统。
而 MOKA BI 通过全方位数据统计和可灵活配置的实时报表,赋能于智能化招聘管理系统和人力资源管理系统。通过 PC 端和移动端的多样化报表展示,为企业改善招聘业务提供数据支持,全面提升招聘竞争力,从而助力科学决策。

MOKA BI 早期架构

Moka BI 数仓早期架构是类 Lambda 架构,实时处理和离线处理并存。
- 实时部分数据主要来源为结构化的数据,Canal 采集 MySQL 或 DBLE(基于 MySQL 的分布式中间件)的 Binlog 输出至 Kafka 中;未建模的数据按照公司分库,存储在业务 DBLE 中,通过 Flink 进行实时建模,将计算后的数据实时写入业务 DBLE 库,通过 DBLE 提供报表查询能力,支持数据大屏和实时报表统计。
- 离线部分涵盖了实时部分数据,其结构化数据来源于 DBLE 的 Binlog,明细数据在 Hbase 中实时更新,并映射成 Hive 表,非结构化数据通过 ETL 流程,存储至 Hive 中,通过 Spark 进行进行离线部分建模计算,离线数仓 ADS 层数据输出至 MySQL 和 Redis 支持离线报表统计,明细数据又为指标预测和搜索等外部应用提供数据支持。
现状与问题
在早期数仓架构中,为了实现实时建模以及实时报表查询功能,就必须要求底层数据库能够承载业务数据的频繁插入、更新及删除操作,并要求支持标准 SQL,因此当时我们选择 DBLE 作为数据存储、建模、查询的底层库。早期 Moka BI 灰度期用户较少,业务数据量以及报表的使用量都比较低,DBLE 尚能满足业务需求,但随着 Moka BI 逐渐面向所有用户开放,DBLE 逐渐无法适应 BI 报表的查询分析性能要求,同时实时与离线架构分离、存储成本高且数据不易维护,亟需进行升级转型。
技术选型
为匹配业务飞速增长的要求、满足更复杂的查询需求,我们决定引入一款性能突出的 OLAP 引擎对 Moka BI 进行升级改造。同时出于多样化分析场景的考虑,我们希望其能够支撑更广泛的应用场景。调研的主要方向包括 报表的实时查询能力、数据的更新能力、标准的查询 SQL 以及数据库的可维护性、扩展性、稳定性等。

确定调研方向后,我们首先对 Greenplum 展开了调研,其特点主要是数据加载和批量 DML 处理快,但受限于主从双层架构设计、存在性能瓶颈,且并发能力很有限、性能随着并发量增加而快速下降,同时其使用的是 PG 语法、不支持 MySQL 语法,在进行引擎切换时成本较高,因此在基本功能调研结束后便不再考虑使用。
随后我们对 ClickHouse 进行了调研,ClickHouse 在单表查询场景下性能表现非常优异的,但是在多表 Join 场景中性能表现不尽如人意,另外 ClickHouse 缺少数据实时更新和删除的能力,仅适用于批量删除或修改数据,同时 ClickHouse 对 SQL 的支持也比较有限,使用起来需要一定的学习成本。
紧接着我们对近几年势如破竹的 Apache Doris 进行了调研,在调研中发现,Doris 支持实时导入,同时也支持数据的实时更新与删除,可以实现 Exactly-Once 语义;其次,在实时查询方面,Doris 可以实现秒级查询,且在多表 Join 能力的支持上更加强劲;除此之外,Doris 简单易用,部署只需两个进程,不依赖其他系统,兼容 MySQL 协议,并且使用标准 SQL ,可快速上手,部署及学习成本投入均比较低。
Benchmark
在初步调研的基础之上,我们进一步将 Apache Doris 、Clickhouse 与当下使用的 DBLE 在查询性能上进行了多轮测试对比,查询耗时如下:
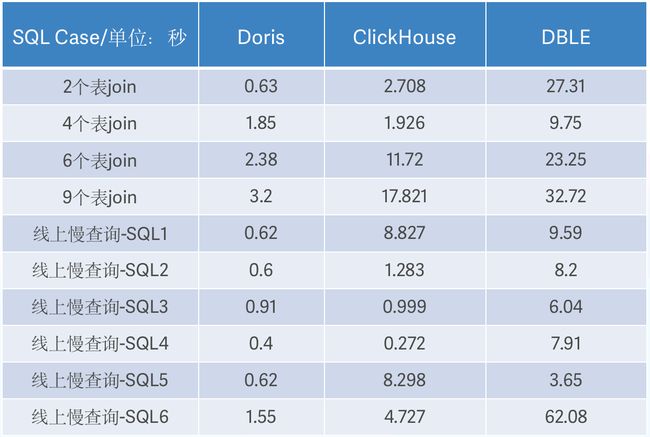
- 多表 Join:随着 SQL Join 数量的增多,Doris 和 ClickHouse 性能表现差距越来越大,Doris 的查询延迟相对比较稳定,最长耗时仅为 3.2s;而 ClickHouse 的查询延迟呈现指数增长,最长耗时甚至达到 17.8s,二者性能最高相差 5 倍,DBLE 的查询性能则远不如这两款产品。
- 慢查询: 在线上慢查询 SQL 的对比测试中,Doris 的性能同样非常稳定,不同的 SQL 查询基本都能在 1s 内返回查询结果,ClickHouse 与之对比查询延迟波动较大、性能表现很不稳定,二者相同 SQL 性能差距最大超过 10 余倍。
通过以上调研对比,可以看出 Apache Doris 不管是在基本功能上、还是查询性能上表现都更胜一筹,因此我们将目标锁定了 Doris,并决定尽快引入 Apache Doris 作为 Moka BI 新一代 数仓 架构的查询引擎。
新版架构
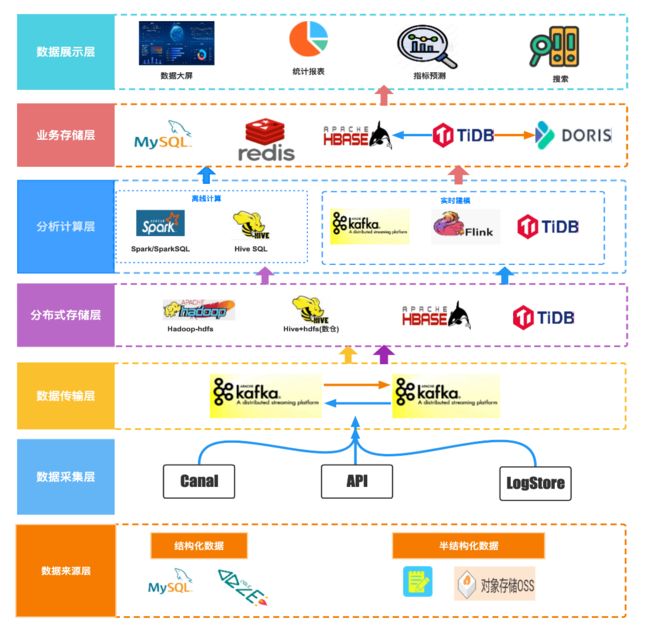
在引入 Doris 之后,Moka BI 数仓架构的主要变化是将 OLAP 和 OLTP 进行分离,即使用 DBLE 支持数据的实时建模,数据来源于 Moka 系统的业务数据,包含了结构化和半结构化的数据,通过 Flink 读取 DBLE Binlog,完成数据去重、合并后写入 Kafka,Doris 通过 Routine Load 读取 Kafka 完成数据写入,此时 DBLE 仅作为数据建模合成使用,由 Doris 提供报表查询能力。
基于 Doris 列存储、高并发、高性能等特性,Moka BI 报表采用自助方式构建完成,支撑客户根据需求灵活配置行、列、筛选的场景。与传统报表按需求定制开发方式对比,这种自助式报表构建非常灵活,平台开发与需求开发完全独立,需求完成速度得到极大的提升。

数据导入方面,数据通过 Routine Load 定期批量导入到 Doris 数据仓库中,保证了数据的准实时同步。通过对系统数据收集与建模,及时向客户提供最新的业务数据,以帮助客户快速了解招聘情况,并做出有效的调整。
数据更新方面,Doris 在大数据量(单表几十亿)的场景下,表现出了突出的数据更新和删除能力,Moka BI 读取的是业务库的 Binlog 数据,其中有大量的更新以及删除操作,Doris 可以通过 Routine Load 的 Delete 配置实现实时删除,根据 Key 实现幂等性写入,配合 Flink 可以做到真正的 Exactly-Once。在架构中增加了 Routine Load 后,数仓可以实现 1 分钟级别的准实时 , 同时结合 Routine load + Kafka 可以实现流量的削峰,保证集群稳定,并且可以通过重置 Kafka 偏移量来实现间数据重写,通过 Kafka 实现多点消费等。
数据查询方面,充分利用 Doris 的多表 Join 能力,使得系统能够实现实时查询。我们将不同的数据表按照关联字段进行连接,形成一个完整的数据集,基于数据集可进行各种数据分析和可视化操作,同时可高效应对任意条件组合的查询场景以及需要灵活定制需求的查询分析场景,在某些报表中,需要 Join 的表可能达到几十张,Doris 强大的 Join 性能,使 Moka BI 的报表查询可以达到秒级响应。
运维管理方面,Doris 部署运维简单方便,不依赖第三方组件,无损弹性扩缩容,自动数据均衡,集群高可用。Doris 集群仅有 FE 和 BE 两个组件,不依赖 Zookeeper 等组件即可实现高可用,部署、运维方便,相比传统的 Hadoop 组件,非常友好,支持弹性扩容,只需简单配置即可实现无损扩容,并且可以自动负载数据到扩容的节点,大大降低了我们引入新技术栈的难度和运维压力。
调优实践
新架构实际的落地使用中,我们总结了一些调优的经验,在此分享给大家。
在 Moka BI 报表查询权限场景中,同样配置的报表,有权限认证时查询速度比没有权限认证时慢 30% 左右,甚至出现查询超时,而超管权限查询时则正常,这一现象在数据量较大的客户报表中尤为明显。
人力资源管理业务的数据权限有着极为严格和精细的管控需求,除了 SaaS 业务自身对于不同租户间的数据隔离要求外,还需要针对业务人员的身份角色、管理部门范畴以及被管理人员的信息敏感程度对可见数据的范围进行进一步细分,因此在 Moka BI 权限功能模块的设计之时就考虑并实现了极为灵活的自定义配置化方案。例如 HRBP 与 PayRoll、HRIS 等角色的可见字段不同、不同职级或部门但角色一致用户的可见数据区间不同,同时针对部分敏感的人员信息还需要做数据过滤,或者出于管理授权的需求临时开通某一权限,甚至以上权限要求还会进行多重的交叉组合,以保证每一用户可查看的数据、报表、信息均被限制在权限范围以内。
因此当用户需要对数据报表进行查询时,会先在 Moka BI 的权限管理模块进行多重验证,验证信息会通过 in 的方式拼接在查询 SQL 中并传递给 OLAP 系统。随着客户业务体量的增大,对于权限管控的要求越精细、最终所产生的 SQL 就越复杂,部分业务规模比较大的客户报表会出现上千甚至更多的权限限制,因此造成 OLAP 系统的 id 过滤时间变长,导致报表查询延迟增加,给大客户造成了体验不佳。

解决方案:
为适配该业务场景,我们通过查看官方的文档发现 Doris Bloom Filter 索引的特性可以很好的解决该问题

Doris BloomFilter 索引使用场景:
- BloomFilter 适用于非前缀过滤。
- 查询会根据该列高频过滤,而且查询条件大多是
in和=过滤。 - 不同于 Bitmap,BloomFilter 适用于高基数列,比如 UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个 Block 几乎都会包含所有取值,导致 BloomFilter 索引失去意义。

经过验证,可以通过上方对比报表看到,将相关 ID 字段增加 BloomFilter 索引后 ,权限验证场景查询速度提升约 30% ,有权限验证的报表超时的问题也得到了改善。
收益与总结
目前 Moka BI Doris 有两个集群, 共 40 台服务器, 数仓 共维护了 400 多张表 ,其中 50 多张表数据量超过 1 亿,总数据量为 T B 级别。
引入 Apache Doris 改造了新的数据仓库之后,满足了日益增长的分析需求以及对数据实时性的要求,总体收益包含以下几点:
- 高性能数据查询: Doris 基于列存储技术,能够快速处理大量的数据,并支持高并发的在线查询,解决了关系型数据库无法支持的复杂查询问题,复杂 SQL 查询的速度上升了一个数据量级。
- 数据仓库 的可扩展性: Doris 采用分布式集群架构,可以通过增加节点来线性提升存储和查询瓶颈,打破了关系型数据库数据单点限制问题,查询性能得以显著提升。
- 更广泛的应用: 基于 Doris 构建了统一的数据查询平台,应用不再局限于报表服务,对于离线的查询也有很好的支撑,可以说 Doris 的引入是构建数仓一体化的前奏。
- 实现自助式分析: 基于 Doris 强大的查询能力,我们引入了全新的报表构建方式,通过用户自助构建报表方式,能够快速满足用户的各种灵活需求。
在使用 Doris 的两年多时间里,Moka BI 与 Apache Doris 共同成长、共同进步,可以说 Doris 成就了 Moka BI 强大的性能与优秀的用户体验;也正是 Moka BI 特殊的使用场景,也丰富了 Doris 的优化方向,我们提的很多 Issue 与建议,经过版本更新迭代后使其更具竞争力。在未来的时间里,Moka BI 也会紧跟社区脚步,不断优化、回馈社区,希望 Apache Doris 和 SelectDB 发展越来越好、越来越强大。